еӨ§иЎЁеҲҶеә“еҲҶиЎЁжҖ»з»“
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңеӨ§иЎЁеҲҶеә“еҲҶиЎЁжҖ»з»“вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
1.еүҚиЁҖ
дёәд»Җд№ҲйңҖиҰҒеҒҡеҲҶеә“еҲҶиЎЁгҖӮиҝҷдёӘзӣёдҝЎеӨ§е®¶еӨҡе°‘йғҪжңүжүҖдәҶи§ЈгҖӮ
жө·йҮҸж•°жҚ®зҡ„еӯҳеӮЁе’Ңи®ҝй—®жҲҗдёәдәҶMySQLж•°жҚ®еә“зҡ„瓶йўҲй—®йўҳпјҢж—ҘзӣҠеўһй•ҝзҡ„дёҡеҠЎж•°жҚ®пјҢж— з–‘еҜ№MySQLж•°жҚ®еә“йҖ жҲҗдәҶзӣёеҪ“еӨ§зҡ„иҙҹиҪҪпјҢеҗҢж—¶еҜ№дәҺзі»з»ҹзҡ„зЁіе®ҡжҖ§е’Ңжү©еұ•жҖ§жҸҗеҮәеҫҲй«ҳзҡ„иҰҒжұӮгҖӮ
иҖҢдё”еҚ•еҸ°жңҚеҠЎеҷЁзҡ„иө„жәҗ(CPUгҖҒзЈҒзӣҳгҖҒеҶ…еӯҳзӯү)жҖ»жҳҜжңүйҷҗзҡ„пјҢжңҖз»Ҳж•°жҚ®еә“жүҖиғҪжүҝиҪҪзҡ„ж•°жҚ®йҮҸгҖҒж•°жҚ®еӨ„зҗҶиғҪеҠӣйғҪе°ҶйҒӯйҒҮ瓶йўҲгҖӮ
зӣ®еүҚжқҘиҜҙдёҖиҲ¬жңүдёӨз§Қж–№жЎҲгҖӮ
1)дёҖз§ҚжҳҜжӣҙжҚўеӯҳеӮЁпјҢдёҚдҪҝз”ЁMySQLпјҢжҜ”еҰӮеҸҜд»ҘдҪҝз”ЁHBaseгҖҒpolarDBгҖҒTiDBзӯүеҲҶеёғејҸеӯҳеӮЁгҖӮ
2)еҰӮжһңеҮәдәҺеҗ„з§ҚеҺҹеӣ иҖғиҷ‘пјҢиҝҳжҳҜжғіз»§з»ӯдҪҝз”ЁMySQLпјҢдёҖиҲ¬дјҡйҮҮ用第дәҢз§Қж–№ејҸпјҢйӮЈе°ұжҳҜеҲҶеә“еҲҶиЎЁгҖӮ
ж–Үз« ејҖеӨҙе°ұиҜҙдәҶпјҢзҪ‘дёҠеҲҶеә“еҲҶиЎЁж–Үз« еҫҲеӨҡпјҢеҜ№зҹҘиҜҶзӮ№и®Іи§ЈжҜ”иҫғеӨҡпјҢеӣ жӯӨпјҢжң¬ж–Үе°ҶдёҚеҶҚиҝҮеӨҡиөҳиҝ°еҲҶеә“еҲҶиЎЁж–№жЎҲзҡ„иҢғејҸеӨ„зҗҶгҖӮ
иҖҢжҳҜдё“жіЁдәҺжўізҗҶеҲҶеә“еҲҶиЎЁд»Һжһ¶жһ„и®ҫи®Ў еҲ° еҸ‘еёғдёҠзәҝзҡ„е®Ңж•ҙиҝҮзЁӢпјҢеҗҢж—¶жҖ»з»“е…¶дёӯзҡ„жіЁж„ҸдәӢйЎ№е’ҢжңҖдҪіе®һи·өгҖӮеҢ…жӢ¬дә”дёӘйғЁеҲҶпјҡ
дёҡеҠЎйҮҚжһ„
еӯҳеӮЁжһ¶жһ„и®ҫи®Ў
ж”№йҖ е’ҢдёҠзәҝ
зЁіе®ҡжҖ§дҝқйҡң
йЎ№зӣ®з®ЎзҗҶ
е°Өе…¶жҳҜеҗ„дёӘйҳ¶ж®өзҡ„жңҖдҪіе®һи·өпјҢйғҪжҳҜиЎҖдёҺжіӘеҮқиҒҡзҡ„з»ҸйӘҢж•ҷи®ӯгҖӮ
2.第дёҖйҳ¶ж®өпјҡдёҡеҠЎйҮҚжһ„(еҸҜйҖү)
еҜ№дәҺеҫ®жңҚеҠЎеҲ’еҲҶжҜ”иҫғеҗҲзҗҶзҡ„еҲҶеә“еҲҶиЎЁиЎҢдёәпјҢдёҖиҲ¬еҸӘйңҖиҰҒе…іжіЁеӯҳеӮЁжһ¶жһ„зҡ„еҸҳеҢ–пјҢжҲ–иҖ…еҸӘйңҖиҰҒеңЁдёӘеҲ«еә”з”ЁдёҠиҝӣиЎҢдёҡеҠЎж”№йҖ еҚіеҸҜпјҢдёҖиҲ¬дёҚйңҖиҰҒзқҖйҮҚиҖғиҷ‘вҖңдёҡеҠЎйҮҚжһ„вҖқ иҝҷдёҖйҳ¶ж®өпјҢеӣ жӯӨпјҢиҝҷдёҖйҳ¶ж®өеұһдәҺвҖңеҸҜйҖүвҖқгҖӮ
жң¬ж¬ЎйЎ№зӣ®зҡ„第дёҖеӨ§йҡҫзӮ№пјҢеңЁдәҺдёҡеҠЎйҮҚжһ„гҖӮ
иҖҢжң¬ж¬ЎжӢҶеҲҶйЎ№зӣ®ж¶үеҸҠеҲ°зҡ„дёӨеј еӨ§иЎЁAе’ҢBпјҢеҚ•иЎЁе°Ҷиҝ‘е…«еҚғдёҮзҡ„ж•°жҚ®пјҢжҳҜд»ҺеҚ•дҪ“еә”з”Ёж—¶д»ЈйҒ—з•ҷдёӢжқҘзҡ„пјҢд»ҺдёҖејҖе§Ӣе°ұжІЎжңүеҫҲеҘҪзҡ„йўҶеҹҹй©ұеҠЁ/MSAжһ¶жһ„и®ҫи®ЎпјҢйҖ»иҫ‘еҸ‘ж•ЈйқһеёёдёҘйҮҚпјҢеҲ°зҺ°еңЁе·Із»Ҹж¶үеҸҠ50+дёӘеңЁзәҝжңҚеҠЎе’Ң20+дёӘзҰ»зәҝдёҡеҠЎзҡ„зҡ„зӣҙжҺҘиҜ»еҶҷгҖӮ
еӣ жӯӨпјҢеҰӮдҪ•дҝқиҜҒдёҡеҠЎж”№йҖ зҡ„еҪ»еә•жҖ§гҖҒе…ЁйқўжҖ§жҳҜйҮҚдёӯд№ӢйҮҚпјҢдёҚиғҪеҮәзҺ°жңүйҒ—жјҸзҡ„жғ…еҶөгҖӮ
еҸҰеӨ–пјҢиЎЁA е’Ң иЎЁB еҗ„иҮӘжңүдәҢгҖҒдёүеҚҒдёӘеӯ—ж®өпјҢдёӨиЎЁзҡ„дё»й”®еӯҳеңЁдёҖдёҖеҜ№еә”е…ізі»пјҢеӣ жӯӨпјҢжң¬ж¬ЎеҲҶеә“еҲҶиЎЁйЎ№зӣ®дёӯпјҢиҝҳйңҖиҰҒе°ҶдёӨдёӘиЎЁиҝӣиЎҢйҮҚжһ„иһҚеҗҲпјҢе°ҶеӨҡдҪҷ/ж— з”Ёзҡ„еӯ—ж®өеү”йҷӨгҖӮ
2.1 жҹҘиҜўз»ҹи®Ў
еңЁзәҝдёҡеҠЎйҖҡиҝҮеҲҶеёғејҸй“ҫи·ҜиҝҪиёӘзі»з»ҹиҝӣиЎҢжҹҘиҜўпјҢжҢүз…§иЎЁеҗҚдҪңдёәжҹҘиҜўжқЎд»¶пјҢ然еҗҺжҢүз…§жңҚеҠЎз»ҙеәҰиҝӣиЎҢиҒҡеҗҲпјҢжүҫеҲ°жүҖжңүзӣёе…іжңҚеҠЎпјҢеҶҷдёҖдёӘж–ҮжЎЈи®°еҪ•зӣёе…іеӣўйҳҹе’ҢжңҚеҠЎгҖӮ
иҝҷйҮҢзү№еҲ«жіЁж„ҸдёӢпјҢеҫҲеӨҡиЎЁдёҚжҳҜеҸӘжңүеңЁзәҝеә”з”ЁеңЁдҪҝз”ЁпјҢеҫҲеӨҡзҰ»зәҝз®—жі•е’Ңж•°жҚ®еҲҶжһҗзҡ„дёҡеҠЎд№ҹеңЁдҪҝз”ЁпјҢиҝҷйҮҢйңҖиҰҒдёҖ并зҡ„жўізҗҶеҘҪпјҢеҒҡеҘҪзәҝдёӢи·Ёеӣўйҳҹзҡ„жІҹйҖҡе’Ңи°ғз ”е·ҘдҪңпјҢд»Ҙе…ҚеҲҮжҚўеҗҺеҪұе“ҚжӯЈеёёзҡ„ж•°жҚ®еҲҶжһҗгҖӮ
2.2 жҹҘиҜўжӢҶеҲҶдёҺиҝҒ移
еҲӣе»әдёҖдёӘjarеҢ…пјҢж №жҚ®2.1зҡ„з»ҹи®Ўз»“жһңпјҢдёҺжңҚеҠЎownerеҗҲдҪңе°ҶжңҚеҠЎдёӯзҡ„зӣёе…іжҹҘиҜўйғҪиҝҒ移еҲ°иҝҷдёӘjarеҢ…дёӯ(жң¬йЎ№зӣ®зҡ„jarеҢ…еҸ«projected)гҖӮ
жӯӨеӨ„дёә1.0.0-SNAPSHOTзүҲжң¬гҖӮ
然еҗҺе°ҶеҺҹжң¬жңҚеҠЎеҶ…зҡ„xxxMapper.xxxMethod( ) е…ЁйғЁж”№жҲҗprojectdb.xxxMethod( )иҝӣиЎҢи°ғз”ЁгҖӮ
иҝҷж ·еҒҡжңүдёӨдёӘеҘҪеӨ„пјҡ
ж–№дҫҝеҒҡеҗҺз»ӯзҡ„жҹҘиҜўжӢҶеҲҶеҲҶжһҗгҖӮ
ж–№дҫҝеҗҺз»ӯзӣҙжҺҘе°ҶjarеҢ…дёӯзҡ„жҹҘиҜўжӣҝжҚўдёәж”№йҖ еҗҺ дёӯеҸ°жңҚеҠЎ зҡ„rpcи°ғз”ЁпјҢдёҡеҠЎж–№еҸӘйңҖеҚҮзә§jarеҢ…зүҲжң¬пјҢеҚіеҸҜеҝ«йҖҹд»Һsqlи°ғз”Ёж”№дёәrpcжҹҘиҜўгҖӮ
иҝҷдёҖжӯҘиҠұдәҶеҮ дёӘжңҲзҡ„е®һйҷ…пјҢеҠЎеҝ…жўізҗҶеҗ„дёӘжңҚеҠЎеҒҡе…Ёйқўзҡ„иҝҒ移пјҢдёҚиғҪйҒ—жјҸпјҢеҗҰеҲҷеҸҜиғҪдјҡеҜјиҮҙжӢҶеҲҶеҲҶжһҗдёҚе…ЁйқўпјҢйҒ—жјҸдәҶзӣёе…іеӯ—ж®өгҖӮ
жҹҘиҜўзҡ„иҝҒ移主иҰҒз”ұдәҺжң¬ж¬ЎжӢҶеҲҶйЎ№зӣ®ж¶үеҸҠеҲ°зҡ„жңҚеҠЎеӨӘеӨҡпјҢйңҖиҰҒ收жӢўеҲ°дёҖдёӘjarеҢ…пјҢжӣҙж–№дҫҝеҗҺжңҹзҡ„ж”№йҖ гҖӮеҰӮжһңе®һйҷ…еҲҶеә“еҲҶиЎЁйЎ№зӣ®дёӯд»…д»…ж¶үеҸҠдёҖдёӨдёӘжңҚеҠЎзҡ„пјҢиҝҷдёҖжӯҘжҳҜеҸҜд»ҘдёҚеҒҡзҡ„гҖӮ
2.3 иҒ”еҗҲжҹҘиҜўзҡ„жӢҶеҲҶеҲҶжһҗ
ж №жҚ®2.2收жӢўзҡ„jarеҢ…дёӯзҡ„жҹҘиҜўпјҢз»“еҗҲе®һйҷ…жғ…еҶөе°ҶжҹҘиҜўиҝӣиЎҢеҲҶзұ»е’ҢеҲӨж–ӯпјҢжҠҠдёҖдәӣеҺҶеҸІйҒ—з•ҷзҡ„й—®йўҳпјҢе’Ңе·Із»Ҹеәҹејғзҡ„еӯ—ж®өеҒҡдёҖдәӣж•ҙзҗҶгҖӮ
д»ҘдёӢдёҫдёҖдәӣжҖқиҖғзӮ№гҖӮ
1)е“ӘдәӣжҹҘиҜўжҳҜж— жі•жӢҶеҲҶзҡ„?дҫӢеҰӮеҲҶйЎө(е°ҪеҸҜиғҪең°ж”№йҖ пјҢе®һеңЁж”№дёҚдәҶеҸӘиғҪд»ҘеҶ—дҪҷеҲ—зҡ„еҪўејҸ)
2)е“ӘдәӣжҹҘиҜўжҳҜеҸҜд»ҘдёҡеҠЎдёҠjoinжӢҶеҲҶзҡ„?
