本篇文章为大家展示了怎么彻底搞懂Kafka消息大小相关参数设置的规则,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
前段时间接到用户要求,调整某个主题在 Kafka 集群消息大小为 4M。
根据 Kafka 消息大小规则设定,生产端自行将 max.request.size 调整为 4M 大小,Kafka 集群为该主题设置主题级别参数 max.message.bytes 的大小为 4M。
以上是针对 Kafka 2.2.x 版本的设置,需要注意的是,在某些旧版本当中,还需要调整相关关联参数,比如 replica.fetch.max.bytes 等。
从上面例子可看出,Kafka 消息大小的设置还是挺复杂的一件事,而且还分版本,需要注意的参数巨多,而且每个都长得差不多,不但分版本,还需要注意生产端、broker、消费端的设置,而且还要区分 broker 级别还是 topic 级别的设置,而且还需要清楚知道每个配置的含义。
下面通过相关参数的解析说明,再结合实战测试,帮助你快速搞明白这些参数的含义以及规则。
broker 关于消息体大小相关的参数主要有 message.max.bytes、replica.fetch.min.bytes、replica.fetch.max.bytes、replica.fetch.response.max.bytes
1、message.max.bytes
Kafka 允许的最大 record batch size,什么是 record batch size ?简单来说就是 Kafka 的消息集合批次,一个批次当中会包含多条消息,生产者中有个参数 batch.size,指的是生产者可以进行消息批次发送,提高吞吐量,以下是 message.max.bytes 参数作用的源码:
kafka.log.Log#analyzeAndValidateRecords

以上源码可以看出 message.max.bytes 并不是限制消息体大小的,而是限制一个批次的消息大小,所以我们需要注意生产端对于 batch.size 的参数设置需要小于 message.max.bytes。
以下附带 Kafka 官方解释:
The largest record batch size allowed by Kafka. If this is increased and there are consumers older than 0.10.2, the consumers' fetch size must also be increased so that the they can fetch record batches this large.
In the latest message format version, records are always grouped into batches for efficiency. In previous message format versions, uncompressed records are not grouped into batches and this limit only applies to a single record in that case.
This can be set per topic with the topic level
max.message.bytesconfig.
翻译如下:
Kafka 允许的最大记录批量。 如果增加此数量,并且有一些消费者的年龄大于 0.10.2,则消费者的获取大小也必须增加,以便他们可以获取如此大的记录批次。
在最新的消息格式版本中,为了提高效率,始终将记录分组。 在以前的消息格式版本中,未压缩的记录不会分组,并且在这种情况下,此限制仅适用于单个记录。
可以使用主题级别 “max.message.bytes” 配置针对每个主题进行设置。
2、replica.fetch.min.bytes、replica.fetch.max.bytes、replica.fetch.response.max.bytes
kafka 的分区如果是多副本,那么 follower 副本就会源源不断地从 leader 副本拉取消息进行复制,这里也会有相关参数对消息大小进行设置,其中 replica.fetch.max.bytes 是限制拉取分区中消息的大小,在 0.8.2 以前的版本中,如果 replica.fetch.max.bytes < message.max.bytes,就会造成 follower 副本复制不了消息。不过在后面的版本当中,已经对这个问题进行了修复。
replica.fetch.max.bytes 参见 2.2.x 版本的官方解释:
The number of bytes of messages to attempt to fetch for each partition. This is not an absolute maximum, if the first record batch in the first non-empty partition of the fetch is larger than this value, the record batch will still be returned to ensure that progress can be made. The maximum record batch size accepted by the broker is defined via message.max.bytes (broker config) or max.message.bytes (topic config).
