MySQLдёӯжҖҺд№Ҳе®һзҺ°й«ҳжҖ§иғҪзҙўеј•
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶMySQLдёӯжҖҺд№Ҳе®һзҺ°й«ҳжҖ§иғҪзҙўеј•пјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
д»Җд№ҲжҳҜзҙўеј•
зҙўеј•еҸҲеҸҜд»Ҙз§°дёәй”®(key)жҳҜеӯҳеӮЁеј•ж“Һз”ЁдәҺеҝ«йҖҹжүҫеҲ°и®°еҪ•зҡ„дёҖз§Қж•°жҚ®з»“жһ„гҖӮ
зҙўеј•жҳҜжҸҗй«ҳMySQLжҹҘиҜўжҖ§иғҪжңҖжңүж•Ҳзҡ„жүӢж®өпјҢжҲ‘们常иҜҙзҡ„MySQLжҖ§иғҪи°ғдјҳеҹәжң¬йғҪжҳҜеҜ№зҙўеј•зҡ„дјҳеҢ–гҖӮжүҖд»ҘиҝҷжҳҜжҜҸдёӘејҖеҸ‘йңҖиҰҒжҺҢжҸЎе№¶дјҡеә”з”Ёзҡ„зҹҘиҜҶзӮ№гҖӮ
зҙўеј•жҳҜдёҖз§Қж•°жҚ®з»“жһ„пјҢе®ғд№ҹжҳҜеӯҳеӮЁеңЁзЈҒзӣҳзҡ„дёҖдёӘж–Ү件гҖӮдёҠдёҖзҜҮжҲ‘们еӯҰд№ MySQLзҡ„йҖ»иҫ‘жһ¶жһ„зҡ„ж—¶еҖҷдәҶи§ЈдәҶInnoDBе’ҢMyISMеӯҳеӮЁеј•ж“ҺпјҢInnoDBеӯҳеӮЁеј•ж“Һзҙўеј•е’Ңж•°жҚ®жҳҜеҗҢдёҖдёӘж–Ү件пјҢMyISAMзҙўеј•е’Ңж•°жҚ®жҳҜдёӨдёӘзӢ¬з«Ӣзҡ„ж–Ү件гҖӮ
еңЁMySQLдёӯпјҢзҙўеј•жҳҜеңЁеӯҳеӮЁеј•ж“ҺеұӮе®һзҺ°зҡ„иҖҢдёҚжҳҜServerеұӮе®һзҺ°зҡ„пјҢжүҖд»ҘдёҚеҗҢзҡ„еӯҳеӮЁеј•ж“Һзҡ„зҙўеј•зҡ„е·ҘдҪңж–№ејҸжҳҜдёҚдёҖж ·зҡ„гҖӮжҲ‘们еҜ№зҙўеј•зҡ„еҲҶжһҗеә”иҜҘжҳҜе»әз«ӢеңЁеӯҳеӮЁеј•ж“Һзҡ„еҹәзЎҖдёҠзҡ„пјҢInnoDBжҳҜMySQLй»ҳи®Өзҡ„еӯҳеӮЁеј•ж“ҺгҖӮ
зҙўеј•зҡ„дјҳзӮ№пјҡ
зҙўеј•еӨ§еӨ§еҮҸе°‘дәҶжңҚеҠЎеҷЁйңҖиҰҒжү«жҸҸзҡ„ж•°жҚ®йҮҸгҖӮ
зҙўеј•еҸҜд»Ҙеё®еҠ©жңҚеҠЎеҷЁйҒҝе…ҚжҺ’еәҸе’Ңдёҙж—¶иЎЁгҖӮ
зҙўеј•еҸҜд»ҘйҡҸжңәI/OеҸҳдёәйЎәеәҸI/OгҖӮ
зҙўеј•зҡ„зјәзӮ№пјҡ
зҙўеј•ж•°жҚ®жЁЎеһӢ
жҜҸдёӘеӯҳеӮЁеј•ж“Һзҡ„ж•°жҚ®з»“жһ„е’Ңз®—жі•йғҪжҳҜеӯҳеңЁеҢәеҲ«пјҢжҲ‘们е…ҲзңӢдёӢMySQLжң¬иә«ж”ҜжҢҒзҡ„зҙўеј•зұ»еһӢгҖӮ
B-Treeзҙўеј•
дёҖиҲ¬жҲ‘们иҜҙзҡ„зҙўеј•з»“жһ„е°ұжҳҜжҢҮB-Treeзҙўеј•пјҢMySQLеӨ§йғЁеҲҶзҡ„еӯҳеӮЁеј•ж“ҺйғҪж”ҜжҢҒиҝҷз§Қзҙўеј•пјҢдҪҶжҳҜдёҚеҗҢзҡ„еӯҳеӮЁеј•ж“Һд»ҘдёҚеҗҢзҡ„ж–№ејҸдҪҝз”ЁB-Treeзҙўеј•пјҢжҖ§иғҪд№ҹеҗ„жңүдёҚеҗҢгҖӮInnoDBдҪҝз”Ёзҡ„жҳҜB+TreeпјҢжҢүз…§еҺҹжңүзҡ„ж•°жҚ®ж јејҸиҝӣиЎҢеӯҳеӮЁпјҢж №жҚ®дё»й”®еј•з”Ёиў«зҙўеј•зҡ„иЎҢгҖӮ
B-TreeжүҖжңүзҡ„еҖјйғҪжҳҜжҢүйЎәеәҸеӯҳеӮЁзҡ„пјҢ并且жҜҸдёҖдёӘеҸ¶еӯҗеҲ°ж №зҡ„и·қзҰ»зӣёеҗҢгҖӮдёӢеӣҫжҳҜB-Treeзҡ„жҠҪиұЎеӣҫпјҡ
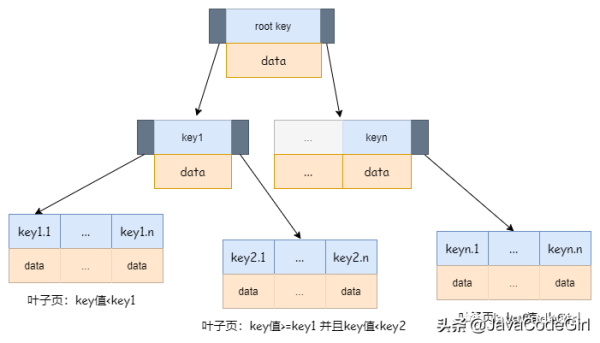
B-TreeиғҪеӨҹеҠ еҝ«и®ҝй—®ж•°жҚ®зҡ„йҖҹеәҰгҖӮ
еӯҳеӮЁеј•ж“ҺдёҚйңҖиҰҒе…ЁиЎЁжү«жҸҸжқҘиҺ·еҸ–жүҖйңҖиҰҒзҡ„ж•°жҚ®пјҢе®ғжҳҜд»Һзҙўеј•зҡ„ж №иҠӮзӮ№ејҖе§ӢжҗңзҙўгҖӮж №иҠӮзӮ№зҡ„ж§Ҫдёӯеӯҳж”ҫжҢҮеҗ‘еӯҗиҠӮзӮ№зҡ„жҢҮй’ҲпјҢжҗңзҙўеј•ж“Һж №жҚ®иҝҷдәӣжҢҮй’Ҳеҗ‘дёӢеұӮжҹҘжүҫгҖӮйҖҡиҝҮжҜ”иҫғиҠӮзӮ№йЎөзҡ„еҖје’ҢиҰҒжҹҘжүҫзҡ„еҖјеҸҜд»ҘжүҫеҲ°еҗҲйҖӮзҡ„жҢҮй’Ҳиҝӣе…ҘеҲ°дёӢеұӮиҠӮзӮ№гҖӮжңҖз»Ҳеј•ж“ҺиҰҒд№ҲжүҫеҲ°еҜ№еә”зҡ„еҖјпјҢиҰҒд№ҲиҜҘи®°еҪ•дёҚеӯҳеңЁгҖӮ