3)е“ӘдәӣиЎЁ/еӯ—ж®өжҳҜеҸҜд»ҘиһҚеҗҲзҡ„?
4)е“Әдәӣеӯ—ж®өйңҖиҰҒеҶ—дҪҷ?
5)е“Әдәӣеӯ—ж®өеҸҜд»ҘзӣҙжҺҘеәҹејғдәҶ?
6)ж №жҚ®дёҡеҠЎе…·дҪ“еңәжҷҜе’Ңsqlж•ҙдҪ“з»ҹи®ЎпјҢиҜҶеҲ«е…ій”®зҡ„еҲҶиЎЁй”®гҖӮе…¶дҪҷжҹҘиҜўиө°жҗңзҙўе№іеҸ°гҖӮ
жҖқиҖғеҗҺеҫ—еҲ°дёҖдёӘжҹҘиҜўж”№йҖ жҖ»дҪ“жҖқи·Ҝе’Ңж–№жЎҲгҖӮ
еҗҢж—¶еңЁжң¬йЎ№зӣ®дёӯйңҖиҰҒе°ҶдёӨеј иЎЁиһҚеҗҲдёәдёҖеј иЎЁпјҢеәҹејғеҶ—дҪҷеӯ—ж®өе’Ңж— ж•Ҳеӯ—ж®өгҖӮ
2.4 ж–°иЎЁи®ҫи®Ў
иҝҷдёҖжӯҘеҹәдәҺ2.3еҜ№дәҺжҹҘиҜўзҡ„жӢҶеҲҶеҲҶжһҗпјҢеҫ—еҮәж—§иЎЁиһҚеҗҲгҖҒеҶ—дҪҷгҖҒеәҹејғеӯ—ж®өзҡ„з»“жһңпјҢи®ҫи®Ўж–°иЎЁзҡ„еӯ—ж®өгҖӮ
дә§еҮәж–°иЎЁи®ҫи®Ўз»“жһ„еҗҺпјҢеҝ…йЎ»еҸ‘з»ҷеҗ„дёӘзӣёе…ідёҡеҠЎж–№иҝӣиЎҢreviewпјҢ并дҝқиҜҒжүҖжңүдёҡеҠЎж–№йғҪйҖҡиҝҮиҜҘиЎЁзҡ„и®ҫи®ЎгҖӮжңүеҝ…иҰҒзҡ„иҜқеҸҜд»ҘиҝӣиЎҢдёҖж¬ЎзәҝдёӢreviewгҖӮ
еҰӮжһңж–°иЎЁзҡ„иҝҮзЁӢдёӯпјҢеҜ№йғЁеҲҶеӯ—ж®өиҝӣиЎҢдәҶеәҹејғпјҢеҝ…йЎ»йҖҡзҹҘжүҖжңүдёҡеҠЎж–№иҝӣиЎҢзЎ®и®ӨгҖӮ
еҜ№дәҺж–°иЎЁзҡ„и®ҫи®ЎпјҢйҷӨдәҶеӯ—ж®өзҡ„жўізҗҶпјҢд№ҹйңҖиҰҒж №жҚ®е…·дҪ“жҹҘиҜўпјҢйҮҚж–°и®ҫи®ЎгҖҒдјҳеҢ–зҙўеј•гҖӮ
2.5 第дёҖж¬ЎеҚҮзә§
ж–°иЎЁи®ҫи®Ўе®ҢжҲҗеҗҺпјҢе…ҲеҒҡдёҖж¬ЎjarеҢ…еҶ…sqlжҹҘиҜўзҡ„ж”№йҖ пјҢе°Ҷж—§зҡ„еӯ—ж®өе…ЁйғЁжӣҙж–°дёәж–°иЎЁзҡ„еӯ—ж®өгҖӮ
жӯӨеӨ„дёә2.0.0-SNAPSHOTзүҲжң¬гҖӮ
然еҗҺи®©жүҖжңүжңҚеҠЎеҚҮзә§jarеҢ…зүҲжң¬пјҢд»ҘжӯӨжқҘдҝқиҜҒиҝҷдәӣеәҹејғеӯ—ж®өзЎ®е®һжҳҜдёҚдҪҝз”ЁдәҶпјҢж–°зҡ„иЎЁз»“жһ„еӯ—ж®өиғҪеӨҹе®Ңе…ЁиҰҶзӣ–иҝҮеҺ»зҡ„дёҡеҠЎеңәжҷҜгҖӮ
зү№еҲ«жіЁж„Ҹзҡ„жҳҜпјҢз”ұдәҺж¶үеҸҠжңҚеҠЎдј—еӨҡпјҢеҸҜд»Ҙе°ҶжңҚеҠЎжҢүз…§ йқһж ёеҝғ дёҺ ж ёеҝғ еҢәеҲҶпјҢ然еҗҺеҲҶжү№ж¬ЎдёҠзәҝпјҢйҒҝе…ҚеҮәзҺ°й—®йўҳеҜјиҮҙдёҘйҮҚж•…йҡңжҲ–иҖ…еӨ§иҢғеӣҙеӣһж»ҡгҖӮ
2.6 жңҖдҪіе®һи·ө
2.6.1 е°ҪйҮҸдёҚж”№еҸҳеҺҹиЎЁзҡ„еӯ—ж®өеҗҚз§°
еңЁеҒҡж–°иЎЁиһҚеҗҲзҡ„ж—¶еҖҷпјҢдёҖејҖе§ӢеҸӘжҳҜз®ҖеҚ•еҪ’并表A е’Ң иЎЁBзҡ„иЎЁпјҢеӣ жӯӨеҫҲеӨҡеӯ—ж®өеҗҚзӣёеҗҢзҡ„еӯ—ж®өеҒҡдәҶйҮҚе‘ҪеҗҚгҖӮ
еҗҺжқҘеӯ—ж®өзІҫз®ҖиҝҮзЁӢдёӯпјҢеҲ йҷӨдәҶеҫҲеӨҡйҮҚеӨҚеӯ—ж®өпјҢдҪҶжҳҜжІЎжңүе°ҶйҮҚе‘ҪеҗҚзҡ„еӯ—ж®өж”№еӣһжқҘгҖӮ
еҜјиҮҙеҗҺжңҹдёҠзәҝзҡ„иҝҮзЁӢдёӯпјҢдёҚеҸҜйҒҝе…Қең°йңҖиҰҒдёҡеҠЎж–№иҝӣиЎҢйҮҚжһ„еӯ—ж®өеҗҚгҖӮ
еӣ жӯӨпјҢж–°иЎЁи®ҫи®Ўзҡ„ж—¶еҖҷпјҢйҷӨйқһеҝ…дёҚеҫ—е·ІпјҢдёҚиҰҒдҝ®ж”№еҺҹиЎЁзҡ„еӯ—ж®өеҗҚз§°!
2.6.2 ж–°иЎЁзҡ„зҙўеј•йңҖиҰҒд»”з»Ҷж–ҹй…Ң
ж–°иЎЁзҡ„зҙўеј•дёҚиғҪз®ҖеҚ•з…§жҗ¬ж—§иЎЁпјҢиҖҢжҳҜйңҖиҰҒж №жҚ®жҹҘиҜўжӢҶеҲҶеҲҶжһҗеҗҺпјҢйҮҚж–°и®ҫи®ЎгҖӮ
е°Өе…¶жҳҜдёҖдәӣеӯ—ж®өзҡ„иһҚеҗҲеҗҺпјҢеҸҜиғҪеҸҜд»ҘеҪ’并дёҖдәӣзҙўеј•пјҢжҲ–иҖ…и®ҫи®ЎдёҖдәӣжӣҙй«ҳжҖ§иғҪзҡ„зҙўеј•гҖӮ
2.6 жң¬з« е°Ҹз»“
иҮіжӯӨпјҢеҲҶеә“еҲҶиЎЁзҡ„第дёҖйҳ¶ж®өе‘ҠдёҖж®өиҗҪгҖӮиҝҷдёҖйҳ¶ж®өжүҖйңҖж—¶й—ҙпјҢе®Ңе…ЁеҸ–еҶідәҺе…·дҪ“дёҡеҠЎпјҢеҰӮжһңжҳҜдёҖдёӘеҺҶеҸІеҢ…иўұжІүйҮҚзҡ„дёҡеҠЎпјҢйӮЈеҸҜиғҪйңҖиҰҒиҠұиҙ№еҮ дёӘжңҲз”ҡиҮіеҚҠе№ҙзҡ„ж—¶й—ҙжүҚиғҪе®ҢжҲҗгҖӮ
иҝҷдёҖйҳ¶ж®өзҡ„е®ҢжҲҗиҙЁйҮҸйқһеёёйҮҚиҰҒпјҢеҗҰеҲҷеҸҜиғҪеҜјиҮҙйЎ№зӣ®еҗҺжңҹйңҖиҰҒйҮҚе»әиЎЁз»“жһ„гҖҒйҮҚж–°е…ЁйҮҸж•°жҚ®гҖӮ
иҝҷйҮҢеҶҚж¬ЎиҜҙжҳҺпјҢеҜ№дәҺеҫ®жңҚеҠЎеҲ’еҲҶжҜ”иҫғеҗҲзҗҶзҡ„жңҚеҠЎпјҢеҲҶеә“еҲҶиЎЁиЎҢдёәдёҖиҲ¬еҸӘйңҖиҰҒе…іжіЁеӯҳеӮЁжһ¶жһ„зҡ„еҸҳеҢ–пјҢжҲ–иҖ…еҸӘйңҖиҰҒеңЁдёӘеҲ«еә”з”ЁдёҠиҝӣиЎҢдёҡеҠЎж”№йҖ еҚіеҸҜпјҢдёҖиҲ¬дёҚйңҖиҰҒзқҖйҮҚиҖғиҷ‘вҖңдёҡеҠЎйҮҚжһ„вҖқ иҝҷдёҖйҳ¶ж®өгҖӮ
3.第дәҢйҳ¶ж®өпјҡеӯҳеӮЁжһ¶жһ„и®ҫи®Ў(ж ёеҝғ)
еҜ№дәҺд»»дҪ•еҲҶеә“еҲҶиЎЁзҡ„йЎ№зӣ®пјҢеӯҳеӮЁжһ¶жһ„зҡ„и®ҫи®ЎйғҪжҳҜжңҖж ёеҝғзҡ„йғЁеҲҶ!
