RedditдёӯжҖҺд№Ҳз»ҹи®ЎжҜҸдёӘеё–еӯҗзҡ„жөҸи§ҲйҮҸ
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іRedditдёӯжҖҺд№Ҳз»ҹи®ЎжҜҸдёӘеё–еӯҗзҡ„жөҸи§ҲйҮҸпјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
и®Ўж•°жңәеҲ¶
еҜ№дәҺи®Ўж•°зі»з»ҹжҲ‘们主иҰҒжңүеӣӣз§ҚйңҖжұӮ:
её–еӯҗжөҸи§Ҳж•°еҝ…йЎ»жҳҜе®һж—¶жҲ–иҖ…иҝ‘е®һж—¶зҡ„пјҢиҖҢдёҚжҳҜжҜҸеӨ©жҲ–иҖ…жҜҸе°Ҹж—¶жұҮжҖ»гҖӮ
еҗҢдёҖз”ЁжҲ·еңЁзҹӯж—¶й—ҙеҶ…еӨҡж¬Ўи®ҝй—®её–еӯҗпјҢеҸӘз®—дёҖдёӘжөҸи§ҲйҮҸ
жҳҫзӨәзҡ„жөҸи§ҲйҮҸдёҺзңҹе®һжөҸи§ҲйҮҸй—ҙе…Ғи®ёжңүе°ҸзҷҫеҲҶд№ӢеҮ зҡ„иҜҜе·®
Reddit жҳҜе…Ёзҗғи®ҝй—®йҮҸ第八зҡ„зҪ‘з«ҷпјҢзі»з»ҹиҰҒиғҪеңЁз”ҹдә§зҺҜеўғзҡ„规模дёҠжӯЈеёёиҝҗиЎҢпјҢд»…е…Ғи®ёеҮ з§’зҡ„延иҝҹ
иҰҒе…ЁйғЁж»Ўи¶ід»ҘдёҠеӣӣдёӘйңҖжұӮзҡ„еӣ°йҡҫиҝңиҝңжҜ”еҗ¬дёҠеҺ»еӨ§зҡ„еӨҡгҖӮдёәдәҶе®һж—¶зІҫеҮҶи®Ўж•°пјҢжҲ‘们йңҖиҰҒзҹҘйҒ“жҹҗдёӘз”ЁжҲ·жҳҜеҗҰжӣҫз»Ҹи®ҝй—®иҝҮиҝҷзҜҮеё–еӯҗгҖӮжғіиҰҒзҹҘйҒ“иҝҷдёӘдҝЎжҒҜпјҢжҲ‘们е°ұиҰҒдёәжҜҸзҜҮеё–еӯҗз»ҙжҠӨдёҖдёӘи®ҝй—®з”ЁжҲ·зҡ„йӣҶеҗҲпјҢ然еҗҺеңЁжҜҸж¬Ўи®Ўз®—жөҸи§ҲйҮҸж—¶жЈҖжҹҘйӣҶеҗҲгҖӮдёҖдёӘ naive зҡ„е®һзҺ°ж–№ејҸе°ұжҳҜе°Ҷи®ҝй—®з”ЁжҲ·зҡ„йӣҶеҗҲеӯҳеӮЁеңЁеҶ…еӯҳзҡ„ hashMap дёӯпјҢд»Ҙеё–еӯҗ Id дёә keyгҖӮ
