python3жҖҺд№Ҳе®һзҺ°еёёи§Ғзҡ„жҺ’еәҸз®—жі•
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢpython3жҖҺд№Ҳе®һзҺ°еёёи§Ғзҡ„жҺ’еәҸз®—жі•зҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
еҶ’жіЎжҺ’еәҸ
еҶ’жіЎжҺ’еәҸжҳҜдёҖз§Қз®ҖеҚ•зҡ„жҺ’еәҸз®—жі•гҖӮе®ғйҮҚеӨҚең°иө°и®ҝиҝҮиҰҒжҺ’еәҸзҡ„ж•°еҲ—пјҢдёҖж¬ЎжҜ”иҫғдёӨдёӘе…ғзҙ пјҢеҰӮжһңе®ғ们зҡ„йЎәеәҸй”ҷиҜҜе°ұжҠҠе®ғ们дәӨжҚўиҝҮжқҘгҖӮиө°и®ҝж•°еҲ—зҡ„е·ҘдҪңжҳҜйҮҚеӨҚең°иҝӣиЎҢзӣҙеҲ°жІЎжңүеҶҚйңҖиҰҒдәӨжҚўпјҢд№ҹе°ұжҳҜиҜҙиҜҘж•°еҲ—е·Із»ҸжҺ’еәҸе®ҢжҲҗгҖӮиҝҷдёӘз®—жі•зҡ„еҗҚеӯ—з”ұжқҘжҳҜеӣ дёәи¶Ҡе°Ҹзҡ„е…ғзҙ дјҡз»Ҹз”ұдәӨжҚўж…ўж…ўвҖңжө®вҖқеҲ°ж•°еҲ—зҡ„йЎ¶з«ҜгҖӮ
def mao(lst):
for i in range(len(lst)):
# з”ұдәҺжҜҸдёҖиҪ®з»“жқҹеҗҺпјҢжҖ»дёҖе®ҡжңүдёҖдёӘеӨ§зҡ„ж•°жҺ’еңЁеҗҺйқў
# иҖҢдё”еҗҺйқўзҡ„ж•°е·Із»ҸжҺ’еҘҪдәҶ
# еҚіiиҪ®д№ӢеҗҺпјҢе°ұжңүiдёӘж•°еӯ—иў«жҺ’еҘҪ
# жүҖд»Ҙе…¶ len-1 -iеҲ° len-1зҡ„дҪҚзҪ®жҳҜе·Із»ҸжҺ’еҘҪзҡ„дәҶ
# еҸӘйңҖиҰҒжҜ”иҫғ0еҲ°len -1 -iзҡ„дҪҚзҪ®еҚіеҸҜ
# flag з”ЁдәҺж Үи®°жҳҜеҗҰеҲҡејҖе§Ӣе°ұжҳҜжҺ’еҘҪзҡ„ж•°жҚ®
# еҸӘжңүеҪ“flagзҠ¶жҖҒеҸ‘з”ҹж”№еҸҳж—¶пјҲ第дёҖж¬ЎеҫӘзҺҜе°ұеҸҜд»ҘзЎ®е®ҡпјүпјҢ继з»ӯжҺ’еәҸпјҢеҗҰеҲҷиҝ”еӣһ
flag = False
for j in range(len(lst) - i - 1):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
flag = True
# йқһжҺ’еҘҪзҡ„ж•°жҚ®пјҢж”№еҸҳflag
if not flag:
return lst
return lst
print(mao([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
йҖүжӢ©жҺ’еәҸ