翻译如下:
尝试为每个分区获取的消息的字节数。 这不是绝对最大值,如果获取的第一个非空分区中的第一个记录批处理大于此值,那么仍将返回记录批处理以确保进度。 代理接受的最大记录批处理大小是通过 message.max.bytes(代理配置)或 max.message.bytes(主题配置)定义的。
replica.fetch.min.bytes、replica.fetch.response.max.bytes 同理。
1、max.message.bytes
该参数跟 message.max.bytes 参数的作用是一样的,只不过 max.message.bytes 是作用于某个 topic,而 message.max.bytes 是作用于全局。
1、max.request.size
该参数挺有意思的,看了 Kafka 生产端发送相关源码后,发现消息在 append 到 RecordAccumulator 之前,会校验该消息是否大于 max.request.size,具体逻辑如下:
org.apache.kafka.clients.producer.KafkaProducer#ensureValidRecordSize
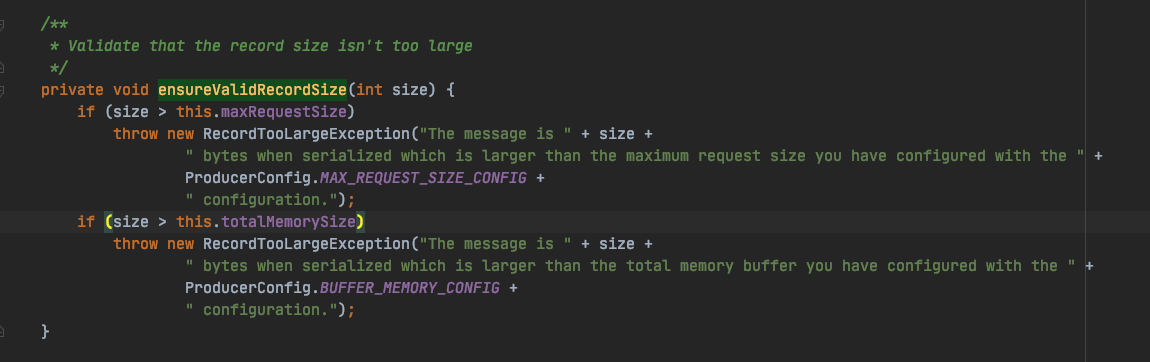
从以上源码得出结论,Kafka 会首先判断本次消息大小是否大于 maxRequestSize,如果本次消息大小 maxRequestSize,则直接抛出异常,不会继续执行追加消息到 batch。
并且还会在 Sender 线程发送数据到 broker 之前,会使用 max.request.size 限制发送请求数据的大小:
org.apache.kafka.clients.producer.internals.Sender#sendProducerData
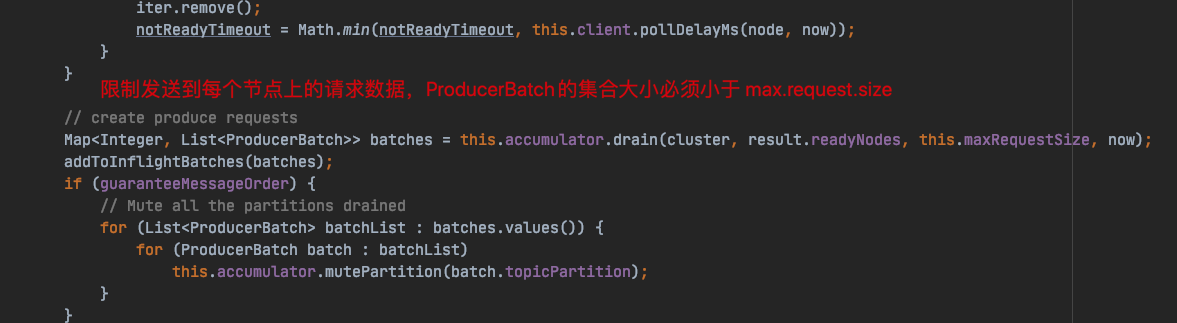
也就是说,max.request.size 参数具备两个特性:
1)限制单条消息大小
2)限制发送请求大小
参见 2.2.x 版本的官方解释:
The maximum size of a request in bytes. This setting will limit the number of record batches the producer will send in a single request to avoid sending huge requests. This is also effectively a cap on the maximum record batch size. Note that the server has its own cap on record batch size which may be different from this.
