本篇内容主要讲解“Flink批处理怎么实现”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Flink批处理怎么实现”吧!
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算,Flink 是一个开源的流处理框架,它具有以下特点
批流一体:统一批处理、流处理
分布式:Flink程序可以运行在多台机器上
高性能:处理性能比较高
高可用:Flink支持高可用性(HA)
准确:Flink可以保证数据处理的准确性
首先,类比Spark, 我们来看Flink的模块划分
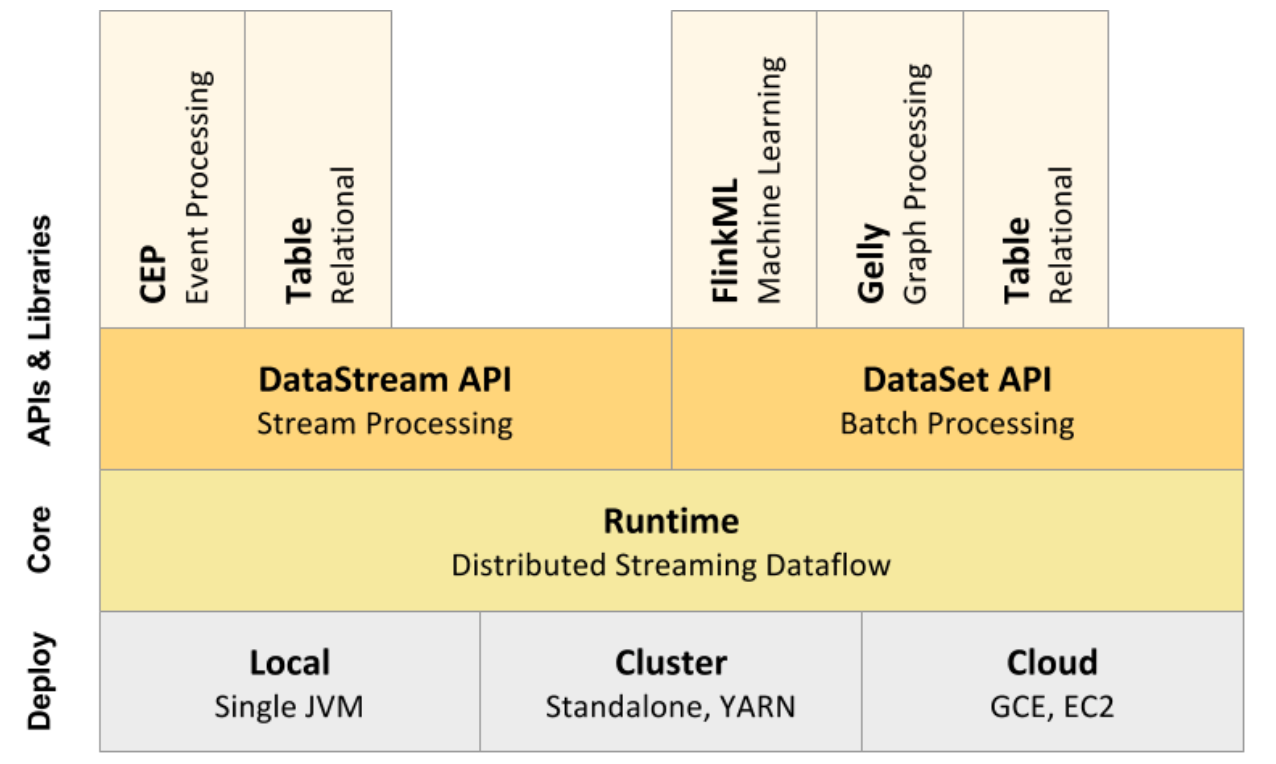
可以启动单个JVM,让Flink以Local模式运行Flink也可以以Standalone 集群模式运行,同时也支持Flink ON YARN,Flink应用直接提交到YARN上面运行Flink还可以运行在GCE(谷歌云服务)和EC2(亚马逊云服务)
在Runtime之上提供了两套核心的API,DataStream API(流处理)和DataSet API(批处理)
核心API之上又扩展了一些高阶的库和API
CEP流处理
Table API和SQL
Flink ML机器学习库
Gelly图计算
Flink作为大数据生态的一员,除了本身外,可以很好地与生态中的其他组件进行结合使用,大的概况方面来讲,就有输入方面和输出方面, 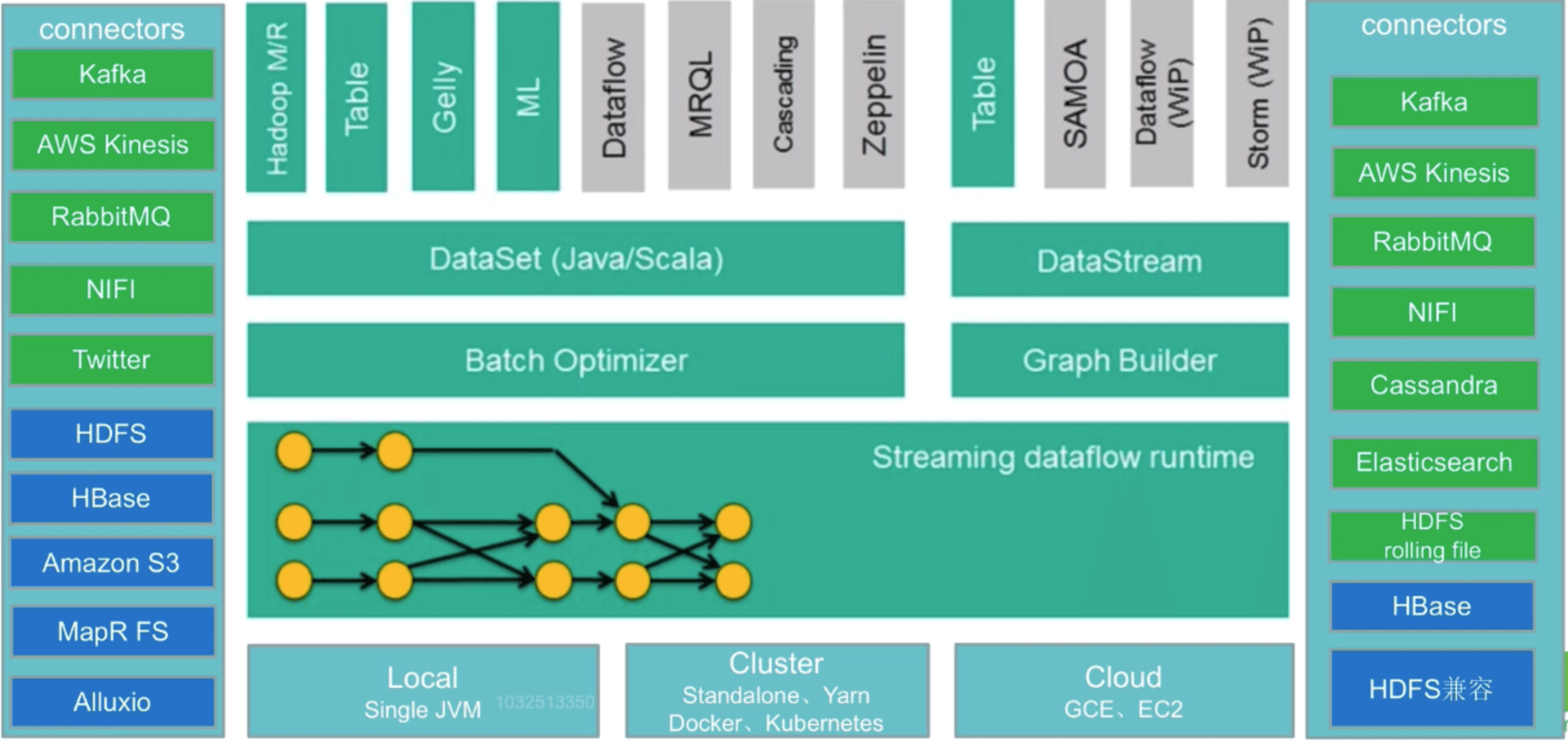
其中中间的部分,上面已经介绍,主页看看两边的,其中绿色背景是流处理方式的场景,蓝色背景是批处理方式的场景
流处理方式:包含Kafka(消息队列)、AWS kinesis(实时数据流服务)、RabbitMQ(消息队列)、NIFI(数 据管道)、Twitter(API)
批处理方式:包含HDFS(分布式文件系统)、HBase(分布式列式数据库)、Amazon S3(文件系统)、 MapR FS(文件系统)、ALLuxio(基于内存分布式文件系统)
流处理方式:包含Kafka(消息队列)、AWS kinesis(实时数据流服务)、RabbitMQ(消息队列)、NIFI(数 据管道)、Cassandra(NOSQL数据库)、ElasticSearch(全文检索)、HDFS rolling file(滚动文件)
