Hadoopзҡ„ж•°жҚ®еҲҶжһҗе№іеҸ°жҖҺд№Ҳжҗӯе»ә
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңHadoopзҡ„ж•°жҚ®еҲҶжһҗе№іеҸ°жҖҺд№Ҳжҗӯе»әвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
дјҒдёҡеҸ‘еұ•еҲ°дёҖе®ҡ规模йғҪдјҡжҗӯе»әеҚ•зӢ¬зҡ„BIе№іеҸ°жқҘеҒҡж•°жҚ®еҲҶжһҗпјҢеҚіOLAP(иҒ”жңәеҲҶжһҗеӨ„зҗҶ)пјҢдёҖиҲ¬йғҪжҳҜеҹәдәҺж•°жҚ®еә“жҠҖжңҜжқҘжһ„е»әпјҢеҹәжң¬йғҪжҳҜеҚ•жңәдә§е“ҒгҖӮйҷӨдәҶдёҡеҠЎж•°жҚ®зҡ„зӣёе…іеҲҶжһҗеӨ–пјҢдә’иҒ”зҪ‘дјҒдёҡиҝҳдјҡеҜ№з”ЁжҲ·иЎҢдёәиҝӣиЎҢеҲҶжһҗпјҢиҝӣдёҖжӯҘжҢ–жҺҳжҪңеңЁд»·еҖјпјҢиҝҷж—¶ж•°жҚ®е°ұдјҡиҶЁиғҖеҫ—еҫҲеҺүе®іпјҢдёҖеӨ©зҡ„ж•°жҚ®йҮҸеҸҜиғҪдјҡжҲҗеҚғдёҮжҲ–дёҠдәҝпјҢеҜ№еҹәдәҺж•°жҚ®еә“зҡ„дј з»ҹж•°жҚ®еҲҶжһҗе№іеҸ°зҡ„ж•°жҚ®еӯҳеӮЁе’ҢеҲҶжһҗи®Ўз®—еёҰжқҘдәҶеҫҲеӨ§жҢ‘жҲҳгҖӮ
дёәдәҶеә”еҜ№йҡҸзқҖж•°жҚ®йҮҸзҡ„еўһй•ҝгҖҒж•°жҚ®еӨ„зҗҶжҖ§иғҪзҡ„еҸҜжү©еұ•жҖ§пјҢи®ёеӨҡдјҒдёҡзә·зә·иҪ¬еҗ‘Hadoopе№іеҸ°жқҘжҗӯе»әж•°жҚ®еҲҶжһҗе№іеҸ°гҖӮHadoopе№іеҸ°е…·жңүеҲҶеёғејҸеӯҳеӮЁеҸҠ并иЎҢи®Ўз®—зҡ„зү№жҖ§пјҢеӣ жӯӨеҸҜиҪ»жқҫжү©еұ•еӯҳеӮЁз»“зӮ№е’Ңи®Ўз®—з»“зӮ№пјҢи§ЈеҶіж•°жҚ®еўһй•ҝеёҰжқҘзҡ„жҖ§иғҪ瓶йўҲгҖӮ
йҡҸзқҖи¶ҠжқҘи¶ҠеӨҡзҡ„дјҒдёҡејҖе§ӢдҪҝз”ЁHadoopе№іеҸ°пјҢд№ҹдёәHadoopе№іеҸ°еј•е…ҘдәҶи®ёеӨҡзҡ„жҠҖжңҜпјҢеҰӮHiveгҖҒSpark SQLгҖҒKafkaзӯүпјҢдё°еҜҢзҡ„组件дҪҝеҫ—з”ЁHadoopжһ„е»әж•°жҚ®еҲҶжһҗе№іеҸ°д»Јжӣҝдј з»ҹж•°жҚ®еҲҶжһҗе№іеҸ°жҲҗдёәеҸҜиғҪгҖӮ