3.1 ж•ҙдҪ“жһ¶жһ„
ж №жҚ®з¬¬дёҖйҳ¶ж®өж•ҙзҗҶзҡ„жҹҘиҜўжўізҗҶз»“жһңпјҢжҲ‘们жҖ»з»“дәҶиҝҷж ·зҡ„жҹҘиҜўи§„еҫӢгҖӮ
80%д»ҘдёҠзҡ„жҹҘиҜўйғҪжҳҜйҖҡиҝҮжҲ–иҖ…еёҰжңүеӯ—ж®өpk1гҖҒеӯ—ж®өpk2гҖҒеӯ—ж®өpk3иҝҷдёүдёӘз»ҙеәҰиҝӣиЎҢжҹҘиҜўзҡ„пјҢе…¶дёӯpk1е’Ңpk2з”ұдәҺеҺҶеҸІеҺҹеӣ еӯҳеңЁдёҖдёҖеҜ№еә”зҡ„е…ізі»
20%зҡ„жҹҘиҜўеҚғеҘҮзҷҫжҖӘпјҢеҢ…жӢ¬жЁЎзіҠжҹҘиҜўгҖҒе…¶д»–еӯ—ж®өжҹҘиҜўзӯүзӯү
еӣ жӯӨпјҢжҲ‘们и®ҫи®ЎдәҶеҰӮдёӢзҡ„ж•ҙдҪ“жһ¶жһ„пјҢеј•е…ҘдәҶж•°жҚ®еә“дёӯй—ҙ件гҖҒж•°жҚ®еҗҢжӯҘе·Ҙе…·гҖҒжҗңзҙўеј•ж“Һ(йҳҝйҮҢдә‘opensearch/ES)зӯүгҖӮ
дёӢж–Үзҡ„и®әиҝ°йғҪжҳҜеӣҙз»•иҝҷдёӘжһ¶жһ„жқҘеұ•ејҖзҡ„гҖӮ
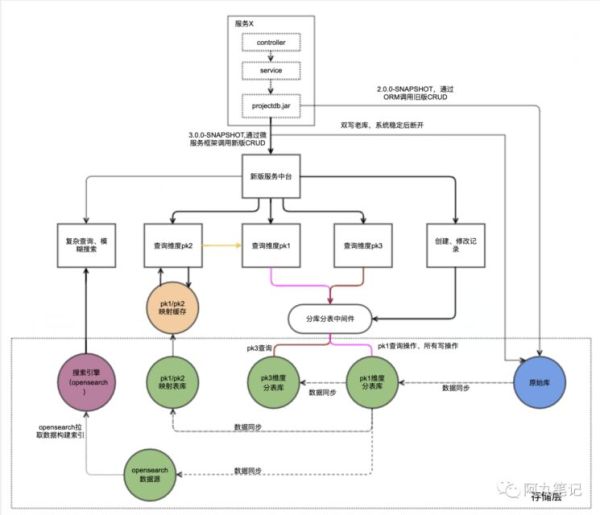
3.1.1 mysqlеҲҶиЎЁеӯҳеӮЁ
MysqlеҲҶиЎЁзҡ„з»ҙеәҰжҳҜж №жҚ®жҹҘиҜўжӢҶеҲҶеҲҶжһҗзҡ„з»“жһңзЎ®е®ҡзҡ„гҖӮ
жҲ‘们еҸ‘зҺ°pk1\pk2\pk3еҸҜд»ҘиҰҶзӣ–80%д»ҘдёҠзҡ„дё»иҰҒжҹҘиҜўгҖӮи®©иҝҷдәӣжҹҘиҜўж №жҚ®еҲҶиЎЁй”®зӣҙжҺҘиө°mysqlж•°жҚ®еә“еҚіеҸҜгҖӮ
еҺҹеҲҷдёҠдёҖиҲ¬жңҖеӨҡз»ҙжҠӨдёҖдёӘеҲҶиЎЁзҡ„е…ЁйҮҸж•°жҚ®пјҢеӣ дёәиҝҮеӨҡзҡ„е…ЁйҮҸж•°жҚ®дјҡйҖ жҲҗеӯҳеӮЁзҡ„жөӘиҙ№гҖҒж•°жҚ®еҗҢжӯҘзҡ„йўқеӨ–ејҖй”ҖгҖҒжӣҙеӨҡзҡ„дёҚзЁіе®ҡжҖ§гҖҒдёҚжҳ“жү©еұ•зӯүй—®йўҳгҖӮ
дҪҶжҳҜз”ұдәҺжң¬йЎ№зӣ®pk1е’Ңpk3зҡ„жҹҘиҜўиҜӯеҸҘйғҪеҜ№е®һж—¶жҖ§жңүжҜ”иҫғй«ҳзҡ„иҰҒжұӮпјҢеӣ жӯӨпјҢз»ҙжҠӨдәҶpk1е’Ңpk3дҪңдёәеҲҶиЎЁй”®зҡ„дёӨд»Ҫе…ЁйҮҸж•°жҚ®гҖӮ
иҖҢpk2е’Ңpk1з”ұдәҺеҺҶеҸІеҺҹеӣ пјҢеӯҳеңЁдёҖдёҖеҜ№еә”е…ізі»пјҢеҸҜд»Ҙд»…дҝқз•ҷдёҖд»Ҫжҳ е°„иЎЁеҚіеҸҜпјҢеҸӘеӯҳеӮЁpk1е’Ңpk2дёӨдёӘеӯ—ж®өгҖӮ
3.1.2 жҗңзҙўе№іеҸ°зҙўеј•еӯҳеӮЁ
жҗңзҙўе№іеҸ°зҙўеј•пјҢеҸҜд»ҘиҰҶзӣ–еү©дҪҷ20%зҡ„йӣ¶ж•ЈжҹҘиҜўгҖӮ
иҝҷдәӣжҹҘиҜўеҫҖеҫҖдёҚжҳҜж №жҚ®еҲҶиЎЁй”®иҝӣиЎҢзҡ„пјҢжҲ–иҖ…жҳҜеёҰжңүжЁЎзіҠжҹҘиҜўзҡ„иҰҒжұӮгҖӮ
еҜ№дәҺжҗңзҙўе№іеҸ°жқҘиҜҙпјҢдёҖиҲ¬дёҚеӯҳеӮЁе…ЁйҮҸж•°жҚ®(е°Өе…¶жҳҜдёҖдәӣеӨ§varcharеӯ—ж®ө)пјҢеҸӘеӯҳеӮЁдё»й”®е’ҢжҹҘиҜўйңҖиҰҒзҡ„зҙўеј•еӯ—ж®өпјҢжҗңзҙўеҫ—еҲ°з»“жһңеҗҺпјҢж №жҚ®дё»й”®еҺ»mysqlеӯҳеӮЁдёӯжӢҝеҲ°йңҖиҰҒзҡ„и®°еҪ•гҖӮ
еҪ“然пјҢд»ҺеҗҺжңҹе®һи·өз»“жһңжқҘзңӢпјҢиҝҷйҮҢиҝҳжҳҜйңҖиҰҒеҒҡдёҖдәӣжқғиЎЎзҡ„пјҡ
1)жңүдәӣйқһзҙўеј•еӯ—ж®өпјҢеҰӮжһңдёҚжҳҜеҫҲеӨ§пјҢд№ҹеҸҜд»ҘеҶ—дҪҷиҝӣжқҘпјҢзұ»дјјиҰҶзӣ–зҙўеј•пјҢйҒҝе…ҚеӨҡдёҖж¬ЎsqlжҹҘиҜў;
2)еҰӮжһңиЎЁз»“жһ„жҜ”иҫғз®ҖеҚ•пјҢеӯ—ж®өдёҚеӨ§пјҢз”ҡиҮіеҸҜд»ҘиҖғиҷ‘е…ЁйҮҸеӯҳеӮЁпјҢжҸҗй«ҳжҹҘиҜўжҖ§иғҪпјҢйҷҚдҪҺmysqlж•°жҚ®еә“зҡ„еҺӢеҠӣгҖӮ
иҝҷйҮҢзү№еҲ«жҸҗзӨәпјҢжҗңзҙўеј•ж“Һе’Ңж•°жҚ®еә“д№Ӣй—ҙеҗҢжӯҘжҳҜеҝ…然еӯҳеңЁе»¶иҝҹзҡ„гҖӮжүҖд»ҘеҜ№дәҺж №жҚ®еҲҶиЎЁidжҹҘиҜўзҡ„иҜӯеҸҘпјҢе°ҪйҮҸдҝқиҜҒзӣҙжҺҘжҹҘиҜўж•°жҚ®еә“пјҢиҝҷж ·дёҚдјҡеёҰжқҘдёҖиҮҙжҖ§й—®йўҳзҡ„йҡҗжӮЈгҖӮ
3.1.3 ж•°жҚ®еҗҢжӯҘ
дёҖиҲ¬ж–°иЎЁе’Ңж—§иЎЁзӣҙжҺҘеҸҜд»ҘйҮҮз”Ё ж•°жҚ®еҗҢжӯҘ жҲ–иҖ… еҸҢеҶҷзҡ„ж–№ејҸиҝӣиЎҢеӨ„зҗҶпјҢдёӨз§Қж–№ејҸжңүеҗ„иҮӘзҡ„дјҳзјәзӮ№гҖӮ
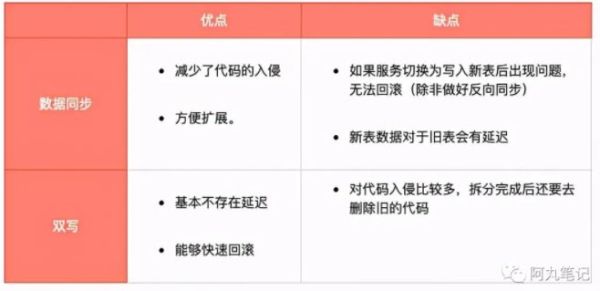
