本篇内容介绍了“Hadoop的ResourceManager怎么恢复”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
当ResourceManager 挂掉重启后,为了使之前的任务能够继续执行,而不是重新执行。势必需要yarn记录应用运行过程的状态。
运行状态可以存储在
ZooKeeper
FileSystem 比如hdfs
LevelDB
使用zookeeper做为状态存储的典型配置为
<property>
<description>Enable RM to recover state after starting. If true, then
yarn.resourcemanager.store.class must be specified</description>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<description>The class to use as the persistent store.</description>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<description>Comma separated list of Host:Port pairs. Each corresponds to a ZooKeeper server
(e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002") to be used by the RM for storing RM state.
This must be supplied when using org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
as the value for yarn.resourcemanager.store.class</description>
<name>hadoop.zk.address</name>
<value>127.0.0.1:2181</value>
</property>基于zookeeper实现active 和standby 的多个ResourceManager之间的自动故障切换。 active Resource Manager只能有一个,而standby 可以有多个
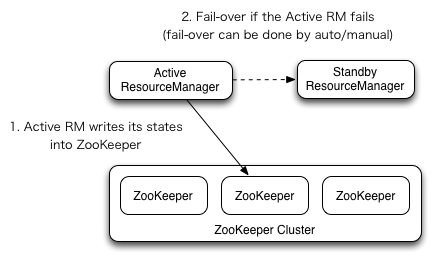
为了防止故障自动转移时的脑裂,推荐上面的ResourceManager recovery 状态存储使用也使用zk。 同时关闭zk的zookeeper.DigestAuthenticationProvider.superDigest配置,避免zk的管理员访问到YARN application/user credential information
一个demo配置如下
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>master2:8088</value>
</property>
<property>
<name>hadoop.zk.address</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
基于Label,将一个Yarn管理的集群,划分为多个分区。不同的queue可以使用不同的分区。
文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
对Node Manager定义一组属性值,使得应用程序能够基于这些属性值,来选择Node Mananger, 并将其应用的container部署到上面
文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeAttributes.html
集群中运行应用的application master 需要提供一些web ui给ResourceManager, 以便其统一管理。但集群中可能有恶意应用,提供了具有安全风险的web ui. 为了降低安全风险,yarn 使用一个名为Web Application Proxy的应用。拥有接管Application Master提供给的web ui链接,将请求中的cookies 进行剥离,同时将不安全的链接标记出来。
默认情况下Web Application Proxy 是作为Resource Manager的一部分启动。不需要单独配置。如果要单独部署,需要额外配置。 文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/WebApplicationProxy.html
能够存储和查询当前、历史的应用执行信息。TimeLine Server中的存储数据结构为
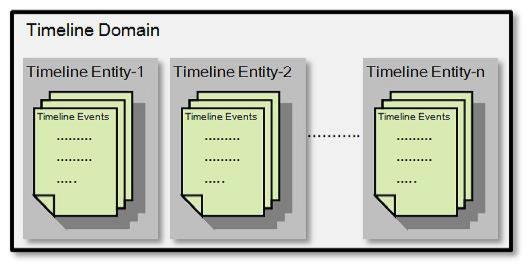
timeline Domain 对应一个用户的应用列表
Time Entity 定义一个应用
Timeline Events定义该应用的执行事件,比如应用启动,应用执行,应用结束等
Timeline Server分为V1和V2版本,V1版本将数据存储在levelDb中,v2版将数据存储在hbase中
文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/TimelineServer.html
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/WritingYarnApplications.html
yarn为了保证应用的运行安全,有一系列的机制先限制应用的权限之类的
文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YarnApplicationSecurity.html
前面说了ResourceMananger 需要重启后,能从原地继续执行任务。Node Mananger在挂掉重启后,也需要有相应的恢复特性。 其具体的配置,参见文档。
文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeManager.html
Node Mananger的健康检查服务,其提供两种健康检查器
Disk Checker 检查node manager的磁盘健康状况,并基于此上报给Resource Manager
External Health Script 管理员可以指定一些自定义的健康检查脚本,供Node Manager的 Health Checker Service调用
yarn使用linux的CGroups实现资源隔离和控制,相关配置见文档: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeManagerCgroups.html
将各应用container 限制在提交他的用户权限下,不同用户提交的应用container 不能访问彼此的文件、文件夹。具体配置 文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/SecureContainer.html
有两种方式:
normal 直接把要移除的节点从集群中摘除
Gracefully 等待节点上的任务执行完毕后摘除 文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html
yarn一般只在对应的Node manager有资源时,才会将一个任务对应的container 分配到该NM. 但开启Opportunistic Containers后,即便对应的node manager没有资源,也会将contaienr 分配到NM,等到NM空闲时,马上开始执行,是为机会主义者。这在一定程度能提高集群的资源利用率。 文档:
部署用户。按照Hadoop官方的建议。yarn相关组件,使用yarn用来管理 
启动RM
$HADOOP_HOME/bin/yarn --daemon start resourcemanager启动NM