B-Treeзҡ„зҙўеј•еҰӮжһңеӨҡдёӘеҲ—пјҢзҙўеј•еҖјзҡ„жҺ’еәҸжҳҜжҢүз…§е»әиЎЁж—¶е®ҡд№үзҡ„зҙўеј•йЎәеәҸпјҢжүҖд»Ҙзҙўеј•зҡ„йЎәеәҸжҳҜжҜ”иҫғйҮҚиҰҒзҡ„гҖӮ
B-TreeжҳҜNеҸүж ‘пјҢNзҡ„еӨ§е°ҸеҸ–еҶідәҺж•°жҚ®еқ—зҡ„еӨ§е°ҸгҖӮ
д»ҘInnoDBзҡ„дёҖдёӘж•ҙж•°еӯ—ж®өзҙўеј•дёәдҫӢпјҢNеӨ§жҰӮдёә1200пјҢеҪ“ж ‘й«ҳжҳҜ4зҡ„ж—¶еҖҷпјҢе°ұеҸҜд»Ҙеӯҳ1200зҡ„3ж¬Ўж–№зҡ„ж•°жҚ®пјҢеӨ§жҰӮдёә17дәҝгҖӮдёҖдёӘжӢҘжңү10дәҝзҡ„иЎЁдёҠдёҖдёӘж•ҙж•°еӯ—ж®өзҡ„зҙўеј•пјҢжҹҘжүҫдёҖдёӘеҖјжңҖеӨҡи®ҝй—®3ж¬ЎзЈҒзӣҳгҖӮе…¶е®һеңЁеә”з”Ёж—¶пјҢеҰӮжһң第дәҢеұӮиў«жҸҗеүҚеҠ иҪҪеҲ°еҶ…еӯҳдёӯпјҢйӮЈд№ҲзЈҒзӣҳзҡ„и®ҝй—®ж¬Ўж•°е°ұжӣҙе°‘дәҶгҖӮ
е“ҲеёҢзҙўеј•
е“ҲеёҢзҙўеј•жҳҜеҹәдәҺе“ҲеёҢиЎЁе®һзҺ°зҡ„пјҢеҸӘжңүзІҫзЎ®еҢ№й…ҚжүҖжңүеҲ—зҡ„жҹҘиҜўжүҚжңүж•ҲгҖӮ
еҜ№дәҺжҜҸдёҖиЎҢж•°жҚ®пјҢеӯҳеӮЁеј•ж“ҺйғҪдјҡеҜ№жүҖжңүзҡ„зҙўеј•еҲ—и®Ўз®—дёҖдёӘе“ҲеёҢз Ғ(hash code)пјҢе“ҲеёҢз ҒжҳҜдёҖдёӘжҜ”иҫғе°Ҹзҡ„еҖјпјҢ并且дёҚеҗҢй”®еҖјзҡ„иЎҢи®Ўз®—еҮәжқҘзҡ„е“ҲеёҢз Ғд№ҹдёҚдёҖж ·гҖӮе“ҲеёҢзҙўеј•е°ҶжүҖжңүзҡ„е“ҲеёҢз ҒеӯҳеӮЁеңЁзҙўеј•дёӯпјҢеҗҢж—¶еңЁhashиЎЁдёӯдҝқеӯҳжҢҮеҗ‘жҜҸдёӘж•°жҚ®иЎҢзҡ„жҢҮй’ҲгҖӮ
еҲӣе»әиЎЁtest_hashпјҢе®ғзҡ„еӯҳеӮЁеј•ж“ҺдёәmemoryпјҢзҙўеј•дёәfull_nameпјҢзҙўеј•зұ»еһӢдёәhashгҖӮ
CREATE TABLE `test_hash` ( `full_name` varchar(255) DEFAULT NULL, `short_name` varchar(32) DEFAULT NULL, `age` int(11) DEFAULT NULL, KEY `idx` (`full_name`) USING HASH ) ENGINE=MEMORY DEFAULT CHARSET=utf8;
иЎЁдёӯзҡ„ж•°жҚ®еҰӮдёӢпјҡ
mysql> select * from test_hash; +-------------------+------------+------+ | full_name | short_name | age | +-------------------+------------+------+ | Dwayne Johnson | Johnson | NULL | | Taylor Swift | Taylor | NULL | | Leonardo DiCaprio | Leonardo | NULL | | Vin Diesel | Diesel | NULL | | Kobe Bryant | Kobe | NULL | +-------------------+------------+------+ 5 rows in set (0.00 sec)
йӮЈд№Ҳе“ҲеёҢзҙўеј•зҡ„ж•°жҚ®з»“жһ„еҸҜиғҪжҳҜпјҡ
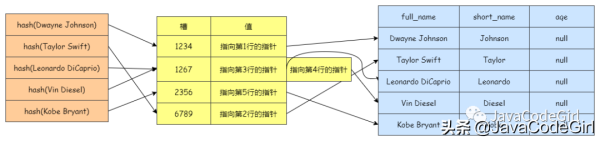
еҪ“жҲ‘们жү§иЎҢжҹҘиҜўиҜӯеҸҘпјҡ
mysql> select short_name from test_hash where full_name = 'Dwayne Johnson';
иҝҷдёӘsqlиҜӯеҸҘзҡ„жү§иЎҢжөҒзЁӢпјҡ