翻译如下:
请求的最大大小(以字节为单位)。 此设置将限制生产者将在单个请求中发送的记录批数,以避免发送大量请求。 这实际上也是最大记录批次大小的上限。 请注意,服务器对记录批大小有自己的上限,该上限可能与此不同。
2、batch.size
batch.size 是 Kafka producer 非常重要的参数,它的值对 Producer 的吞吐量有着非常大的影响,因为我们知道,收集到一批消息再发送到 broker,比每条消息都请求一次 broker,性能会有显著的提高,但 batch.size 设置得非常大又会给机器内存带来极大的压力,因此需要在项目中合理地增减 batch.size 值,才能提高 producer 的吞吐量。
org.apache.kafka.clients.producer.internals.RecordAccumulator#append
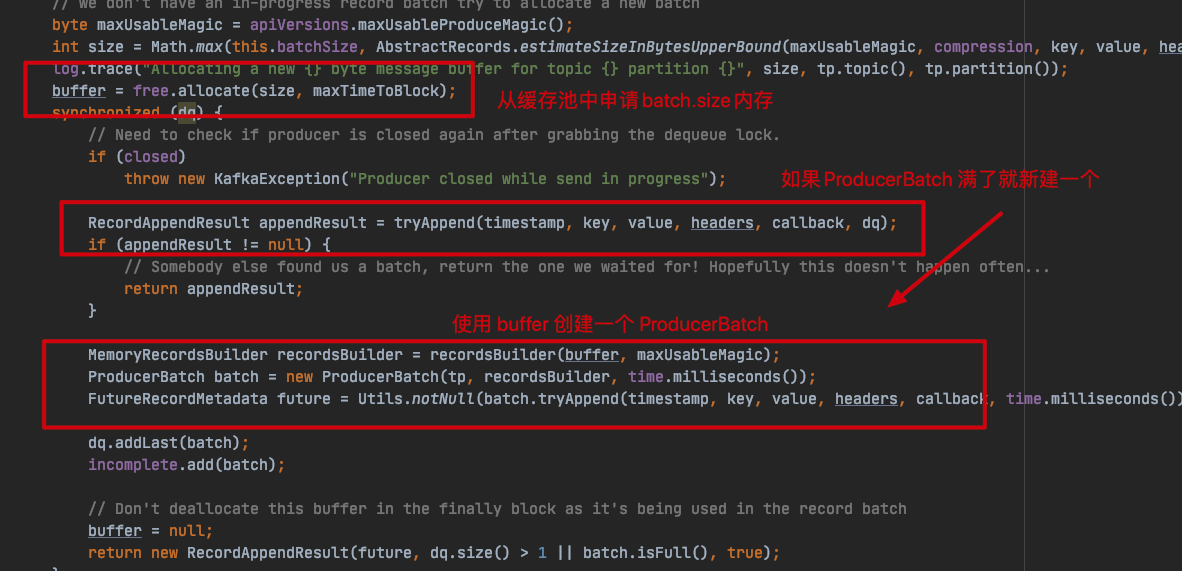
以上,将消息追加到消息缓冲区时,会尝试追加到一个 ProducerBatch,如果 ProducerBatch 满了,就去缓存区申请 batch.size 大小的缓存创建一个新的 ProducerBatch 继续追加消息。需要注意的是,如果消息大小本身就比 batch.size 大,这种情况每个 ProducerBatch 只会包含一条消息。
最终 RecordAccumulator 缓存区看起来是这样的:
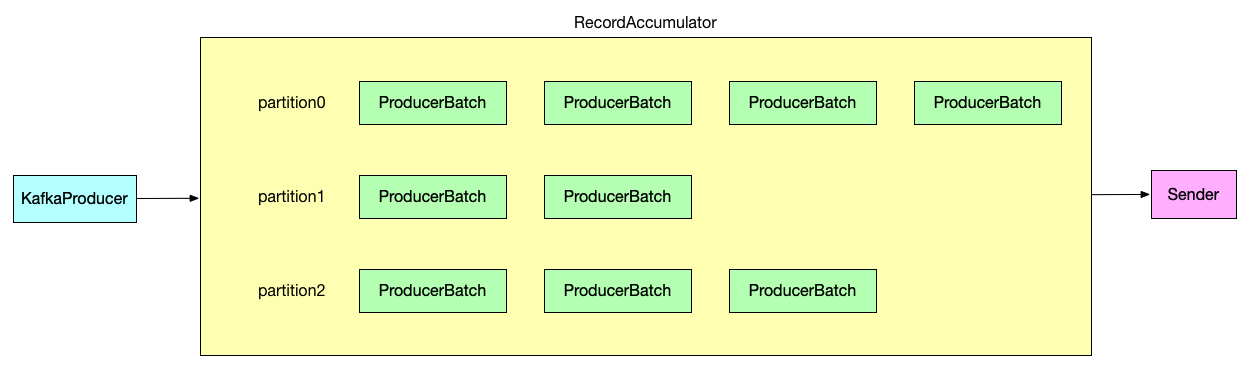
参见 2.2.x 版本的官方解释:
The producer will attempt to batch records together into fewer requests whenever multiple records are being sent to the same partition. This helps performance on both the client and the server. This configuration controls the default batch size in bytes.
No attempt will be made to batch records larger than this size.
Requests sent to brokers will contain multiple batches, one for each partition with data available to be sent.
