这篇文章主要为大家分析了如何进行mAP计算的思考的相关知识点,内容详细易懂,操作细节合理,具有一定参考价值。如果感兴趣的话,不妨跟着跟随小编一起来看看,下面跟着小编一起深入学习“如何进行mAP计算的思考”的知识吧。
从直观理解,一个目标检测网络性能好,主要有以下表现:
把画面中的目标都检测到——漏检少
背景不被检测为目标——误检少
目标类别符合实际——分类准
目标框与物体的边缘贴合度高—— 定位准
满足运行效率的要求——算得快
下图是从 Tensorflow Object Detection API 的 Model Zoo 中截取的部分模型列表。
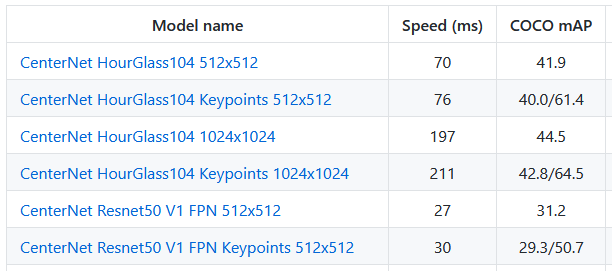
算得快这一点通过 Speed 来体现。而其他因素,使用了mAP (mean average Precision) 这一个指标来综合体现。
mean 和 average 都有平均的意思,因此从字面理解,mAP 指标至少从两个方面进行了平均。
mAP 的计算大致可以分解为以下几步:
| 阶段 | 输出 | 关键变量 |
|---|---|---|
| 针对单个目标 | TP、FP、FN | IOU(交并比) |
| 针对单个类别 | PR-Curve、AP | Confidence(置信度) |
| 针对测试集全集 | mAP |
针对不同类型的目标检测网络,模型推理的原始输出可能的形式多种多样。
首先需要完成目标解码,生成标准化的目标列表,至少包含每个目标的:
类别
2DBBox
置信度
这里的置信度与推理使用时的置信度阈值有差别,没有固定的阈值,只要在该通道有响应,都输出为目标。
不同类型的网络,置信度数值的含义也不同,因此也无法设定一个统一的阈值。
针对单个目标,问题简化为分类结果的判定。
首先将 GT (Ground Truth) 和 Predictions 分别按照各自的类别分组。
在每一个类别内,对 GT 和 Predictions 两组数据进行匹配,匹配的依据是 IOU。
匹配结果可能有如下几种:
TP (True Positive):一个正确的检测,IOU ≥ threshold。即预测的目标分类正确,且边框与 GT 重合度够高。
FP (False Positive):一个错误的检测,没有匹配上 GT 的目标,或IOU < threshold。即预测的目标分类不正确,或边框与 GT 重合度不够高。
FN (False Negative):漏检的 GT。即没有被匹配上目标的 Ground Truth。
完成对整个测试集上每个目标的判断后,分类别统计 Precision 和 Recall:
Precision:准确率(查准率),模型只找正确目标的能力。
Precision = TP / (TP + FP),其中 TP+FP 即模型找到的所有目标。
Recall:召回率(查全率),模型找到所有目标的能力。
Recall = TP / (TP + FN),其中 TP+FN 即所有的 GT。
在单个目标的处理步骤中,只需要记录TP。则对于所有检测目标,非TP即为FP,对于所有 GT,非TP即为FN。
当设定不同的 Confidence 阈值时,输出的检测目标数量不同,由此计算得到的 Precision 和 Recall 也不同。