1)ж №жҚ®whereжқЎд»¶ 'Dwayne Johnson'и®Ўз®—еҮәе“ҲеёҢз ҒпјҢйӮЈд№Ҳеҫ—еҲ°зҡ„е“ҲеёҢз Ғдёә1234гҖӮ
2)MySQLеңЁзҙўеј•дёӯжҹҘжүҫеҲ°1234пјҢе№¶ж №жҚ®иҝҷдёӘеҖјжүҫеҲ°дәҶеҜ№еә”зҡ„иЎҢи®°еҪ•жҢҮй’ҲгҖӮ
3)ж №жҚ®жҢҮй’Ҳең°еқҖжүҫеҲ°еҜ№еә”зҡ„иЎҢпјҢжңҖеҗҺжҜ”иҫғиҝҷдёӘиЎҢдёӯзҡ„full_nameеҲ—жҳҜеҗҰдёә'Dwayne Johnson'гҖӮ
йӮЈзҺ°еңЁжңүдёӘй—®йўҳпјҢе“ҲеёҢз ҒеҶІзӘҒзҡ„ж—¶еҖҷжҖҺд№ҲеҠһе‘ў?еӯҰиҝҮHashMapзҡ„е°ҸдјҷдјҙжӯӨж—¶иӮҜе®ҡзҒөжңәдёҖеҠЁпјҡе“ҲеёҢз ҒеҶІзӘҒзҡ„ж—¶еҖҷдҪҝз”Ёй“ҫиЎЁгҖӮеҜ№зҡ„пјҢеҪ“й”®еҖјзҡ„е“ҲеёҢз ҒеҶІзӘҒзҡ„ж—¶еҖҷпјҢMySQLд№ҹжҳҜдҪҝз”Ёзҡ„й“ҫиЎЁз»“жһ„гҖӮеҰӮжһңжҳҜй“ҫиЎЁз»“жһ„пјҢеңЁжҹҘжүҫзҡ„ж—¶еҖҷе°ұйңҖиҰҒйҒҚеҺҶжҜҸдёӘй“ҫиЎЁжҢҮй’ҲжҢҮеҗ‘зҡ„иЎҢи®°еҪ•еҒҡеҢ№й…ҚпјҢжүҖд»Ҙе“ҲеёҢеҶІзӘҒжҜ”иҫғеӨ§зҡ„ж—¶еҖҷжҹҘжүҫзҡ„ж•ҲзҺҮжҳҜжҜ”иҫғдҪҺзҡ„гҖӮ
д»ҺдёҠйқўзҡ„зӨәдҫӢжҲ‘们еҸҜд»ҘзңӢеҮәпјҢе“ҲеёҢзҙўеј•зҡ„з»“жһ„дёӯеҸӘеӯҳеӮЁдәҶе“ҲеёҢеҖјпјҢе®ғзҡ„з»“жһ„жҳҜжҜ”иҫғзҙ§еҮ‘зҡ„пјҢеҜ№дәҺзІҫзЎ®жҹҘиҜўзҡ„ж•ҲзҺҮжҳҜжҜ”иҫғеҝ«зҡ„гҖӮ
дҪҶжҳҜе“ҲеёҢзҙўеј•иҝҳжҳҜжңүдәӣйҷҗеҲ¶зҡ„пјҡ
е“ҲеёҢзҙўеј•дёӯеӯҳеӮЁзҡ„жҳҜй”®еҖјзҡ„е“ҲеёҢеҖјпјҢе®ғдёҚжҳҜжҢүз…§зҙўеј•еҲ—зҡ„йЎәеәҸзҡ„пјҢжүҖд»Ҙе®ғдёҚж— жі•з”ЁдәҺжҺ’еәҸгҖӮ
е“ҲеёҢзҙўеј•дёҚж”ҜжҢҒйғЁеҲҶзҙўеј•еҢ№й…ҚжҹҘжүҫпјҢеӣ дёәе“ҲеёҢзҙўеј•е§Ӣз»ҲжҳҜзҙўеј•еҲ—зҡ„е…ЁйғЁеҶ…е®№гҖӮеҰӮжһңжҲ‘们зҙўеј•жңүдёӨдёӘеҲ—(AпјҢB)пјҢжҹҘиҜўзҡ„ж—¶еҖҷеҸӘжғідҪҝз”ЁAеҲ—пјҢиҝҷдёӘж—¶еҖҷжҳҜж— жі•еә”з”Ёзҙўеј•зҡ„гҖӮ
е“ҲеёҢзҙўеј•еҸӘж”ҜжҢҒзӯүеҖјжҹҘиҜўпјҢжҜ”еҰӮ=гҖҒinзӯүпјҢе®ғдёҚж”ҜжҢҒд»»дҪ•иҢғеӣҙжҹҘиҜўгҖӮ
еҪ“е“ҲеёҢеҶІзӘҒзҡ„ж—¶еҖҷпјҢеӯҳеӮЁеј•ж“Һеҝ…йЎ»иҰҒйҒҚеҺҶй“ҫиЎЁдёӯзҡ„жүҖжңүиЎҢжҢҮй’ҲпјҢйҖҗиЎҢжҜ”иҫғпјҢзӣҙеҲ°жүҫеҲ°жүҖжңүз¬ҰеҗҲжқЎд»¶зҡ„иЎҢпјҢеҰӮжһңе“ҲеёҢеҶІзӘҒжҜ”иҫғеӨҡзҡ„ж—¶еҖҷпјҢзҙўеј•з»ҙжҠӨзҡ„д»Јд»·жҜ”иҫғй«ҳгҖӮ
еңЁMySQLдёӯпјҢзӣ®еүҚеҸӘжңүmemoryеј•ж“ҺжҳҫејҸж”ҜжҢҒе“ҲеёҢзҙўеј•гҖӮ
InnoDBзҙўеј•жЁЎеһӢ
жҲ‘们еүҚйқўжҸҗеҲ°пјҢInnoDBзҡ„зҙўеј•з»“жһ„жҳҜB+TeeпјҢе®ғжҳҜд»Ҙдё»й”®еј•з”Ёиў«зҙўеј•зҡ„иЎҢгҖӮжүҖд»ҘеңЁInnoDBдёӯпјҢиЎЁйғҪжҳҜж №жҚ®дё»й”®йЎәеәҸд»Ҙзҙўеј•зҡ„еҪўејҸеӯҳж”ҫзҡ„пјҢжҜҸдёҖдёӘзҙўеј•еңЁInnoDBйҮҢйқўеҜ№еә”дёҖжЈөB+ж ‘гҖӮ
B+Treeзҙўеј•
B+TreeжҳҜжҲ‘们еүҚйқўжҸҗеҲ°зҡ„B-Treeзҡ„жү©еұ•пјҢB-Treeзҡ„жҜҸдёҖдёӘиҠӮзӮ№йғҪеҢ…еҗ«дәҶж•°жҚ®йЎ№пјҢиҝҷж ·жҜҸдёҖеқ—зЈҒзӣҳеӯҳеӮЁзҡ„зҙўеј•еҖје°ұдјҡжҜ”иҫғе°‘пјҢж ‘зҡ„й«ҳеәҰе°ұдјҡеҸҳеӨ§пјҢжҹҘиҜўзҡ„зЈҒзӣҳI/Oж¬Ўж•°е°ұдјҡеўһеҠ гҖӮ
