这篇文章主要讲解了“数据库是如何重建连接从15000个到100个以下”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“数据库是如何重建连接从15000个到100个以下”吧!

从一开始,DigitalOcean就痴迷于简洁。这是其核心价值观之一:力求简单而优雅的解决方案。这不仅适用于我们的产品,也适用于我们的技术决策。在最初的系统设计中,这一点再明显不过了。
像GitHub、Shopify和Airbnb一样,DigitalOcean在2011年开始作为Rails应用程序。Rails应用程序(内部称为Cloud)管理UI和公共API中的所有用户交互。帮助Rails的是两个Perl服务:Scheduler和DOBE(DigitalOcean后端)。
Scheduler计划并分配Droplet给管理程序,而DOBE负责创建实际的Droplet虚拟机。当Cloud和Scheduler作为独立服务运行时,DOBE在机队的每台服务器上运行。
Cloud、Scheduler和DOBE都不能直接交流。他们通过MySQL数据库进行通信。这个数据库有两个作用:存储数据和安排通信。这三个服务都使用一个数据库表作为消息队列来传递信息。
每当用户创建一个新的Droplet时,Cloud就会向队列中插入一个新的事件记录。Scheduler每秒连续调查数据库以查找新的Droplet事件,并计划在可用的管理程序上创建这些事件。
最后,每个DOBE事件将等待新的计划Droplet被创建并完成任务。为了使这些服务器可以检测到所有新改动,它们都需要调查数据库以查找表中的新记录。
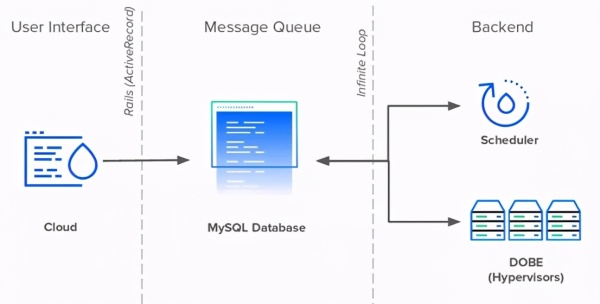
在系统设计方面,无限循环和给每个服务器一个与数据库的直接连接,这可能是最基本的,很简单,而且很有效——特别是对于一个人手不足的技术团队来说,他们面临着紧迫的最后期限和快速增长的用户群。
四年来,数据库消息队列构成了DigitalOcean技术栈的主干。在此期间,我们采用了一种微服务体系结构,用gRPC替换了HTTPS作为内部通信量,用Golang代替Perl作为后端服务。然而,所有的路仍然通向那个MySQL数据库。
重要的是,不能仅仅因为某些东西是陈旧的,就认为它就是不正常的,应该被取代的。Bloomberg和IBM拥有用Fortran和COBOL编写的遗留服务,它们所产生的收入比整个公司多得多。另一方面,每个系统都有一个比例限制。我们需要面对。
从2012年到2016年,DigitalOcean的用户流量增长超过10000%。我们在产品目录中增加了更多的产品,在基础设施中增加了更多的服务。这增加了数据库消息队列上事件的进入量。
对Droplet的需求增加意味着Scheduler正在加班加点地将它们全部分配给服务器。不幸的是,对于Scheduler来说,可用服务器的数量并不固定。
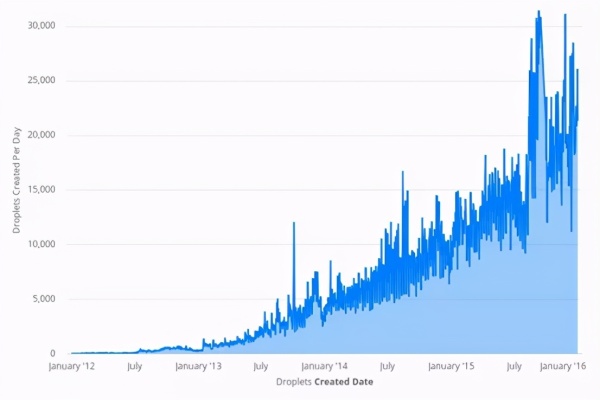
为了跟上不断增长的Droplet需求,我们增加了越来越多的服务器来处理流量。每个新的管理程序意味着另一个到数据库的持久连接。到2016年初,该数据库拥有超过15000个直接连接,每个连接每1到5秒查询一次新事件。
如果这还不够糟糕的话,那么每个管理程序用来获取新的Droplet事件的SQL查询也变得越来越复杂。它已经变成了一个150多行的巨人,横跨18张表格。它既令人印象深刻,又岌岌可危,难以维持。
不出所料,就是在这个时期前后,裂缝显现。一个单一的故障点和数千个依赖项争夺共享资源,不可避免地导致了一段混乱的时期。表锁和查询积压导致中断和性能下降。
而且由于系统中的紧密耦合,没有一个明确或简单的解决方案。Cloud、Scheduler和DOBE都是瓶颈。仅修补一个或两个组件只会将负载转移到其余的瓶颈。于是,经过反复考虑,工程人员想出了一个三管齐下的整改方案:
减少数据库上的直接连接数。
重构调度器的排序算法以提高可用性。
解除其消息队列职责的数据库。
