Hadoopз”ҹжҖҒеңҲд»ҘеҸҠеҗ„з»„жҲҗйғЁеҲҶжҳҜд»Җд№Ҳ
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іHadoopз”ҹжҖҒеңҲд»ҘеҸҠеҗ„з»„жҲҗйғЁеҲҶжҳҜд»Җд№ҲпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
1.HadoopжҳҜд»Җд№Ҳ?
йҖӮеҗҲеӨ§ж•°жҚ®зҡ„еҲҶеёғејҸеӯҳеӮЁдёҺи®Ўз®—е№іеҸ°
HDFS: Hadoop Distributed File SystemеҲҶеёғејҸж–Ү件系з»ҹ
MapReduceпјҡ并иЎҢи®Ўз®—жЎҶжһ¶
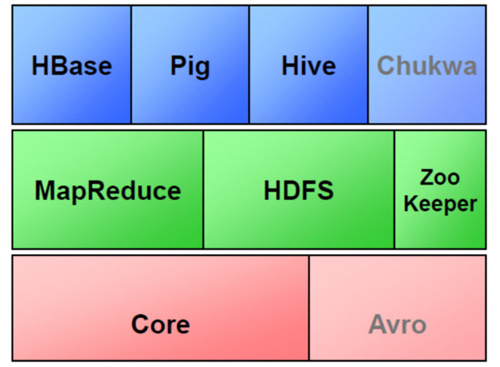
2.Hadoopз”ҹжҖҒеңҲ
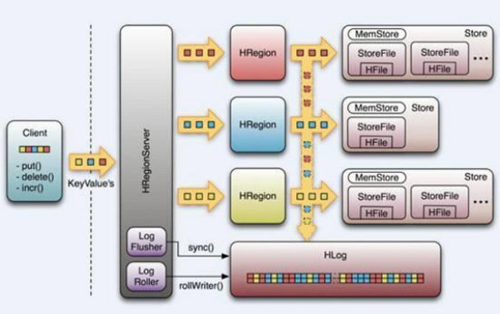
в‘ HBase
Google Bigtableзҡ„ејҖжәҗе®һзҺ°
еҲ—ејҸж•°жҚ®еә“
еҸҜйӣҶзҫӨеҢ–
еҸҜд»ҘдҪҝз”ЁshellгҖҒwebгҖҒapiзӯүеӨҡз§Қж–№ејҸи®ҝй—®
йҖӮеҗҲй«ҳиҜ»еҶҷ(insert)зҡ„еңәжҷҜ
HQLжҹҘиҜўиҜӯиЁҖ
NoSQLзҡ„е…ёеһӢд»ЈиЎЁдә§е“Ғ
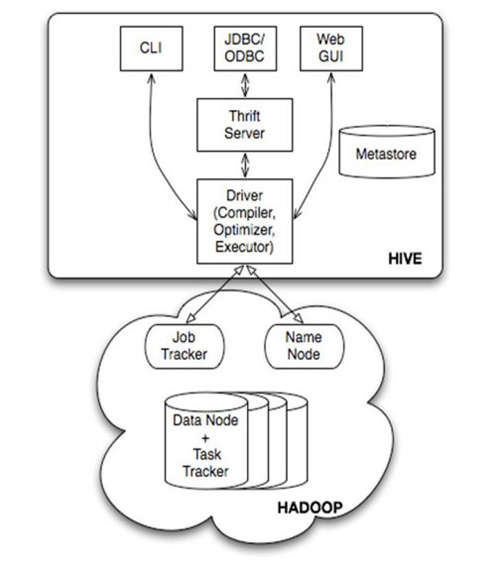
в‘ЎHive
ж•°жҚ®д»“еә“е·Ҙе…·гҖӮеҸҜд»ҘжҠҠHadoopдёӢзҡ„еҺҹе§Ӣз»“жһ„еҢ–ж•°жҚ®еҸҳжҲҗHiveдёӯзҡ„иЎЁ
ж”ҜжҢҒдёҖз§ҚдёҺSQLеҮ д№Һе®Ңе…ЁзӣёеҗҢзҡ„иҜӯиЁҖHiveQLгҖӮйҷӨдәҶдёҚж”ҜжҢҒжӣҙж–°гҖҒзҙўеј•е’ҢдәӢеҠЎпјҢеҮ д№ҺSQLзҡ„е…¶е®ғзү№еҫҒйғҪиғҪж”ҜжҢҒ