йӮЈB+TreeжҳҜжҖҺд№Ҳж ·зҡ„ж•°жҚ®з»“жһ„е‘ў?дёӢеӣҫжҳҜB+Treeзҡ„жҠҪиұЎеӣҫпјҡ
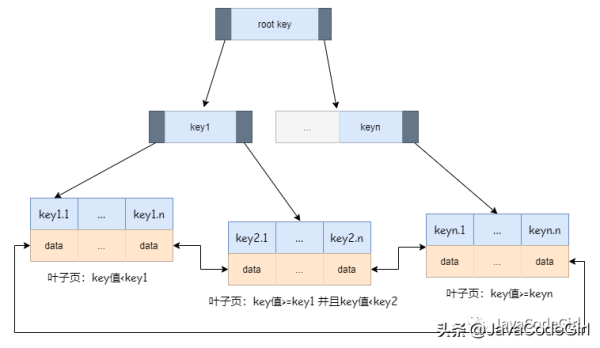
B+TreeдёҺB-Treeзҡ„еҢәеҲ«пјҡ
B+Treeзҡ„йқһеҸ¶еӯҗиҠӮзӮ№дёҚдҝқеӯҳж•°жҚ®дҝЎжҒҜпјҢеҸӘдҝқеӯҳзҙўеј•еҖје’ҢжҢҮеҗ‘дёӢдёҖеұӮиҠӮзӮ№зҡ„жҢҮй’ҲгҖӮ
B+Treeзҡ„еҸ¶еӯҗиҠӮзӮ№дҝқеӯҳдәҶж•°жҚ®
B+Treeзҡ„еҸ¶еӯҗиҠӮзӮ№жҳҜйЎәеәҸжҺ’еҲ—зҡ„пјҢ并且еҸ¶еӯҗзӣёйӮ»иҠӮзӮ№д№Ӣй—ҙжңүжҢҮй’Ҳзҡ„дә’зӣёеј•з”Ё
B+TreeиғҪеӨҹжӣҙеҘҪең°й…ҚеҗҲзЈҒзӣҳзҡ„иҜ»еҶҷзү№жҖ§пјҢеҮҸе°‘еҚ•ж¬ЎжҹҘиҜўзҡ„зЈҒзӣҳи®ҝй—®ж¬Ўж•°гҖӮ
InnoDBзҡ„зҙўеј•зұ»еһӢеҲҶдёәдё»й”®зҙўеј•е’Ңйқһдё»й”®зҙўеј•гҖӮ
дё»й”®зҙўеј•е’Ңйқһдё»й”®зҙўеј•
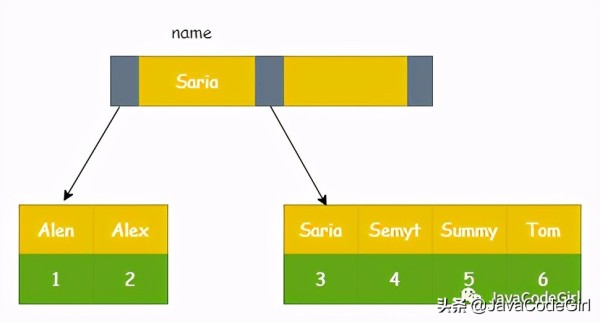
еҲӣе»әиЎЁuserпјҢе®ғзҡ„еӯҳеӮЁеј•ж“ҺдёәInnoDBпјҢidдёәдё»й”®пјҢnameдёәжҷ®йҖҡзҙўеј•гҖӮ
CREATE TABLE `user` ( `id` int(10) NOT NULL, `name` varchar(32) DEFAULT NULL, `age` int(3) DEFAULT NULL, `sex` varchar(1) DEFAULT NULL, `comment` varchar(255) DEFAULT NULL, `date` date DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx` (`name`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
иЎЁдёӯзҡ„ж•°жҚ®еҰӮдёӢ:
mysql> select * from user; +----+-------+------+------+---------+------------+ | id | name | age | sex | comment | date | +----+-------+------+------+---------+------------+ | 1 | Alen | 20 | 1 | NULL | 2021-02-16 | | 2 | Alex | 21 | 1 | NULL | 2021-02-16 | | 3 | Saria | 16 | 0 | NULL | 2021-02-16 | | 4 | Semyt | 18 | 0 | NULL | 2021-02-16 | | 5 | Summy | 17 | 1 | NULL | 2021-02-16 | | 6 | Tom | 19 | 0 | NULL | 2021-02-16 | +----+-------+------+------+---------+------------+ 6 rows in set (0.00 sec)
дё»й”®зҙўеј•д№ҹз§°дёәиҒҡз°Үзҙўеј•пјҢе®ғзҡ„еҸ¶еӯҗиҠӮзӮ№йғҪеҢ…еҗ«дәҶдё»й”®еҖјгҖҒдәӢеҠЎIDгҖҒз”ЁдәҺдәӢеҠЎе’ҢMVCCзҡ„еӣһж»ҡжҢҮй’Ҳд»ҘеҸҠжүҖжңүеү©дҪҷзҡ„еҲ—гҖӮ
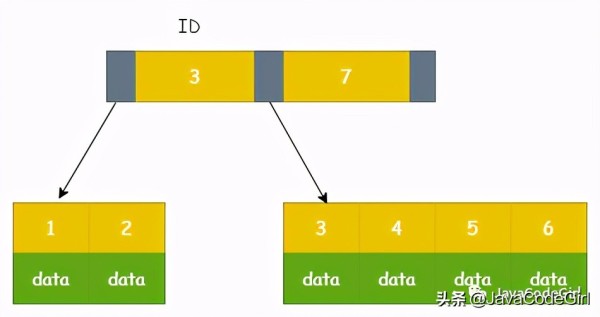
mysql> select * from user where id = 1;
дё»й”®зҙўеј•еҸӘйңҖиҰҒжҗңзҙўIDиҝҷжЈөB+Treeе°ұеҸҜд»ҘжӢҝеҲ°з¬ҰеҗҲжқЎд»¶зҡ„иЎҢи®°еҪ•гҖӮ
InnoDBжҳҜйҖҡиҝҮдё»й”®зҙўеј•иҒҡйӣҶж•°жҚ®пјҢеҰӮжһңиЎЁдёӯжІЎжңүе®ҡд№үдё»й”®пјҢInnoDBдјҡйҖүжӢ©дёҖдёӘе”ҜдёҖзҡ„йқһз©әзҙўеј•д»ЈжӣҝгҖӮеҰӮжһңжІЎжңүиҝҷж ·зҡ„зҙўеј•пјҢInnoDBдјҡйҡҗејҸе®ҡд№үдёҖдёӘдё»й”®жқҘдҪңдёәиҒҡз°Үзҙўеј•гҖӮиҝҷд№ҹжҳҜеӢҫеӢҫдёәжҜҸдёӘиЎЁйғҪеҲӣе»әдё»й”®зҡ„еҺҹеӣ гҖӮ