дёҖгҖҒж•°жҚ®еҲҶжһҗе№іеҸ°жһ¶жһ„еҺҹзҗҶ
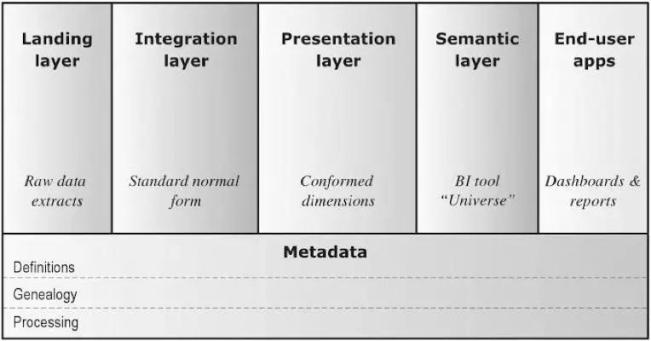
д»ҺжҰӮеҝөдёҠи®ІпјҢжҲ‘们еҸҜд»ҘжҠҠж•°жҚ®еҲҶжһҗе№іеҸ°еҲҶдёәжҺҘе…ҘеұӮ(Landing)гҖҒж•ҙеҗҲеұӮ(Integration)гҖҒиЎЁзҺ°еұӮ(Persentation)гҖҒиҜӯд№үеұӮ(Semantic)гҖҒз»Ҳз«Ҝз”ЁжҲ·еә”з”Ё(End-user applications)гҖҒе…ғж•°жҚ®(Metadata)гҖӮеҹәдәҺHadoopе’Ңж•°жҚ®еә“зҡ„еҲҶжһҗе№іеҸ°еҹәжң¬жҰӮеҝөе’ҢйҖ»иҫ‘жһ¶жһ„жҳҜйҖҡз”Ёзҡ„пјҢеҸӘжҳҜжҠҖжңҜйҖүеһӢзҡ„дёҚеҗҢпјҡ
жҺҘе…ҘеұӮ(Landing)пјҡд»Ҙе’Ңжәҗзі»з»ҹзӣёеҗҢзҡ„з»“жһ„жҡӮеӯҳеҺҹе§Ӣж•°жҚ®пјҢжңүж—¶иў«з§°дёәвҖңиҙҙжәҗеұӮвҖқжҲ–ODS;
ж•ҙеҗҲеұӮ(Integration)пјҡжҢҒд№…еӯҳеӮЁж•ҙеҗҲеҗҺзҡ„дјҒдёҡж•°жҚ®пјҢй’ҲеҜ№дјҒдёҡдҝЎжҒҜе®һдҪ“е’ҢдёҡеҠЎдәӢ件е»әжЁЎпјҢд»ЈиЎЁз»„з»Үзҡ„вҖң***зңҹзӣёжқҘжәҗвҖқпјҢжңүж—¶иў«з§°дёәвҖңж•°жҚ®д»“еә“вҖқ;
иЎЁзҺ°еұӮ(Presentation)пјҡдёәж»Ўи¶іжңҖз»Ҳз”ЁжҲ·зҡ„йңҖжұӮжҸҗдҫӣеҸҜж¶Ҳиҙ№зҡ„ж•°жҚ®пјҢй’ҲеҜ№е•ҶдёҡжҷәиғҪе’ҢжҹҘиҜўжҖ§иғҪе»әжЁЎпјҢжңүж—¶иў«з§°дёәвҖңж•°жҚ®йӣҶеёӮвҖқ;
иҜӯд№үеұӮ(Semantic)пјҡжҸҗдҫӣж•°жҚ®зҡ„е‘ҲзҺ°еҪўејҸе’Ңи®ҝй—®жҺ§еҲ¶пјҢдҫӢеҰӮжҹҗз§ҚжҠҘиЎЁе·Ҙе…·;
з»Ҳз«Ҝз”ЁжҲ·еә”з”Ё(End-user applications)пјҡдҪҝз”ЁиҜӯд№үеұӮзҡ„е·Ҙе…·пјҢе°ҶиЎЁзҺ°еұӮж•°жҚ®жңҖз»Ҳе‘ҲзҺ°з»ҷз”ЁжҲ·пјҢеҢ…жӢ¬д»ӘиЎЁжқҝгҖҒжҠҘиЎЁгҖҒеӣҫиЎЁзӯүеӨҡз§ҚеҪўејҸ;
е…ғж•°жҚ®(Metadata)пјҡи®°еҪ•еҗ„еұӮж•°жҚ®йЎ№зҡ„е®ҡд№ү(Definitions)гҖҒиЎҖзјҳ(Genealogy)гҖҒеӨ„зҗҶиҝҮзЁӢ(Processing)гҖӮ
