本篇内容介绍了“MySQL分库分表后总存储变大了的原因是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
1.背景
在完成一个分表项目后,发现分表的数据迁移后,新库所需的存储容量远大于原本两张表的大小。在做了一番查询了解后,完成了优化。
回过头来,需要进一步了解下为什么会出现这样的情况。
与标题的问题的类似问题还有,为什么表数据内容删除了而表大小没有变化。其本质都是一样的。
要回答这些问题,我们需要从mysql的索引模型谈起。
2.InnoDB 的索引模型
在 MySQL 中,索引是在存储引擎层实现的,所以并没有统一的索引标准,即不同存储引擎的索引的工作方式并不一样。
而即使多个存储引擎支持同一种类型的索引,其底层的实现也可能不同。由于 InnoDB 存储引擎在 MySQL 数据库中使用最为广泛,所以接下来就以 InnoDB 为例,分析其中的索引模型。
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。而InnoDB中,使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的,每一个索引会对应一颗B+树。
假设,我们有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引,建表语句如下
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`k` int(11) NOT NULL,
`name` varchar(16) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `k` (`k`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
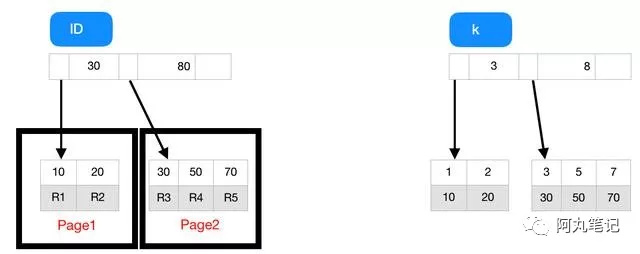
表中 R1~R5 的 (ID,k) 值分别为 (10,1)、(20,2)、(30,3)、(50,5) 和 (70,7),索引id和索引k的B+树的示例示意图如下。
根据叶子节点的内容,索引类型分为主键索引和非主键索引,主键索引的叶子节点存的是整行数据R1~R5,非主键索引的叶子节点内容是主键的值。
从图中可以看出,基于非主键索引的查询需要多扫描一棵索引树才能找到对应的数据。提一句题外话,我们在应用中应该尽量使用主键查询。
3.索引维护
B+ 树为了维护索引有序性,在增删改数据的时候需要做必要的维护。
假设,我们要删掉 R4 这个记录,InnoDB 引擎只会把 R4 这个记录标记为删除。如果之后要再插入一个 ID 在 300 和 600 之间的记录时,可能会复用这个位置。
如果删掉了一个数据页上的所有记录,那么整个数据页就能被复用了。进一步地,如果我们用 delete 命令把整个表的数据删除呢?结果就是,这个表相关的所有的数据页都会被标记为可复用。
但是,无论如何,磁盘文件的大小并不会缩小。
这些被标记为可复用,而并没有实际被使用的空间,就是一些“存储空洞”。
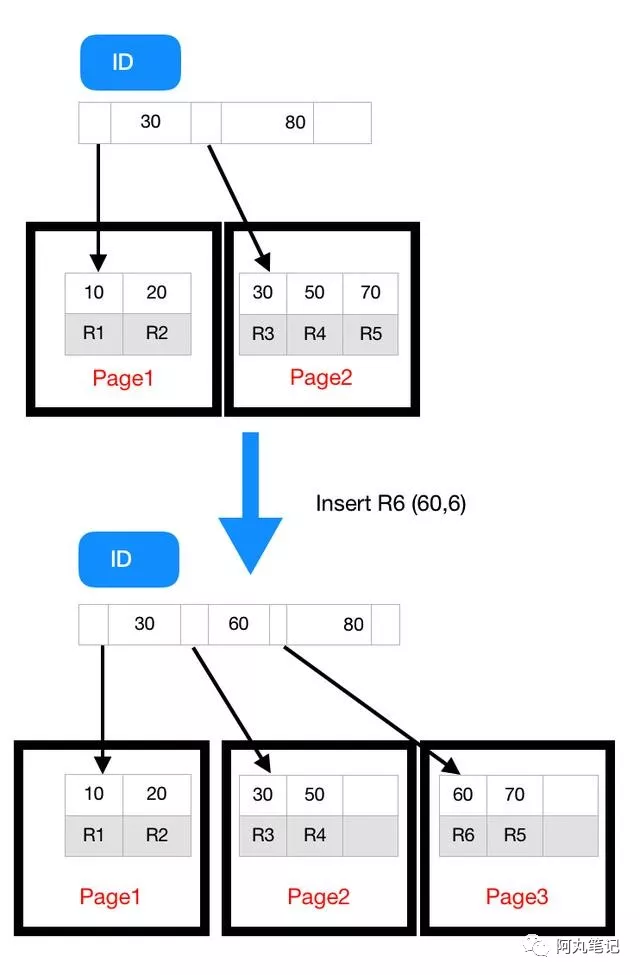
实际上,不止是删除数据会造成空洞,插入数据也会。
以上图为例,如果插入新的行 ID 值为 80,则只需要在 R5 的记录后面插入一个新记录。
如果新插入的 ID 值为 60,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
而更糟的情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,插入一条记录竟然使得整体空间利用率降低大约 50%。
可以看到,由于 page 2 满了,再插入一个 ID 是 60 的数据时,就不得不再申请一个新的页面 page 3 来保存数据了。
页分裂完成后,page 2 的末尾就留下了空洞(注意:实际上,可能不止 1 个记录的位置是空洞)。
另外,更新索引上的值,可以理解为删除一个旧的值,再插入一个新值。不难理解,这也是会造成空洞的。
因此,大量的增删改之后的表,都是可能存在很大的“数据空洞”的。
因此,我们就能解释,为什么分表后的总存储变大了。
因为分表后,需要从老库全量同步数据到新库,数据同步平台开启多个线程进行同步,插入各个分表并不是按照递增的顺序插入的,因此,会产生巨量的“数据空洞”,造成存储空间变大。
如果能够把这些空洞去掉,就能达到收缩表空间的目的。而重建表就能达到这样的目的。
4.重建表
如果我们手动重建一张表,可以新建一个与表 A 结构相同的表 B,然后按照主键 ID 递增的顺序,把数据一行一行地(就是递增地)从表 A 里读出来再插入到表 B 中。由于表 B 是新建的表,所以表 A 主键索引上的空洞,在表 B 中就都不存在了。显然地,表 B 的主键索引更紧凑,数据页的利用率也更高。如果我们把表 B 作为临时表,数据从表 A 导入表 B 的操作完成后,用表 B 替换 A,从效果上看,就起到了收缩表 A 空间的作用。
这里,你可以使用 alter table A engine=InnoDB 命令来重建表。在 MySQL 5.5 版本之前,这个命令的执行流程跟我们前面描述的差不多,区别只是这个临时表 B 不需要你自己创建,MySQL 会自动完成转存数据、交换表名、删除旧表的操作。显然,花时间最多的步骤是往临时表插入数据的过程,如果在这个过程中,有新的数据要写入到表 A 的话,就会造成数据丢失。因此,在整个 DDL 过程中,表 A 中不能有更新。也就是说,这个 DDL 不是 Online 的。
MySQL 5.6 版本开始引入的 Online DDL,对这个操作流程做了优化。
建立一个临时文件,扫描表 A 主键的所有数据页;
用数据页中表 A 的记录生成 B+ 树,存储到临时文件中;
生成临时文件的过程中,将所有对 A 的操作记录在一个日志文件(row log)中;
临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 A 相同的数据文件;(应用row log的过程可能又回有页分裂)
用临时文件替换表 A 的数据文件。
可以看到,在这个过程中,由于日志文件记录和重放操作这个功能的存在,这个方案在重建表的过程中,允许对表 A 做增删改操作。这也就是 Online DDL 名字的来源。
需要补充说明的是,上述的这些重建方法都会扫描原表数据和构建临时文件。对于很大的表来说,这个操作是很消耗 IO 和 CPU 资源的。因此,如果是线上服务,你要很小心地控制操作时间。
optimize table、analyze table 和 alter table 这三种方式重建表的区别:
从 MySQL 5.6 版本开始,alter table t engine = InnoDB(也就是 recreate)默认的就是上面online DDL 的流程了;
analyze table t 其实不是重建表,只是对表的索引信息做重新统计,没有修改数据,这个过程中加了 MDL 读锁;
optimize table t 等于 recreate+analyze。
“MySQL分库分表后总存储变大了的原因是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/byvRSC9V4B-1BPuGRLghqQ



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



