本篇内容介绍了“使用了索引查询还是慢的原因是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
案例剖析
言归正传,为了实验,我创建了如下表:
CREATE TABLE `T`( `id` int(11) NOT NULL, `a` int(11) DEFAUT NULL, PRIMARY KEY(`id`), KEY `a`(`a`) ) ENGINE=InnoDB;
该表有三个字段,其中用id是主键索引,a是普通索引。
首先SQL判断一个语句是不是慢查询语句,用的是语句的执行时间。他把语句执行时间跟long_query_time这个系统参数作比较,如果语句执行时间比它还大,就会把这个语句记录到慢查询日志里面,这个参数的默认值是10秒。当然在生产上,我们不会设置这么大,一般会设置1秒,对于一些比较敏感的业务,可能会设置一个比1秒还小的值。
语句执行过程中有没有用到表的索引,可以通过explain一个语句的输出结果来看KEY的值不是NULL。
我们看下 explain select * from t;的KEY结果是NULL

(图一)
explain select * from t where id=2;的KEY结果是PRIMARY,就是我们常说的使用了主键索引

(图二)
explain select a from t;的KEY结果是a,表示使用了a这个索引。

(图三)
虽然后两个查询的KEY都不是NULL,但是最后一个实际上扫描了整个索引树a。
假设这个表的数据量有100万行,图二的语句还是可以执行很快,但是图三就肯定很慢了。如果是更极端的情况,比如,这个数据库上CPU压力非常的高,那么可能第2个语句的执行时间也会超过long_query_time,会进入到慢查询日志里面。
所以我们可以得出一个结论:是否使用索引和是否进入慢查询之间并没有必然的联系。使用索引只是表示了一个SQL语句的执行过程,而是否进入到慢查询是由它的执行时间决定的,而这个执行时间,可能会受各种外部因素的影响。换句话来说,使用了索引你的语句可能依然会很慢。
全索引扫描的不足
那如果我们在更深层次的看这个问题,其实他还潜藏了一个问题需要澄清,就是什么叫做使用了索引。
我们都知道,InnoDB是索引组织表,所有的数据都是存储在索引树上面的。比如上面的表t,这个表包含了两个索引,一个主键索引和一个普通索引。在InnoDB里,数据是放在主键索引里的。如图所示:
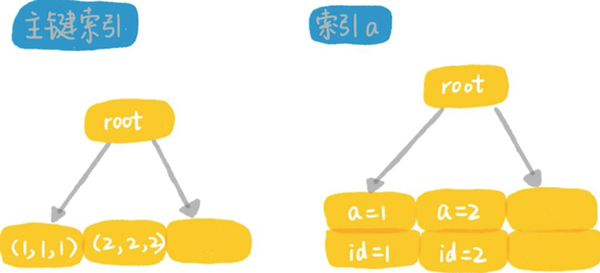
可以看到数据都放在主键索引上,如果从逻辑上说,所有的InnoDB表上的查询,都至少用了一个索引,所以现在我问你一个问题,如果你执行select from t where id>0,你觉得这个语句有用上索引吗?