根据不同的阈值,可以得到一系列 Precision 和 Recall 的值,连起来即可得到PR曲线。
在实际操作中,将所有目标按照置信度从高到低排序,每一步都只累加一个目标,统计当前的P-R值。
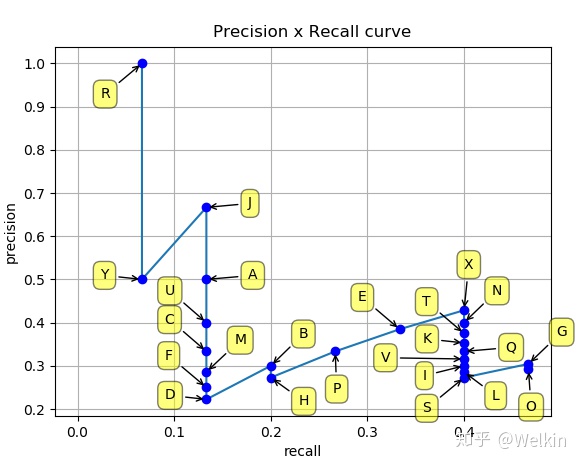
PR曲线示例如上图所示。
PR曲线会有折线的原因。每累加一步,如果:
当前累加的目标是FP,则 Recall 值不变, Precision 值变小,对应图中竖直向下的线段;
当前累加的目标是TP,则 Recall 和 Precision 都变大,对应图中斜向右上方的线段。
至此,针对每一个类别,都计算得到一条PR曲线。
PR曲线与x轴所围成的面积,即为当前类别的AP值。
Average 是指对不同 Confidence 阈值下的结果进行平均。
所有类别AP值的均值,即为 mAP。
mean 是指对不同类别之间结果进行平均。
(1)误检/漏检少、分类准、定位准,这些要求并没有在 mAP 的整个计算过程中一直传导到最终结果。
首先按照目标类别进行分类处理。
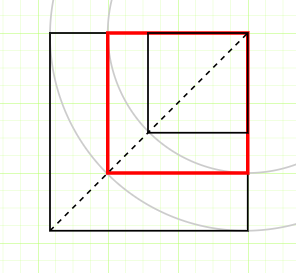
在对单个目标的处理中,将IOU作为匹配的指标,将检测到的目标二分类为TP/FP。在选定IOU阈值后,TP/FP的分配也就确定了。在后续的步骤中,目标被抽象为正确/错误两类,但正确或错误的程度被忽略了。
下图为 IOU=0.5 时的极限情况示意:
类似的IOU值实际可能代表的不同情况:
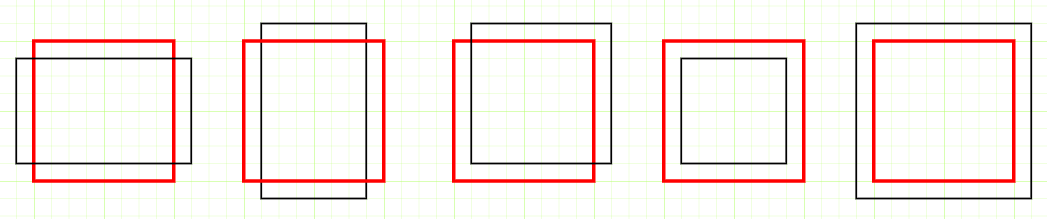
在对所有目标的处理中,主要考察不同的 Confidence 阈值下,检测出正确目标的能力。
因此,误检/漏检少、分类准、定位准这几个要求是按照一种串行的方式,分阶段组织起来的。
(2)问题是多样化的,只用一个指标,没法知道目前的性能瓶颈在哪里。
根据 mAP 的高低,我们只能较为概括地知道网络整体性能的好坏,但比较难分析问题具体在哪。
举几个例子:
如果网络输出的框很贴合,选择合适的 Confidence 阈值时,检出和召回也较均衡,但是目标的类别判断错误较多。由于首先根据类别结果分类处理,只要类别错了,定位、检出和召回都很好,mAP 指标也不会高。但从结果观察,并不能很明确知道,问题出在类别判断上。
比如 Faster-RCNN 系列网络,如果 RPN 部分效果很好,但是 RCNN 部分效果很差,只根据 mAP, 是无法判断出来的。
如果两个网络的其他性能表现都类似,但是输出框的定位精度不同。对于大部分判定为 TP 的目标,一个网络的目标 IOU 值很高,框非常贴合 GT;另一个网络的目标 IOU 值刚刚超过阈值。理论上这样两个网络计算出来的 mAP 值是类似的,但实际使用的表现是有差别的。
(3)mAP 指标关注的点,与实际应用时关注的点,并不完全吻合
mAP 会统计所有 Confidence 值下的 PR值,而实际使用时,会设定一个 Confidence 阈值,低于该阈值的目标会被丢弃,这部分目标在统计 mAP 时也会有一定的贡献。部分针对比赛刷榜的涨点技巧,会关注这部分检测结果对 mAP 的影响。
此外,在 ADAS 应用(特别是车辆检测)中一些比较关心的点,mAP 指标并没有很好地体现。比如:
最关心正前方近处的目标,对远处侧面的目标关注度相对低
关注目标框的下沿和宽度,而对上沿的要求不高
关注连续帧中,同一个目标检测结果的稳定性和连续性
不同的类别错判,严重程度不同(比如卡车误判为客车问题不大,行人误判为车辆问题就比较大)
(1)考察不同 IOU 阈值下的性能表现
在 VOC 标准的 mAP 计算中,只取 IOU=0.5 一个阈值。
MS-COCO 标准对此进行了改进,取0.5:0.05:0.95等间隔的11个阈值,分别统计:
AP:在所有11个 IOU 阈值上计算出来的 mAP 的均值(最主要的度量指标)
AP@.5IOU:阈值取0.5时的 mAP 值(等价于 VOC mAP)
AP@.75IOU:阈值取0.75时的 mAP 值
此外还针对目标大小分别进行了统计:
AP(small):像素面积小于32^2的目标,在所有11个 IOU 阈值上的AP
AP(medium):像素面积介于32^2和96^2之间的目标,在所有11个 IOU 阈值上的AP
AP(large):像素面积大于96^2的目标,在所有11个 IOU 阈值上的AP
此外,还有 AR (Average Recall) 相关的一系列指标。
可见, COCO mAP 对检测性能进行了更全面的评估,改进了单一 IOU 阈值的问题。
COCO mAP 的计算可以直接使用
pycocotools,将检测结果按照规定的格式提供,即可自动完成计算。
(2)统一训练和评测的指标
在网络训练过程中,location 分支的输出通常会用IOU Loss去进行优化,目前已经升级到DIOU或CIOU。
那么在测试过程中,也可以将 IOU 指标替换为类似 DIOU 或 CIOU 的版本,实现更合理的评价,以及训练和评测的统一。
(3)设计更多自定义的指标
mAP 是一个基准指标,属于规定动作,可以用来比较不同网络,包括与开源模型、外部团队开发的模型等进行比较。
此外,基于我们关心的模型性能表现,可以设计一些额外的指标。包括:
mAP 计算过程中,可拆分出来的的一些中间指标
mAP 没有涵盖到的指标
(4)模型使用时的阈值选择
使用模型进行推理时,在目标解码过程中涉及 Confidence 阈值的选取。通常是采用一刀切的方式,选择一个统一的阈值。
在 mAP 的计算过程中,会输出每个类别的PR曲线。一个典型PR曲线的示意如下:

根据PR曲线,既可以找到一个数学意义上的最优点,也可以根据实际使用时,对于误检和漏检的不同容忍程度,选定一个权衡值。
可以根据每个类别的不同情况,选取不同的 Confidence 阈值,来让每一个类别的检测结果达到最优。
在实际操作中,可先根据 class 通道的结果,判定类别,再根据 conf 通道的结果和不同的阈值,筛选检出的目标。
对于类别性质差异较大,类别不均衡现象较为严重的案例,可以实现更理想的输出。
比如,在ADAS应用中,对于车辆目标、行人目标、交通标识目标的识别要求可能存在差异。根据各自的PR曲线去定制阈值,是一个更合理的选择。
关于“如何进行mAP计算的思考”就介绍到这了,更多相关内容可以搜索亿速云以前的文章,希望能够帮助大家答疑解惑,请多多支持亿速云网站!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