йҖүжӢ©жҺ’еәҸжҳҜдёҖз§Қз®ҖеҚ•зӣҙи§Ӯзҡ„жҺ’еәҸз®—жі•гҖӮе®ғзҡ„е·ҘдҪңеҺҹзҗҶпјҡйҰ–е…ҲеңЁжңӘжҺ’еәҸеәҸеҲ—дёӯжүҫеҲ°жңҖе°ҸпјҲеӨ§пјүе…ғзҙ пјҢеӯҳж”ҫеҲ°жҺ’еәҸеәҸеҲ—зҡ„иө·е§ӢдҪҚзҪ®пјҢ然еҗҺпјҢеҶҚд»Һеү©дҪҷжңӘжҺ’еәҸе…ғзҙ дёӯ继з»ӯеҜ»жүҫжңҖе°ҸпјҲеӨ§пјүе…ғзҙ пјҢ然еҗҺж”ҫеҲ°е·ІжҺ’еәҸеәҸеҲ—зҡ„жң«е°ҫгҖӮд»ҘжӯӨзұ»жҺЁпјҢзӣҙеҲ°жүҖжңүе…ғзҙ еқҮжҺ’еәҸе®ҢжҜ•гҖӮ

# йҖүжӢ©жҺ’еәҸжҳҜд»ҺеүҚејҖе§ӢжҺ’зҡ„
# йҖүжӢ©жҺ’еәҸжҳҜд»ҺдёҖдёӘеҲ—иЎЁдёӯжүҫеҮәдёҖдёӘжңҖе°Ҹзҡ„е…ғзҙ пјҢ然еҗҺж”ҫеңЁз¬¬дёҖдҪҚдёҠгҖӮ
# еҶ’жіЎжҺ’еәҸзұ»дјј
# е…¶ 0 еҲ° iзҡ„дҪҚзҪ®жҳҜжҺ’еҘҪзҡ„пјҢеҸӘйңҖиҰҒжҺ’i+1еҲ°len(lst)-1еҚіеҸҜ
def select_sort(lst):
for i in range(len(lst)):
min_index = i # з”ЁдәҺи®°еҪ•жңҖе°Ҹзҡ„е…ғзҙ зҡ„зҙўеј•
for j in range(i + 1, len(lst)):
if lst[j] < lst[min_index]:
min_index = j
# жӯӨж—¶пјҢе·Із»ҸзЎ®е®ҡпјҢmin_indexдёә i+1 еҲ°len(lst) - 1 иҝҷдёӘеҢәй—ҙжңҖе°ҸеҖјзҡ„зҙўеј•
lst[i], lst[min_index] = lst[min_index], lst[i]
return lst
def select_sort2(lst):
# 第дәҢз§ҚйҖүжӢ©жҺ’еәҸзҡ„ж–№жі•
# еҺҹзҗҶдёҺ第дёҖз§ҚдёҖж ·
# дёҚиҝҮдёҚйңҖиҰҒеј•з”Ёдёӯй—ҙеҸҳйҮҸmin_index
# еҸӘйңҖиҰҒжүҫеҲ°зҙўеј•iеҗҺйқўзҡ„i+1еҲ°len(lst)зҡ„е…ғзҙ еҚіеҸҜ
for i in range(len(lst)):
for j in range(len(lst) - i):
# lst[i + j]жҳҜдёҖдёӘiеҲ°len(lst)-1зҡ„дёҖдёӘж•°
# еӣ дёәj <= len(lst) -i еҚі j + i <= len(lst)
if lst[i] > lst[i + j]:
# иҜҙжҳҺеҗҺйқўзҡ„ж•°жӣҙе°ҸпјҢжӣҙжҚўдҪҚзҪ®
lst[i], lst[i + j] = lst[i + j], lst[i]
return lst
print(select_sort([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