我们看上面这个语句的explain的输出结果显示的是PRIMARY。其实从数据上你是知道的,这个语句一定是做了全面扫描。但是优化器认为,这个语句的执行过程中,需要根据主键索引,定位到第1个满足ID>0的值,也算用到了索引。
所以即使explain的结果里写的KEY不是NULL,实际上也可能是全表扫描的,因此InnoDB里面只有一种情况叫做没有使用索引,那就是从主键索引的最左边的叶节点开始,向右扫描整个索引树。
也就是说,没有使用索引并不是一个准确的描述。
你可以用全表扫描来表示一个查询遍历了整个主键索引树;
也可以用全索引扫描,来说明像select a from t;这样的查询,他扫描了整个普通索引树;
而select * from t where id=2这样的语句,才是我们平时说的使用了索引。他表示的意思是,我们使用了索引的快速搜索功能,并且有效的减少了扫描行数。
索引的过滤性要足够好
根据以上解剖,我们知道全索引扫描会让查询变慢,接下来就要来谈谈索引的过滤性。
假设你现在维护了一个表,这个表记录了中国14亿人的基本信息,现在要查出所有年龄在10~15岁之间的姓名和基本信息,那么你的语句会这么写,select * from t_people where age between 10 and 15。
你一看这个语句一定要在age字段上开始建立索引了,否则就是个全面扫描,但是你会发现,在你建立索引以后,这个语句还是执行慢,因为满足这个条件的数据可能有超过1亿行。
我们来看看建立索引以后,这个表的组织结构图:
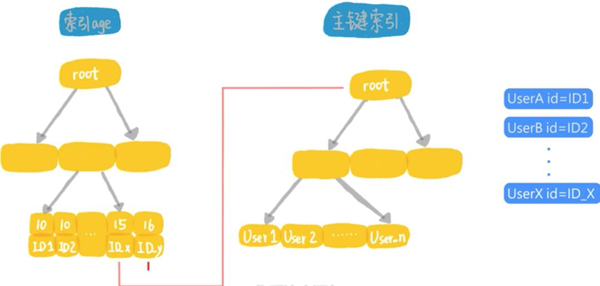
这个语句的执行流程是这样的:
从索引上用树搜索,取到第1个age等于10的记录,得到它的主键id的值,根据id的值去主键索引取整行的信息,作为结果集的一部分返回;
在索引age上向右扫描,取下一个id的值,到主键索引上取整行信息,作为结果集的一部分返回;
重复上面的步骤,直到碰到第1个age大于15的记录;
你看这个语句,虽然他用了索引,但是他扫描超过了1亿行。所以你现在知道了,当我们在讨论有没有使用索引的时候,其实我们关心的是扫描行数。
对于一个大表,不止要有索引,索引的过滤性还要足够好。
像刚才这个例子的age,它的过滤性就不够好,在设计表结构的时候,我们要让所有的过滤性足够好,也就是区分度足够高。
回表的代价
那么过滤性好了,是不是表示查询的扫描行数就一定少呢?
我们再来看一个例子:
如果你的执行语句是 select * from t_people where name='张三' and age=8
t_people表上有一个索引是姓名和年龄的联合索引,那这个联合索引的过滤性应该不错,可以在联合索引上快速找到第1个姓名是张三,并且年龄是8的小朋友,当然这样的小朋友应该不多,因此向右扫描的行数很少,查询效率就很高。
但是查询的过滤性和索引的过滤性可不一定是一样的,如果现在你的需求是查出所有名字的第1个字是张,并且年龄是8岁的所有小朋友,你的语句会怎么写呢?
你的语句要怎么写?很显然你会这么写:select * from t_people where name like '张%' and age=8;
在MySQL5.5和之前的版本中,这个语句的执行流程是这样的:
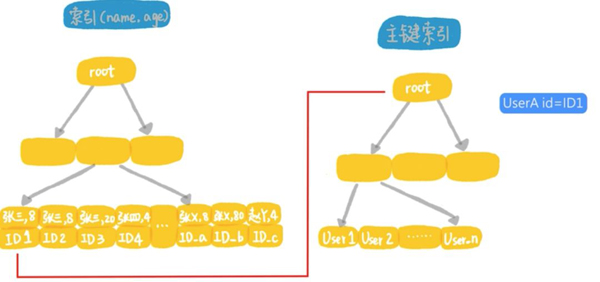
首先从联合索引上找到第1个年龄字段是张开头的记录,取出主键id,然后到主键索引树上,根据id取出整行的值;
判断年龄字段是否等于8,如果是就作为结果集的一行返回,如果不是就丢弃。
在联合索引上向右遍历,并重复做回表和判断的逻辑,直到碰到联合索引树上名字的第1个字不是张的记录为止。
我们把根据id到主键索引上查找整行数据这个动作,称为回表。你可以看到这个执行过程里面,最耗费时间的步骤就是回表,假设全国名字第1个字是张的人有8000万,那么这个过程就要回表8000万次,在定位第一行记录的时候,只能使用索引和联合索引的最左前缀,最称为最左前缀原则。
你可以看到这个执行过程,它的回表次数特别多,性能不够好,有没有优化的方法呢?
在MySQL5.6版本,引入了index condition pushdown的优化。我们来看看这个优化的执行流程:
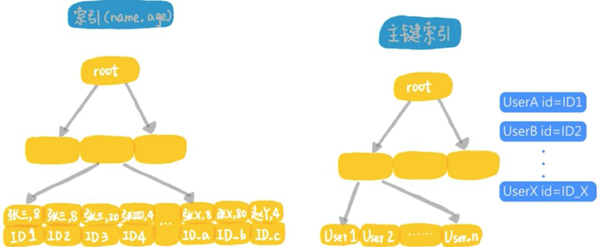
首先从联合索引树上,找到第1个年龄字段是张开头的记录,判断这个索引记录里面,年龄的值是不是8,如果是就回表,取出整行数据,作为结果集的一部分返回,如果不是就丢弃;
在联合索引树上,向右遍历,并判断年龄字段后,根据需要做回表,直到碰到联合索引树上名字的第1个字不是张的记录为止;
这个过程跟上面的差别,是在遍历联合索引的过程中,将年龄等于8的条件下推到所有遍历的过程中,减少了回表的次数,假设全国名字第1个字是张的人里面,有100万个是8岁的小朋友,那么这个查询过程中在联合索引里要遍历8000万次,而回表只需要100万次。
虚拟列
可以看到这个优化的效果还是很不错的,但是这个优化还是没有绕开最左前缀原则的限制,因此在联合索引你还是要扫描8000万行,那有没有更进一步的优化方法呢?
我们可以考虑把名字的第一个字和age来做一个联合索引。这里可以使用MySQL5.7引入的虚拟列来实现。对应的修改表结构的SQL语句:
alter table t_people add name_first varchar(2) generated (left(name,1)),add index(name_first,age);
我们来看这个SQL语句的执行效果:
CREATE TABLE `t_people`( `id` int(11) DEFAULT NULL, `name` varchar(20) DEFAUT NULL, `name_first` varchar(2) GENERATED ALWAYS AS (left(`name`,1)) VIRTUAL,KEY `name_first`(`name_first`,'age') ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
首先他在people上创建一个字段叫name_first的虚拟列,然后给name_first和age上创建一个联合索引,并且,让这个虚拟列的值总是等于name字段的前两个字节,虚拟列在插入数据的时候不能指定值,在更新的时候也不能主动修改,它的值会根据定义自动生成,在name字段修改的时候也会自动修改。
有了这个新的联合索引,我们在找名字的第1个字是张,并且年龄为8的小朋友的时候,这个SQL语句就可以这么写:select * from t_people where name_first='张' and age=8。
这样这个语句的执行过程,就只需要扫描联合索引的100万行,并回表100万次,这个优化的本质是我们创建了一个更紧凑的索引,来加速了查询的过程。
“使用了索引查询还是慢的原因是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