иҝҷз§Қе®һзҺ°ж–№ејҸеҜ№дәҺи®ҝй—®йҮҸдҪҺзҡ„её–еӯҗжҳҜеҸҜиЎҢзҡ„пјҢдҪҶдёҖж—ҰдёҖдёӘеё–еӯҗеҸҳеҫ—жөҒиЎҢпјҢи®ҝй—®йҮҸеү§еўһж—¶е°ұеҫҲйҡҫжҺ§еҲ¶дәҶгҖӮз”ҡиҮіжңүзҡ„её–еӯҗжңүи¶…иҝҮ 100 дёҮзҡ„зӢ¬з«Ӣи®ҝе®ў! еҜ№дәҺиҝҷж ·зҡ„её–еӯҗпјҢеӯҳеӮЁзӢ¬з«Ӣи®ҝе®ўзҡ„ ID 并且频з№ҒжҹҘиҜўжҹҗдёӘз”ЁжҲ·жҳҜеҗҰд№ӢеүҚжӣҫи®ҝй—®иҝҮдјҡз»ҷеҶ…еӯҳе’Ң CPU йҖ жҲҗеҫҲеӨ§зҡ„иҙҹжӢ…гҖӮ
еӣ дёәжҲ‘们дёҚиғҪжҸҗдҫӣеҮҶзЎ®зҡ„и®Ўж•°пјҢжҲ‘们жҹҘзңӢдәҶеҮ з§ҚдёҚеҗҢзҡ„еҹәж•°дј°и®Ўз®—жі•гҖӮжңүдёӨдёӘз¬ҰеҗҲжҲ‘们йңҖжұӮзҡ„йҖүжӢ©пјҡ
дёҖжҳҜзәҝжҖ§жҰӮзҺҮи®Ўж•°жі•пјҢеҫҲеҮҶзЎ®пјҢдҪҶеҪ“и®Ўж•°йӣҶеҗҲеҸҳеӨ§ж—¶жүҖйңҖеҶ…еӯҳдјҡзәҝжҖ§еҸҳеӨ§гҖӮ
дәҢжҳҜеҹәдәҺ HyperLogLog (д»ҘдёӢз®Җз§° HLL )зҡ„и®Ўж•°жі•гҖӮ HLL з©әй—ҙеӨҚжқӮеәҰиҫғдҪҺпјҢдҪҶжҳҜзІҫзЎ®еәҰдёҚеҰӮзәҝжҖ§и®Ўж•°гҖӮ
дёӢйқўзңӢдёӢ HLL дјҡиҠӮзңҒеӨҡе°‘еҶ…еӯҳгҖӮеҰӮжһңжҲ‘们йңҖиҰҒеӯҳеӮЁ 100 дёҮдёӘзӢ¬з«Ӣи®ҝе®ўзҡ„ ID, жҜҸдёӘз”ЁжҲ· ID 8 еӯ—иҠӮй•ҝпјҢйӮЈд№ҲдёәдәҶеӯҳеӮЁдёҖзҜҮеё–еӯҗзҡ„зӢ¬з«Ӣи®ҝе®ўжҲ‘们е°ұйңҖиҰҒ 8 Mзҡ„еҶ…еӯҳгҖӮеҸҚд№ӢпјҢеҰӮжһңйҮҮз”Ё HLL дјҡжҳҫи‘—еҮҸе°‘еҶ…еӯҳеҚ з”ЁгҖӮдёҚеҗҢзҡ„ HLL е®һзҺ°ж–№ејҸж¶ҲиҖ—зҡ„еҶ…еӯҳдёҚеҗҢгҖӮеҰӮжһңйҮҮз”ЁиҝҷзҜҮж–Үз« зҡ„е®һзҺ°ж–№жі•пјҢйӮЈд№ҲеӯҳеӮЁ 100 дёҮдёӘ ID д»…йңҖ 12 KBпјҢжҳҜеҺҹжқҘзҡ„ 0.15%!!
