这篇文章主要讲解了“为什么说共享数据库已成过去式了”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“为什么说共享数据库已成过去式了”吧!
共享数据库范式是一种常见的开发工作流程,即团队中的所有开发人员都共享某一个数据库的访问权限,都使用该数据库来支持应用程序开发。
这一工作流程很简单,无需为每个工程师配置基础架构,使安装成本降至最低,因而人们愿意选择它。但由于工程师做出改变的同时不得不承担着影响其他人工作的风险,它也会给工程师造成痛苦和瓶颈。
Spawn使我们能够轻松进行数据库配置,并使每个工程师都拥有自己专用的数据库环境,而无需配置任何额外的基础架构。
共享数据库
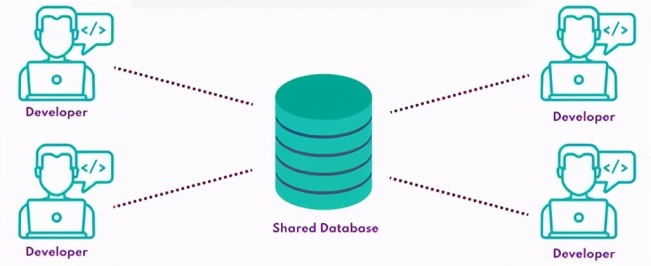
共享数据库通常包含一个生产数据库的副本(适当地被屏蔽以删除敏感数据,并且可能被子集化以缩小其规模),该副本由团队中的所有开发人员共享。共享数据库的好处是管理的基础架构更少,开发人员只需将连接字符串插入共享数据库即可快速启动并运行。
尽管这种设置对一个很小的团队或很少进行数据库更改的团队颇有作用,但它很快会遇到一些问题:
互踩:开发人员可能会尝试对共享数据库进行矛盾互斥的更改,存在抹去彼此工作的风险。
不能安全地迁移应用:更改一项功能的数据库架构可能会破坏其他代码。
未知状态:如果数据库的状态不受单个开发人员的控制,从一瞬间更改到下一瞬间,错误再现和应用程序测试将变得更加困难。
共享数据库模式日益落后,因为容器化使得数据库供应比以往任何时候都更容易,消除了基础设施供应的开销。
每个开发人员一个数据库
在这种模型下,团队中的每个开发人员都有自己的(隐藏的)生产数据库副本,可以根据该副本进行工作。这使开发人员可以单独更改其数据库副本,从而解决了由于争用共享数据库而引起的问题。
这在过去比较困难,因为我们必须为每个开发人员提供类似于生产的应用程序数据库的副本。但是,通过使用Spawn,我们可以从命令行配置临时数据库实例,而无需设置或托管任何其他基础架构:
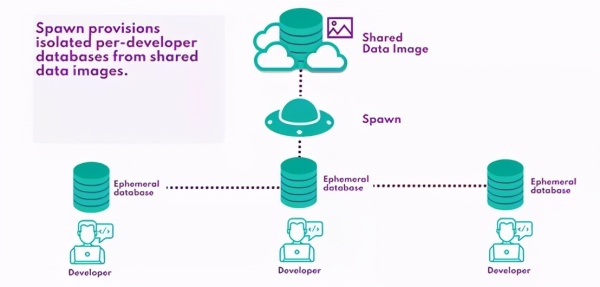
使用Spawn,我们可以每天从生产环境中创建一个数据映像(作为计划构建管道的一部分),并使此映像对开发人员和CI系统都可用——所有这些都使用Spawn CLI。可以从备份文件或脚本创建映像。
然后,每个开发人员都可以基于此映像配置自己的数据库,而不必像运行spawnctl create data-container
Spawn在幕后Kubernetes集群中创建并托管一个容器化的数据库实例,将开发团队从管理自己的数据库基础设施的负担中解脱出来,并获得专用数据库进行开发的所有好处:
快速提供任意规模的数据库:Spawn使用块级文件系统快照来恢复和写入数据库。这意味着即使是最大的映像也可以在几秒钟内配置完毕,并且保持高速写入。
快照和还原:可以使用Spawn CLI spawnctl save命令随时对数据库进行快照。使用spawnctlreset可恢复到以前的任何状态。无需担心数据库更改,因为它总是很容易还原。
无需基础设施:Spawn负责数据库的供应和托管,允许开发人员专注于代码。
同一映像的多个副本:一个映像可用于根据需要提供尽可能多的数据库——所有这些数据库都有自己的连接字符串,相互独立和分离。
感谢各位的阅读,以上就是“为什么说共享数据库已成过去式了”的内容了,经过本文的学习后,相信大家对为什么说共享数据库已成过去式了这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