иҒҡз°Үзҙўеј•зҡ„дјҳзӮ№пјҡ
иҒҡз°Үзҙўеј•зҡ„зјәзӮ№пјҡ
еҰӮжһңж•°жҚ®йғҪеңЁеҶ…еӯҳдёӯпјҢиҒҡз°Үзҙўеј•зҡ„жҹҘиҜўжҖ§иғҪе°ұжІЎжңүйӮЈд№ҲеҘҪзҡ„дјҳеҠҝдәҶгҖӮ
жҸ’е…Ҙзҡ„йҖҹеәҰдёҘйҮҚдҫқиө–дәҺжҸ’е…ҘйЎәеәҸгҖӮе°ҪйҮҸдҝқиҜҒдё»й”®зҙўеј•жҳҜжңүеәҸзҡ„гҖӮ
жӣҙж–°иҒҡз°Үзҙўеј•еҲ—зҡ„д»Јд»·жӣҙй«ҳгҖӮ
еңЁжҸ’е…ҘиЎҢжҲ–иҖ…жӣҙж–°дё»й”®зҡ„ж—¶еҖҷеҜјиҮҙйңҖиҰҒ移еҠЁиЎҢзҡ„ж—¶еҖҷеҸҜиғҪеҜјиҮҙйЎөеҲҶиЈӮзҡ„й—®йўҳгҖӮеҪ“жҸ’е…ҘеҲ°дёҖдёӘе·Іж»Ўзҡ„йЎөдёӯпјҢеӯҳеӮЁеј•ж“Һдјҡе°ҶиҜҘйЎөеҲҶиЈӮдёәдёӨйЎөжқҘе®№зәіж•°жҚ®пјҢйЎөеҲҶиЈӮдјҡеҜјиҮҙеҚ з”ЁжӣҙеӨҡзҡ„зЈҒзӣҳз©әй—ҙгҖӮ
йқһдё»й”®зҙўеј•д№ҹз§°дёәйқһиҒҡз°Үзҙўеј•пјҢеңЁInnoDBдёӯеҸҲиў«з§°дёәдәҢзә§зҙўеј•гҖӮйқһдё»й”®зҙўеј•зҡ„еҸ¶еӯҗиҠӮзӮ№еҶ…е®№жҳҜдё»й”®зҡ„еҖјгҖӮ
mysql> select * from user where name = 'Alen';
йқһдё»й”®зҙўеј•жҹҘиҜўж—¶пјҢйҰ–е…Ҳж №жҚ®nameжҷ®йҖҡжҹҘиҜўжҗңзҙўnameзҙўеј•ж ‘пјҢжүҫеҲ°idдёә1пјҢеҶҚж №жҚ®id=1еҲ°IDзҙўеј•ж ‘жҹҘиҜўдёҖж¬ЎжүҚиғҪиҺ·еҸ–еҲ°з¬ҰеҗҲжқЎд»¶зҡ„иЎҢи®°еҪ•гҖӮ
жҲ‘们жҠҠе…Ҳжҗңзҙўжҷ®йҖҡзҙўеј•ж ‘еҫ—еҲ°дё»й”®пјҢеҶҚжҗңзҙўдё»й”®зҙўеј•ж ‘зҡ„иҝҮзЁӢз§°дёәеӣһиЎЁгҖӮ
жҷ®йҖҡзҙўеј•зҡ„жҹҘиҜўжҜ”дё»й”®зҙўеј•еӨҡжЈҖзҙўдәҶдёҖжЈөB+TreeпјҢеңЁе®һйҷ…еә”з”ЁеңәжҷҜдёӢеҰӮжһңиғҪз”ЁеҲ°дё»й”®зҙўеј•е°ҪйҮҸйҖүжӢ©дё»й”®зҙўеј•гҖӮ
еңЁеҲӣе»әзҙўеј•зҡ„ж—¶еҖҷиҝҳжңүе…¶д»–зҡ„еҺҹеҲҷпјҢжҲ‘们жҺҘдёӢжқҘ继з»ӯеӯҰд№ й«ҳжҖ§иғҪзҡ„зҙўеј•зӯ–з•ҘгҖӮ
зҙўеј•зӯ–з•Ҙ
е°Ҹдјҷдјҙ们еңЁеӯҰд№ зҙўеј•зӯ–з•Ҙзҡ„ж—¶еҖҷеҸҜд»ҘеҲ©з”ЁдёҠдёҖзҜҮж–Үз« зҡ„explianе…ій”®еӯ—жҹҘиҜўжү§иЎҢи®ЎеҲ’гҖӮ
зҙўеј•зҡ„йҖүжӢ©
зҙўеј•зҡ„еҲҶзұ»жңүеӨҡз§ҚпјҢжҲ‘们еҸҜд»ҘжҢүз…§зҙўеј•еӯ—ж®өзҡ„дёӘж•°е°Ҷзҙўеј•еҲҶдёәеҚ•еҲ—зҙўеј•е’ҢиҒ”еҗҲзҙўеј•гҖӮ
еҚ•еҲ—зҙўеј•пјҡдёҖдёӘзҙўеј•еҸӘеҢ…еҗ«дёҖдёӘеҲ—пјҢдёҖдёӘиЎЁдёӯеҸҜд»ҘеӨҡдёӘеҚ•еҲ—зҙўеј•гҖӮ
иҒ”еҗҲзҙўеј•пјҡдёҖдёӘзҙўеј•еҢ…еҗ«еӨҡдёӘеҲ—гҖӮ
жҲ‘们иҝҳеҸҜд»Ҙе°Ҷзҙўеј•еҲҶдёәжҷ®йҖҡзҙўеј•гҖҒе”ҜдёҖзҙўеј•е’Ңдё»й”®зҙўеј•гҖӮ
жҷ®йҖҡзҙўеј•пјҡеҹәжң¬зҡ„зҙўеј•зұ»еһӢпјҢеёёз”ЁжқҘжҸҗй«ҳжҹҘиҜўж•ҲзҺҮпјҢеҜ№ж•°жҚ®жІЎжңүйҷҗеҲ¶гҖӮе…Ғи®ёеңЁзҙўеј•еҲ—дёӯжҸ’е…Ҙз©әеҖје’ҢйҮҚеӨҚеҖјгҖӮ
е”ҜдёҖзҙўеј•пјҡзҙўеј•еҲ—дёӯзҡ„еҖјеҝ…йЎ»жҳҜе”ҜдёҖзҡ„пјҢе…Ғи®ёеӯҳеңЁз©әеҖјгҖӮ
дё»й”®зҙўеј•пјҡдёҚе…Ғи®ёз©әеҖјзҡ„зү№ж®Ҡзҡ„е”ҜдёҖзҙўеј•гҖӮ
зҙўеј•жңүиҝҷд№ҲеӨҡеҲҶзұ»пјҢжҲ‘们еңЁеҲӣе»әзҙўеј•зҡ„ж—¶еҖҷеҰӮдҪ•йҖүжӢ©е‘ў?