$HADOOP_HOME/bin/yarn --daemon start nodemanager启动proxyServer
$HADOOP_HOME/bin/yarn --daemon start proxyserver切换到mapred用户下,启动historyserver
$HADOOP_HOME/bin/mapred --daemon start historyserveryarn本身由多个组件组成,且有些组件还有多个节点,比如nodemanager,一次启动去到多个机器上执行是件很繁琐的事情。hadoop发型包,提供了sbin/start-yarn.sh 和 sbin/stop-yarn.sh两个脚本去启停yarn相关的所有组件:比如nodemanager、resourcemanager、proxyserver 。
他实现的原理是,基于hadoop安装包中的/opt/hadoop-3.2.1/etc/hadoop/workers文件,去登录到相应的机器,完成组件的执行。workers中定义了所有datanode的机器host。 登录方式是基于SSH的免密登录方式,具体配置参见:https://www.cnblogs.com/niceshot/p/13019823.html
如果发起脚本执行的机器,本身也需要部署一个nodemanager。那么他需要配置自己对自己的SSH免密登录
通yarn-site.xml , 脚本已经可以知道resource manager的组件机器。所以workers文件中,只需要设置所有的node manager的机器host
一般yarn的node manager会跟hdfs的 datanode部署在一起,所以hdfs的批量启停,也是用的这个workers文件。
但上面说的$HADOOP_HOME/bin/mapred --daemon start historyserver不属于,只属于mapreduce,所以还是要单独启停,通过yarn的相关脚本是不能管理它的。之所以将这个historyserver放到yarn的文档中来写,是为了偷懒,没单独搞一个mr的wend
在yarn的管理界面,发现提交的sql,执行有以下错误
yarn错误
错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster问题原因是,yarn的类路径有问题。通过hadoop官方的yarn-default.xml文件得知,yarn加载的类路径配置yarn.application.classpath的默认值为
$HADOOP_CONF_DIR, $HADOOP_COMMON_HOME/share/hadoop/common/*, $HADOOP_COMMON_HOME/share/hadoop/common/lib/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*, $HADOOP_YARN_HOME/share/hadoop/yarn/*, $HADOOP_YARN_HOME/share/hadoop/yarn/lib/* For Windows: %HADOOP_CONF_DIR%, %HADOOP_COMMON_HOME%/share/hadoop/common/*, %HADOOP_COMMON_HOME%/share/hadoop/common/lib/*, %HADOOP_HDFS_HOME%/share/hadoop/hdfs/*, %HADOOP_HDFS_HOME%/share/hadoop/hdfs/lib/*, %HADOOP_YARN_HOME%/share/hadoop/yarn/*, %HADOOP_YARN_HOME%/share/hadoop/yarn/lib/*路径中的许多环境变量都没有配置。解决办法有2
将对应的环境变量配置上,以使yarn的默认配置能够正常加载上。推荐这种
使用hadoop classpath命令,看下hadoop使用的类路径都有哪些,将其拷贝出来,在yarn-site.xml中配置,举例
<property> <name>yarn.application.classpath</name> <value>/opt/hadoop-3.2.1/etc/hadoop:/opt/hadoop-3.2.1/share/hadoop/common/lib/*:/opt/hadoop-3.2.1/share/hadoop/common/*:/opt/hadoop-3.2.1/share/hadoop/hdfs:/opt/hadoop-3.2.1/share/hadoop/hdfs/lib/*:/opt/hadoop-3.2.1/share/hadoop/hdfs/*:/opt/hadoop-3.2.1/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.2.1/share/hadoop/mapreduce/*:/opt/hadoop-3.2.1/share/hadoop/yarn:/opt/hadoop-3.2.1/share/hadoop/yarn/lib/*:/opt/hadoop-3.2.1/share/hadoop/yarn/*</value> </property> ``` ### 错误2 通过historyserver, 在Mapreduce阶段,看到异常
org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not exist at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at原因,这是因为mr使用了mapreduce_shuffle辅助服务,但yarn没有配置。 解决办法,同样是修改yarn-site.xml,在其中加入以下配置
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>ontainer [pid=26153,containerID=container_e42_1594730232763_0121_02_000006] is running 598260224B beyond the 'VIRTUAL' memory limit. Current usage: 297.5 MB of 1 GB physical memory used; 2.7 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_e42_1594730232763_0121_02_000006 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE错误的意思是,yarn分配给container的虚拟内存,超过了限制。原因是,一个container使用的内存,除了物理内存,还可以使用操作系统的虚拟内存,也即硬盘。
container分为两种类型,map 和reduce。 决定map的container的物理内存大小为mapreduce.map.memory.mb 决定reduce的物理内存为mapreduce.reduce.memory.mb 决定map container所能申请的虚拟内存大小的公式是:mapreduce.map.memory.mb * yarn.nodemanager.vmem-pmem-ratio 决定reduce container所能申请的虚拟内存带下是公式是:mapreduce.reduce.memory.mb * yarn.nodemanager.vmem-pmem-ratio。
所以要解决虚拟内存超限有两个办法:
增大container的物理内存大小。即增大mapreduce.map.memory.mb 或 mapreduce.reduce.memory.mb
增大虚拟内存申请的比率yarn.nodemanager.vmem-pmem-ratio
“Hadoop的ResourceManager怎么恢复”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4852452/blog/5014962



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