print(select_sort2([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
еҝ«йҖҹжҺ’еәҸ
еҝ«йҖҹжҺ’еәҸжҳҜйҖҡиҝҮдёҖи¶ҹжҺ’еәҸе°Ҷеҫ…жҺ’и®°еҪ•еҲҶйҡ”жҲҗзӢ¬з«Ӣзҡ„дёӨйғЁеҲҶпјҢе…¶дёӯдёҖйғЁеҲҶи®°еҪ•зҡ„е…ій”®еӯ—еқҮжҜ”еҸҰдёҖйғЁеҲҶзҡ„е…ій”®еӯ—е°ҸпјҢеҲҷеҸҜеҲҶеҲ«еҜ№иҝҷдёӨйғЁеҲҶи®°еҪ•з»§з»ӯиҝӣиЎҢжҺ’еәҸпјҢд»ҘиҫҫеҲ°ж•ҙдёӘеәҸеҲ—жңүеәҸгҖӮ
# еҺҹзҗҶ
# 1. д»»еҸ–еҲ—иЎЁдёӯзҡ„дёҖдёӘе…ғзҙ i
# 2. жҠҠеҲ—иЎЁдёӯеӨ§дәҺiзҡ„е…ғзҙ ж”ҫдәҺе…¶еҸіиҫ№пјҢе°ҸдәҺеҲҷж”ҫдәҺе…¶е·Ұиҫ№
# 3. еҰӮжӯӨйҮҚеӨҚ
# 4. зӣҙеҲ°дёҚиғҪеңЁеҲҶпјҢеҚіеҸӘеү©1дёӘе…ғзҙ дәҶ
# 5. 然еҗҺе°Ҷиҝҷдәӣз»“жһңз»„еҗҲиө·жқҘ
def quicksort(lst):
if len(lst) < 2: # lstжңүеҸҜиғҪдёәз©ә
return lst
# ["pЙӘvЙҷt] дёӯеҝғзӮ№
pivot = lst[0]
less_lst = [i for i in lst[1:] if i <= pivot]
greater_lst = [i for i in lst[1:] if i > pivot]
# жңҖеҗҺзҡ„з»“жһңе°ұжҳҜ
# е·Ұиҫ№зҡ„з»“жһң + дёӯй—ҙеҖј + еҸіиҫ№зҡ„з»“жһң
# 然еҗҺз»ҶеҲҶ е·Ұ+дёӯ+еҸі + дёӯй—ҙеҖј + е·Ұ + дёӯ+ еҸі
# ........... + дёӯй—ҙеҖј + ............
return quicksort(less_lst) + [pivot] + quicksort(greater_lst)
print(quicksort([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
print(quicksort([1, 5, 8, 62]))
жҸ’е…ҘжҺ’еәҸ
жҸ’е…ҘжҺ’еәҸзҡ„з®—жі•жҸҸиҝ°жҳҜдёҖз§Қз®ҖеҚ•зӣҙи§Ӯзҡ„жҺ’еәҸз®—жі•гҖӮе®ғзҡ„е·ҘдҪңеҺҹзҗҶжҳҜйҖҡиҝҮжһ„е»әжңүеәҸеәҸеҲ—пјҢеҜ№дәҺжңӘжҺ’еәҸж•°жҚ®пјҢеңЁе·ІжҺ’еәҸеәҸеҲ—дёӯд»ҺеҗҺеҗ‘еүҚжү«жҸҸпјҢжүҫеҲ°зӣёеә”дҪҚзҪ®е№¶жҸ’е…ҘгҖӮ