дёҖиҲ¬ж №жҚ®е…·дҪ“жғ…еҶөйҖүжӢ©дёҖз§Қж–№ејҸе°ұиЎҢгҖӮ
жң¬ж¬ЎйЎ№зӣ®зҡ„е…·дҪ“еҗҢжӯҘе…ізі»и§Ғж•ҙдҪ“еӯҳеӮЁжһ¶жһ„пјҢеҢ…жӢ¬дәҶеӣӣдёӘйғЁеҲҶпјҡ
1)ж—§иЎЁеҲ°ж–°иЎЁе…ЁйҮҸдё»иЎЁзҡ„еҗҢжӯҘ
дёҖејҖе§ӢдёәдәҶеҮҸе°‘д»Јз Ғе…ҘдҫөгҖҒж–№дҫҝжү©еұ•пјҢйҮҮз”ЁдәҶж•°жҚ®еҗҢжӯҘзҡ„ж–№ејҸгҖӮиҖҢдё”з”ұдәҺдёҡеҠЎиҝҮеӨҡпјҢжӢ…еҝғжңүжңӘз»ҹи®ЎеҲ°зҡ„жңҚеҠЎжІЎжңүеҸҠж—¶ж”№йҖ пјҢжүҖд»Ҙж•°жҚ®еҗҢжӯҘиғҪйҒҝе…Қиҝҷдәӣжғ…еҶөеҜјиҮҙж•°жҚ®дёўеӨұгҖӮ
дҪҶжҳҜеңЁдёҠзәҝиҝҮзЁӢдёӯеҸ‘зҺ°пјҢеҪ“延иҝҹеӯҳеңЁж—¶пјҢеҫҲеӨҡж–°еҶҷе…Ҙзҡ„и®°еҪ•ж— жі•иҜ»еҲ°пјҢеҜ№е…·дҪ“дёҡеҠЎеңәжҷҜйҖ жҲҗдәҶжҜ”иҫғдёҘйҮҚзҡ„еҪұе“ҚгҖӮ(е…·дҪ“еҺҹеӣ еҸӮиҖғ4.5.1зҡ„иҜҙжҳҺ)
еӣ жӯӨпјҢдёәдәҶж»Ўи¶іеә”з”ЁеҜ№дәҺе®һж—¶жҖ§зҡ„иҰҒжұӮпјҢжҲ‘们еңЁж•°жҚ®еҗҢжӯҘзҡ„еҹәзЎҖдёҠпјҢйҮҚж–°еңЁ3.0.0-SNAPSHOTзүҲжң¬дёӯж”№йҖ жҲҗдәҶеҸҢеҶҷзҡ„еҪўејҸгҖӮ
2)ж–°иЎЁе…ЁйҮҸдё»иЎЁеҲ°е…ЁйҮҸеүҜиЎЁзҡ„еҗҢжӯҘ
3)ж–°иЎЁе…ЁйҮҸдё»иЎЁеҲ°жҳ е°„иЎЁеҲ°еҗҢжӯҘ
4)ж–°иЎЁе…ЁйҮҸдё»иЎЁеҲ°жҗңзҙўеј•ж“Һж•°жҚ®жәҗзҡ„еҗҢжӯҘ
2)гҖҒ3)гҖҒ4)йғҪжҳҜд»Һж–°иЎЁе…ЁйҮҸдё»иЎЁеҲ°е…¶д»–ж•°жҚ®жәҗзҡ„ж•°жҚ®еҗҢжӯҘпјҢеӣ дёәжІЎжңүејәе®һж—¶жҖ§зҡ„иҰҒжұӮпјҢеӣ жӯӨпјҢдёәдәҶж–№дҫҝжү©еұ•пјҢе…ЁйғЁйҮҮз”ЁдәҶж•°жҚ®еҗҢжӯҘзҡ„ж–№ејҸпјҢжІЎжңүиҝӣиЎҢжӣҙеӨҡзҡ„еӨҡеҶҷж“ҚдҪңгҖӮ
3.2 е®№йҮҸиҜ„дј°
еңЁз”іиҜ·mysqlеӯҳеӮЁе’Ңжҗңзҙўе№іеҸ°зҙўеј•иө„жәҗеүҚпјҢйңҖиҰҒиҝӣиЎҢе®№йҮҸиҜ„дј°пјҢеҢ…жӢ¬еӯҳеӮЁе®№йҮҸе’ҢжҖ§иғҪжҢҮж ҮгҖӮ
е…·дҪ“зәҝдёҠжөҒйҮҸиҜ„дј°еҸҜд»ҘйҖҡиҝҮзӣ‘жҺ§зі»з»ҹжҹҘзңӢqpsпјҢеӯҳеӮЁе®№йҮҸеҸҜд»Ҙз®ҖеҚ•и®ӨдёәжҳҜзәҝдёҠеҗ„дёӘиЎЁеӯҳеӮЁе®№йҮҸзҡ„е’ҢгҖӮ
дҪҶжҳҜеңЁе…ЁйҮҸеҗҢжӯҘиҝҮзЁӢдёӯпјҢжҲ‘们еҸ‘зҺ°йңҖиҰҒзҡ„е®һйҷ…е®№йҮҸзҡ„йңҖжұӮдјҡеӨ§дәҺйў„дј°пјҢе…·дҪ“еҸҜд»ҘзңӢ3.4.6зҡ„иҜҙжҳҺгҖӮ
е…·дҪ“жҖ§иғҪеҺӢжөӢиҝҮзЁӢе°ұдёҚеҶҚиөҳиҝ°гҖӮ
3.3 ж•°жҚ®ж ЎйӘҢ
д»ҺдёҠж–ҮеҸҜд»ҘзңӢеҲ°пјҢеңЁжң¬ж¬ЎйЎ№зӣ®дёӯпјҢеӯҳеңЁеӨ§йҮҸзҡ„дёҡеҠЎж”№йҖ пјҢеұһдәҺејӮжһ„иҝҒ移гҖӮ
д»ҺиҝҮеҺ»зҡ„дёҖдәӣеҲҶеә“еҲҶиЎЁйЎ№зӣ®жқҘиҜҙпјҢеӨ§еӨҡжҳҜеҗҢжһ„/еҜ№зӯүжӢҶеҲҶпјҢеӣ жӯӨдёҚдјҡеӯҳеңЁеҫҲеӨҡеӨҚжқӮйҖ»иҫ‘пјҢжүҖд»ҘеҜ№дәҺж•°жҚ®иҝҒ移зҡ„ж ЎйӘҢеҫҖеҫҖжҜ”иҫғеҝҪи§ҶгҖӮ
еңЁе®Ңе…ЁеҜ№зӯүиҝҒ移зҡ„жғ…еҶөдёӢпјҢдёҖиҲ¬зЎ®е®һжҜ”иҫғе°‘еҮәзҺ°й—®йўҳгҖӮ
дҪҶжҳҜпјҢзұ»дјјиҝҷж ·жңүжҜ”иҫғеӨҡж”№йҖ зҡ„ејӮжһ„иҝҒ移пјҢж ЎйӘҢз»қеҜ№жҳҜйҮҚдёӯд№ӢйҮҚ!!
еӣ жӯӨпјҢеҝ…йЎ»еҜ№ж•°жҚ®еҗҢжӯҘзҡ„з»“жһңеҒҡж ЎйӘҢпјҢдҝқиҜҒдёҡеҠЎйҖ»иҫ‘ж”№йҖ жӯЈзЎ®гҖҒж•°жҚ®еҗҢжӯҘдёҖиҮҙжҖ§жӯЈзЎ®гҖӮиҝҷдёҖзӮ№йқһеёёйқһеёёйҮҚиҰҒгҖӮ
еңЁжң¬ж¬ЎйЎ№зӣ®дёӯпјҢеӯҳеңЁеӨ§йҮҸдёҡеҠЎйҖ»иҫ‘дјҳеҢ–д»ҘеҸҠеӯ—ж®өеҸҳеҠЁпјҢжүҖд»ҘжҲ‘们еҚ•зӢ¬еҒҡдәҶдёҖдёӘж ЎйӘҢжңҚеҠЎпјҢеҜ№ж•°жҚ®зҡ„е…ЁйҮҸгҖҒеўһйҮҸиҝӣиЎҢж ЎйӘҢгҖӮ
иҝҮзЁӢдёӯжҸҗеүҚеҸ‘зҺ°дәҶи®ёеӨҡж•°жҚ®еҗҢжӯҘгҖҒдёҡеҠЎйҖ»иҫ‘зҡ„дёҚдёҖиҮҙй—®йўҳпјҢз»ҷжҲ‘们жң¬ж¬ЎйЎ№зӣ®е№ізЁідёҠзәҝжҸҗдҫӣдәҶжңҖйҮҚиҰҒзҡ„еүҚжҸҗдҝқйҡң!!