зҙўеј•зҡ„дёүжҳҹзі»з»ҹпјҡ
дёҖжҳҹпјҡзҙўеј•зӣёе…ізҡ„и®°еҪ•ж”ҫеҲ°дёҖиө·гҖӮ
дәҢжҳҹпјҡзҙўеј•дёӯзҡ„ж•°жҚ®йЎәеәҸе’ҢжҹҘжүҫеҲ—дёӯзҡ„йЎәеәҸдёҖиҮҙгҖӮ
дёүжҳҹпјҡзҙўеј•зҡ„еҲ—еҢ…еҗ«дәҶжҹҘиҜўдёӯйңҖиҰҒзҡ„е…ЁйғЁеҲ—гҖӮ
жӯЈзЎ®зҡ„еҲӣе»әе’ҢдҪҝз”Ёзҙўеј•жҳҜе®һзҺ°й«ҳжҖ§иғҪжҹҘиҜўзҡ„еҹәзЎҖгҖӮзҙўеј•зҡ„йҖүжӢ©жІЎжңүз»қеҜ№зҡ„иҰҒжұӮпјҢдё»иҰҒжҳҜж №жҚ®иҮӘе·ұзҡ„дёҡеҠЎйңҖжұӮпјҢдҪҶжҳҜжңүдәӣеҺҹеҲҷжҲ‘们еңЁеҲӣе»әзҙўеј•зҡ„ж—¶еҖҷеҸҜд»ҘдҪңдёәеҸӮиҖғгҖӮ
зҙўеј•еҲ—зҡ„еҢәеҲҶеәҰи¶Ҡй«ҳеҲҷжҹҘиҜўж•ҲзҺҮи¶Ҡй«ҳгҖӮ
е°Ҷйў‘з№Ғжҗңзҙўзҡ„еҲ—еҠ е…Ҙзҙўеј•пјҢеҸҜд»ҘжҸҗй«ҳжҗңзҙўж•ҲзҺҮгҖӮ
зҙўеј•дёҚеҸӘжҸҗй«ҳдәҶжҹҘиҜўж•ҲзҺҮпјҢд№ҹеҸҜд»ҘеҸӮдёҺжҺ’еәҸе’ҢеҲҶз»„пјҢз»Ҹеёёз”ЁжқҘжҺ’еәҸе’ҢеҲҶз»„зҡ„еӯ—ж®өд№ҹйңҖиҖғиҷ‘еҠ е…Ҙзҙўеј•гҖӮ
еҲӣе»әзҙўеј•ж—¶пјҢеә”е°ҶеҢәеҲҶеәҰй«ҳзҡ„еӯ—ж®өжҺ’еңЁеүҚйқўгҖӮеҚійңҖиҰҒжіЁж„Ҹзҙўеј•еӯ—ж®өзҡ„йЎәеәҸгҖӮ
зҙўеј•еҲ—дёҚиғҪеҸӮдёҺд»»дҪ•иҝҗз®—гҖӮ
йҒҝе…ҚеҲӣе»әйҮҚеӨҚзҙўеј•пјҢеҚіеңЁеҗҢдёҖдёӘеҲ—дёҠжҢүз…§зӣёеҗҢзҡ„йЎәеәҸеҲӣе»әзӣёеҗҢзұ»еһӢзҡ„зҙўеј•гҖӮ
еҜ№дәҺд»ҺжңӘдҪҝз”Ёзҡ„зҙўеј•пјҢеә”е°ҪйҮҸеҲ йҷӨгҖӮ
еҜ№дәҺblobгҖҒtextжҲ–иҖ…й•ҝvarcharзұ»еһӢзҡ„еҲ—пјҢеҝ…йЎ»иҰҒдҪҝз”ЁеүҚзјҖзҙўеј•пјҢеҸ–жңҖеӨҹй•ҝзҡ„еүҚзјҖжқҘдҝқиҜҒиҫғй«ҳзҡ„еҢәеҲҶеәҰгҖӮ
жҷ®йҖҡзҙўеј•е’Ңе”ҜдёҖзҙўеј•еңЁжҹҘиҜўж•ҲзҺҮдёҠе·®еҲ«е№¶дёҚеӨ§пјҢеӣ дёәеј•ж“ҺжҳҜжҢүз…§йЎөиҜ»еҸ–ж•°жҚ®гҖӮеҜ№дәҺе”ҜдёҖзҙўеј•еңЁжҹҘиҜўзҡ„ж—¶еҖҷеҸӘиҰҒжүҫеҲ°е°ұдёҚеҶҚ继з»ӯжҜ”иҫғдәҶпјҢеӣ дёәзҙўеј•е·Із»ҸдҝқиҜҒдәҶе”ҜдёҖжҖ§гҖӮиҖҢеҜ№дәҺжҷ®йҖҡзҙўеј•еҲҷеңЁжүҫеҲ°ж»Ўи¶іжқЎд»¶зҡ„и®°еҪ•еҗҺиҝҳйңҖиҰҒ继з»ӯжҹҘжүҫзӣҙеҲ°жүҫеҲ°дёҚж»Ўи¶іжқЎд»¶зҡ„第дёҖжқЎи®°еҪ•пјҢдҪҶжҳҜеҜ№дәҺжҢүз…§йЎөиҜ»еҸ–ж•°жҚ®зҡ„еј•ж“ҺжқҘиҜҙпјҢеӨҡдёҖж¬Ўзҡ„еҲӨж–ӯеҜ№жҖ§иғҪзҡ„еҪұе“Қиҫғе°ҸгҖӮжҷ®йҖҡзҙўеј•е’Ңе”ҜдёҖзҙўеј•зҡ„йҖүжӢ©йҷӨдәҶдҝқиҜҒдёҡеҠЎзҡ„еҮҶзЎ®жҖ§д№ӢеӨ–пјҢе…¶д»–жӣҙеӨҡзҡ„иҖғиҷ‘жӣҙж–°ж•°жҚ®ж—¶еҜ№жҖ§иғҪзҡ„еҪұе“ҚгҖӮ