жқҘиҮӘдёҚеҗҢж•°жҚ®жәҗзҡ„вҖңз”ҹвҖқж•°жҚ®(жҺҘе…ҘеұӮ)пјҢе’Ңз»ҸиҝҮдёӯй—ҙеӨ„зҗҶд№ӢеҗҺеҫ—еҲ°зҡ„ж•ҙеҗҲеұӮгҖҒиЎЁзҺ°еұӮзҡ„ж•°жҚ®жЁЎеһӢпјҢйғҪдјҡеӯҳеӮЁеңЁж•°жҚ®ж№–йҮҢеӨҮз”ЁгҖӮ
ж•°жҚ®ж№–зҡ„е®һзҺ°йҖҡеёёе»әз«ӢеңЁHadoopз”ҹжҖҒдёҠпјҢеҸҜиғҪзӣҙжҺҘеӯҳеӮЁеңЁHDFSдёҠпјҢд№ҹеҸҜиғҪеӯҳеӮЁеңЁHBaseжҲ–HiveдёҠпјҢд№ҹжңүз”Ёе…ізі»еһӢж•°жҚ®еә“дҪңдёәж•°жҚ®ж№–еӯҳеӮЁзҡ„еҸҜиғҪжҖ§еӯҳеңЁгҖӮ

дёӢеӣҫиҜҙжҳҺдәҶж•°жҚ®еҲҶжһҗе№іеҸ°зҡ„ж•°жҚ®еӨ„зҗҶжөҒзЁӢпјҡ
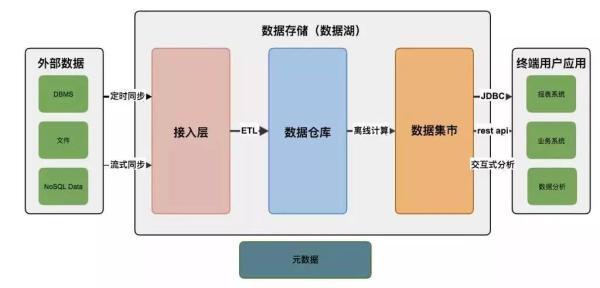
ж•°жҚ®еҲҶжһҗеҹәжң¬йғҪжҳҜеҚ•зӢ¬зҡ„зі»з»ҹпјҢдјҡе°Ҷе…¶д»–ж•°жҚ®жәҗзҡ„ж•°жҚ®(еҚіеӨ–йғЁж•°жҚ®)еҗҢжӯҘеҲ°ж•°жҚ®е№іеҸ°зҡ„еӯҳеӮЁдҪ“зі»жқҘ(еҚіж•°жҚ®ж№–)пјҢдёҖиҲ¬ж•°жҚ®е…Ҳиҝӣе…ҘеҲ°жҺҘе…ҘеұӮпјҢиҝҷдёҖеұӮеҸӘз®ҖеҚ•зҡ„е°ҶеӨ–йғЁж•°жҚ®еҗҢжӯҘеҲ°ж•°жҚ®еҲҶжһҗе№іеҸ°пјҢжІЎжңүеҒҡе…¶д»–еӨ„зҗҶпјҢиҝҷж ·еҗҢжӯҘеҮәй”ҷеҗҺйҮҚиҜ•еҚіеҸҜпјҢжңүе®ҡж—¶еҗҢжӯҘе’ҢжөҒејҸеҗҢжӯҘдёӨз§Қпјҡ
ж•°жҚ®еҲҶжһҗе№іеҸ°жү§иЎҢеҜ№еә”ж“ҚдҪңдҝ®ж”№ж•°жҚ®гҖӮ
жҺҘе…ҘеұӮж•°жҚ®йңҖиҰҒз»ҸиҝҮETLеӨ„зҗҶжӯҘйӘӨжүҚдјҡиҝӣе…Ҙж•°жҚ®д»“еә“пјҢж•°жҚ®еҲҶжһҗдәәе‘ҳйғҪжҳҜеҹәдәҺж•°жҚ®д»“еә“зҡ„ж•°жҚ®жқҘеҒҡеҲҶжһҗи®Ўз®—пјҢж•°жҚ®д»“еә“еҸҜд»ҘзңӢдҪңж•°жҚ®еҲҶжһҗзҡ„***жқҘжәҗпјҢETLдјҡе°ҶжҺҘе…ҘеұӮзҡ„ж•°жҚ®еҒҡж•°жҚ®жё…жҙ—гҖҒиҪ¬жҚўпјҢеҶҚеҠ иҪҪеҲ°ж•°жҚ®д»“еә“пјҢиҝҮж»ӨжҲ–еӨ„зҗҶдёҚеҗҲжі•гҖҒдёҚе®Ңж•ҙзҡ„ж•°жҚ®пјҢ并дҪҝз”Ёз»ҹдёҖзҡ„з»ҙеәҰжқҘиЎЁзӨәж•°жҚ®зҠ¶жҖҒгҖӮжңүзҡ„зі»з»ҹдјҡеңЁиҝҷдёҖеұӮе°ұе°Ҷж•°жҚ®д»“еә“жһ„е»әжҲҗж•°жҚ®з«Ӣж–№дҪ“гҖҒе°Ҷз»ҙеәҰдҝЎжҒҜжһ„е»әжҲҗйӣӘиҠұжҲ–жҳҹеһӢжЁЎејҸ;д№ҹжңүзҡ„зі»з»ҹиҝҷдёҖеұӮеҸӘжҳҜз»ҹдёҖдәҶжүҖжңүж•°жҚ®дҝЎжҒҜпјҢжІЎжңүеҒҡж•°жҚ®з«Ӣж–№дҪ“пјҢз•ҷеңЁж•°жҚ®йӣҶеёӮеҒҡгҖӮ
ж•°жҚ®йӣҶеёӮжҳҜеҹәдәҺж•°жҚ®д»“еә“ж•°жҚ®еҜ№дёҡеҠЎе…іеҝғзҡ„дҝЎжҒҜеҒҡи®Ўз®—жҸҗеҸ–еҗҺеҫ—еҲ°зҡ„иҝӣдёҖжӯҘдҝЎжҒҜпјҢжҳҜдёҡеҠЎдәәе‘ҳзӣҙжҺҘйқўеҜ№зҡ„дҝЎжҒҜпјҢжҳҜж•°жҚ®д»“еә“зҡ„иҝӣдёҖжӯҘи®Ўз®—е’Ңж·ұе…ҘеҲҶжһҗзҡ„з»“жһңпјҢдёҖиҲ¬йғҪдјҡжһ„е»әж•°жҚ®з«Ӣж–№дҪ“гҖӮзі»з»ҹејҖеҸ‘дәәе‘ҳдёҖиҲ¬дјҡејҖеҸ‘йЎөйқўжқҘеҗ‘з”ЁжҲ·еұ•зӨәж•°жҚ®йӣҶеёӮзҡ„ж•°жҚ®гҖӮ
дәҢгҖҒеҹәдәҺHadoopжһ„е»әж•°жҚ®еҲҶжһҗе№іеҸ°
еҹәдәҺHadoopжһ„е»әзҡ„ж•°жҚ®еҲҶжһҗе№іеҸ°е»әжһ„зҗҶи®әдёҺж•°жҚ®еӨ„зҗҶжөҒзЁӢдёҺеүҚйқўи®Ізҡ„зӣёеҗҢгҖӮдј з»ҹеҲҶжһҗе№іеҸ°дҪҝз”Ёж•°жҚ®еә“еҘ—件жһ„е»әпјҢиҝҷйҮҢжҲ‘们дҪҝз”ЁHadoopе№іеҸ°зҡ„组件гҖӮ
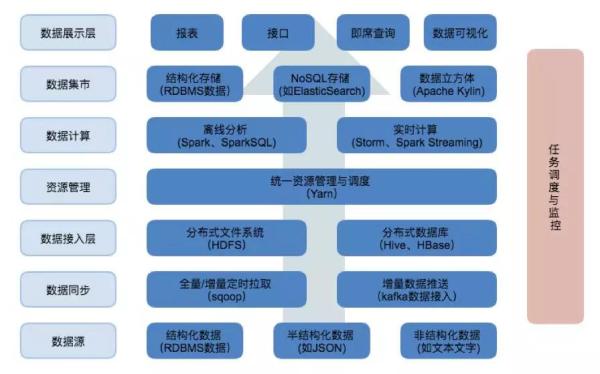
дёҠйқўиҝҷеј еӣҫжҳҜжҲ‘们дҪҝз”ЁеҲ°зҡ„Hadoopе№іеҸ°зҡ„组件пјҢж•°жҚ®д»ҺдёӢеҲ°дёҠжөҒеҠЁпјҢж•°жҚ®еӨ„зҗҶжөҒзЁӢе’ҢдёҠйқўиҜҙзҡ„дёҖиҮҙгҖӮ
д»»еҠЎи°ғеәҰиҙҹиҙЈе°Ҷж•°жҚ®еӨ„зҗҶзҡ„жөҒзЁӢдёІиҒ”иө·жқҘпјҢиҝҷйҮҢжҲ‘йҖүжӢ©дҪҝз”Ёзҡ„жҳҜOozieпјҢд№ҹжңүеҫҲеӨҡе…¶е®ғйҖүжӢ©гҖӮ
1гҖҒж•°жҚ®еӯҳеӮЁ