批处理方式:包含HBase(分布式列式数据库)、HDFS(分布式文件系统)
Spark中的流处理主要有两种,一种是Spark Streamin是维批处理,如果对事件内的时间没有要求,这种方式可以满足很多需求,另外一种是Structed Streaming 是基于一张无界的大表,核心API就是Spark Sql的,而Flink是专注于无限流,把有界流看成是无限流的一种特殊情况,另外两个框架都有状态管理。
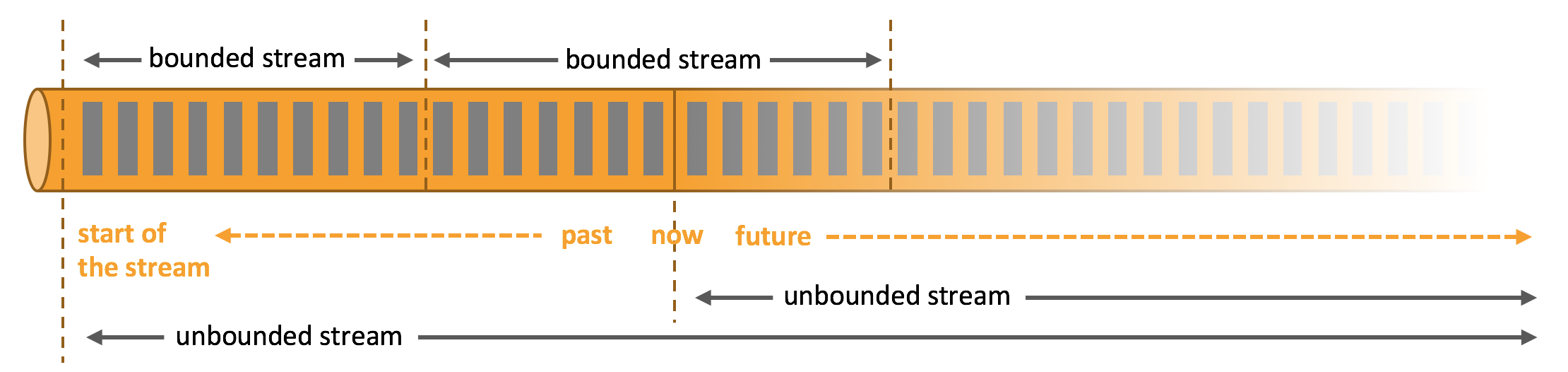
输入的数据没有尽头,像水流一样源源不断,数据处理从当前或者过去的某一个时间 点开始,持续不停地进行。
从某一个时间点开始处理数据,然后在另一个时间点结束输入数据可能本身是有限的(即输入数据集并不会随着时间增长),也可能出于分析的目的被人为地设定为有限集(即只分析某一个时间段内的事件)Flink封装了DataStream API进行流处理,封装了DataSet API进行批处理。同时,Flink也是一个批流一体的处理引擎,提供了Table API / SQL统一了批处理和流处理。
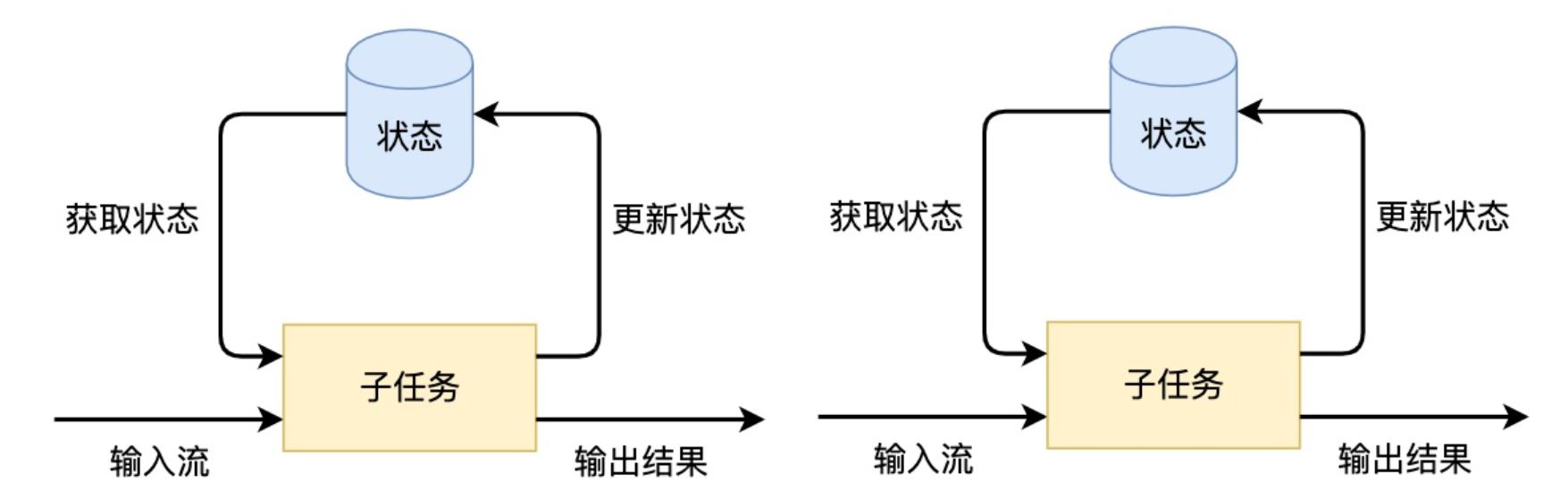
基于SubTask,每个SubTask处理时候,都会获取状态并更新状态,
以经典的WordCount为例,来看Flink的两个批流处理案例,案例以nc -lp 来作为Source, 以控制台输出为Sink, 分为Java和Scala版本哦,
import org.apache.flink.api.scala._
object WordCountScalaBatch {
def main(args: Array[String]): Unit = {
val inputPath = "E:\\hadoop_res\\input\\a.txt"
val outputPath = "E:\\hadoop_res\\output2"
val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
val text: DataSet[String] = environment.readTextFile(inputPath)
text
.flatMap(_.split("\\s+"))
.map((_, 1))
.groupBy(0)