# lstзҡ„[0, i) йЎ№жҳҜжңүеәҸзҡ„пјҢеӣ дёәе·Із»ҸжҺ’иҝҮдәҶ
# йӮЈд№ҲеҸӘйңҖиҰҒжҜ”еҜ№з¬¬iйЎ№зҡ„lst[i]е’Ңlst[0 : i]зҡ„е…ғзҙ еӨ§е°ҸеҚіеҸҜ
# еҒҮеҰӮпјҢlst[i]еӨ§пјҢеҲҷдёҚз”Ёж”№еҸҳдҪҚзҪ®
# еҗҰеҲҷпјҢlst[i]ж”№еҸҳдҪҚзҪ®пјҢжҸ’еҲ°jзҡ„дҪҚзҪ®пјҢиҖҢlst[j]иҮӘ然еҫҖеҗҺжҢӘдёҖдҪҚ
# 然еҗҺеҶҚеҲ йҷӨlst[i+1]еҚіеҸҜпјҲlst[i+1]жҳҜеҺҹжқҘзҡ„lst[i]пјү
#
# йҮҚеӨҚдёҠйқўжӯҘйӘӨеҚіеҸҜпјҢжҺ’еәҸе®ҢжҲҗ
def insert_sort(lst: list):
# еӨ–еұӮејҖе§Ӣзҡ„дҪҚзҪ®д»Һ1ејҖе§ӢпјҢеӣ дёәд»Һ0ејҖе§ӢйғҪжІЎеҫ—жҺ’
# еҸӘжңүдёӨдёӘе…ғзҙ д»ҘдёҠжүҚиғҪжҺ’еәҸ
for i in range(1, len(lst)):
# еҶ…еұӮйңҖиҰҒд»Һ0ејҖе§ӢпјҢеӣ дёәlst[0]зҡ„дҪҚзҪ®дёҚдёҖе®ҡжҳҜжңҖе°Ҹзҡ„
for j in range(i):
if lst[i] < lst[j]:
lst.insert(j, lst[i])
# lst[i]е·Із»ҸжҸ’е…ҘеҲ°jзҡ„дҪҚзҪ®дәҶпјҢjд№ӢеҗҺзҡ„е…ғзҙ йғҪеҫҖеҗҺ+1дҪҚпјҢжүҖд»ҘеҲ йҷӨlst[i+1]
del lst[i + 1]
return lst
print(insert_sort([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
еёҢе°”жҺ’еәҸ
еёҢе°”жҺ’еәҸжҳҜ1959е№ҙShellеҸ‘жҳҺзҡ„пјҢ第дёҖдёӘзӘҒз ҙO(n2)зҡ„жҺ’еәҸз®—жі•пјҢжҳҜз®ҖеҚ•жҸ’е…ҘжҺ’еәҸзҡ„ж”№иҝӣзүҲгҖӮе®ғдёҺжҸ’е…ҘжҺ’еәҸзҡ„дёҚеҗҢд№ӢеӨ„еңЁдәҺпјҢе®ғдјҡдјҳе…ҲжҜ”иҫғи·қзҰ»иҫғиҝңзҡ„е…ғзҙ гҖӮеёҢе°”жҺ’еәҸеҸҲеҸ«зј©е°ҸеўһйҮҸжҺ’еәҸгҖӮ
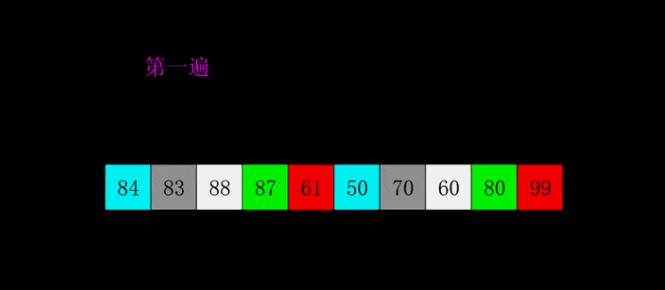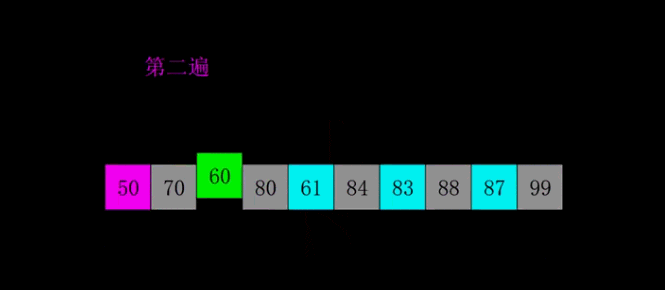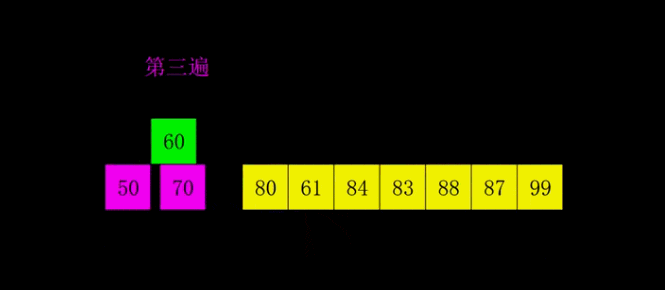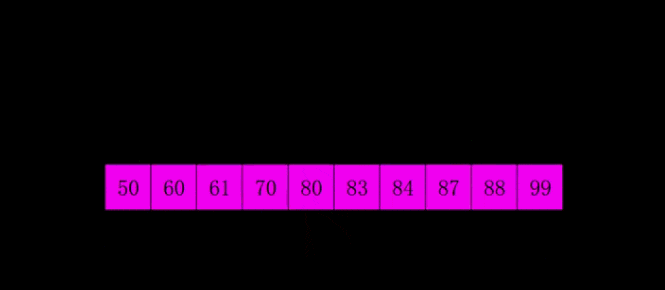
еёҢе°”жҺ’еәҸ