зӢ¬з«Ӣзҡ„еҲ—
вҖқзӢ¬з«Ӣзҡ„еҲ—вҖңжҳҜжҢҮзҙўеј•дёҚиғҪжҳҜиЎЁиҫҫејҸзҡ„дёҖйғЁеҲҶпјҢд№ҹдёҚиғҪжҳҜеҮҪж•°зҡ„еҸӮж•°гҖӮ
дҫӢеҰӮпјҢеҰӮдёӢsqlиҜӯеҸҘпјҢеңЁжҹҘиҜўж—¶зҙўеј•еӯ—ж®өnameеҸӮдёҺдәҶеҮҪж•°иҝҗз®—пјҢдјҡеҜјиҮҙзҙўеј•еӨұж•ҲпјҢе…ЁиЎЁжү«жҸҸгҖӮ
mysql> select * from user where CONCAT(name,'n') = 'Alen';
ж·»еҠ зҙўеј•ageеӯ—ж®өпјҢеҰӮжһңжҲ‘们еңЁжҹҘиҜўзҡ„ж—¶еҖҷеҜ№ageеӯ—ж®өиҝӣиЎҢдәҶиҝҗз®—д№ҹдјҡеҜјиҮҙзҙўеј•еӨұж•Ҳпјҡ
mysql> select * from user where age + 1 = 21;
жҲ‘们平时ејҖеҸ‘дёӯиҰҒе…»жҲҗз®ҖеҢ–whereжқЎд»¶зҡ„д№ жғҜпјҢе§Ӣз»ҲдҪҝз”ЁеҚ•зӢ¬зҡ„зҙўеј•еҲ—гҖӮ
иҰҶзӣ–зҙўеј•
еҰӮжһңжҲ‘们жҠҠжҢүз…§жҷ®йҖҡзҙўеј•жҹҘиҜўзҡ„sqlиҜӯеҸҘдҝ®ж”№еҰӮдёӢ:
mysql> select name from user where name like 'Al%';
иҝҷж—¶еҸӘйңҖиҰҒжҹҘиҜўжҷ®йҖҡзҙўеј•ж ‘еҚіеҸҜеҫ—еҲ°иҰҒжҹҘиҜўзҡ„еҲ—пјҢеӣ дёәиҰҒжҹҘиҜўзҡ„еҲ—е·Із»ҸеңЁзҙўеј•ж ‘дәҶпјҢиҖҢдёҚйңҖиҰҒеҶҚеӣһиЎЁжҹҘиҜўгҖӮ
иҝҷз§Қзҙўеј•еӯ—ж®өиҰҶзӣ–дәҶжҲ‘们йңҖиҰҒжҹҘиҜўзҡ„з»“жһңеӯ—ж®өзҡ„еңәжҷҜжҲ‘们称дёәиҰҶзӣ–зҙўеј•гҖӮ
иҰҶзӣ–зҙўеј•еҸҜд»ҘеҮҸе°‘еӣһиЎЁпјҢеҮҸе°‘зҙўеј•ж ‘зҡ„жҗңзҙўж¬Ўж•°пјҢжҳҫи‘—жҸҗй«ҳжҹҘиҜўжҖ§иғҪпјҢжүҖд»ҘиҰҶзӣ–зҙўеј•жҳҜдёҖдёӘжҜ”иҫғеҘҪзҡ„дјҳеҢ–зӯ–з•ҘгҖӮ
еңЁе®һйҷ…ејҖеҸ‘дёӯпјҢеҸҜд»ҘжҢүз…§дёҡеҠЎйңҖиҰҒжҠҠдёҖдәӣеёёз”Ёзҡ„жЈҖзҙўеӯ—ж®өж·»еҠ еҲ°зҙўеј•дёӯпјҢеҲ©з”ЁиҰҶзӣ–зҙўеј•жҸҗй«ҳжҹҘиҜўж•ҲзҺҮпјҢдҪҶжҳҜжңүдәӣеңәжҷҜдёӢдёҚиғҪдёәдәҶдҪҝз”ЁиҰҶзӣ–зҙўеј•иҖҢиҝҮеӨҡзҡ„з»ҙжҠӨзҙўеј•пјҢжҜ•з«ҹзҙўеј•зҡ„з»ҙжҠӨжҲҗжң¬д№ҹжҳҜеҫҲй«ҳзҡ„гҖӮ
жңҖе·ҰеүҚзјҖ
иҝҷдёӘж—¶еҖҷжҲ‘们иҝҳйңҖиҰҒжҖқиҖғдёҖдёӘй—®йўҳпјҢеңЁдёҡеҠЎеңәжҷҜдёӯжҲ‘们зҡ„жҹҘиҜўжҳҜеӨҡж ·еҢ–зҡ„пјҢдёҚиғҪдёәдәҶдҪҝз”Ёзҙўеј•иҖҢдёәжҜҸдёҖз§ҚеңәжҷҜйғҪи®ҫи®ЎдёҖдёӘзҙўеј•еҗ§?