еҸҜд»ҘзңӢжҲҗжҳҜд»ҺSQLеҲ°Map-Reduceзҡ„жҳ е°„еҷЁ
жҸҗдҫӣshellгҖҒJDBC/ODBCгҖҒThriftгҖҒWebзӯүжҺҘеҸЈ
в‘ўZookeeper
Google Chubbyзҡ„ејҖжәҗе®һзҺ°
з”ЁдәҺеҚҸи°ғеҲҶеёғејҸзі»з»ҹдёҠзҡ„еҗ„з§ҚжңҚеҠЎгҖӮдҫӢеҰӮзЎ®и®Өж¶ҲжҒҜжҳҜеҗҰеҮҶзЎ®еҲ°иҫҫпјҢйҳІжӯўеҚ•зӮ№еӨұж•ҲпјҢеӨ„зҗҶиҙҹиҪҪеқҮиЎЎзӯү
еә”з”ЁеңәжҷҜпјҡHbaseпјҢе®һзҺ°NamenodeиҮӘеҠЁеҲҮжҚў
е·ҘдҪңеҺҹзҗҶпјҡ***пјҢи·ҹйҡҸиҖ…д»ҘеҸҠйҖүдёҫиҝҮзЁӢ

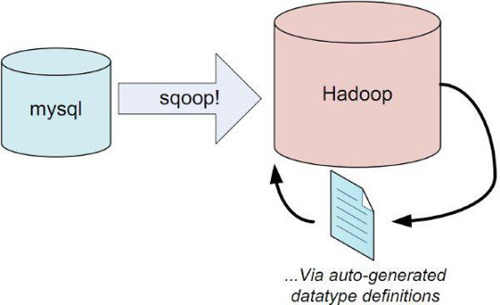
в‘ЈSqoop
з”ЁдәҺеңЁHadoopе’Ңе…ізі»еһӢж•°жҚ®еә“д№Ӣй—ҙдәӨжҚўж•°жҚ®
йҖҡиҝҮJDBCжҺҘеҸЈиҝһе…Ҙе…ізі»еһӢж•°жҚ®еә“
в‘ӨChukwa
жһ¶жһ„еңЁHadoopд№ӢдёҠзҡ„ж•°жҚ®йҮҮйӣҶдёҺеҲҶжһҗжЎҶжһ¶
дё»иҰҒиҝӣиЎҢж—Ҙеҝ—йҮҮйӣҶе’ҢеҲҶжһҗ
йҖҡиҝҮе®үиЈ…еңЁж”¶йӣҶиҠӮзӮ№зҡ„вҖңд»ЈзҗҶвҖқйҮҮйӣҶжңҖеҺҹе§Ӣзҡ„ж—Ҙеҝ—ж•°жҚ®
д»ЈзҗҶе°Ҷж•°жҚ®еҸ‘з»ҷ收йӣҶеҷЁ
收йӣҶеҷЁе®ҡж—¶е°Ҷж•°жҚ®еҶҷе…ҘHadoopйӣҶзҫӨ
жҢҮе®ҡе®ҡж—¶еҗҜеҠЁзҡ„Map-ReduceдҪңдёҡйҳҹж•°жҚ®иҝӣиЎҢеҠ е·ҘеӨ„зҗҶе’ҢеҲҶжһҗ

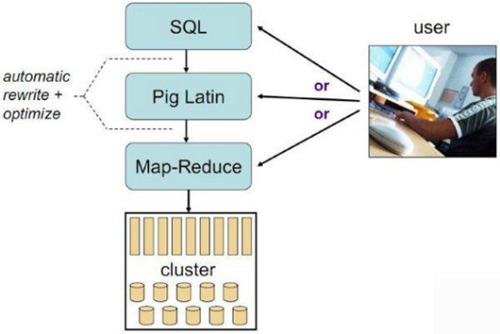
в‘ҘPig
Hadoopе®ўжҲ·з«Ҝ
дҪҝз”Ёзұ»дјјдәҺSQLзҡ„йқўеҗ‘ж•°жҚ®жөҒзҡ„иҜӯиЁҖPig Latin
