这篇文章主要讲解了“如何使用Nginx做页面采集”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何使用Nginx做页面采集”吧!
模拟线上的实时流,比如用户的操作日志,采集到数据后,进行处理,暂时只考虑数据的采集,使用Html+Jquery+Nginx+Ngx_kafka_module+Kafka来实现,其中Ngx_kafka_module 是开源的专门用来对接Nginx和Kafka的一个组件。
html和jquery 模拟用户请求日志其中包括下面下面几项:
用户id:user_id, 访问时间:act_time, 操作: (action,包括click,job_collect,cv_send,cv_upload)
企业编码job_code
由于使用现成的已安装好的docker-kafka镜像,所以直接启动即可.
$ cd /usr/local/src $ git clone git@github.com:edenhill/librdkafka.git # 进入到librdkafka,然后进行编译 $ cd librdkafka $ yum install -y gcc gcc-c++ pcre-devel zlib-devel $ ./configure $ make && make install $ yum -y install make zlib-devel gcc-c++ libtool openssl openssl-devel $ cd /opt/hoult/software # 1.下载 $ wget http://nginx.org/download/nginx-1.18.0.tar.gz # 2.解压 $ tar -zxf nginx-1.18.0.tar.gz -C /opt/hoult/servers # 3. 下载模块源码 $ cd /opt/hoult/software $ git clone git@github.com:brg-liuwei/ngx_kafka_module.git # 4. 编译 $ cd /opt/hoult/servers/nginx-1.18.0 $ ./configure --add-module=/opt/hoult/software/ngx_kafka_module/ $ make && make install # 5.删除Nginx安装包 $ rm /opt/hoult/software/nginx-1.18.0.tar.gz # 6.启动nginx $ cd /opt/hoult/servers/nginx-1.18.0 $ nginx
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
kafka;
kafka_broker_list linux121:9092;
server {
listen 9090;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
#------------kafka相关配置开始------------
location = /kafka/log {
#跨域相关配置
add_header 'Access-Control-Allow-Origin' $http_origin;
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
kafka_topic tp_individual;
}
#error_page 404 /404.html;
}
}# 创建topic kafka-topics.sh --zookeeper linux121:2181/myKafka --create --topic tp_individual --partitions 1 --replication-factor 1 # 创建消费者 kafka-console-consumer.sh --bootstrap-server linux121:9092 --topic tp_individual --from-beginning # 创建生产者测试 kafka-console-producer.sh --broker-list linux121:9092 --topic tp_individual
<!DOCTYPE html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1,shrink-to-fit=no"> <title>index</title> <!-- jquery cdn, 可换其他 --> <script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.5.1/jquery.js"></script> </head> <body> <input id="click" type="button" value="点击" onclick="operate('click')" /> <input id="collect" type="button" value="收藏" onclick="operate('job_collect')" /> <input id="send" type="button" value="投简历" onclick="operate('cv_send')" /> <input id="upload" type="button" value="上传简历" onclick="operate('cv_upload')" /> </body> <script> function operate(action) { var json = {'user_id': 'u_donald', 'act_time': current().toString(), 'action': action, 'job_code': 'donald'}; $.ajax({ url:"http://linux121:8437/kafka/log", type:"POST" , crossDomain: true, data: JSON.stringify(json), // 下面这句话允许跨域的cookie访问 xhrFields: { withCredentials: true }, success:function (data, status, xhr) { // console.log("操作成功:'" + action) }, error:function (err) { // console.log(err.responseText); } }); }; function current() { var d = new Date(), str = ''; str += d.getFullYear() + '-'; str += d.getMonth() + 1 + '-'; str += d.getDate() + ' '; str += d.getHours() + ':'; str += d.getMinutes() + ':'; str += d.getSeconds(); return str; } </script> </html>
将a.html 放在nginx的目录下,浏览器访问192.168.18.128:9090
4.1 首先启动zk集群,kafka集群
4.2 然后创建topic, 创建消费者,创建生产者,测试topic
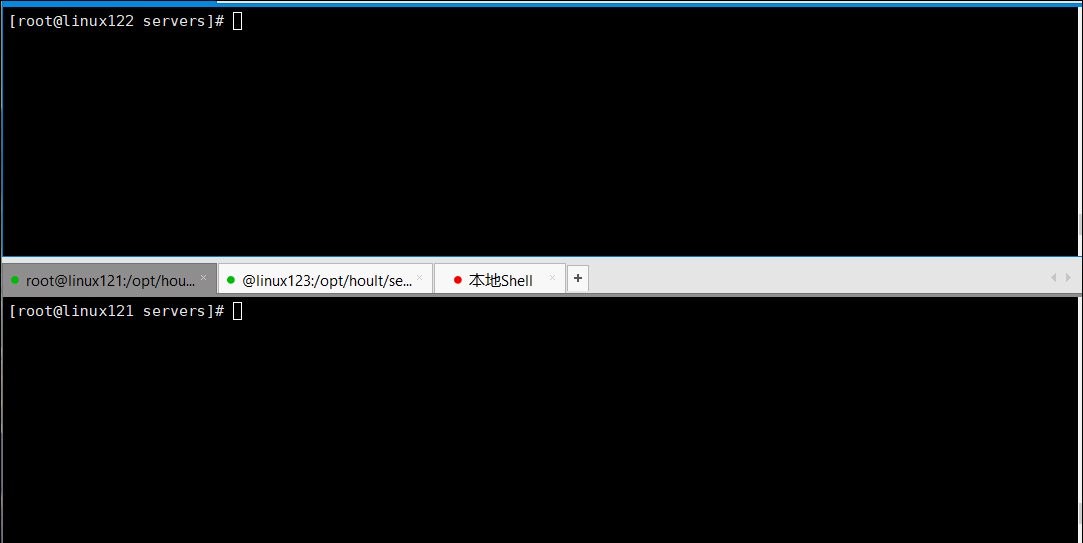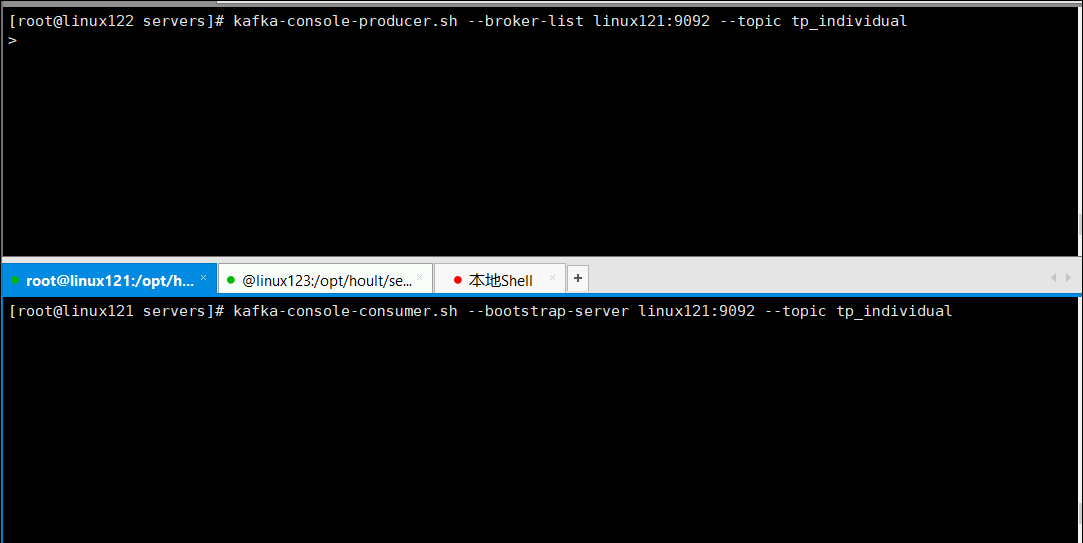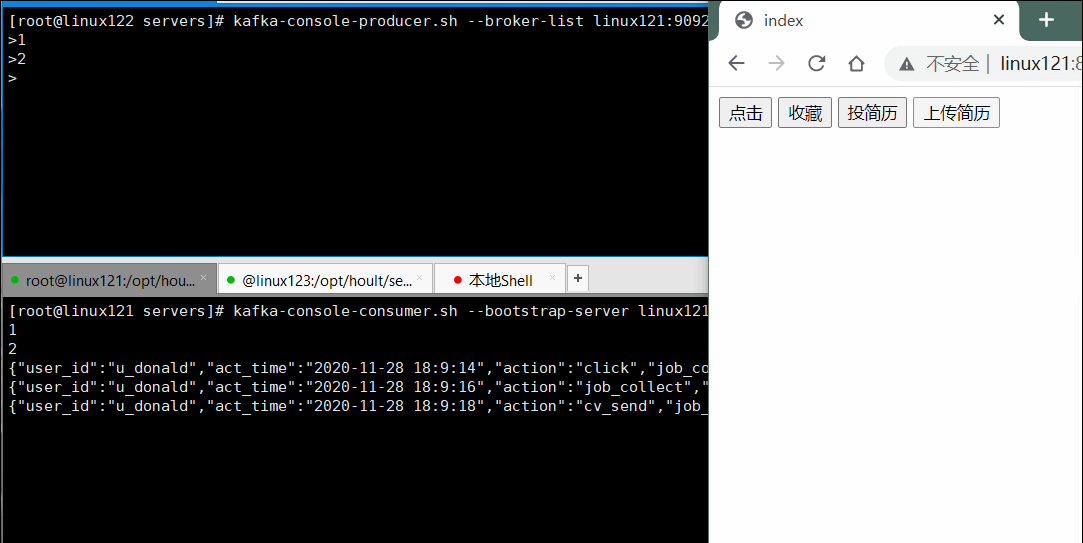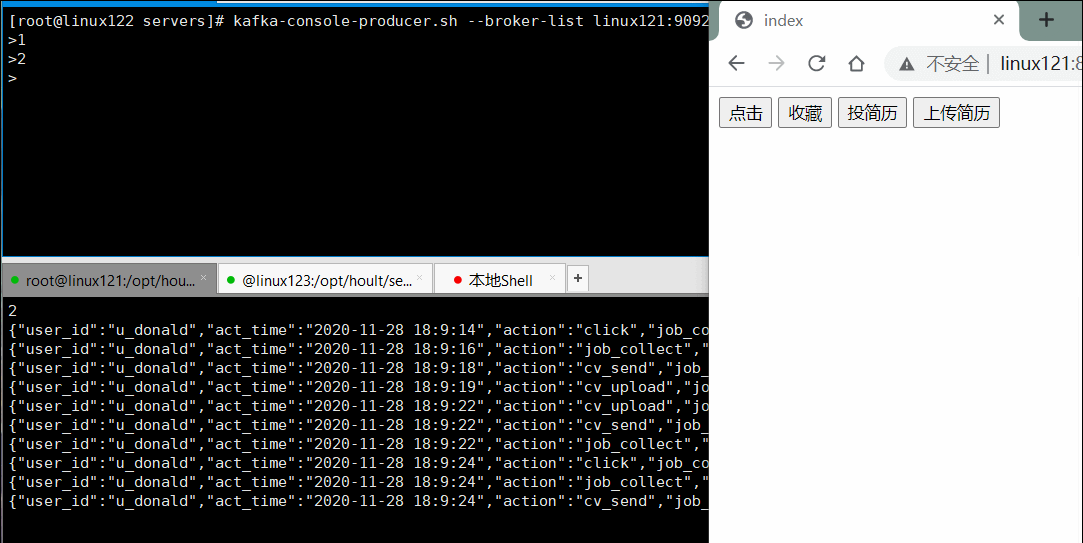
4.3 启动nginx访问页面,进行点击,观察消费者状态
整个过程如下图:
感谢各位的阅读,以上就是“如何使用Nginx做页面采集”的内容了,经过本文的学习后,相信大家对如何使用Nginx做页面采集这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