# еёҢе°”жҺ’еәҸжҳҜеҜ№зӣҙжҺҘжҸ’е…ҘжҺ’еәҸзҡ„дјҳеҢ–зүҲжң¬
# 1. еҲҶз»„пјҡ
# жҜҸй—ҙйҡ”дёҖж®өи·қзҰ»еҸ–дёҖдёӘе…ғзҙ дёәдёҖз»„
# й—ҙйҡ”иҮӘе·ұзЎ®е®ҡпјҢдёҖиҲ¬дёәlstзҡ„дёҖеҚҠ
# 2. ж №жҚ®жҸ’е…ҘжҺ’еәҸпјҢжҠҠжҜҸдёҖз»„жҺ’еәҸеҘҪ
# 3. 继з»ӯеҲҶз»„пјҡ
# еҗҢж ·жІЎй—ҙйҡ”дёҖж®өи·қзҰ»еҸ–дёҖдёӘе…ғзҙ дёәдёҖз»„
# й—ҙйҡ”иҰҒжұӮжҜ” д№ӢеүҚзҡ„й—ҙйҡ”е°‘дёҖеҚҠ
# 4. еҶҚжҜҸз»„жҸ’е…ҘжҺ’еәҸ
# 5. зӣҙеҲ°й—ҙйҡ”дёә1пјҢеҲҷжҺ’еәҸе®ҢжҲҗ
#
def shell_sort(lst):
lst_len = len(lst)
gap = lst_len // 2 # ж•ҙйҷӨ2пјҢеҸ–й—ҙйҡ”
while gap >= 1: # й—ҙйҡ”дёә0ж—¶з»“жқҹ
for i in range(gap, lst_len):
temp = lst[i]
j = i
# жҸ’е…ҘжҺ’еәҸ
while j - gap >= 0 and lst[j - gap] > temp:
lst[j] = lst[j - gap]
j -= gap
lst[j] = temp
gap //= 2
return lst
print(shell_sort([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
# еҘҮж•°
# gap = 2
# [5, 2, 4, 3, 1]
# [5, 4, 1] [2, 3]
# [1, 4, 5, 2, 3]
# gap = 1
# [1, 2, 3, 4, 5]
# еҒ¶ж•°
# gap = 3
# [5, 2, 4, 3, 1пјҢ 6]
# [5, 3] [2, 1] [4,6]
# [3, 5, 1, 2, 4 , 6]
# gap = 1
# [1, 2, 3, 4, 5, 6]
并еҪ’жҺ’еәҸ
еҪ’并жҺ’еәҸжҳҜе»әз«ӢеңЁеҪ’并ж“ҚдҪңдёҠзҡ„дёҖз§Қжңүж•Ҳзҡ„жҺ’еәҸз®—жі•гҖӮиҜҘз®—жі•жҳҜйҮҮз”ЁеҲҶжІ»жі•пјҲDivide and Conquerпјүзҡ„дёҖдёӘйқһеёёе…ёеһӢзҡ„еә”з”ЁгҖӮе°Ҷе·ІжңүеәҸзҡ„еӯҗеәҸеҲ—еҗҲ并пјҢеҫ—еҲ°е®Ңе…ЁжңүеәҸзҡ„еәҸеҲ—пјӣеҚіе…ҲдҪҝжҜҸдёӘеӯҗеәҸеҲ—жңүеәҸпјҢеҶҚдҪҝеӯҗеәҸеҲ—ж®өй—ҙжңүеәҸгҖӮиӢҘе°ҶдёӨдёӘжңүеәҸиЎЁеҗҲ并жҲҗдёҖдёӘжңүеәҸиЎЁпјҢз§°дёә2-и·ҜеҪ’并гҖӮ
并еҪ’жҺ’еәҸ