为了解决数据库依赖性问题,DigitalOcean工程师创建了事件路由器。事件路由器充当区域代理,代表每个数据中心的每个DOBE实例轮询数据库。而不是成千上万的服务器每个查询数据库,将只有少数代理做查询。
每个事件路由器代理将获取特定区域中的所有活动事件,并将每个事件委托给相应的管理程序。事件路由器还将庞大的轮询查询分解得更小、更易于维护。
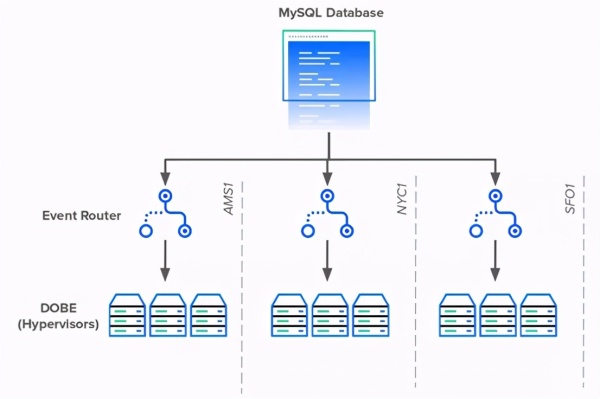
当事件路由器上线时,它将数据库连接的数量从15000多个锐减到不到100个。
接下来,工程师们将目光投向了下一个目标:Scheduler。如前所述,Scheduler是一个Perl脚本,用于确定管理程序将负责创建的Droplet。它通过使用一系列查询对服务器进行排名和排序来实现这一点。每当用户创建一个Droplet时,Scheduler就会用最好的机器更新表行。
虽然听起来很简单,但Scheduler有一些缺陷。它的逻辑很复杂,很难处理。它是单线程的,在流量高峰时性能会受到影响。最后,只有一个Scheduler实例而它必须服务于整个机队。这是一个不可避免的瓶颈。为了解决这些问题,工程团队创建了Scheduler V2。
更新后的Scheduler彻底修改了排名系统。它没有在数据库中查询服务器度量,而是从管理程序聚合并将其存储在自己的数据库中。此外,Scheduler团队通过并发和复制使他们的新服务可在负载下运行。
事件路由器和Scheduler V2都取得了巨大的成就,解决了许多体系结构的故障。即便如此,还是有一个明显的缺陷。到2017年初,集中式MySQL消息队列仍在使用中,甚至很繁忙。它每天处理多达40万条新记录,每秒更新20次。
不幸的是,删除数据库的消息队列并非易事。第一步是阻止服务直接访问它。数据库需要一个抽象层。它还需要一个API来聚合请求并代表它执行查询。如果任何服务想要创建一个新事件,它就需要通过API来创建。于是,Harpoon诞生了。
但是,为事件队列构建接口是最简单的部分。事实证明,要得到其他团队的入股更加困难。与Harpoon集成意味着团队必须放弃对数据库的访问,重写部分代码库,并最终改变他们一直以来的工作方式。那并不容易。
一个团队接着一个团队,一个服务接着一个服务,Harpoon工程师成功地将整个代码库迁移到他们的新平台上。这花了大约一年时间,但到2017年底,Harpoon成为数据库消息队列的唯一发布者。
现在真正的工作开始了。完全控制事件系统意味着Harpoon可以自由地重新设计Droplet工作流。
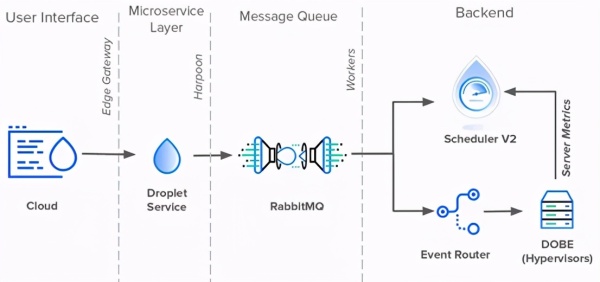
Harpoon的第一个任务是将消息队列职责从数据库提取到自身中。为此,Harpoon创建了自己的内部消息传递队列,该队列由RabbitMQ和异步工作站组成。当Harpoon把新事件推到一边的队列中时,工作站把它们从另一边拉了出来。
由于RabbitMQ取代了数据库的队列,工作站可以自由地直接与Scheduler和事件路由器通信。因此,Harpoon没有使用Scheduler V2和Event Router轮询数据库中的新更改,而是直接将更新推送到数据库中。2019年撰写本文时,这就是Droplet事件体系结构所处的位置。
在过去的七年里,DigitalOcean已经从库乐队的根基成长为今天的老牌云提供商。与其他转型期科技公司一样,DigitalOcean定期处理遗留代码和科技债务。无论是打破整体,创建多区域服务,或消除单一故障点, DigitalOcean工程师始终致力于制定优雅和简单的解决方案。
感谢各位的阅读,以上就是“数据库是如何重建连接从15000个到100个以下”的内容了,经过本文的学习后,相信大家对数据库是如何重建连接从15000个到100个以下这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.toutiao.com/i6946489866767122982/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