3.4 жңҖдҪіе®һи·ө
3.4.1 еҲҶеә“еҲҶиЎЁеј•иө·зҡ„жөҒйҮҸж”ҫеӨ§й—®йўҳ
еңЁеҒҡе®№йҮҸиҜ„дј°зҡ„ж—¶еҖҷпјҢйңҖиҰҒе…іжіЁдёҖдёӘйҮҚиҰҒй—®йўҳгҖӮе°ұжҳҜеҲҶиЎЁеёҰжқҘзҡ„жҹҘиҜўжөҒйҮҸж”ҫеӨ§гҖӮ
иҝҷдёӘжөҒйҮҸж”ҫеӨ§жңүдёӨж–№йқўзҡ„еҺҹеӣ пјҡ
зҙўеј•иЎЁзҡ„дәҢж¬ЎжҹҘиҜўгҖӮжҜ”еҰӮж №жҚ®pk2жҹҘиҜўзҡ„пјҢйңҖиҰҒе…ҲйҖҡиҝҮpk2жҹҘиҜўpk1пјҢ然еҗҺж №жҚ®pk1жҹҘиҜўиҝ”еӣһз»“жһңгҖӮ
inзҡ„еҲҶжү№жҹҘиҜўгҖӮеҰӮжһңдёҖдёӘselect...in...зҡ„жҹҘиҜўпјҢж•°жҚ®еә“дёӯй—ҙ件дјҡж №жҚ®еҲҶиЎЁй”®пјҢе°ҶжҹҘиҜўжӢҶеҲҶиҗҪеҲ°еҜ№еә”зҡ„зү©зҗҶеҲҶиЎЁдёҠпјҢзӣёеҪ“дәҺеҺҹжң¬зҡ„дёҖж¬ЎжҹҘиҜўпјҢж”ҫеӨ§дёәеӨҡж¬ЎжҹҘиҜўгҖӮ(еҪ“然пјҢж•°жҚ®еә“дјҡе°ҶиҗҪеңЁеҗҢдёҖдёӘеҲҶиЎЁзҡ„idдҪңдёәдёҖж¬Ўжү№йҮҸжҹҘиҜўпјҢиҖҢиҝҷжҳҜдёҚзЁіе®ҡзҡ„еҗҲ并)
еӣ жӯӨпјҢжҲ‘们йңҖиҰҒжіЁж„Ҹпјҡ
дёҡеҠЎеұӮйқўе°ҪйҮҸйҷҗеҲ¶inжҹҘиҜўж•°йҮҸпјҢйҒҝе…ҚжөҒйҮҸиҝҮдәҺж”ҫеӨ§;
е®№йҮҸиҜ„дј°ж—¶пјҢйңҖиҰҒиҖғиҷ‘иҝҷйғЁеҲҶж”ҫеӨ§еӣ зҙ пјҢеҒҡйҖӮеҪ“еҶ—дҪҷпјҢеҸҰеӨ–пјҢеҗҺз»ӯдјҡжҸҗеҲ°дёҡеҠЎж”№йҖ дёҠзәҝеҲҶжү№иҝӣиЎҢпјҢдҝқиҜҒеҸҜд»ҘеҸҠж—¶жү©е®№;
еҲҶ64гҖҒ128иҝҳжҳҜ256еј иЎЁжңүдёӘеҗҲзҗҶйў„дј°пјҢжӢҶеҫ—и¶ҠеӨҡпјҢзҗҶи®әдёҠдјҡж”ҫеӨ§и¶ҠеӨҡпјҢеӣ жӯӨдёҚиҰҒж— и°“ең°еҲҶиҝҮеӨҡзҡ„иЎЁпјҢж №жҚ®дёҡеҠЎи§„жЁЎеҒҡйҖӮеҪ“дј°и®Ў;
еҜ№дәҺжҳ е°„иЎЁзҡ„жҹҘиҜўпјҢз”ұдәҺеӯҳеңЁжҳҺжҳҫзҡ„еҶ·зғӯж•°жҚ®пјҢжүҖд»ҘжҲ‘们еҸҲеңЁдёӯй—ҙеҠ дәҶдёҖеұӮзј“еӯҳпјҢеҮҸе°‘ж•°жҚ®еә“зҡ„еҺӢеҠӣ
3.4.2 еҲҶиЎЁй”®зҡ„еҸҳжӣҙж–№жЎҲ
жң¬йЎ№зӣ®дёӯпјҢеӯҳеңЁдёҖз§ҚдёҡеҠЎжғ…еҶөдјҡеҸҳжӣҙеӯ—ж®өpk3пјҢдҪҶжҳҜpk3дҪңдёәеҲҶиЎЁй”®пјҢеңЁж•°жҚ®еә“дёӯй—ҙ件дёӯжҳҜдёҚиғҪдҝ®ж”№зҡ„пјҢеӣ жӯӨпјҢеҸӘиғҪеңЁдёӯеҸ°дёӯдҝ®ж”№еҜ№pk3зҡ„жӣҙж–°йҖ»иҫ‘пјҢйҮҮз”Ёе…ҲеҲ йҷӨгҖҒеҗҺж·»еҠ зҡ„ж–№ејҸгҖӮ
иҝҷйҮҢйңҖиҰҒжіЁж„ҸпјҢеҲ йҷӨе’Ңж·»еҠ ж“ҚдҪңзҡ„дәӢеҠЎеҺҹеӯҗжҖ§гҖӮеҪ“然пјҢз®ҖеҚ•еӨ„зҗҶд№ҹеҸҜд»ҘйҖҡиҝҮж—Ҙеҝ—зҡ„ж–№ејҸпјҢиҝӣиЎҢе‘ҠиӯҰе’Ңж ЎеҮҶгҖӮ
3.4.3 ж•°жҚ®еҗҢжӯҘдёҖиҮҙжҖ§й—®йўҳ
жҲ‘们йғҪзҹҘйҒ“пјҢж•°жҚ®еҗҢжӯҘдёӯдёҖдёӘе…ій”®зӮ№е°ұжҳҜ(ж¶ҲжҒҜ)ж•°жҚ®зҡ„йЎәеәҸжҖ§пјҢеҰӮжһңдёҚиғҪдҝқиҜҒжҺҘеҸ—зҡ„ж•°жҚ®е’Ңдә§з”ҹзҡ„ж•°жҚ®зҡ„йЎәеәҸдёҘж јдёҖиҮҙпјҢе°ұжңүеҸҜиғҪеӣ дёә(ж¶ҲжҒҜ)ж•°жҚ®д№ұеәҸеёҰжқҘж•°жҚ®иҰҶзӣ–пјҢжңҖз»ҲеёҰжқҘдёҚдёҖиҮҙй—®йўҳгҖӮ
жҲ‘们иҮӘз ”зҡ„ж•°жҚ®еҗҢжӯҘе·Ҙе…·еә•еұӮдҪҝз”Ёзҡ„ж¶ҲжҒҜйҳҹеҲ—жҳҜkakfaпјҢпјҢkafkaеҜ№дәҺж¶ҲжҒҜзҡ„еӯҳеӮЁпјҢеҸӘиғҪеҒҡеҲ°еұҖйғЁжңүеәҸжҖ§(е…·дҪ“жқҘиҜҙжҳҜжҜҸдёҖдёӘpartitionзҡ„жңүеәҸ)гҖӮжҲ‘们еҸҜд»ҘжҠҠеҗҢдёҖдё»й”®зҡ„ж¶ҲжҒҜи·Ҝз”ұиҮіеҗҢдёҖеҲҶеҢәпјҢиҝҷж ·дёҖиҮҙжҖ§дёҖиҲ¬еҸҜд»ҘдҝқиҜҒгҖӮдҪҶжҳҜпјҢеҰӮжһңеӯҳеңЁдёҖеҜ№еӨҡзҡ„е…ізі»пјҢе°ұж— жі•дҝқиҜҒжҜҸдёҖиЎҢеҸҳжӣҙжңүеәҸпјҢи§ҒеҰӮдёӢдҫӢеӯҗгҖӮ

йӮЈд№ҲйңҖиҰҒйҖҡиҝҮеҸҚжҹҘж•°жҚ®жәҗиҺ·еҸ–жңҖж–°ж•°жҚ®дҝқиҜҒдёҖиҮҙжҖ§гҖӮ
дҪҶжҳҜпјҢеҸҚжҹҘд№ҹдёҚжҳҜвҖң银弹вҖңпјҢйңҖиҰҒиҖғиҷ‘дёӨдёӘй—®йўҳгҖӮ
1)еҰӮжһңж¶ҲжҒҜеҸҳжӣҙжқҘжәҗдәҺиҜ»еҶҷе®һдҫӢпјҢиҖҢеҸҚжҹҘ ж•°жҚ®еә“жҳҜжҹҘеҸӘиҜ»е®һдҫӢпјҢйӮЈе°ұдјҡеӯҳеңЁиҜ»еҶҷе®һдҫӢ延иҝҹеҜјиҮҙзҡ„ж•°жҚ®дёҚдёҖиҮҙй—®йўҳгҖӮеӣ жӯӨпјҢйңҖиҰҒдҝқиҜҒ ж¶ҲжҒҜеҸҳжӣҙжқҘжәҗ е’Ң еҸҚжҹҘж•°жҚ®еә“ зҡ„е®һдҫӢжҳҜеҗҢдёҖдёӘгҖӮ
2)еҸҚжҹҘеҜ№ж•°жҚ®еә“дјҡеёҰжқҘйўқеӨ–жҖ§иғҪејҖй”ҖпјҢйңҖиҰҒд»”з»ҶиҜ„дј°е…ЁйҮҸж—¶еҖҷзҡ„еҪұе“ҚгҖӮ
3.4.4 ж•°жҚ®е®һж—¶жҖ§й—®йўҳ
延иҝҹдё»иҰҒйңҖиҰҒжіЁж„ҸеҮ ж–№йқўзҡ„й—®йўҳпјҢе№¶ж №жҚ®дёҡеҠЎе®һйҷ…жғ…еҶөеҒҡиҜ„дј°е’ҢиЎЎйҮҸгҖӮ
1)ж•°жҚ®еҗҢжӯҘе№іеҸ°зҡ„з§’зә§е»¶иҝҹ
2)еҰӮжһңж¶ҲжҒҜи®ўйҳ…е’ҢеҸҚжҹҘж•°жҚ®еә“йғҪжҳҜиҗҪеңЁеҸӘиҜ»е®һдҫӢдёҠпјҢйӮЈд№ҲйҷӨдәҶдёҠиҝ°ж•°жҚ®еҗҢжӯҘе№іеҸ°зҡ„з§’зә§е»¶иҝҹпјҢиҝҳдјҡжңүж•°жҚ®еә“дё»д»ҺеҗҢжӯҘзҡ„延иҝҹ
3)е®ҪиЎЁеҲ°жҗңзҙўе№іеҸ°зҡ„з§’зә§е»¶иҝҹ
еҸӘжңүиғҪеӨҹж»Ўи¶ідёҡеҠЎеңәжҷҜзҡ„ж–№жЎҲпјҢжүҚжҳҜеҗҲйҖӮзҡ„ж–№жЎҲгҖӮ
3.4.5 еҲҶиЎЁеҗҺеӯҳеӮЁе®№йҮҸдјҳеҢ–
з”ұдәҺж•°жҚ®еҗҢжӯҘиҝҮзЁӢдёӯпјҢеҜ№дәҺеҚ•иЎЁиҖҢиЁҖпјҢдёҚжҳҜдёҘж јжҢүз…§йҖ’еўһжҸ’е…Ҙзҡ„пјҢеӣ жӯӨдјҡдә§з”ҹеҫҲеӨҡвҖқеӯҳеӮЁз©әжҙһвҖңпјҢдҪҝеҫ—еҗҢжӯҘе®ҢеҗҺзҡ„еӯҳеӮЁжҖ»йҮҸиҝңеӨ§дәҺйў„дј°зҡ„е®№йҮҸгҖӮ
еӣ жӯӨпјҢеңЁж–°еә“з”іиҜ·зҡ„ж—¶еҖҷпјҢеӯҳеӮЁе®№йҮҸеӨҡз”іиҜ·50%гҖӮ
е…·дҪ“еҺҹеӣ еҸҜд»ҘеҸӮиҖғжҲ‘зҡ„иҝҷзҜҮж–Үз« дёәд»Җд№ҲMySQLеҲҶеә“еҲҶиЎЁеҗҺжҖ»еӯҳеӮЁеӨ§е°ҸеҸҳеӨ§дәҶ?
3.5 жң¬з« е°Ҹз»“
иҮіжӯӨпјҢеҲҶеә“еҲҶиЎЁзҡ„第дәҢйҳ¶ж®өе‘ҠдёҖж®өиҗҪгҖӮ
иҝҷдёҖйҳ¶ж®өиё©дәҶйқһеёёеӨҡзҡ„еқ‘гҖӮ
дёҖж–№йқўжҳҜи®ҫи®Ўй«ҳеҸҜз”ЁгҖҒжҳ“жү©еұ•зҡ„еӯҳеӮЁжһ¶жһ„гҖӮеңЁйЎ№зӣ®иҝӣеұ•иҝҮзЁӢдёӯпјҢд№ҹеҒҡдәҶеӨҡж¬Ўзҡ„дҝ®ж”№дёҺи®Ёи®әпјҢеҢ…жӢ¬mysqlж•°жҚ®еҶ—дҪҷж•°йҮҸгҖҒжҗңзҙўе№іеҸ°зҡ„зҙўеј•и®ҫи®ЎгҖҒжөҒйҮҸж”ҫеӨ§гҖҒеҲҶиЎЁй”®дҝ®ж”№зӯүй—®йўҳгҖӮ
еҸҰдёҖж–№йқўжҳҜвҖңж•°жҚ®еҗҢжӯҘвҖқжң¬иә«жҳҜдёҖдёӘйқһеёёеӨҚжқӮзҡ„ж“ҚдҪңпјҢжӯЈеҰӮжң¬з« жңҖдҪіе®һи·өдёӯжҸҗеҸҠзҡ„е®һж—¶жҖ§гҖҒдёҖиҮҙжҖ§гҖҒдёҖеҜ№еӨҡзӯүй—®йўҳпјҢйңҖиҰҒеј•иө·й«ҳеәҰйҮҚи§ҶгҖӮ
еӣ жӯӨпјҢжӣҙеҠ дҫқиө–дәҺж•°жҚ®ж ЎйӘҢеҜ№жңҖз»ҲдёҡеҠЎйҖ»иҫ‘жӯЈзЎ®гҖҒж•°жҚ®еҗҢжӯҘжӯЈзЎ®зҡ„жЈҖйӘҢ!