# еҲ©з”ЁеҲҶжІ»жі•
# дёҚж–ӯе°ҶlstеҲҶдёәе·ҰеҸідёӨдёӘеҲҶ
# зӣҙеҲ°дёҚиғҪеҶҚеҲҶ
# 然еҗҺиҝ”еӣһ
# е°ҶдёӨиҫ№зҡ„еҲ—иЎЁзҡ„е…ғзҙ иҝӣиЎҢжҜ”еҜ№пјҢжҺ’еәҸ然еҗҺиҝ”еӣһ
# дёҚж–ӯйҮҚеӨҚдёҠйқўиҝҷдёҖжӯҘйӘӨ
# зӣҙеҲ°жҺ’еәҸе®ҢжҲҗпјҢеҚідёӨдёӘеӨ§зҡ„еҲ—иЎЁжҜ”еҜ№е®ҢжҲҗ
def merge(left, right):
# left еҸҜиғҪдёәеҸӘжңүдёҖдёӘе…ғзҙ зҡ„еҲ—иЎЁпјҢжҲ–е·Із»ҸжҺ’еҘҪеәҸзҡ„еӨҡдёӘе…ғзҙ еҲ—иЎЁпјҲд№ӢеүҚи°ғз”ЁиҝҮmergeпјү
# right д№ҹдёҖж ·
res = []
while left and right:
item = left.pop(0) if left[0] < right[0] else right.pop(0)
res.append(item)
# жӯӨж—¶пјҢleftжҲ–rightе·Із»ҸжңүдёҖдёӘдёәз©әпјҢзӣҙжҺҘextendжҸ’е…Ҙ
# иҖҢдё”пјҢleftе’ҢrightжҳҜд№ӢеүҚе·Із»ҸжҺ’еҘҪеәҸзҡ„еҲ—иЎЁпјҢдёҚйңҖиҰҒеҶҚж“ҚдҪңдәҶ
res.extend(left)
res.extend(right)
return res
def merge_sort(lst):
lst_len = len(lst)
if lst_len <= 1:
return lst
mid = lst_len // 2
lst_right = merge_sort(lst[mid:len(lst)]) # иҝ”еӣһзҡ„ж—¶lst_len <= 1ж—¶зҡ„ lst жҲ– mergeдёӯиҝӣиЎҢжҺ’еәҸеҗҺзҡ„еҲ—иЎЁ
lst_left = merge_sort(lst[:mid]) # иҝ”еӣһзҡ„жҳҜlst_len <= 1ж—¶зҡ„ lst жҲ– mergeдёӯиҝӣиЎҢжҺ’еәҸеҗҺзҡ„еҲ—иЎЁ
return merge(lst_left, lst_right) # иҝӣиЎҢжҺ’еәҸпјҢlst_left lst_right зҡ„е…ғзҙ дјҡдёҚж–ӯеўһеҠ
print(merge_sort([1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]))
е ҶжҺ’еәҸ
е ҶжҺ’еәҸжҳҜжҢҮеҲ©з”Ёе Ҷиҝҷз§Қж•°жҚ®з»“жһ„жүҖи®ҫи®Ўзҡ„дёҖз§ҚжҺ’еәҸз®—жі•гҖӮе Ҷз§ҜжҳҜдёҖдёӘиҝ‘дјје®Ңе…ЁдәҢеҸүж ‘зҡ„з»“жһ„пјҢ并еҗҢж—¶ж»Ўи¶іе Ҷз§Ҝзҡ„жҖ§иҙЁпјҡеҚіеӯҗз»“зӮ№зҡ„й”®еҖјжҲ–зҙўеј•жҖ»жҳҜе°ҸдәҺпјҲжҲ–иҖ…еӨ§дәҺпјүе®ғзҡ„зҲ¶иҠӮзӮ№гҖӮ然еҗҺиҝӣиЎҢжҺ’еәҸгҖӮ

