这期内容当中小编将会给大家带来有关如何采用分段排查法诊断服务器性能,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
在日常性能测试中,我们需要掌握一些常用的策略以及有必要了解和掌握查看服务器性能的命令,来排查诊断服务器性能。
今天,就和大家分享一下在压测过程中,采用分段排查法快速利用命令去诊断服务器的性能。

Linux服务器分段排查的方法,按照CPU、内存、磁盘IO、网络的先后顺序依次排除。参考流程图如下:
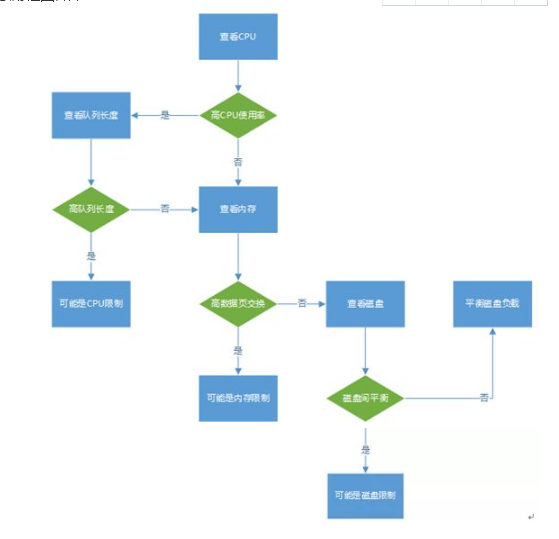
分析步骤:
Step1 用top查看系统大致情况:
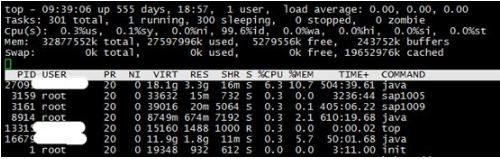
关注cpu(sys+us)使用率,若此值持续大于80%,可以观察进程视图,是否是非核心应用进程占用大量CPU资源,若能排除非核心应用进程的影响,则基本能确定该系统cpu资源面临短缺,此时结合vmstat监控观察到proc列r值应该较大;同理,当cpu利用率很低,但运行进程队列(r值)却很大时,表面cpu存在阻塞
关注%idle(cpu 空闲时间的百分比),若此值较高但系统响应却很慢时,有可能是CPU在等待分配内存,此时应关注内存使用情况(见step3);如果空闲时间%idle持续为0并且系统时间(cpu sy)是用户时间(cpu us)的两倍 ,系统则面临着CPU资源的短缺.
关注%wait(cpu等待 IO 的时间的百分比),在cpu资源尚未耗尽情况下,若此值持续很高表示系统存储IO可能存在瓶颈;问题原因可能是:(1)系统存在一个应用程序问题(应用本身有许多IO请求);(2)物理内存不足; (3)低效的 I/O 子系统配置; 此时应先排查是否是应用程序问题,然后检查系统内存使用情况,若是交换分页多,则确定是由物理内存不足引发的磁盘IO问题(见step3);若不是,则检查系统磁盘,结合iostat来验证此现象是由应用IO过多造成(见step4).
Step2 结合vmstat、sar监控cpu:

主要关注报告中的4个cpu列和2个procs(内核线程)列
r:等待在CPU资源的进程数。这个数据比平均负载更加能够体现CPU负载情况,数据中不包含等待IO的进程。如果这个数值大于系统中的逻辑CPU核数,表示系统现在运行比较慢,有多数的进程等待CPU,那么系统的CPU资源已经饱和。
us, sy, id, wa, st:这些都代表了CPU时间的消耗,它们分别表示用户时间(user)、系统(内核)时间(sys)、空闲时间(idle)、IO等待时间(wait)和被偷走的时间(stolen,一般被其他虚拟机消耗)。上述这些CPU时间,可以让我们很快了解CPU是否出于繁忙状态。一般情况下,如果用户时间和系统时间相加非常大,CPU出于忙于执行指令。如果IO等待时间很长,那么系统的瓶颈可能在磁盘IO。
sar –P ALL : 对cpu分开查询,统计每个cpu的使用情况,检查多个cpu的负载是否平衡
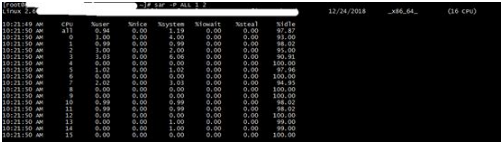
通过前两步,已能基本确定cpu是否存在瓶颈:
若cpu资源不足,可以调整应用程序对CPU的占用情况,使得应用程序能够更有效的使用CPU,同时可以考虑增加更多的CPU;
若cpu不是瓶颈,则着重查看系统内存。
Step3 用vmstat查看内存使用情况:

每行会输出一些系统核心指标,这些指标可以让我们更详细的了解系统状态。后面跟的参数1,表示每秒输出一次统计信息,参数2,表示一共输出2次统计信息。表头提示了每一列的含义,这只介绍一些和内存性能调优相关的列:
Memory区域
swpd:表示切换到内存交换区的内存大小,即虚拟内存已使用的大小(单位KB),如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free:表示当前空闲的物理内存(以千字节为单位), 如果剩余内存不足,也会导致系统性能问题。
buff:表示baffers cached内存大小,也就是缓冲大小,一般对块设备的读写才需要缓冲。
Cache:表示page cached的内存大小,也就是缓存大小,一般作为文件系统进行缓冲,频繁访问的文件都会被缓存,如果cache值非常大说明缓存文件比较多,如果此时io中的bi比较小,说明文件系统效率比较好。
Swap区域
si:表示有磁盘调入内存,也就是内存进入内存交换区的内存大小;通俗的讲就是 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。
so:表示由内存进入磁盘,也就是由内存交换区进入内存的内存大小。
注意:一般情况下si、so的值都为0,如果si、so的值长期不为0,则说明系统内存不足,需要增加系统内存。
Step4 用iostat查看磁盘IO

tps:该设备每秒的传输次数(Indicate the number of transfers persecond that were issued to the device.)。"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;
kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes
关注%iowait,如果 CPU 和内存受限的情况不存在,并且%iowait 长时间大于25%,则认为IO存在瓶颈。
收集磁盘IO数据吞吐量(iostat –d -k),大致估计系统数据吞吐量与应用负载是否相匹配,排查是否有与业务无关的大量IO操作。
Step5 使用sar –d 查看磁盘读写:
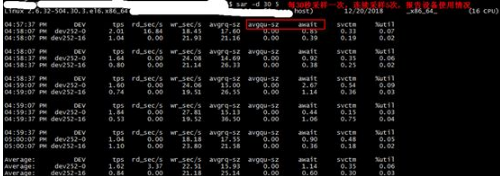
其中:
tps:每秒从物理磁盘I/O的次数.多个逻辑请求会被合并为一个I/O磁盘请求,一次传输的大小是不确定的。
rd_sec/s:每秒读扇区的次数。
wr_sec/s:每秒写扇区的次数。
avgrq-sz:平均每次设备I/O操作的数据大小(扇区)。
avgqu-sz:磁盘请求队列的平均长度。
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1秒=1000毫秒)。
svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间。
%util:I/O请求占CPU的百分比,比率越大,说明越饱和。
正常情况下avserv应该是小于avwait值的, 如果avserv的值与avwait很接近,表示几乎没有I/O等待,磁盘性能很好;如果avwait的值远高于avserv的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,磁盘IO为系统瓶颈。
Step6 使用netstat查看网络:
1、通过ping命令检测网络的连通性
2、通过netstat –nltp组合检测网络接口状况
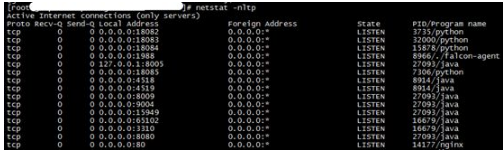
-u (udp)仅显示udp相关选项
-l 仅列出有在 Listen (监听) 的服务状态
-n 拒绝显示别名,能显示数字的全部转化成数字。
-t (tcp)仅显示tcp相关选项
-p 显示建立相关链接的程序名,
3、通过netstat –r组合检测系统的路由表信息
cpu瓶颈常见征兆:
很慢的响应时间
cpu空闲时间为零
过高的用户占用cpu时间
过高的系统占用cpu时间
长时间的有很长的运行进程队列
cpu调优方法:
平衡系统负载,在不同的期间运行进程,从而更有效地利用每天的24小时。
使用 nice 或 renice 优化调度程序——可为运行进程分配不同的优先级,以避免占用大量cpu资源。
增加资源,添加更多的cpu
内存瓶颈常见征兆:
很高的换页率
交换空间使用率很高
进程进入不活动状态;
交换区所有磁盘的活动次数很高;
很高的全局系统CPU利用率;
内存不够出错
内存调优方法:
保证交换空间分配合理(分配足够多的交换空间、每个交换空间大小相同、每个交换空间分配在不同的硬盘上)
参数调整,调整内存参数阀值
增加内存资源
IO瓶颈常见征兆:
过高的磁盘利用率
太长的磁盘等待队列
等待磁盘I/O的时间所占的百分率太高
太高的物理I/O速率
过低的缓存***率
太长的运行进程队列,但CPU却空闲
IO调优方法:
一般来说,高的%iowait 表明系统至少存在一个应用程序问题、缺少内存问题或低效的 I/O 子系统配置;
应检查应用程序产生大量IO请求是否正常;
检查是否是由于内存交换空间频繁换页引起的IO问题;
检查磁盘配置情况是否合理
针对磁盘IO本身的优化来说,尽管存在一些 I/O 优化参数的虚拟内存等价项,但是提高磁盘 I/O 性能的方法仍然是正确地配置Linux系统,而不仅仅是优化相关的参数。
上述就是小编为大家分享的如何采用分段排查法诊断服务器性能了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/k7psW3DQfnd0xyOklUgxnw



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