A small batch size will make batching less common and may reduce throughput (a batch size of zero will disable batching entirely). A very large batch size may use memory a bit more wastefully as we will always allocate a buffer of the specified batch size in anticipation of additional records.
翻译如下:
每当将多个记录发送到同一分区时,生产者将尝试将记录一起批处理成更少的请求。 这有助于提高客户端和服务器的性能。 此配置控制默认的批处理大小(以字节为单位)。
不会尝试批处理大于此大小的记录。
发送给代理的请求将包含多个批次,每个分区一个,并包含可发送的数据。
较小的批处理量将使批处理变得不那么普遍,并且可能会降低吞吐量(零的批处理量将完全禁用批处理)。 非常大的批处理大小可能会浪费一些内存,因为我们总是在预期其他记录时分配指定批处理大小的缓冲区。
那么针对 max.request.size 、batch.size 之间大小的调优就尤其重要,通常来说,max.request.size 大于 batch.size,这样每次发送消息通常会包含多个 ProducerBatch。
1、fetch.min.bytes、fetch.max.bytes、max.partition.fetch.bytes
1)fetch.max.bytes
参见 2.2.x 版本的官方解释:
The maximum amount of data the server should return for a fetch request. Records are fetched in batches by the consumer, and if the first record batch in the first non-empty partition of the fetch is larger than this value, the record batch will still be returned to ensure that the consumer can make progress. As such, this is not a absolute maximum. The maximum record batch size accepted by the broker is defined via
message.max.bytes(broker config) ormax.message.bytes(topic config). Note that the consumer performs multiple fetches in parallel.
翻译如下:
服务器为获取请求应返回的最大数据量。 使用者将批量获取记录,并且如果获取的第一个非空分区中的第一个记录批次大于此值,则仍将返回记录批次以确保使用者可以取得进展。 因此,这不是绝对最大值。 代理可接受的最大记录批处理大小是通过“ message.max.bytes”(代理配置)或“ max.message.bytes”(主题配置)定义的。 请注意,使用者并行执行多个提取。
fetch.min.bytes、max.partition.fetch.bytes 同理。
针对以上相关参数配置的解读,还需要对 max.request.size、batch.size、message.max.bytes(或者 max.message.bytes)三个参数进一步验证。
1、测试消息大于 max.request.size 是否会被拦截
设置:
max.request.size = 1000, record-size = 2000
使用 kafka-producer-perf-test.sh 脚本测试:
$ {kafka_path}/bin/kafka-producer-perf-test.sh --topic test-topic2 --num-records 500000000000 --record-size 20000 --throughput 1 --producer-props bootstrap.servers=localhost:9092,localhost:9093,localhost:9094 acks=-1 max.request.size=1000测试结果:

可以得出结论,成功拦截了大于 max.request.size 的消息。
2、测试 max.message.bytes 参数用于校验批次大小还是校验消息大小
设置:
record-size = 500 batch.size = 2000 linger.ms = 1000 max.message.bytes = 1000 // 在控制台调整主题级别配置即可
使用 kafka-producer-perf-test.sh 脚本测试:
$ {kafka_path}/bin/kafka-producer-perf-test.sh --topic test-topic1 --num-records 500000000000 --record-size 500 --throughput 5 --producer-props bootstrap.servers=localhost:9092,localhost:9093,localhost:9094 acks=-1 batch.size=2000 linger.ms=1000测试结果:
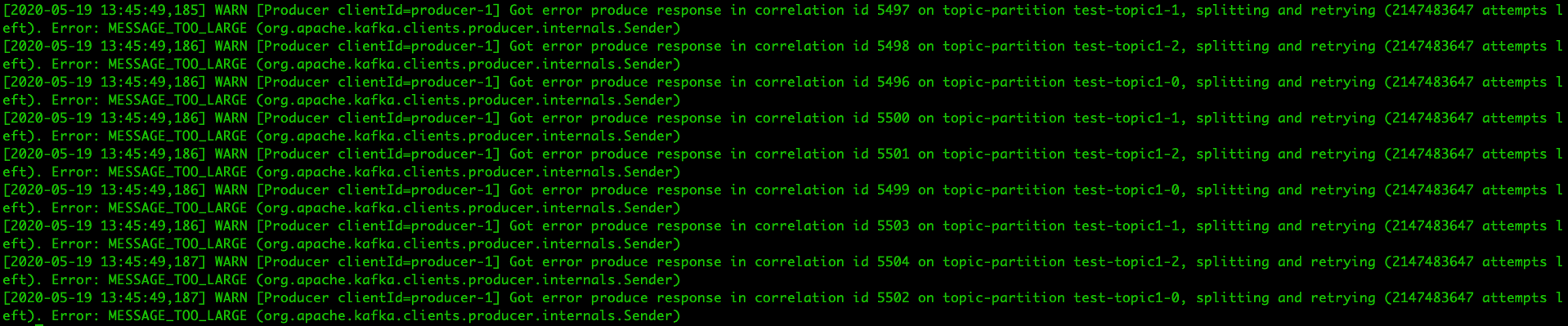
当 max.message.bytes = 2500 时:

可以得出结论,max.message.bytes 参数校验的是批次大小,而不是消息大小。
3、测试消息大小比 batch.size 还大的情况下,是否还会发送消息,当 max.message.bytes 参数小于消息大小时,是否会报错
record-size = 1000 batch.size = 500 linger.ms = 1000
使用 kafka-producer-perf-test.sh 脚本测试:
$ {kafka_path}/bin/kafka-producer-perf-test.sh --topic test-topic1 --num-records 500000000000 --record-size 1000 --throughput 5 --producer-props bootstrap.servers=localhost:9092,localhost:9093,localhost:9094 acks=-1 batch.size=500 linger.ms=1000测试结果:

可以得出结论,即使消息大小比 batch.size 还大,依然会继续发送消息。
当 max.message.bytes = 900 时:

可以得出结论,即使 batch.size < max.message.bytes,但由于消息大小比 batch.size 大的情况下依然会发送消息,如果没有 max.request.size 参数控制消息大小的话,就有可能会报错。
这也说明了文章开头为什么直接修改 max.request.size 和 max.message.bytes 即可,而不需要调整 batch.size 的原因。
上述内容就是怎么彻底搞懂Kafka消息大小相关参数设置的规则,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