е ҶжҺ’еәҸ
# жҠҠеҲ—иЎЁеҲӣжҲҗдёҖдёӘеӨ§ж №е ҶжҲ–е°Ҹж №е Ҷ
# 然еҗҺж №жҚ®еӨ§пјҲе°Ҹпјүж №е Ҷзҡ„зү№зӮ№пјҡж №иҠӮзӮ№жңҖеӨ§пјҲе°ҸпјүпјҢйҖҗдёҖеҸ–еҖј
#
# еҚҮеәҸ----дҪҝз”ЁеӨ§йЎ¶е Ҷ
#
# йҷҚеәҸ----дҪҝз”Ёе°ҸйЎ¶е Ҷ
# жң¬дҫӢд»Ҙе°Ҹж №е ҶдёәдҫӢ
# еҲ—иЎЁlst = [1, 22 ,11, 8, 12, 4, 9]
# 1. е»әжҲҗдёҖдёӘжҷ®йҖҡзҡ„е Ҷпјҡ
# 1
# /
# 22 11
# / /
# 8 12 4 9
#
# 2. иҝӣиЎҢи°ғж•ҙпјҢд»ҺеӯҗејҖе§Ӣи°ғж•ҙдҪҚзҪ®пјҢиҰҒжұӮпјҡ зҲ¶иҠӮзӮ№<= еӯ—иҠӮзӮ№
#
# 1 1 1
# / 13е’Ң22и°ғжҚўдҪҚзҪ® / 4е’Ң11и°ғжҚўдҪҚзҪ® /
# 22 11 ==============> 13 11 ==============> 13 4
# / / / / / /
# 13 14 4 9 22 14 4 9 22 14 11 9
#
# 3. еҸ–еҮәж ‘дёҠж №иҠӮзӮ№пјҢеҚіжңҖе°ҸеҖјпјҢжҠҠжҚўдёҠеҸ¶еӯҗиҠӮзӮ№зҡ„жңҖеӨ§еҖј
#
# 1
# /
# ~~~~/
# 22
# /
# 8 4
# /
# 12 11 9
#
# 4. жҢүз…§еҗҢж ·зҡ„йҒ“зҗҶпјҢ继з»ӯеҪўжҲҗе°Ҹж №е ҶпјҢ然еҗҺеҸ–еҮәж №иҠӮзӮ№пјҢгҖӮгҖӮгҖӮгҖӮйҮҚеӨҚиҝҷдёӘиҝҮзЁӢ
#
# 1 1 1 4 1 4 1 4 8 1 4 8
# / / / / / /
# ~~~/ ~~~/ ~~~/ ~~~/ ~~~/ ~~~/
# 22 4 22 8 22 9
# / / / / / /
# 8 4 8 9 8 9 12 9 12 9 12 11
# / / / / / /
# 12 11 9 12 11 22 12 11 22 11 11 22
#
# з»ӯдёҠпјҡ
# 1 4 8 9 1 4 8 9 1 4 8 9 11 1 4 8 9 11 1 4 8 9 11 12 ==> 1 4 8 9 11 12 22
# / / / / /
# ~~~/ ~~~/ ~~~/ ~~~/ ~~~/
# 22 11 22 12 22
# / / / /
# 12 11 12 22 12 22
#
# д»Јз Ғе®һзҺ°
def heapify(lst, lst_len, i):
"""еҲӣе»әдёҖдёӘе Ҷ"""
less = i # largestдёәжңҖеӨ§е…ғзҙ зҡ„зҙўеј•
left_node_index = 2 * i + 1 # е·ҰеӯҗиҠӮзӮ№зҙўеј•
