这篇文章主要介绍“大数据数据库HBase的集群安装部署方法”,在日常操作中,相信很多人在大数据数据库HBase的集群安装部署方法问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”大数据数据库HBase的集群安装部署方法”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
<font color=#999AAA >Hive的学习告一段落,接下来开始了解大数据主流NoSql数据库HBase,本文主要讲解HBase集群的安装部署,为后续Hbase学习作准备。</font>
<hr color=#000000 size=1">
漫画学习HBase----最易懂的Hbase架构原理解析
HBase基于Google的BigTable论文,是建立的==HDFS==之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的分布式数据库系统。
在需要==实时读写随机访问==超大规模数据集时,可以使用HBase。
==海量存储==
可以存储大批量的数据
==列式存储==
HBase表的数据是基于列族进行存储的,列族是在列的方向上的划分。
==极易扩展==
底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加datanode节点就可以了
可以通过增加服务器来对集群的存储进行扩容
==高并发==
支持高并发的读写请求
==稀疏==
稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
==数据的多版本==
HBase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳
==数据类型单一==
所有的数据在HBase中是以==字节数组==进行存储
下载安装包并上传到node01服务器
安装包下载地址:
http://archive.cloudera.com/cdh6/cdh/5/hbase-1.2.0-cdh6.14.2.tar.gz
将安装包上传到node01服务器/kkb/soft路径下,并进行解压
[hadoop@node01 ~]$ cd /kkb/soft/
[hadoop@node01 soft]$ tar -xzvf hbase-1.2.0-cdh6.14.2.tar.gz -C /kkb/install/修改文件
[hadoop@node01 soft]$ cd /kkb/install/hbase-1.2.0-cdh6.14.2/conf/
[hadoop@node01 conf]$ vim hbase-env.sh修改如下两项内容,值如下
export JAVA_HOME=/kkb/install/jdk1.8.0_141
export HBASE_MANAGES_ZK=false

修改文件
[hadoop@node01 conf]$ vim hbase-site.xml<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node01:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01,node02,node03</value>
</property>
<!-- 此属性可省略,默认值就是2181 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/kkb/install/zookeeper-3.4.5-cdh6.14.2/zkdatas</value>
</property>
<!-- 此属性可省略,默认值就是/hbase -->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
</configuration>修改文件
[hadoop@node01 conf]$ vim regionservers指定HBase集群的从节点;原内容清空,添加如下三行
node01 node02 node03
创建back-masters配置文件,里边包含备份HMaster节点的主机名,每个机器独占一行,实现HMaster的高可用
[hadoop@node01 conf]$ vim backup-masters将node01上的HBase安装包,拷贝到其他机器上
[hadoop@node01 conf]$ cd /kkb/install
[hadoop@node01 install]$ scp -r hbase-1.2.0-cdh6.14.2/ node02:$PWD
[hadoop@node01 install]$ scp -r hbase-1.2.0-cdh6.14.2/ node03:$PWD**<font color='red'>注意:三台机器</font>**均做如下操作
因为HBase集群需要读取hadoop的core-site.xml、hdfs-site.xml的配置文件信息,所以我们==三台机器==都要执行以下命令,在相应的目录创建这两个配置文件的软连接
ln -s /kkb/install/hadoop-2.6.0-cdh6.14.2/etc/hadoop/core-site.xml /kkb/install/hbase-1.2.0-cdh6.14.2/conf/core-site.xml
ln -s /kkb/install/hadoop-2.6.0-cdh6.14.2/etc/hadoop/hdfs-site.xml /kkb/install/hbase-1.2.0-cdh6.14.2/conf/hdfs-site.xml执行完后,出现如下效果,以node01为例 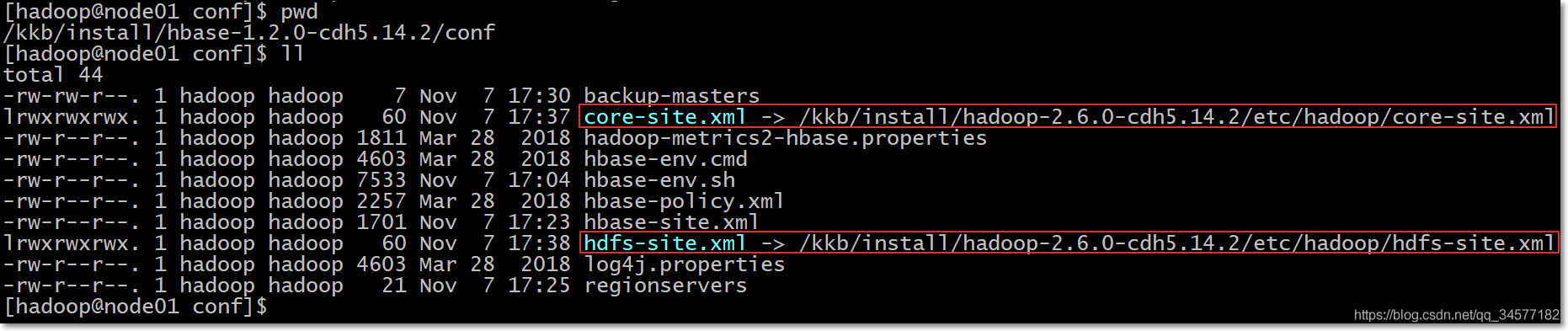
**<font color='red'>注意:三台机器</font>**均执行以下命令,添加环境变量
sudo vim /etc/profile
文件末尾添加如下内容
export HBASE_HOME=/kkb/install/hbase-1.2.0-cdh6.14.2
export PATH=$PATH:$HBASE_HOME/bin重新编译/etc/profile,让环境变量生效
source /etc/profile<font color='red'>需要提前启动HDFS及ZooKeeper集群</font>
第一台机器==node01==(HBase主节点)执行以下命令,启动HBase集群
[hadoop@node01 ~]$ start-hbase.sh启动完后,jps查看HBase相关进程
node01、node02上有进程HMaster、HRegionServer
node03上有进程HRegionServer
警告提示:HBase启动的时候会产生一个警告,这是因为jdk7与jdk8的问题导致的,如果linux服务器安装jdk8就会产生这样的一个警告

可以注释掉所有机器的hbase-env.sh当中的
“HBASE_MASTER_OPTS”和“HBASE_REGIONSERVER_OPTS”配置 来解决这个问题。
不过警告不影响我们正常运行,可以不用解决
我们也可以执行以下命令,单节点启动相关进程
#HMaster节点上启动HMaster命令
hbase-daemon.sh start master
#启动HRegionServer命令
hbase-daemon.sh start regionserver浏览器页面访问
http://node01:60010
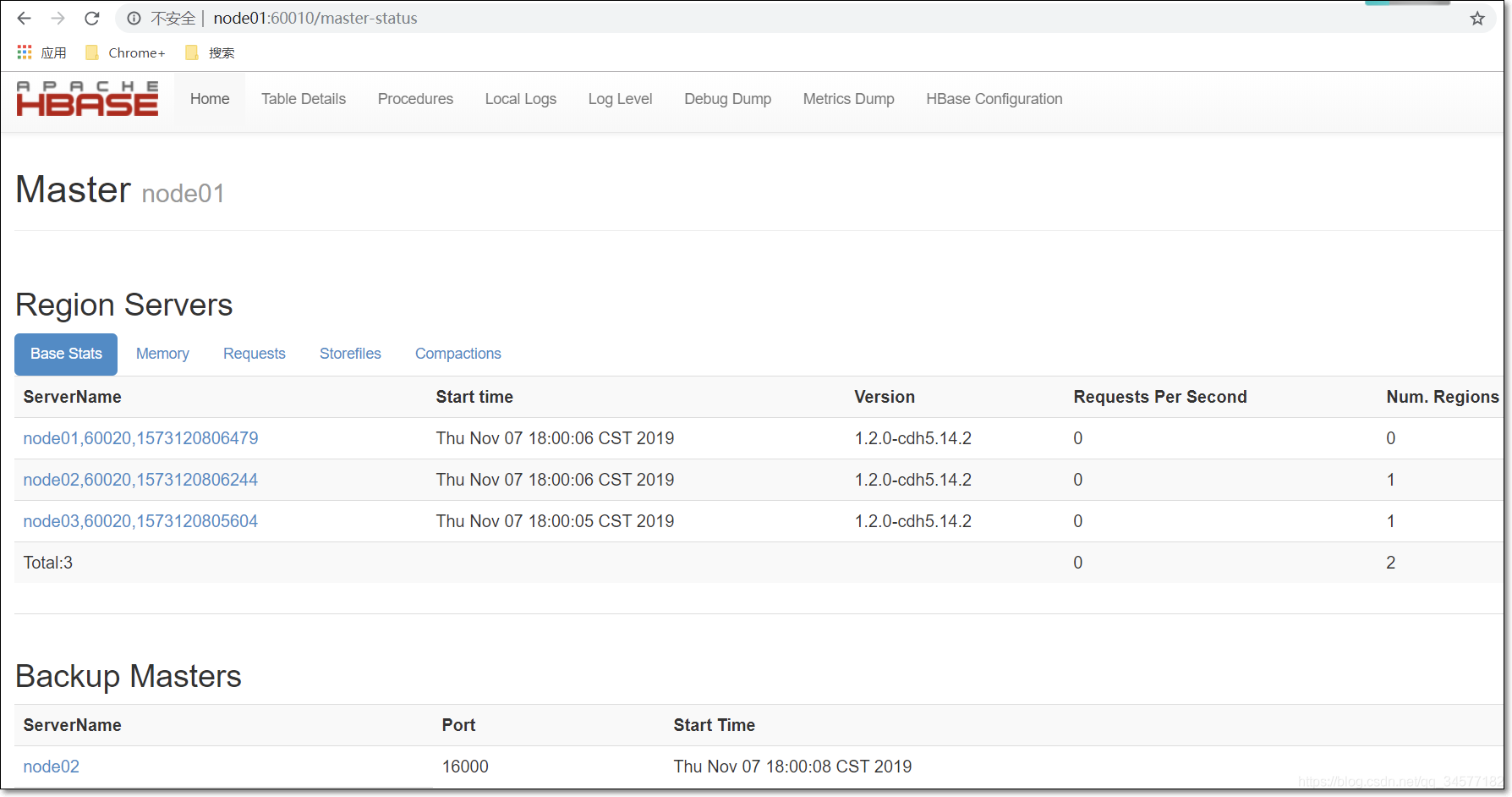
停止HBase集群的正确顺序
node01上运行
[hadoop@node01 ~]$ stop-hbase.sh若需要关闭虚拟机,则还需要关闭ZooKeeper、Hadoop集群
到此,关于“大数据数据库HBase的集群安装部署方法”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4895516/blog/5002869



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



