这篇文章主要讲解了“如何利用SQL和Python分别实现人流量查询”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何利用SQL和Python分别实现人流量查询”吧!
案例来源于LeetCode,这样的需求在时间序列数据中还是较为常见的。
某市体育馆每日人流量信息被记录在stadium表的三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people),找出至少连续三行人流量不少于100的记录。
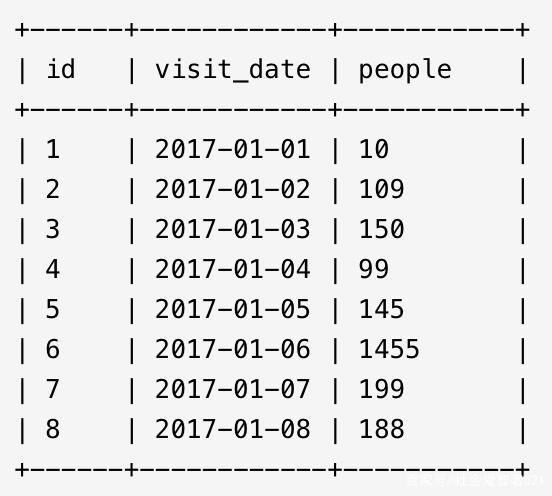
最简单的思路肯定是对stadium表进行三次笛卡尔积连接,但这种方式在数据量大时不可取,而且也不具备泛化性(譬如需求改成至少连续十行)。网上也流传着阿里的编程规范——禁止三表以上的连接。
总之,这种思路不是我们该采取的,我们需要寻找其它思路。
(1)构建等差数列
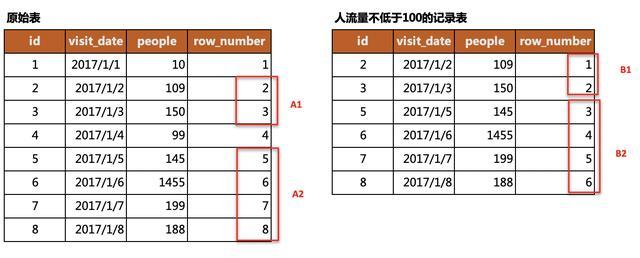
从上图中我们能发现一个规律,满足条件的数据区域在原始表和结果表中的行编号均是等差数列,两个等差数列的差值是固定的。譬如,数列A1和B1的差值均为1;数列A2和B2的差值均为2。
只要我们保证每块区域等差数列的差值各不相等,那我们就可以通过筛选差值出现的次数来筛选满足条件的区域。例如,差值2出现了4次,满足条件,那该差值对应的记录就是我们需要的数据。
构建差值的方式除了通过行编号外,也还有其它方式,大家可以想一想。
(2)数据切片
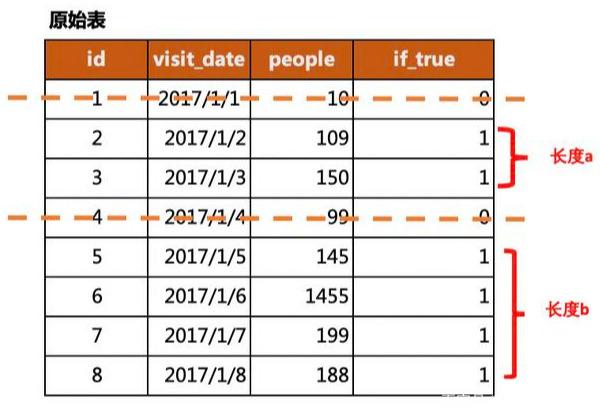
从图中可看出,if_true是辅助列,表示是否满足条件,1为True,0为False。我们要选择满足条件的区域,可通过用0对该列进行切片,得到的是全为1的不同长度的小数列,根据每个小数列的长度来筛选满足条件的区域。
在图中就是得到了长度为a和b的数列,通过计算数列的长度来找出满足条件的区域。
上节我们选择了两种思路,其中Python两种思路都可以实现,SQL可实现第一种思路。本节用SQL实现第一种思路,用Python实现第二种思路。
(1)SQL
select id,visit_date,people from (select t2.*,count(1) over(partition by rn2) rn3 from (selectt1.*,rn1 - row_number() over(order by visit_date) rn2 from (select *,row_number() over() as rn1 from stadium order by visit_date)t1 #t1表对日期升序排列后生成行编号 where people>=100) t2 #t2表筛选人数不低于100的数据,并用原行编号减去新生成的行编号得到差值 where 1=1) t3 #t3表统计每类差值出现的次数 where rn3>2 #筛选次数大于2的数据即为所需要的数据
因为实际中表中的ID几乎都不是连续的数字,所以为了保证泛化性就先生成了行编号,这样就不用依赖于ID了。
除此之外也还可以通过用户变量等方式实现,大家可以试着想一想。
(2)Python
import pandas as pd dt=pd.DataFrame({"id":range(1,9), "visit_date":pd.date_range(start="2017-01-01",periods=8), "people":[10,109,150,99,145,1455,199,188]}) dt["col1"]=dt["people"].apply(lambda x : 1 if x>=100 else 0) #生成人数是否不低于100的新列 dt['counter'] = (dt["col1"]==0).cumsum() #按照col1列是否为0计算累计和,标记每个连续区域 dt = dt[dt["col1"] !=0] #剔除人数低于100的记录 gb=dt.groupby("counter")["id"].count() # 统计各标记值的次数 result=dt[dt["counter"].isin(gb[gb>2].index)] #筛选满足条件的数据这里有一点需要注意,如果直接将col1列转为字符串按0进行切片的话,虽然可以求出满足条件的区域数量和长度,但很难再寻找到具体的区域。
split_col1="".join([str(i) for i in dt["col1"]]).split("0")原本是按照的这种思路,但发现寻找长度符合字符串在原列表中的索引时会比较麻烦,尤其是当需要查找多个索引值时。
但此种思路还是非常重要,因为在只是计算连续区域的最大值时会非常简单。
感谢各位的阅读,以上就是“如何利用SQL和Python分别实现人流量查询”的内容了,经过本文的学习后,相信大家对如何利用SQL和Python分别实现人流量查询这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