right_node_index = 2 * i + 2 # еҸіеӯҗиҠӮзӮ№зҙўеј•
# lst[i] е°ұжҳҜзҲ¶иҠӮзӮ№(еҒҮеҰӮжңүеӯҗиҠӮзӮ№зҡ„иҜқ)пјҡ
#
# lst[i]
# /
# lst[2*i + 1] lst[ 2*i + 2]
#
# жғіиҰҒеӨ§ж №е ҶпјҢеҚіеҚҮеәҸпјҢ е°ҶеҲӨж–ӯе·ҰеҸіеӯҗиҠӮзӮ№еӨ§е°Ҹзҡ„ вҖҳ>" ж”№дёә вҖҳ<" еҚіеҸҜ
#
if left_node_index < lst_len and lst[less] > lst[left_node_index]:
less = left_node_index
if right_node_index < lst_len and lst[less] > lst[right_node_index]:
# еҸіиҫ№иҠӮзӮ№жңҖе°Ҹзҡ„ж—¶еҖҷ
less = right_node_index
if less != i:
# жӯӨж—¶пјҢжҳҜеӯ—иҠӮзӮ№еӨ§дәҺзҲ¶иҠӮзӮ№пјҢжүҖд»Ҙзӣёдә’дәӨжҚўдҪҚзҪ®
lst[i], lst[less] = lst[less], lst[i] # дәӨжҚў
heapify(lst, lst_len, less)
# иҠӮзӮ№еҸҳеҠЁдәҶпјҢйңҖиҰҒеҶҚжЈҖжҹҘдёҖдёӢ
def heap_sort(lst):
res = []
i = len(lst)
lst_len = len(lst)
for i in range(lst_len, -1, -1):
# иҰҒд»ҺеҸ¶иҠӮзӮ№ејҖе§ӢжҜ”иҫғпјҢжүҖд»ҘеҖ’зқҖжқҘ
heapify(lst, lst_len, i)
# жӯӨж—¶пјҢе·Із»Ҹе»әеҘҪдәҶдёҖдёӘе°Ҹж №ж ‘
# жүҖд»ҘпјҢдәӨжҚўе…ғзҙ пјҢе°Ҷж №иҠӮзӮ№пјҲжңҖе°ҸеҖјпјүж”ҫеңЁеҗҺйқўпјҢйҮҚеӨҚиҝҷдёӘиҝҮзЁӢ
for j in range(lst_len - 1, 0, -1):
lst[0], lst[j] = lst[j], lst[0] # дәӨжҚўпјҢжңҖе°Ҹзҡ„ж”ҫеңЁjзҡ„дҪҚзҪ®
heapify(lst, j, 0) # еҶҚж¬Ўжһ„е»әдёҖдёӘ[0: j)е°Ҹж №е Ҷ [j: lst_len-1]е·Із»ҸеҖ’еәҸжҺ’еҘҪдәҶ
return lst
arr = [1, 5, 55, 4, 5, 1, 3, 4, 5, 8, 62, 7]
print(heap_sort(arr))
д»ҘдёҠе°ұжҳҜвҖңpython3жҖҺд№Ҳе®һзҺ°еёёи§Ғзҡ„жҺ’еәҸз®—жі•вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