еңЁе®ҢжҲҗиҝҷдёҖйҳ¶ж®өеҗҺпјҢеҸҜд»ҘжӯЈејҸиҝӣе…ҘдёҡеҠЎеҲҮжҚўзҡ„йҳ¶ж®өгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢж•°жҚ®ж ЎйӘҢд»Қ然дјҡеңЁдёӢдёҖйҳ¶ж®өеҸ‘жҢҘе…ій”®жҖ§дҪңз”ЁгҖӮ
4.第дёүйҳ¶ж®өпјҡж”№йҖ е’ҢдёҠзәҝ(ж…ҺйҮҚ)
еүҚдёӨдёӘйҳ¶ж®өе®ҢжҲҗеҗҺпјҢејҖе§ӢдёҡеҠЎеҲҮжҚўжөҒзЁӢпјҢдё»иҰҒжӯҘйӘӨеҰӮдёӢпјҡ
1)дёӯеҸ°жңҚеҠЎйҮҮз”ЁеҚ•иҜ» еҸҢеҶҷ зҡ„жЁЎејҸ
2)ж—§иЎЁеҫҖж–°иЎЁејҖзқҖж•°жҚ®еҗҢжӯҘ
3) жүҖжңүжңҚеҠЎеҚҮзә§дҫқиө–зҡ„projectDBзүҲжң¬пјҢдёҠзәҝRPCпјҢеҰӮжһңеҮәзҺ°й—®йўҳпјҢйҷҚзүҲжң¬еҚіеҸҜеӣһж»ҡ(дёҠзәҝжҲҗеҠҹеҗҺпјҢеҚ•иҜ»ж–°еә“пјҢеҸҢеҶҷж–°ж—§еә“)
4)жЈҖжҹҘзӣ‘жҺ§зЎ®дҝқжІЎжңү дёӯеҸ°жңҚеҠЎ д»ҘеӨ–зҡ„е…¶д»–жңҚеҠЎи®ҝй—®ж—§еә“ж—§иЎЁ
5)еҒңжӯўж•°жҚ®еҗҢжӯҘ
6)еҲ йҷӨж—§иЎЁ
4.1 жҹҘиҜўж”№йҖ
еҰӮдҪ•йӘҢиҜҒжҲ‘们еүҚдёӨдёӘйҳ¶ж®өи®ҫи®ЎжҳҜеҗҰеҗҲзҗҶ?иғҪеҗҰе®Ңе…ЁиҰҶзӣ–жҹҘиҜўзҡ„дҝ®ж”№ жҳҜдёҖдёӘеүҚжҸҗжқЎд»¶гҖӮ
еҪ“ж–°иЎЁи®ҫи®Ўе®ҢжҜ•еҗҺпјҢе°ұеҸҜд»Ҙд»Ҙж–°иЎЁдёәж ҮеҮҶпјҢдҝ®ж”№иҖҒзҡ„жҹҘиҜўгҖӮ
д»Ҙжң¬йЎ№зӣ®дёәдҫӢпјҢйңҖиҰҒе°Ҷж—§зҡ„sqlеңЁ ж–°зҡ„дёӯеҸ°жңҚеҠЎдёӯ иҝӣиЎҢж”№йҖ гҖӮ
1)иҜ»жҹҘиҜўзҡ„ж”№йҖ
еҸҜиғҪжҹҘиҜўдјҡж¶үеҸҠд»ҘдёӢеҮ дёӘж–№йқўпјҡ
a)ж №жҚ®жҹҘиҜўжқЎд»¶пјҢйңҖиҰҒе°Ҷpk1е’Ңpk2зҡ„inner joinж”№дёәеҜ№еә”еҲҶиЎЁй”®зҡ„ж–°иЎЁиЎЁеҗҚ
b)йғЁеҲҶsqlзҡ„еәҹејғеӯ—ж®өеӨ„зҗҶ
c)йқһеҲҶиЎЁй”®жҹҘиҜўж”№дёәиө°жҗңзҙўе№іеҸ°зҡ„жҹҘиҜўпјҢжіЁж„ҸдҝқиҜҒиҜӯд№үдёҖиҮҙ
d)жіЁж„ҸеҶҷеҚ•жөӢйҒҝе…ҚдҪҺзә§й”ҷиҜҜпјҢдё»иҰҒжҳҜDAOеұӮйқўгҖӮ
еҸӘжңүж–°иЎЁз»“жһ„е’ҢеӯҳеӮЁжһ¶жһ„иғҪе®Ңе…ЁйҖӮеә”жҹҘиҜўж”№йҖ пјҢжүҚиғҪи®ӨдёәеүҚйқўзҡ„и®ҫи®ЎжҡӮж—¶жІЎжңүй—®йўҳгҖӮ
еҪ“然пјҢиҝҷйҮҢиҝҳжңүдёӘеүҚжҸҗжқЎд»¶пјҢе°ұжҳҜзӣёе…іжҹҘиҜўе·Із»Ҹе…ЁйғЁж”¶жӢўпјҢжІЎжңүйҒ—жјҸгҖӮ
2) еҶҷжҹҘиҜўзҡ„ж”№йҖ
йҷӨдәҶзӣёе…іеӯ—ж®өзҡ„жӣҙж”№д»ҘеӨ–пјҢжӣҙйҮҚиҰҒзҡ„жҳҜпјҢйңҖиҰҒж”№йҖ дёәж—§иЎЁгҖҒж–°иЎЁзҡ„еҸҢеҶҷжЁЎејҸгҖӮ
иҝҷйҮҢеҸҜиғҪж¶үеҸҠеҲ°е…·дҪ“дёҡеҠЎеҶҷе…ҘйҖ»иҫ‘пјҢжң¬йЎ№зӣ®е°ӨдёәеӨҚжқӮпјҢйңҖиҰҒж”№йҖ иҝҮзЁӢдёӯдёҺдёҡеҠЎж–№е……еҲҶжІҹйҖҡпјҢдҝқиҜҒеҶҷе…ҘйҖ»иҫ‘жӯЈзЎ®гҖӮ
еҸҜд»ҘеңЁеҸҢеҶҷдёҠеҗ„еҠ дёҖдёӘй…ҚзҪ®ејҖе…іпјҢж–№дҫҝеҲҮжҚўгҖӮеҰӮжһңеҸҢеҶҷдёӯеҸ‘зҺ°ж–°еә“еҶҷе…Ҙжңүй—®йўҳпјҢеҸҜд»Ҙеҝ«йҖҹе…ій—ӯгҖӮ
еҗҢж—¶пјҢеҸҢеҶҷиҝҮзЁӢдёӯдёҚе…ій—ӯ ж—§еә“еҲ°ж–°еә“ зҡ„ж•°жҚ®еҗҢжӯҘгҖӮ
дёәд»Җд№Ҳе‘ў?дё»иҰҒиҝҳжҳҜз”ұдәҺжҲ‘们项зӣ®зҡ„зү№ж®ҠжҖ§гҖӮз”ұдәҺжҲ‘们ж¶үеҸҠеҲ°еҮ еҚҒдёӘжңҚеҠЎпјҢдёәдәҶйҷҚдҪҺйЈҺйҷ©пјҢеҝ…йЎ»еҲҶжү№дёҠзәҝгҖӮеӣ жӯӨпјҢеӯҳеңЁжҜ”иҫғйә»зғҰзҡ„дёӯй—ҙжҖҒпјҢдёҖйғЁеҲҶжңҚеҠЎжҳҜиҖҒйҖ»иҫ‘пјҢдёҖйғЁеҲҶжңҚеҠЎжҳҜж–°йҖ»иҫ‘пјҢеҝ…йЎ»дҝқиҜҒдёӯй—ҙжҖҒзҡ„ж•°жҚ®жӯЈзЎ®жҖ§пјҢе…·дҪ“и§Ғ4.5.1зҡ„еҲҶжһҗгҖӮ
4.2 жңҚеҠЎеҢ–ж”№йҖ
дёәд»Җд№ҲйңҖиҰҒж–°е»әдёҖдёӘ жңҚеҠЎжқҘ жүҝиҪҪж”№йҖ еҗҺзҡ„жҹҘиҜўе‘ў?
дёҖж–№йқўжҳҜдёәдәҶж”№йҖ иғҪеӨҹж–№дҫҝзҡ„еҚҮзә§дёҺеӣһж»ҡеҲҮжҚўпјҢеҸҰдёҖж–№йқўжҳҜдёәдәҶе°ҶжҹҘиҜўж”¶жӢўпјҢдҪңдёәдёҖдёӘдёӯеҸ°еҢ–зҡ„жңҚеҠЎжқҘжҸҗдҫӣзӣёеә”зҡ„жҹҘиҜўиғҪеҠӣгҖӮ
е°Ҷж”№йҖ еҗҺзҡ„ж–°зҡ„жҹҘиҜўж”ҫеңЁжңҚеҠЎдёӯпјҢ然еҗҺjarеҢ…дёӯзҡ„еҺҹжң¬жҹҘиҜўпјҢе…ЁйғЁжӣҝжҚўжҲҗиҝҷдёӘжңҚеҠЎзҡ„clientи°ғз”ЁгҖӮ
еҗҢж—¶пјҢеҚҮзә§jarеҢ…зүҲжң¬еҲ°3.0.0-SNAPSHOTгҖӮ
4.3 жңҚеҠЎеҲҶжү№дёҠзәҝ
дёәдәҶйҷҚдҪҺйЈҺйҷ©пјҢйңҖиҰҒе®үжҺ’д»Һйқһж ёеҝғжңҚеҠЎеҲ°ж ёеҝғжңҚеҠЎзҡ„еҲҶжү№дёҠзәҝгҖӮ
жіЁж„ҸпјҢеҲҶжү№дёҠзәҝиҝҮзЁӢдёӯпјҢз”ұдәҺеҶҷжңҚеҠЎеҫҖеҫҖжҳҜж ёеҝғжңҚеҠЎпјҢжүҖд»Ҙе®үжҺ’еңЁеҗҺйқўгҖӮеҸҜиғҪеҮәзҺ°йқһж ёеҝғзҡ„иҜ»жңҚеҠЎдёҠзәҝдәҶпјҢиҝҷж—¶еҖҷдјҡжңүиҜ»ж–°иЎЁгҖҒеҶҷж—§иЎЁзҡ„дёӯй—ҙзҠ¶жҖҒгҖӮ
1) жүҖжңүзӣёе…іжңҚеҠЎдҪҝз”Ё йҮҚжһ„еҲҶж”Ҝ еҚҮзә§projectdbзүҲжң¬еҲ°3.0.0-SNAPSHOT并йғЁзҪІеҶ…зҪ‘зҺҜеўғ;
2) дёҡеҠЎжңҚеҠЎдҫқиө–дәҺ дёӯеҸ°жңҚеҠЎпјҢйңҖиҰҒи®ўйҳ…жңҚеҠЎ
3) ејҖйҮҚжһ„еҲҶж”Ҝ(дёҚиҰҒдёҺжӯЈеёёиҝӯд»ЈеҲҶж”ҜеҗҲ并)пјҢйғЁзҪІеҶ…зҪ‘пјҢеҶ…зҪ‘йў„и®ЎжөӢиҜ•дёӨе‘Ёд»ҘдёҠ
дҪҝз”ЁдёҖдёӘж–°зҡ„ йҮҚжһ„еҲҶж”Ҝ жҳҜдёәдәҶеңЁеҶ…зҪ‘жөӢиҜ•дёӨе‘Ёзҡ„ж—¶еҖҷпјҢдёҚеҪұе“ҚдёҡеҠЎжӯЈеёёиҝӯд»ЈгҖӮжҜҸе‘Ёжӣҙж–°зҡ„дёҡеҠЎеҲҶж”ҜеҸҜд»ҘmergeеҲ°йҮҚжһ„еҲҶж”ҜдёҠйғЁзҪІеҶ…зҪ‘пјҢ然еҗҺеӨ–зҪ‘дҪҝз”ЁдёҡеҠЎеҲҶж”ҜmergeеҲ°masterдёҠйғЁзҪІгҖӮ
еҪ“然пјҢеҰӮжһңд»ҺзәҝдёҠзәҝдёӢд»Јз ҒеҲҶж”ҜдёҖиҮҙзҡ„и§’еәҰпјҢд№ҹеҸҜд»ҘйҮҚжһ„еҲҶж”Ҝе’ҢдёҡеҠЎеҲҶж”ҜдёҖиө·жөӢиҜ•дёҠзәҝпјҢеҜ№ејҖеҸ‘е’ҢжөӢиҜ•зҡ„еҺӢеҠӣдјҡиҫғеӨ§гҖӮ
4)еҲҶжү№дёҠзәҝиҝҮзЁӢдёӯпјҢеҰӮжһңзў°еҲ°дҫқиө–еҶІзӘҒзҡ„й—®йўҳпјҢйңҖиҰҒеҸҠж—¶и§ЈеҶіе№¶еҸҠж—¶жӣҙж–°еҲ°иҜҘж–ҮжЎЈдёӯ
5)жңҚеҠЎдёҠзәҝеүҚпјҢеҝ…йЎ»иҰҒжұӮдёҡеҠЎејҖеҸ‘жҲ–иҖ…жөӢиҜ•пјҢжҳҺзЎ®иҜ„дј°е…·дҪ“apiе’ҢйЈҺйҷ©зӮ№пјҢеҒҡеҘҪеӣһеҪ’гҖӮ
иҝҷйҮҢеҶҚж¬ЎжҸҗйҶ’пјҢдёҠзәҝе®ҢжҲҗеҗҺпјҢиҜ·дёҚиҰҒжјҸжҺүзҰ»зәҝзҡ„ж•°жҚ®еҲҶжһҗдёҡеҠЎ!иҜ·дёҚиҰҒжјҸжҺүзҰ»зәҝзҡ„ж•°жҚ®еҲҶжһҗдёҡеҠЎ!иҜ·дёҚиҰҒжјҸжҺүзҰ»зәҝзҡ„ж•°жҚ®еҲҶжһҗдёҡеҠЎ!
