今天就跟大家聊聊有关如何部署Spark集群,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
1. 安装环境简介
硬件环境:两台四核cpu、4G内存、500G硬盘的虚拟机。
软件环境:64位Ubuntu12.04 LTS;主机名分别为spark1、spark2,IP地址分别为1**.1*.**.***/***。JDK版本为1.7。集群上已经成功部署了Hadoop2.2,详细的部署过程可以参见另一篇文档Yarn的安装与部署。
2. 安装Scala2.9.3
1)在/home/test/spark目录下面运行wget http://www.scala-lang.org/downloads/distrib/files/scala-2.9.3.tgz命令,下载scala的二进制包。
2) 解压下载后的文件,配置环境变量:编辑/etc/profile文件,添加如下内容:
export SCALA_HOME=/home/test/spark/scala/scala-2.9.3 export PATH=$SCALA_HOME/bin3)运行source /etc/profile使环境变量的修改立即生效。在spark2上执行相同的操作,安装scala。
3. 下载编译好的spark文件,地址为:http://d3kbcqa49mib13.cloudfront.net/spark-0.8.1-incubating-bin-hadoop2.tgz。下载后解压。
4.配置conf/spark-env.sh环境变量,添加如下内容:
export SCALA_HOME=/home/test/spark/scala/scala-2.9.35. 在/etc/profile中配置SPARK_EXAMPLES_JAR以及spark的环境变量:添加如下内容:
export SPRAK_EXAMPLES_JAR=/home/test/spark/spark-0.8.1-incubating-bin-hadoop2/examples/target/scala-2.9.3/spark-examples_2.9.3-assembly-0.8.1-incubating.jar export SPARK_HOME=/home/test/spark/spark-0.8.1-incubating-bin-hadoop2 export PATH=$SPARK_HOME/bin6. 修改/conf/slaves文件,在文件中添加如下内容:
spark1 spark2
7.使用scp命令将上述文件拷贝到spark节点的相同路径下面scp -rspark-0.8.1-incubating-bin-hadoop2 test@spark2:/home/test/spark:
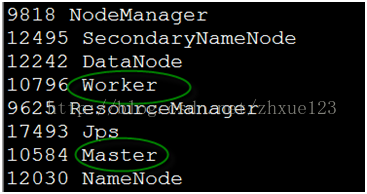
8. 在spark1上启动spark集群,并检查进程是否成功启动。如下master和worker已经成功启动。
使用浏览器打开http://1**.**.*.***:8080/,其显示如下所示:
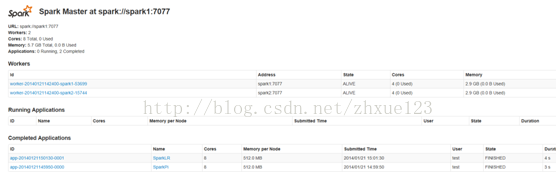
可以看到集群中的两个slave节点已经成功启动。
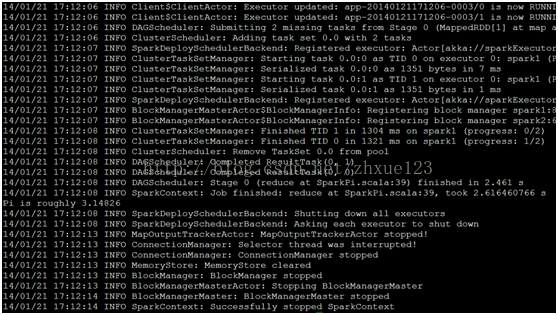
9. 运行spark自带的例子:./run-exampleorg.apache.spark.examples.SparkPi spark://master:7077,其结果如下所示:
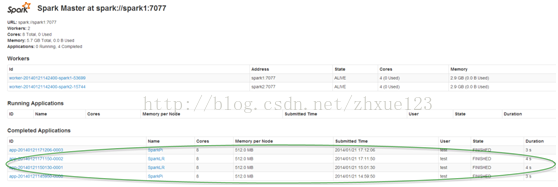
在web界面能看到刚才运行的job如下所示:
看完上述内容,你们对如何部署Spark集群有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