Big Data Counting: How to count a billion distinct objects using only 1.5KB of Memory – High Scalability –иҝҷзҜҮж–Үз« еҫҲеҘҪзҡ„жҖ»з»“дәҶдёҠйқўзҡ„з®—жі•гҖӮ
и®ёеӨҡ HLL зҡ„е®һзҺ°йғҪжҳҜз»“еҗҲдәҶдёҠйқўдёӨз§Қз®—жі•гҖӮеңЁйӣҶеҗҲе°Ҹзҡ„ж—¶еҖҷйҮҮз”ЁзәҝжҖ§и®Ўж•°пјҢеҪ“йӣҶеҗҲеӨ§е°ҸеҲ°иҫҫдёҖе®ҡзҡ„йҳҲеҖјеҗҺеҲҮжҚўеҲ° HLLгҖӮеүҚиҖ…йҖҡеёёиў«жҲҗдёә вҖқзЁҖз–ҸвҖң(sparse) HLLпјҢеҗҺиҖ…иў«з§°дёәвҖқзЁ еҜҶвҖң(dense) HLLгҖӮиҝҷз§Қз»“еҗҲдәҶдёӨз§Қз®—жі•зҡ„е®һзҺ°жңүеҫҲеӨ§зҡ„еҘҪеӨ„пјҢеӣ дёәе®ғеҜ№дәҺе°ҸйӣҶеҗҲе’ҢеӨ§йӣҶеҗҲйғҪиғҪеӨҹдҝқиҜҒзІҫзЎ®еәҰпјҢеҗҢж—¶дҝқиҜҒдәҶйҖӮеәҰзҡ„еҶ…еӯҳеўһй•ҝгҖӮ
зҺ°еңЁжҲ‘们已з»ҸзЎ®е®ҡиҰҒйҮҮз”Ё HLL з®—жі•дәҶпјҢдёҚиҝҮеңЁйҖүжӢ©е…·дҪ“зҡ„е®һзҺ°ж—¶пјҢжҲ‘们иҖғиҷ‘дәҶд»ҘдёӢдёүз§ҚдёҚеҗҢзҡ„е®һзҺ°гҖӮеӣ дёәжҲ‘们зҡ„ж•°жҚ®е·ҘзЁӢеӣўйҳҹдҪҝз”Ё Java е’Ң ScalaпјҢжүҖд»ҘжҲ‘们еҸӘиҖғиҷ‘ Java е’Ң Scala зҡ„е®һзҺ°гҖӮ
Twitter жҸҗдҫӣзҡ„ AlgebirdпјҢйҮҮз”Ё Scala е®һзҺ°гҖӮAlgebird жңүеҫҲеҘҪзҡ„ж–ҮжЎЈпјҢдҪҶ他们еҜ№дәҺ sparse е’Ң dense HLL зҡ„е®һзҺ°з»ҶиҠӮдёҚжҳҜеҫҲе®№жҳ“зҗҶи§ЈгҖӮ
stream-libдёӯжҸҗдҫӣзҡ„ HyperLogLog++пјҢ йҮҮз”Ё Java е®һзҺ°гҖӮstream-lib дёӯзҡ„д»Јз Ғж–ҮжЎЈйҪҗе…ЁпјҢдҪҶжңүдәӣйҡҫзҗҶи§ЈеҰӮдҪ•еҗҲйҖӮзҡ„дҪҝ用并且改йҖ зҡ„з¬ҰеҗҲжҲ‘们зҡ„йңҖжұӮгҖӮ