4.4 ж—§иЎЁдёӢзәҝжөҒзЁӢ
1)жЈҖжҹҘзӣ‘жҺ§зЎ®дҝқжІЎжңүдёӯеҸ°жңҚеҠЎд»ҘеӨ–зҡ„е…¶д»–жңҚеҠЎи®ҝй—®ж—§еә“ж—§иЎЁ
2)жЈҖжҹҘж•°жҚ®еә“дёҠзҡ„sqlе®Ўи®ЎпјҢзЎ®дҝқжІЎжңүе…¶д»–жңҚеҠЎд»Қ然иҜ»еҸ–ж—§иЎЁж•°жҚ®
3)еҒңжӯўж•°жҚ®еҗҢжӯҘ
4)еҲ йҷӨж—§иЎЁ
4.5 жңҖдҪіе®һи·ө
4.5.1 еҶҷе®Ңз«ӢеҚіиҜ»еҸҜиғҪиҜ»дёҚеҲ°
еңЁеҲҶжү№дёҠзәҝиҝҮзЁӢдёӯпјҢйҒҮеҲ°дәҶеҶҷе®Ңз«ӢеҚіиҜ»еҸҜиғҪиҜ»дёҚеҲ°зҡ„жғ…еҶөгҖӮз”ұдәҺдёҡеҠЎдј—еӨҡпјҢжҲ‘们йҮҮз”ЁдәҶеҲҶжү№дёҠзәҝзҡ„ж–№ејҸйҷҚдҪҺйЈҺйҷ©пјҢеӯҳеңЁдёҖйғЁеҲҶеә”з”Ёе·Із»ҸеҚҮзә§пјҢдёҖйғЁеҲҶеә”з”Ёе°ҡжңӘеҚҮзә§зҡ„жғ…еҶөгҖӮжңӘеҚҮзә§зҡ„жңҚеҠЎд»Қ然еҫҖж—§иЎЁеҶҷж•°жҚ®пјҢиҖҢеҚҮзә§еҗҺзҡ„еә”з”Ёдјҡд»Һж–°иЎЁиҜ»ж•°жҚ®пјҢеҪ“延иҝҹеӯҳеңЁж—¶пјҢеҫҲеӨҡж–°еҶҷе…Ҙзҡ„и®°еҪ•ж— жі•иҜ»еҲ°пјҢеҜ№е…·дҪ“дёҡеҠЎеңәжҷҜйҖ жҲҗдәҶжҜ”иҫғдёҘйҮҚзҡ„еҪұе“ҚгҖӮ
延иҝҹзҡ„еҺҹеӣ дё»иҰҒжңүдёӨдёӘпјҡ
1)еҶҷжңҚеҠЎиҝҳжІЎжңүеҚҮзә§пјҢиҝҳжІЎжңүејҖе§ӢеҸҢеҶҷпјҢиҝҳжҳҜеҶҷж—§иЎЁпјҢиҝҷж—¶еҖҷдјҡжңүиҜ»ж–°иЎЁгҖҒеҶҷж—§иЎЁзҡ„дёӯй—ҙзҠ¶жҖҒпјҢж–°ж—§иЎЁеӯҳеңЁеҗҢжӯҘ延иҝҹгҖӮ
2)дёәдәҶйҒҝе…Қдё»еә“еҺӢеҠӣпјҢж–°иЎЁж•°жҚ®жҳҜд»Һж—§иЎЁиҺ·еҸ–еҸҳжӣҙгҖҒ然еҗҺеҸҚжҹҘж—§иЎЁеҸӘиҜ»е®һдҫӢзҡ„ж•°жҚ®иҝӣиЎҢеҗҢжӯҘзҡ„пјҢдё»д»Һеә“жң¬иә«еӯҳеңЁдёҖе®ҡ延иҝҹгҖӮ
и§ЈеҶіж–№жЎҲдёҖиҲ¬жңүдёӨз§Қпјҡ
1)ж•°жҚ®еҗҢжӯҘж”№дёәеҸҢеҶҷйҖ»иҫ‘гҖӮ
2)еңЁиҜ»жҺҘеҸЈеҒҡиЎҘеҒҝпјҢеҰӮжһңж–°иЎЁжҹҘдёҚеҲ°пјҢеҲ°ж—§иЎЁеҶҚжҹҘдёҖж¬ЎгҖӮ
4.5.2 ж•°жҚ®еә“дёӯй—ҙ件е”ҜдёҖIDжӣҝжҚўиҮӘеўһдё»й”®(еҲ’йҮҚзӮ№пјҢж•Ій»‘жқҝ)
з”ұдәҺеҲҶиЎЁеҗҺпјҢ继з»ӯдҪҝз”ЁеҚ•иЎЁзҡ„иҮӘеўһдё»й”®пјҢдјҡеҜјиҮҙе…ЁеұҖдё»й”®еҶІзӘҒгҖӮеӣ жӯӨпјҢйңҖиҰҒдҪҝз”ЁеҲҶеёғејҸе”ҜдёҖIDжқҘд»ЈжӣҝиҮӘеўһдё»й”®гҖӮеҗ„з§Қз®—жі•зҪ‘дёҠжҜ”иҫғеӨҡпјҢжң¬йЎ№зӣ®йҮҮз”Ёзҡ„жҳҜж•°жҚ®еә“иҮӘеўһsequenceз”ҹжҲҗж–№ејҸгҖӮ
ж•°жҚ®еә“иҮӘеўһsequenceзҡ„еҲҶеёғејҸIDз”ҹжҲҗеҷЁпјҢжҳҜдёҖдёӘдҫқиө–Mysqlзҡ„еӯҳеңЁпјҢ е®ғзҡ„еҹәжң¬еҺҹзҗҶжҳҜеңЁMysqlдёӯеӯҳе…ҘдёҖдёӘж•°еҖјпјҢ жҜҸжңүдёҖеҸ°жңәеҷЁеҺ»иҺ·еҸ–IDзҡ„ж—¶еҖҷпјҢйғҪдјҡеңЁеҪ“еүҚIDдёҠзҙҜеҠ дёҖе®ҡзҡ„ж•°йҮҸжҜ”еҰӮиҜҙ2000пјҢ 然еҗҺжҠҠеҪ“еүҚзҡ„еҖјеҠ дёҠ2000иҝ”еӣһз»ҷжңҚеҠЎеҷЁгҖӮиҝҷж ·жҜҸдёҖеҸ°жңәеҷЁйғҪеҸҜд»Ҙ继з»ӯйҮҚеӨҚжӯӨж“ҚдҪңиҺ·еҫ—е”ҜдёҖidеҢәй—ҙгҖӮ
дҪҶжҳҜд»…д»…жңүе…ЁеұҖе”ҜдёҖIDе°ұеӨ§еҠҹе‘ҠжҲҗдәҶеҗ—?жҳҫ然дёҚжҳҜпјҢеӣ дёәиҝҷйҮҢиҝҳдјҡеӯҳеңЁж–°ж—§иЎЁзҡ„idеҶІзӘҒй—®йўҳгҖӮ
еӣ дёәжңҚеҠЎжҜ”иҫғеӨҡпјҢдёәдәҶйҷҚдҪҺйЈҺйҷ©йңҖиҰҒеҲҶжү№дёҠзәҝгҖӮеӣ жӯӨпјҢеӯҳеңЁдёҖйғЁеҲҶжңҚеҠЎиҝҳжҳҜеҚ•еҶҷж—§иЎЁзҡ„йҖ»иҫ‘пјҢдёҖйғЁеҲҶжңҚеҠЎжҳҜеҸҢеҶҷзҡ„йҖ»иҫ‘гҖӮ
иҝҷж ·зҡ„зҠ¶жҖҒдёӯпјҢж—§иЎЁзҡ„idзӯ–з•ҘдҪҝз”Ёзҡ„жҳҜauto_incrementгҖӮеҰӮжһңеҸӘжңүеҚ•еҗ‘ж•°жҚ®жқҘеҫҖзҡ„иҜқ(ж—§иЎЁеҲ°ж–°иЎЁ)пјҢеҸӘйңҖиҰҒз»ҷж—§иЎЁзҡ„idйў„з•ҷдёҖдёӘеҢәй—ҙж®өпјҢsequenceд»ҺдёҖдёӘиҫғеӨ§зҡ„иө·е§ӢеҖјејҖе§Ӣе°ұиғҪйҒҝе…ҚеҶІзӘҒгҖӮ
дҪҶиҜҘйЎ№зӣ®дёӯпјҢиҝҳжңүж–°иЎЁж•°жҚ®е’Ңж—§иЎЁж•°жҚ®зҡ„еҸҢеҶҷпјҢеҰӮжһңйҮҮз”ЁдёҠиҝ°ж–№жЎҲпјҢиҫғеӨ§зҡ„idеҶҷе…ҘеҲ°ж—§иЎЁпјҢж—§иЎЁзҡ„auto_incrementе°Ҷдјҡиў«йҮҚзҪ®еҲ°иҜҘеҖјпјҢиҝҷж ·еҚ•еҶҷж—§иЎЁзҡ„жңҚеҠЎдә§з”ҹзҡ„йҖ’еўһidзҡ„и®°еҪ•еҝ…然дјҡеҮәзҺ°еҶІзӘҒгҖӮ
жүҖд»ҘиҝҷйҮҢдәӨжҚўдәҶеҸҢж–№зҡ„еҢәй—ҙж®өпјҢж—§еә“д»ҺиҫғеӨ§зҡ„auto_incrementиө·е§ӢеҖјејҖе§ӢпјҢж–°иЎЁйҖүжӢ©зҡ„id(д№ҹе°ұжҳҜsequenceзҡ„иҢғеӣҙ)д»ҺеӨ§дәҺж—§иЎЁзҡ„жңҖеӨ§и®°еҪ•зҡ„idејҖе§ӢйҖ’еўһпјҢе°ҸдәҺж—§иЎЁauto_incrementеҚіе°Ҷи®ҫзҪ®зҡ„иө·е§ӢеҖјпјҢеҫҲеҘҪзҡ„йҒҝе…ҚдәҶidеҶІзӘҒй—®йўҳгҖӮ
1)еҲҮжҚўеүҚпјҡ