еҹәдәҺHadoopзҡ„ж•°жҚ®ж№–дё»иҰҒз”ЁеҲ°дәҶHDFSгҖҒHiveе’ҢHBaseпјҢHDFSжҳҜHadoopе№іеҸ°зҡ„ж–Ү件еӯҳеӮЁзі»з»ҹпјҢжҲ‘们зӣҙжҺҘж“Қзәөж–Ү件жҳҜжҜ”иҫғеӨҚжқӮзҡ„пјҢжүҖд»ҘеҸҜд»ҘдҪҝз”ЁеҲҶеёғејҸж•°жҚ®еә“HiveжҲ–HBaseз”ЁжқҘеҒҡж•°жҚ®ж№–пјҢеӯҳеӮЁжҺҘе…ҘеұӮгҖҒж•°жҚ®д»“еә“гҖҒж•°жҚ®йӣҶеёӮзҡ„ж•°жҚ®гҖӮ
Hiveе’ҢHBaseеҗ„жңүдјҳеҠҝпјҡHBaseжҳҜдёҖдёӘNoSQLж•°жҚ®еә“пјҢйҡҸжңәжҹҘиҜўжҖ§иғҪе’ҢеҸҜжү©еұ•жҖ§йғҪжҜ”иҫғеҘҪ;иҖҢHiveжҳҜдёҖдёӘеҹәдәҺHDFSзҡ„ж•°жҚ®еә“пјҢж•°жҚ®ж–Ү件йғҪд»ҘHDFSж–Ү件(еӨ№)еҪўејҸеӯҳж”ҫпјҢеӯҳеӮЁдәҶиЎЁзҡ„еӯҳеӮЁдҪҚзҪ®(еҚіеңЁHDFSдёӯзҡ„дҪҚзҪ®)гҖҒеӯҳеӮЁж јејҸзӯүе…ғж•°жҚ®пјҢHiveж”ҜжҢҒSQLжҹҘиҜўпјҢеҸҜе°ҶжҹҘиҜўи§ЈжһҗжҲҗMap/Reduceжү§иЎҢпјҢиҝҷеҜ№дј з»ҹзҡ„ж•°жҚ®еҲҶжһҗе№іеҸ°ејҖеҸ‘дәәе‘ҳжӣҙеҸӢеҘҪгҖӮ
Hiveж•°жҚ®ж јејҸеҸҜйҖүжӢ©ж–Үжң¬ж јејҸжҲ–дәҢиҝӣеҲ¶ж јејҸпјҢж–Үжң¬ж јејҸжңүcsvгҖҒjsonжҲ–иҮӘе®ҡд№үеҲҶйҡ”пјҢдәҢиҝӣеҲ¶ж јејҸжңүorcжҲ–parquetпјҢ他们йғҪеҹәдәҺиЎҢеҲ—ејҸеӯҳеӮЁпјҢеңЁжҹҘиҜўж—¶жҖ§иғҪжӣҙеҘҪгҖӮеҗҢж—¶еҸҜйҖүжӢ©еҲҶеҢә(partition)пјҢиҝҷж ·еңЁжҹҘиҜўж—¶еҸҜйҖҡиҝҮжқЎд»¶иҝҮж»ӨиҝӣдёҖжӯҘеҮҸе°‘ж•°жҚ®йҮҸгҖӮжҺҘе…ҘеұӮдёҖиҲ¬йҖүжӢ©csvжҲ–jsonзӯүж–Үжң¬ж јејҸпјҢд№ҹдёҚеҒҡеҲҶеҢәпјҢд»Ҙе°ҪйҮҸз®ҖеҢ–ж•°жҚ®еҗҢжӯҘгҖӮж•°жҚ®д»“еә“еҲҷйҖүжӢ©orcжҲ–parquetпјҢд»ҘжҸҗеҚҮж•°жҚ®зҰ»зәҝи®Ўз®—жҖ§иғҪгҖӮ
ж•°жҚ®йӣҶеёӮиҝҷеқ—еҸҜд»ҘйҖүжӢ©е°Ҷж•°жҚ®зҒҢеӣһдј з»ҹж•°жҚ®еә“(RDBMS)пјҢд№ҹеҸҜд»ҘеҒңз•ҷеңЁж•°жҚ®еҲҶжһҗе№іеҸ°пјҢдҪҝз”ЁNoSQLжҸҗдҫӣж•°жҚ®жҹҘиҜўжҲ–з”ЁApache KylinжқҘжһ„е»әж•°жҚ®з«Ӣж–№дҪ“пјҢжҸҗдҫӣSQLжҹҘиҜўжҺҘеҸЈгҖӮ
2гҖҒж•°жҚ®еҗҢжӯҘ
жҲ‘们йҖҡиҝҮж•°жҚ®еҗҢжӯҘеҠҹиғҪдҪҝеҫ—ж•°жҚ®еҲ°иҫҫжҺҘе…ҘеұӮпјҢдҪҝз”ЁеҲ°дәҶSqoopе’ҢKafkaгҖӮж•°жҚ®еҗҢжӯҘеҸҜд»ҘеҲҶдёәе…ЁйҮҸеҗҢжӯҘе’ҢеўһйҮҸеҗҢжӯҘпјҢеҜ№дәҺе°ҸиЎЁеҸҜд»ҘйҮҮз”Ёе…ЁйҮҸеҗҢжӯҘпјҢеҜ№дәҺеӨ§иЎЁе…ЁйҮҸеҗҢжӯҘжҳҜжҜ”иҫғиҖ—ж—¶зҡ„пјҢдёҖиҲ¬йғҪйҮҮз”ЁеўһйҮҸеҗҢжӯҘпјҢе°ҶеҸҳеҠЁеҗҢжӯҘеҲ°ж•°жҚ®е№іеҸ°жү§иЎҢпјҢд»ҘиҫҫеҲ°дёӨиҫ№ж•°жҚ®дёҖиҮҙзҡ„зӣ®зҡ„гҖӮ
е…ЁйҮҸеҗҢжӯҘдҪҝз”ЁSqoopжқҘе®ҢжҲҗпјҢеўһйҮҸеҗҢжӯҘеҰӮжһңиҖғиҷ‘е®ҡж—¶жү§иЎҢпјҢд№ҹеҸҜд»Ҙз”ЁSqoopжқҘе®ҢжҲҗгҖӮжҲ–иҖ…пјҢд№ҹеҸҜд»ҘйҖҡиҝҮKafkaзӯүMQжөҒејҸеҗҢжӯҘж•°жҚ®пјҢеүҚжҸҗжҳҜеӨ–йғЁж•°жҚ®жәҗдјҡе°ҶеҸҳеҠЁеҸ‘йҖҒеҲ°MQгҖӮ
3гҖҒETLеҸҠзҰ»зәҝи®Ўз®—
жҲ‘们дҪҝз”ЁYarnжқҘз»ҹдёҖз®ЎзҗҶе’Ңи°ғеәҰи®Ўз®—иө„жәҗгҖӮзӣёиҫғMap/ReduceпјҢSpark SQLеҸҠSpark RDDеҜ№ејҖеҸ‘дәәе‘ҳжӣҙеҸӢеҘҪпјҢеҹәдәҺеҶ…еӯҳи®Ўз®—ж•ҲзҺҮд№ҹжӣҙй«ҳпјҢжүҖд»ҘжҲ‘们дҪҝз”ЁSpark on YarnдҪңдёәеҲҶжһҗе№іеҸ°зҡ„и®Ўз®—йҖүеһӢгҖӮ
ETLеҸҜд»ҘйҖҡиҝҮSpark SQLжҲ–Hive SQLжқҘе®ҢжҲҗпјҢHiveеңЁ2.0д»ҘеҗҺж”ҜжҢҒеӯҳеӮЁиҝҮзЁӢпјҢдҪҝз”Ёиө·жқҘжӣҙж–№дҫҝгҖӮеҪ“然пјҢеҮәдәҺжҖ§иғҪиҖғиҷ‘Saprk SQLиҝҳжҳҜдёҚй”ҷзҡ„йҖүжӢ©гҖӮ
вҖңHadoopзҡ„ж•°жҚ®еҲҶжһҗе№іеҸ°жҖҺд№Ҳжҗӯе»әвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