Redis HLL е®һзҺ°пјҢиҝҷжҳҜжҲ‘们жңҖз»ҲйҖүжӢ©зҡ„гҖӮжҲ‘们и®Өдёә Redis дёӯ HLLs зҡ„е®һзҺ°ж–ҮжЎЈйҪҗе…ЁгҖҒе®№жҳ“й…ҚзҪ®пјҢжҸҗдҫӣзҡ„зӣёе…і API д№ҹеҫҲе®№жҳ“йӣҶжҲҗгҖӮиҝҳжңүдёҖдёӘеҘҪеӨ„жҳҜпјҢжҲ‘们еҸҜд»Ҙз”ЁдёҖеҸ°дё“й—Ёзҡ„жңҚеҠЎеҷЁйғЁзҪІпјҢд»ҺиҖҢеҮҸиҪ»жҖ§иғҪдёҠзҡ„еҺӢеҠӣгҖӮ
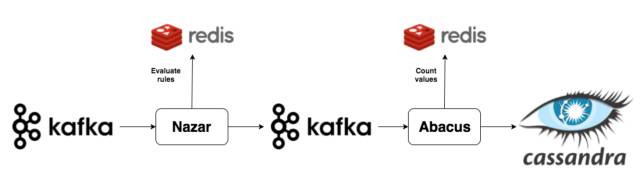
Reddit зҡ„ж•°жҚ®з®ЎйҒ“дҫқиө–дәҺ KafkaгҖӮеҪ“дёҖдёӘз”ЁжҲ·и®ҝй—®дәҶдёҖзҜҮеҚҡе®ўпјҢдјҡи§ҰеҸ‘дёҖдёӘдәӢ件пјҢдәӢ件дјҡиў«еҸ‘йҖҒеҲ°дәӢ件收йӣҶжңҚеҠЎеҷЁпјҢ并被жҢҒд№…еҢ–еңЁ Kafka дёӯгҖӮ
д№ӢеҗҺпјҢи®Ўж•°зі»з»ҹдјҡдҫқж¬ЎйЎәеәҸиҝҗиЎҢдёӨдёӘ组件гҖӮеңЁжҲ‘们зҡ„и®Ўж•°зі»з»ҹжһ¶жһ„дёӯпјҢ***йғЁеҲҶжҳҜдёҖдёӘ Kafka зҡ„ж¶Ҳиҙ№иҖ…пјҢжҲ‘们称д№Ӣдёә NazarгҖӮNazar дјҡд»Һ Kafka дёӯиҜ»еҸ–жҜҸдёӘдәӢ件пјҢ并е°Ҷе®ғйҖҡиҝҮдёҖзі»еҲ—й…ҚзҪ®зҡ„规еҲҷжқҘеҲӨж–ӯиҜҘдәӢ件жҳҜеҗҰйңҖиҰҒиў«и®Ўж•°гҖӮжҲ‘们еҸ–иҝҷдёӘеҗҚеӯ—д»…д»…жҳҜеӣ дёә Nazar жҳҜдёҖдёӘзңјзқӣеҪўзҠ¶зҡ„жҠӨиә«з¬ҰпјҢиҖҢ вҖқNazarвҖң зі»з»ҹе°ұеғҸзңјзқӣдёҖж ·дҪҝжҲ‘们зҡ„и®Ўж•°зі»з»ҹиҝңзҰ»дёҚжҖҖеҘҪж„ҸиҖ…зҡ„з ҙеқҸгҖӮе…¶дёӯдёҖдёӘжҲ‘们дёҚе°ҶдёҖдёӘдәӢ件计算еңЁеҶ…зҡ„еҺҹеӣ е°ұжҳҜеҗҢдёҖдёӘз”ЁжҲ·еңЁеҫҲзҹӯж—¶й—ҙеҶ…йҮҚеӨҚи®ҝй—®гҖӮNazar дјҡдҝ®ж”№дәӢ件пјҢеҠ дёҠдёӘж ҮжҳҺжҳҜеҗҰеә”иҜҘиў«и®Ўж•°зҡ„еёғе°”ж ҮиҜҶпјҢ并е°ҶдәӢ件йҮҚж–°ж”ҫе…Ҙ KafkaгҖӮ
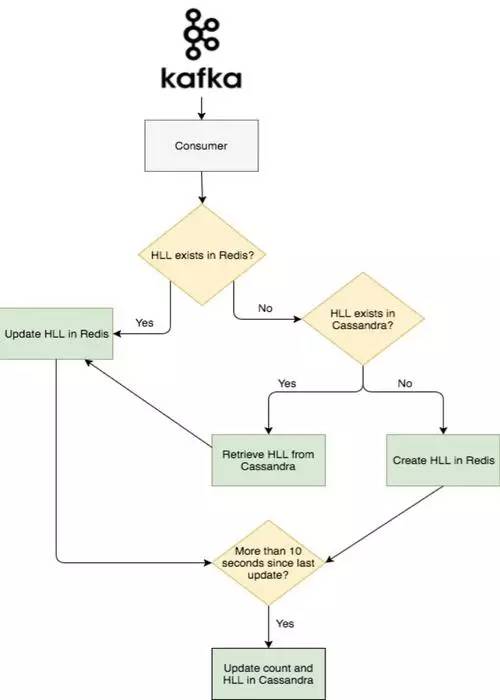