Pig LatinеҸҜд»Ҙе®ҢжҲҗжҺ’еәҸпјҢиҝҮж»ӨпјҢжұӮе’ҢпјҢиҒҡз»„пјҢе…іиҒ”зӯүж“ҚдҪңпјҢеҸҜд»Ҙж”ҜжҢҒиҮӘе®ҡд№үеҮҪж•°
PigиҮӘеҠЁжҠҠPig Latinжҳ е°„дёәMap-ReduceдҪңдёҡдёҠдј еҲ°йӣҶзҫӨиҝҗиЎҢпјҢеҮҸе°‘з”ЁжҲ·зј–еҶҷJavaзЁӢеәҸзҡ„иӢҰжҒј
в‘ҰAvro
ж•°жҚ®еәҸеҲ—еҢ–е·Ҙе…·пјҢз”ұHadoopзҡ„еҲӣе§ӢдәәDoug Cuttingдё»жҢҒејҖеҸ‘
з”ЁдәҺж”ҜжҢҒеӨ§жү№йҮҸж•°жҚ®дәӨжҚўзҡ„еә”з”ЁгҖӮж”ҜжҢҒдәҢиҝӣеҲ¶еәҸеҲ—еҢ–ж–№ејҸпјҢеҸҜд»ҘдҫҝжҚ·пјҢеҝ«йҖҹең°еӨ„зҗҶеӨ§йҮҸж•°жҚ®
еҠЁжҖҒиҜӯиЁҖеҸӢеҘҪпјҢAvroжҸҗдҫӣзҡ„жңәеҲ¶дҪҝеҠЁжҖҒиҜӯиЁҖеҸҜд»Ҙж–№дҫҝең°еӨ„зҗҶ Avroж•°жҚ®гҖӮ
ThriftжҺҘеҸЈ
⑧Cassandra
NoSQLпјҢеҲҶеёғејҸзҡ„Key-ValueеһӢж•°жҚ®еә“пјҢз”ұFacebookиҙЎзҢ®
дёҺHbaseзұ»дјјпјҢд№ҹжҳҜеҖҹйүҙGoogle Bigtableзҡ„жҖқжғідҪ“зі»
еҸӘжңүйЎәеәҸеҶҷпјҢжІЎжңүйҡҸжңәеҶҷзҡ„и®ҫи®ЎпјҢж»Ўи¶ій«ҳиҙҹиҚ·жғ…еҪўзҡ„жҖ§иғҪйңҖжұӮ
3.Hadoopз”ҹжҖҒеңҲжөҒзЁӢеӣҫ
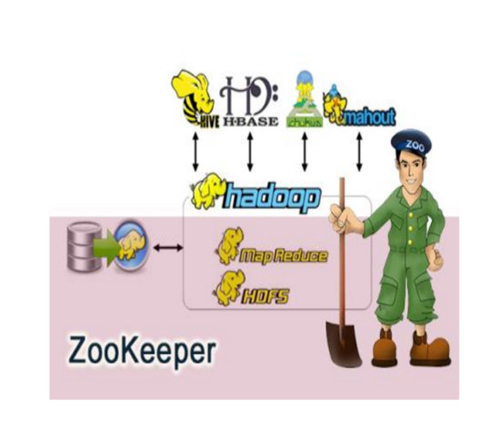
д»ҘдёҠе°ұжҳҜHadoopз”ҹжҖҒеңҲд»ҘеҸҠеҗ„з»„жҲҗйғЁеҲҶжҳҜд»Җд№ҲпјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