sequenceзҡ„иө·е§Ӣidи®ҫзҪ®дёәеҪ“еүҚж—§иЎЁзҡ„иҮӘеўһidеӨ§е°ҸпјҢ然еҗҺж—§иЎЁзҡ„иҮӘеўһidйңҖиҰҒж”№еӨ§пјҢйў„з•ҷдёҖж®өеҢәй—ҙпјҢз»ҷж—§иЎЁзҡ„иҮӘеўһid继з»ӯдҪҝз”ЁпјҢйҳІжӯўжңӘеҚҮзә§дёҡеҠЎеҶҷе…Ҙж—§иЎЁзҡ„ж•°жҚ®еҗҢжӯҘеҲ°ж–°еә“еҗҺдә§з”ҹidеҶІзӘҒ;
2)еҲҮжҚўеҗҺ
ж— йңҖд»»дҪ•ж”№йҖ пјҢж–ӯејҖж•°жҚ®еҗҢжӯҘеҚіеҸҜ
3)дјҳзӮ№
еҸӘз”ЁдёҖд»Ҫд»Јз Ғ;
еҲҮжҚўеҸҜд»ҘдҪҝз”ЁејҖе…іиҝӣиЎҢпјҢдёҚз”ЁеҚҮзә§ж”№йҖ ;
еҰӮжһңдёҮдёҖдёӯйҖ”ж—§иЎЁзҡ„autoincrementиў«ејӮеёёж•°жҚ®еҸҳеӨ§дәҶпјҢд№ҹдёҚдјҡйҖ жҲҗд»Җд№Ҳй—®йўҳгҖӮ
4)зјәзӮ№
еҰӮжһңж—§иЎЁеҶҷеӨұиҙҘдәҶпјҢж–°иЎЁеҶҷжҲҗеҠҹдәҶпјҢйңҖиҰҒж—Ҙеҝ—иҫ…еҠ©еӨ„зҗҶ
4.6 жң¬з« е°Ҹз»“
е®ҢжҲҗж—§иЎЁдёӢзәҝеҗҺпјҢж•ҙдёӘеҲҶеә“еҲҶиЎЁзҡ„ж”№йҖ е°ұе®ҢжҲҗдәҶгҖӮ
еңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢйңҖиҰҒе§Ӣз»ҲдҝқжҢҒеҜ№зәҝдёҠдёҡеҠЎзҡ„敬з•ҸпјҢд»”з»ҶжҖқиҖғжҜҸдёӘеҸҜиғҪеҸ‘з”ҹзҡ„й—®йўҳпјҢжғіеҘҪеҝ«йҖҹеӣһж»ҡж–№жЎҲ(еңЁдёүдёӘйҳ¶ж®өжҸҗеҲ°дәҶprojectdbзҡ„jarеҢ…зүҲжң¬иҝӯд»ЈпјҢд»Һ1.0.0-SNAPSHOTеҲ°3.0.0-SNAPSHOTпјҢеҢ…еҗ«дәҶжҜҸдёӘйҳ¶ж®өдёҚеҗҢзҡ„еҸҳжӣҙпјҢеңЁдёҚеҗҢйҳ¶ж®өзҡ„еҲҶжү№дёҠзәҝзҡ„иҝҮзЁӢдёӯпјҢйҖҡиҝҮjarеҢ…зүҲжң¬зҡ„ж–№ејҸиҝӣиЎҢеӣһж»ҡпјҢеҸ‘жҢҘдәҶе·ЁеӨ§дҪңз”Ё)пјҢйҒҝе…ҚйҖ жҲҗйҮҚеӨ§ж•…йҡңгҖӮ
5.зЁіе®ҡжҖ§дҝқйҡң
иҝҷдёҖз« дё»иҰҒеҶҚж¬Ўејәи°ғзЁіе®ҡжҖ§зҡ„дҝқйҡңжүӢж®өгҖӮдҪңдёәжң¬ж¬ЎйЎ№зӣ®зҡ„йҮҚиҰҒзӣ®ж Үд№ӢдёҖпјҢзЁіе®ҡжҖ§е…¶е®һиҙҜз©ҝеңЁж•ҙдёӘйЎ№зӣ®е‘ЁжңҹеҶ…пјҢеҹәжң¬дёҠеңЁдёҠж–Үеҗ„дёӘзҺҜиҠӮйғҪе·Із»ҸйғҪжңүжҸҗеҲ°пјҢжҜҸдёҖдёӘзҺҜиҠӮйғҪиҰҒеј•иө·и¶іеӨҹзҡ„йҮҚи§ҶпјҢд»”з»Ҷи®ҫи®Ўе’ҢиҜ„дј°ж–№жЎҲпјҢеҒҡеҲ°еҝғдёӯжңүж•°пјҢиҖҢдёҚжҳҜйқ еӨ©еҗғйҘӯпјҡ
1)ж–°иЎЁи®ҫи®Ўеҝ…йЎ»и·ҹдёҡеҠЎж–№е……еҲҶжІҹйҖҡгҖҒдҝқиҜҒreviewгҖӮ
2)еҜ№дәҺвҖңж•°жҚ®еҗҢжӯҘвҖқпјҢеҝ…йЎ»жңүж•°жҚ®ж ЎйӘҢдҝқйҡңж•°жҚ®жӯЈзЎ®жҖ§пјҢеҸҜиғҪеҜјиҮҙж•°жҚ®дёҚжӯЈзЎ®зҡ„еҺҹеӣ дёҠж–Үе·Із»ҸжҸҗеҲ°жқҘеҫҲеӨҡпјҢеҢ…жӢ¬е®һж—¶жҖ§гҖҒдёҖиҮҙжҖ§зҡ„й—®йўҳгҖӮдҝқиҜҒж•°жҚ®жӯЈзЎ®жҳҜдёҠзәҝзҡ„еӨ§еүҚжҸҗгҖӮ
3)жҜҸдёҖйҳ¶ж®өзҡ„еҸҳеҠЁпјҢйғҪеҝ…йЎ»еҒҡеҘҪеҝ«йҖҹеӣһж»ҡйғҪйў„жЎҲгҖӮ
4)дёҠзәҝиҝҮзЁӢпјҢйғҪд»ҘеҲҶжү№дёҠзәҝзҡ„еҪўејҸпјҢд»Һйқһж ёеҝғдёҡеҠЎејҖе§ӢеҒҡиҜ•зӮ№пјҢйҒҝе…Қж•…йҡңжү©еӨ§гҖӮ
5)зӣ‘жҺ§е‘ҠиӯҰиҰҒй…ҚзҪ®е…ЁйқўпјҢеҮәзҺ°й—®йўҳеҸҠ时收еҲ°е‘ҠиӯҰпјҢеҝ«йҖҹе“Қеә”гҖӮдёҚиҰҒеҝҪз•ҘпјҢеҫҲйҮҚиҰҒпјҢжңүеҮ ж¬ЎеҮәзҺ°иҝҮж•°жҚ®зҡ„й—®йўҳпјҢйғҪжҳҜйҖҡиҝҮе‘ҠиӯҰеҸҠж—¶еҸ‘зҺ°е’Ңи§ЈеҶізҡ„гҖӮ6)еҚ•жөӢпјҢдёҡеҠЎеҠҹиғҪжөӢиҜ•зӯүиҰҒе……еҲҶ
6.йЎ№зӣ®з®ЎзҗҶд№Ӣи·ЁеӣўйҳҹеҚҸдҪң
е…ідәҺвҖңи·ЁеӣўйҳҹеҚҸдҪңвҖқпјҢжң¬ж–Үдё“й—ЁжӢҺеҮәжқҘдҪңдёәдёҖз« гҖӮ
еӣ дёәеңЁиҝҷж ·дёҖдёӘи·Ёеӣўйҳҹзҡ„еӨ§еһӢйЎ№зӣ®ж”№йҖ иҝҮзЁӢдёӯпјҢ科еӯҰзҡ„еӣўйҳҹеҚҸдҪңжҳҜдҝқйҡңж•ҙдҪ“йЎ№зӣ®жҢүж—¶гҖҒй«ҳиҙЁйҮҸе®ҢжҲҗзҡ„дёҚеҸҜзјәе°‘зҡ„еӣ зҙ гҖӮ
дёӢйқўпјҢеҲҶдә«еҮ зӮ№еҝғеҫ—дёҺдҪ“дјҡгҖӮ
6.1 дёҖеҲҮж–ҮжЎЈе…ҲиЎҢ
еӣўйҳҹеҚҸдҪңжңҖеҝҢвҖңз©әеҸЈж— еҮӯвҖқгҖӮ
ж— и®әжҳҜеӣўйҳҹеҲҶе·ҘгҖҒиҝӣеәҰе®үжҺ’жҲ–жҳҜд»»дҪ•йңҖиҰҒеӨҡдәәеҚҸдҪңзҡ„дәӢжғ…пјҢйғҪйңҖиҰҒжңүдёҖдёӘж–ҮжЎЈи®°еҪ•пјҢз”ЁдәҺиҝҪиёӘиҝӣеәҰпјҢжҠҠжҺ§жөҒзЁӢгҖӮ
6.2 дёҡеҠЎжІҹйҖҡдёҺзЎ®и®Ө
жүҖжңүзҡ„иЎЁз»“жһ„ж”№йҖ пјҢеҝ…йЎ»и·ҹзӣёе…ідёҡеҠЎж–№жІҹйҖҡпјҢеҜ№дәҺеҸҜиғҪеӯҳеңЁзҡ„еҺҶеҸІйҖ»иҫ‘пјҢиҝӣиЎҢе…ЁйқўжўізҗҶ;
жүҖжңүи®Ёи®әзЎ®е®ҡеҗҺзҡ„еӯ—ж®өж”№йҖ пјҢеҝ…йЎ»з”ұжҜҸдёӘжңҚеҠЎзҡ„OwnerиҝӣиЎҢзЎ®и®ӨгҖӮ
6.3 иҙЈд»»еҲ°дҪҚ
еҜ№дәҺеӨҡеӣўйҳҹеӨҡдәәж¬Ўзҡ„еҗҲдҪңйЎ№зӣ®пјҢжҜҸдёӘеӣўйҳҹйғҪеә”иҜҘжҳҺзЎ®дёҖдёӘеҜ№жҺҘдәәпјҢз”ұйЎ№зӣ®жҖ»иҙҹиҙЈдәәдёҺеӣўйҳҹе”ҜдёҖеҜ№жҺҘдәәжІҹйҖҡпјҢжҳҺзЎ®еӣўйҳҹе®Ңж•ҙиҝӣеәҰе’Ңе®ҢжҲҗиҙЁйҮҸгҖӮ
вҖңеӨ§иЎЁеҲҶеә“еҲҶиЎЁжҖ»з»“вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