дёӢйқўе°ұеҲ°дәҶзі»з»ҹзҡ„第дәҢдёӘйғЁеҲҶгҖӮжҲ‘们е°Ҷ第дәҢдёӘ Kafka зҡ„ж¶Ҳиҙ№иҖ…з§°дҪң AbacusпјҢз”ЁжқҘиҝӣиЎҢзңҹжӯЈжөҸи§ҲйҮҸзҡ„и®Ўз®—пјҢ并且е°Ҷи®Ўз®—з»“жһңжҳҫзӨәеңЁзҪ‘з«ҷжҲ–е®ўжҲ·з«ҜгҖӮAbacus д»Һ Kafka дёӯиҜ»еҸ–з»ҸиҝҮ Nazar еӨ„зҗҶиҝҮзҡ„дәӢ件пјҢе№¶ж №жҚ® Nazar зҡ„еӨ„зҗҶз»“жһңеҶіе®ҡжҳҜи·іиҝҮиҝҷдёӘдәӢ件иҝҳжҳҜе°Ҷе…¶еҠ е…Ҙи®Ўж•°гҖӮеҰӮжһң Nazar дёӯзҡ„еӨ„зҗҶз»“жһңжҳҜеҸҜд»ҘеҠ е…Ҙи®Ўж•°пјҢйӮЈд№Ҳ Abacus йҰ–е…ҲдјҡжЈҖжҹҘиҝҷдёӘдәӢ件жүҖе…іиҒ”зҡ„её–еӯҗеңЁ Redis дёӯжҳҜеҗҰе·Із»ҸеӯҳеңЁдәҶдёҖдёӘ HLL и®Ўж•°еҷЁгҖӮеҰӮжһңе·Із»ҸеӯҳеңЁпјҢAbacus дјҡз»ҷ Redis еҸ‘йҖҒдёӘ PFADD зҡ„иҜ·жұӮгҖӮеҰӮжһңдёҚеӯҳеңЁпјҢйӮЈд№Ҳ Abacus дјҡз»ҷ Cassandra йӣҶзҫӨеҸ‘йҖҒдёӘиҜ·жұӮ(Cassandra з”ЁжқҘжҢҒд№…еҢ– HLL и®Ўж•°еҷЁе’Ң и®Ўж•°еҖјзҡ„)пјҢ然еҗҺеҗ‘ Redis еҸ‘йҖҒ SET иҜ·жұӮгҖӮиҝҷйҖҡеёёдјҡеҸ‘з”ҹеңЁзҪ‘еҸӢи®ҝй—®иҫғиҖҒеё–еӯҗзҡ„ж—¶еҖҷпјҢиҝҷж—¶иҜҘеё–еӯҗзҡ„и®Ўж•°еҷЁеҫҲеҸҜиғҪе·Із»ҸеңЁ Redis дёӯиҝҮжңҹдәҶгҖӮ
дёәдәҶеӯҳеӮЁеӯҳеңЁ Redis дёӯзҡ„и®Ўж•°еҷЁиҝҮжңҹзҡ„иҖҒеё–еӯҗзҡ„жөҸи§ҲйҮҸгҖӮAbacus дјҡе‘ЁжңҹжҖ§зҡ„е°Ҷ Redis дёӯе…ЁйғЁзҡ„ HLL е’Ң жҜҸзҜҮеё–еӯҗзҡ„жөҸи§ҲйҮҸеҶҷе…ҘеҲ° Cassandra йӣҶзҫӨдёӯгҖӮдёәдәҶйҒҝе…ҚйӣҶзҫӨиҝҮиҪҪпјҢжҲ‘们д»Ҙ 10 з§’дёәе‘Ёжңҹжү№йҮҸеҶҷе…ҘгҖӮ
дёӢеӣҫжҳҜдәӢ件жөҒзҡ„еӨ§иҮҙжөҒзЁӢпјҡ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№RedditдёӯжҖҺд№Ҳз»ҹи®ЎжҜҸдёӘеё–еӯҗзҡ„жөҸи§ҲйҮҸжңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ





