用于生成文本到图像的新框架TReCS是怎么样的,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。

基于生成对抗网络(GAN)的深度神经网络促进了端到端可训练的照片级逼真的文本到图像的生成。许多方法还使用中间场景图表示法来改善图像合成。使用基于对话的交互的方法允许用户提供指令,以逐步改进和调整生成的场景。通过指定背景中对象的相对位置,可以为用户提供更好的控制。但是上述方法中使用的语言受到限制,并且生成的图像仅限于合成3D可视化效果或卡通。
为了创建能够在任何语言对之间进行翻译的通用神经机器翻译系统,一组Google研究人员开发了一种新的框架,即标签检索,合成综合系统(TReCS)。所提出的方法通过改进语言唤起图像元素的方式以及迹线如何通知其位置,从而显着增强了图像生成过程。该系统接受了超过250亿个示例的训练,具有处理103种语言的潜力。其功能使鼠标轨迹与文本描述对齐,并为提供的短语创建可视标签。
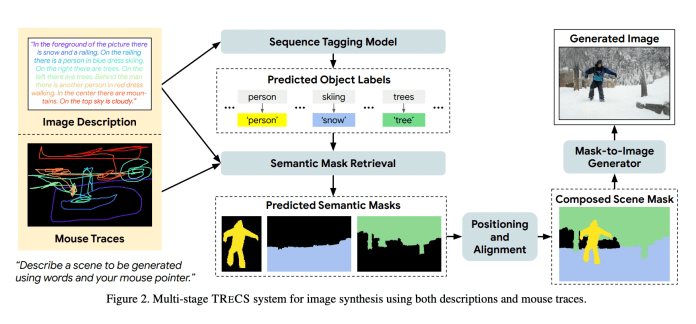
新框架利用可控的鼠标轨迹作为细粒度的视觉基础,根据用户的叙述生成高质量的图像。标记器用于预测短语中每个单词的对象标签。
文本到图像的双重编码器使用语义相关的掩码检索图像。对于每个迹线序列,选择一个遮罩以最大化空间重叠,从而克服了真实的文本到对象信息和更好的地面描述。
选定的蒙版根据跟踪顺序组成,并为背景和前景对象使用单独的画布。将前景蒙版放置在背景蒙版上以创建完整的场景分割。
最后,通过将整个分割输入到蒙版到图像的转换模型中来合成逼真的图像。
在评估方面,新系统在自动和人工判断下均优于SOTA文本图像生成技术。它显示了从日常演讲中翻译的嘈杂叙事中的复杂文本生成逼真的可控照片的可行性。TReCS系统解决了冗长而复杂的文本描述生成文本图像的复杂性。所提出的方法表明,鼠标跟踪可以成为生成实际文本图像的有用来源。
局限性:
该研究的局限性之一是缺乏合适的评估指标来定量测量生成的图像的质量。现有的度量标准不能合理地反映出真实图像与机器生成的图像之间的语义相似性。
在未来几年中,提出的想法可以支持提供友好的人机界面的各种应用程序。它可以帮助艺术家创建原型,从机器生成的照片中汲取见解并生成逼真的图像。此外,它还可用于设计人在环评估系统以优化网络。
看完上述内容,你们掌握用于生成文本到图像的新框架TReCS是怎么样的的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3267804/blog/4942006



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