иҝҷдёӘж—¶еҖҷжҲ‘们е°ұиҰҒеҲ©з”ЁB+Treeж ‘зҙўеј•з»“жһ„зҡ„еҸҰеӨ–дёҖдёӘзү№жҖ§жңҖе·ҰеүҚзјҖгҖӮ
жңҖе·ҰеүҚзјҖеҸҜд»ҘжҳҜиҒ”еҗҲзҙўеј•зҡ„жңҖе·Ұзҡ„еҮ дёӘеӯ—ж®өпјҢд№ҹеҸҜд»ҘжҳҜеӯ—з¬ҰдёІзҙўеј•зҡ„жңҖе·Ұзҡ„еҮ дёӘеӯ—з¬ҰгҖӮ
еҲӣе»әиҒ”еҗҲзҙўеј•(name,age)пјҢйЎәеәҸдёҖиҮҙгҖӮ
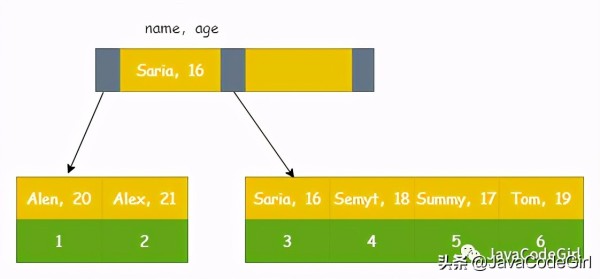
жӯӨж—¶жү§иЎҢsqlиҜӯеҸҘпјҡ
mysql> select * from user where name = 'Alen';
иҷҪ然жҳҜиҒ”еҗҲзҙўеј•пјҢдҪҶжҳҜnameеӯ—ж®өжҺ’еңЁз¬¬дёҖдҪҚпјҢд№ҹжҳҜеҸҜд»Ҙе‘Ҫдёӯзҙўеј•зҡ„гҖӮ
mysql> select * from user where name like 'Al%';
еҰӮжһңдҪҝз”Ёnameзҙўеј•еӯ—ж®өзҡ„жңҖе·ҰNдёӘеӯ—з¬ҰдёІпјҢд№ҹжҳҜеҸҜд»Ҙе‘Ҫдёӯзҙўеј•зҡ„гҖӮдҪҶжҳҜеҰӮжһңжҲ‘们дҪҝз”Ё%AlжҳҜдёҚиғҪе‘Ҫдёӯзҙўеј•зҡ„гҖӮ
еҰӮжһңжҲ‘们дҪҝз”ЁеҰӮдёӢзҡ„sqlжҹҘиҜўиҜӯеҸҘпјҡ
mysql> select * from user where age = '16'пјӣ
иҷҪ然ageд№ҹжҳҜиҒ”еҗҲзҙўеј•зҡ„еӯ—ж®өпјҢдҪҶжҳҜд»–зҡ„йЎәеәҸеңЁnameд№ӢеҗҺпјҢзӣҙжҺҘдҪҝз”ЁageжҹҘиҜўж— жі•е‘Ҫдёӯзҙўеј•гҖӮжүҖд»ҘеҲӣе»әиҒ”еҗҲзҙўеј•ж—¶дёҖе®ҡиҰҒиҖғиҷ‘зҙўеј•еӯ—ж®өзҡ„йЎәеәҸгҖӮ
зҙўеј•з»ҙжҠӨж—¶жңүдёҖдёӘеҺҹеҲҷпјҡеҰӮжһңиғҪйҖҡиҝҮи°ғж•ҙзҙўеј•йЎәеәҸпјҢеҸҜд»Ҙе°‘з»ҙжҠӨдёҖдёӘзҙўеј•пјҢйӮЈд№Ҳе°ұйңҖиҰҒдјҳе…Ҳи°ғж•ҙйЎәеәҸиҖҢдёҚжҳҜеўһеҠ зҙўеј•гҖӮ
MySQLеҸҜд»ҘеҲ©з”ЁеҗҢдёҖдёӘзҙўеј•иҝӣиЎҢжҺ’еәҸе’Ңжү«жҸҸиЎҢпјҢдҪҶжҳҜеҸӘжңүеҪ“зҙўеј•зҡ„еҲ—йЎәеәҸе’Ңorder byеӯҗеҸҘзҡ„йЎәеәҸе®Ңе…ЁдёҖиҮҙпјҢ并且еҲ—зҡ„жҺ’еәҸж–№еҗ‘йғҪдёҖиҮҙ(жӯЈеәҸжҲ–иҖ…еҖ’еәҸ)ж—¶пјҢMySQLжүҚиғҪдҪҝз”ЁеҜ№з»“жһңиҝӣиЎҢжҺ’еәҸгҖӮ
order byеӯҗеҸҘе’ҢжҹҘиҜўзұ»еһӢйҷҗеҲ¶жҳҜдёҖж ·зҡ„пјҢд№ҹйңҖиҰҒж»Ўи¶івҖқжңҖе·ҰеүҚзјҖвҖңзҡ„еҺҹеҲҷпјҢеҗҰеҲҷMySQLж— жі•еҲ©з”Ёзҙўеј•жҺ’еәҸгҖӮ
зҙўеј•дёӢжҺЁ
еҪ“жҲ‘们зҡ„жҹҘиҜўиҜӯеҸҘдёҚж»Ўи¶іжңҖе·ҰеүҚзјҖзҡ„ж—¶еҖҷдјҡеҰӮдҪ•е‘ў?
жҜ”еҰӮжҲ‘们жҹҘиҜўеҗҚеӯ—第дёҖдёӘеӯ—дёәAпјҢе№ҙйҫ„дёә20пјҢ并且жҖ§еҲ«дёә1(з”·)зҡ„дәәе‘ҳдҝЎжҒҜпјҢsqlиҜӯеҸҘеҰӮдёӢпјҡ
mysql> select * from user where name like 'A%' and age = 20 and sex = 1 ;
жҢүз…§жҲ‘们еүҚйқўеӯҰд№ зҡ„жңҖе·ҰеүҚзјҖеҺҹеҲҷпјҢжҢүз…§’A‘е…ҲжҗңзҙўеҲ°з¬¬дёҖдёӘж»Ўи¶іжқЎд»¶зҡ„дё»й”®1пјҢ然еҗҺеӣһиЎЁжҹҘиҜўеҲӨж–ӯе…¶д»–зҡ„дёӨдёӘжқЎд»¶жҳҜеҗҰж»Ўи¶ігҖӮ
MySQL5.6д№ӢеҗҺеј•е…ҘдәҶзҙўеј•дёӢжҺЁзҡ„дјҳеҢ–пјҢеҚідјҡжҢүз…§зҙўеј•дёӯеҢ…еҗ«зҡ„еӯ—ж®өдјҳе…ҲиҝҮж»ӨпјҢеҮҸе°‘еӣһиЎЁзҡ„ж¬Ўж•°гҖӮ
жҲ‘们дёҠиҝ°зҡ„sqlиҜӯеҸҘеңЁMySQL5.6д№ӢеүҚдјҡеӣһиЎЁ2ж¬ЎеҲҶеҲ«еҜ№жҜ”дё»й”®1е’Ң2дёӨжқЎзҡ„ж•°жҚ®зҡ„е…¶д»–жқЎд»¶жҳҜеҗҰж»Ўи¶іпјҢдҪҶжҳҜеј•е…Ҙзҙўеј•дёӢжҺЁзҡ„дјҳеҢ–д№ӢеҗҺage = 20иҝҷдёӘжқЎд»¶дёҚж»Ўзҡ„дјҡзӣҙжҺҘиҝҮж»ӨжҺүпјҢеҸӘйңҖиҰҒеҜ№дё»й”®1еӣһиЎЁдёҖж¬Ўе°ұеҸҜд»ҘиҺ·еҸ–еҲ°з»“жһңгҖӮ
дёҠиҝ°еҶ…е®№е°ұжҳҜMySQLдёӯжҖҺд№Ҳе®һзҺ°й«ҳжҖ§иғҪзҙўеј•пјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