.sum(1)
.setParallelism(1)
.writeAsCsv(outputPath, "\n", ",")
//setParallelism(1)很多算子后面都可以调用
environment.execute("job name")
}
}import org.apache.flink.streaming.api.scala._
object WordCountScalaStream {
def main(args: Array[String]): Unit = {
//处理流式数据
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val streamData: DataStream[String] = environment.socketTextStream("linux121", 7777)
val out: DataStream[(String, Int)] = streamData
.flatMap(_.split("\\s+"))
.map((_, 1))
.keyBy(0)
.sum(1)
out.print()
environment.execute("test stream")
}
}package com.hoult.demo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class WordCountJavaBatch {
public static void main(String[] args) throws Exception {
String inputPath = "E:\\hadoop_res\\input\\a.txt";
String outputPath = "E:\\hadoop_res\\output";
//获取flink的运行环境
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> text = executionEnvironment.readTextFile(inputPath);
FlatMapOperator<String, Tuple2<String, Integer>> wordsOne = text.flatMap(new SplitClz());
//hello,1 you,1 hi,1 him,1
UnsortedGrouping<Tuple2<String, Integer>> groupWordAndOne = wordsOne.groupBy(0);
AggregateOperator<Tuple2<String, Integer>> wordCount = groupWordAndOne.sum(1);
wordCount.writeAsCsv(outputPath, "\n", "\t").setParallelism(1);
executionEnvironment.execute();
}
static class SplitClz implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] strs = s.split("\\s+");
for (String str : strs) {
collector.collect(new Tuple2<String, Integer>(str, 1));
}
}
}
}package com.hoult.demo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountJavaStream {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataStream = executionEnvironment.socketTextStream("linux121", 7777);
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = dataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String word : s.split(" ")) {
collector.collect(new Tuple2<String, Integer>(word, 1));
}
}
}).keyBy(0).sum(1);
sum.print();
executionEnvironment.execute();
}
}到此,相信大家对“Flink批处理怎么实现”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





