本篇内容主要讲解“怎么用edgeadm一键安装边缘K8s集群和原生K8s集群”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“怎么用edgeadm一键安装边缘K8s集群和原生K8s集群”吧!
用户需要提前准备一个 Kubernetes 集群,对于很多用户来说门槛太高,搭建的流程比较复杂,容易失败,把很多想使用边缘能力的人群拒之门外;
往往要求特定工具搭建的特定版本的 Kubernetes 集群,通用性太差,用户在想在实际生产环境上使用限制性太大;
添加边缘节点需要依靠搭建 Kubernetes 集群本身的工具添加 Kubernetes 原生的节点再进行转化,对第三方工具依赖性较强,并且操作流程比较麻烦,容易出错;
无论 Kubernetes 集群的搭建,还是添加边缘节点都很难在生产环境自动化起来,相关流程还需要自己的团队进行二次开发,集成难度较大;
为了降低用户体验边缘能力的门槛,云原生社区的同学打算开发一个可以一键部署边缘 Kubernetes 集群的方法,让用户可以更容易、更简单的体验边缘 Kubernetes 集群。
针对上述问题,为了降低用户使用边缘 Kubernetes 集群的门槛,让边缘 Kubernetes 集群具备生产能力,我们设计了一键就可以部署出来一个边缘 Kubernetes 集群的方案,完全屏蔽安装细节,让用户可以零门槛的体验边缘能力。
让用户很简单、无门槛的使用边缘 Kubernetes 集群,并能在生产环境真正把边缘能力用起来;
一键化使用
能够一键搭建起一个边缘 Kubernetes 集群;
能够一键很简单、很灵活的添加边缘节点;
两种安装创景
支持在线安装;
支持离线安装,让私有化环境也能很简单;
可生产使用
不要封装太多,可以让想使用边缘 Kubernetes 集群的团队能在内部系统进行简单的集成,就生产可用;
零学习成本
尽可能的和 kubeadm 的使用方式保持一致,让用户无额外的学习成本,会用 kubeadm 就会用 edgeadm;
不修改 kubeadm 源码
尽量引用和复用 kubeadm 的源码,尽量不修改 kubeadm 的源码,避免后面升级的隐患;
基于 kubeadm 但又高于 kubeadm,不必被 kubeadm 的设计所局限,只要能让用户使用起来更简单就可以被允许;
允许用户选择是否部署边缘能力组件;
允许用户自定义边缘能力组件的配置;
我们研究了 kubeadm 的源码,发现可以借用 kubeadm 创建原生 Kubernetes集群、join 节点、workflow 思想来一键部署边缘 Kubernetes 集群,并且可以分步去执行安装步骤。这正是我们想要的简单、灵活、低学习成本的部署方案。于是我们站在巨人的肩膀上,利用 Kubedam 的思想,复用 kubeadm 的源码,设计出了如下的解决方案。
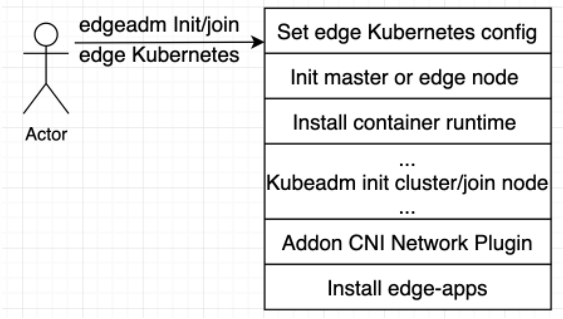
其中
kubeadm init cluster/join node部分完全复用了 kubadm 的源码,所有逻辑和 kubeadm 完全相同。
这个方案有如下几个优点:
我们只是站在 kubeadm 的肩膀上,在 kubeadm init/join 之前设置了一些边缘集群需要的配置参数,将初始化 Master 或 Node 节点自动化,安装了容器运行时。在 kubeadm init/join 完成之后,安装了 CNI 网络插件和部署了相应的边缘能力组件。
我们以 Go Mod 方式引用了 kubeadm 源码,整个过程中并未对 kubeadm 的源码修改过一行,完全的原生,为后面升级更高版本的 kubeadm 做好了准备。
edgeadm init 集群和 join 节点完全保留了 kubeadm init/join 原有的参数和流程,只是自动了初始化节点和安装容器运行时,可以用edgeadm --enable-edge=fasle参数来一键化安装原生 Kubernetes 集群, 也可以用edgeadm --enable-edge=true参数一键化来安装边缘 Kubernetes 集群。
可以 Join 任何只要能够访问到 Kube-apiserver 位于任何位置的节点, 也可以 join master。join master 也延续了 kubeadm 的的方式,搭建高可用的节点可以在需要的时候,直接用 join master 去扩容 Master 节点,实现高可用。
因为kubeadm init cluster/join node部分完全复用了 kubadm 的源码,所有逻辑和 kubeadm 完全相同,完全保留了 kubeadm 的使用习惯和所有 flag 参数,用法和 kubeadm 使用完全一样,没有任何新的学习成本,用户可以按 kubeadm 的参数或者使用 kubeadm.config 去自定义边缘 Kubernetes 集群。
借助 Kubernetes Node鉴权机制,我们默认开启了NodeRestriction准入插件,确保每个节点身份都唯一,只具有最小权限集,即使某个边缘节点被攻破也无法操作其他边缘节点。
Kubelet 我们也默认开启了Kubelet配置证书轮换机制,在 Kubelet 证书即将过期时, 将自动生成新的秘钥,并从 Kubernetes API 申请新的证书。 一旦新的证书可用,它将被用于与 Kubernetes API 间的连接认证。
以下流程社区已经录制了详细教程视频,可结合文档进行安装:
视频资源链接:用edgeadm一键安装边缘Kubernetes 集群和原生Kubernetes 集群
遵循 kubeadm 的最低要求 ,Master && Node 最低2C2G,磁盘空间不小于1G;
目前支持 amd64、arm64 两个体系;
其他体系可自行编译 edgeadm 和制作相应体系安装包,可参考 5. 自定义Kubernetes静态安装包
支持的 Kubernetes 版本:大于等于v1.18,提供的安装包仅提供 Kubernetes v1.18.2 版本;
其他 Kubernetes 版本可参考 5. 自定义 Kubernetes 静态安装包,自行制作。
下载 edgeadm 静态安装包,并拷贝到所有 Master 和 Node 节点。
注意修改"arch=amd64"参数,目前支持[amd64, amd64], 下载自己机器对应的体系结构,其他参数不变
arch=amd64 version=v0.3.0-beta.0 && rm -rf edgeadm-linux-* && wget https://superedge-1253687700.cos.ap-guangzhou.myqcloud.com/$version/$arch/edgeadm-linux-$arch-$version.tgz && tar -xzvf edgeadm-linux-* && cd edgeadm-linux-$arch-$version && ./edgeadm
安装包大约200M,关于安装包的详细信息可查看 5. 自定义Kubernetes静态安装包。
如果下载安装包比较慢,可直接查看相应SuperEdge相应版本, 下载
edgeadm-linux-amd64/arm64-*.0.tgz,并解压也是一样的。一键安装边缘独立 Kubernetes 集群功能从 SuperEdge-v0.3.0-beta.0开始支持,注意下载 v0.3.0-beta.0 及以后版本。
./edgeadm init --kubernetes-version=1.18.2 --image-repository superedge.tencentcloudcr.com/superedge --service-cidr=10.96.0.0/12 --pod-network-cidr=192.168.0.0/16 --install-pkg-path ./kube-linux-*.tar.gz --apiserver-cert-extra-sans=<Master节点外网IP> --apiserver-advertise-address=<Master节点内网IP> --enable-edge=true -v=6
其中:
--enable-edge=true: 是否部署边缘能力组件,默认 true
--enable-edge=false 表示安装原生 Kubernetes 集群,和 kubeadm 搭建的集群完全一样;
--install-pkg-path: Kubernetes 静态安装包的地址
--install-pkg-path的值可以为机器上的路径,也可以为网络地址(比如:http://xxx/xxx/kube-linux-arm64/amd64-*.tar.gz, 能免密wget到就可以),注意用和机器体系匹配的Kubernetes静态安装包;
--apiserver-cert-extra-sans: kube-apiserver的证书扩展地址
推荐签订Master节点外网IP或者域名,只要签订的Master节点的IP或者域名能被边缘节点访问到就可以,当然内网IP也被允许,前提是边缘节点可以通过此IP访问 Kube-apiserver。自定义域名的话可自行在所有 Matser和Node节点配置 hosts;
签订外网IP和域名,是因为边缘节点一般和 Master 节点不在同一局域网,需要通过外网来加入和访问Master;
--image-repository:镜像仓库地址
要是 superedge.tencentcloudcr.com/superedge 比较慢,可换成其他加速镜像仓库,只要能 Pull 下来 kube-apiserver,kube-controller-manager,kube-scheduler,kube-proxy,etcd, pause……镜像就可以。
其他参数和 kubeadm 含义完全相同,可按 kubeadm 的要求进行配置。
也可用 kubeadm.config 配置 kubeadm 的原参数,通过
edgeadm init --config kubeadm.config --install-pkg-path ./kube-linux-*.tar.gz来创建边缘 Kubernetes 集群。
要是执行过程中没有问题,集群成功初始化,会输出如下内容:
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: edgeadm join xxx.xxx.xxx.xxx:xxx --token xxxx \ --discovery-token-ca-cert-hash sha256:xxxxxxxxxx --install-pkg-path <Path of edgeadm kube-* install package>
执行过程中如果出现问题会直接返回相应的错误信息,并中断集群的初始化,可使用./edgeadm reset命令回滚集群的初始化操作。
要使非 root 用户可以运行 kubectl,请运行以下命令,它们也是 edgeadm init 输出的一部分:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
或者,如果你是 root 用户,则可以运行:
export KUBECONFIG=/etc/kubernetes/admin.conf
注意保存./edgeadm init输出的./edgeadm join命令,后面添加Node节点时会用到。
其中token的有效期和kubeadm一样24h,过期之后可以用./edgeadm token create创建新的token。
--discovery-token-ca-cert-hash 的值生成也同 kubeadm,可在 Master 节点执行下面命令生成。
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
在边缘节点上执行 <2>.下载edgeadm静态安装包,或者通过其他方式把 edgeadm 静态安装包上传到边缘节点,然后执行如下命令:
./edgeadm join <Master节点外网IP/Master节点内网IP/域名>:Port --token xxxx \ --discovery-token-ca-cert-hash sha256:xxxxxxxxxx --install-pkg-path <edgeadm Kube-*静态安装包地址/FTP路径> --enable-edge=true
其中:
<Master 节点外网 IP/Master 节点内网IP/域名>:Port 是节点访问 Kube-apiserver 服务的地址
可以把
edgeadm init加入节点提示的 Kube-apiserver 服务的地址视情况换成Master节点外网IP/Master节点内网IP/域名,主要取决于想让节点通过外网还是内网访问 Kube-apiserver 服务。
--enable-edge=true: 加入的节点是否作为边缘节点(是否部署边缘能力组件),默认 true
--enable-edge=false 表示 join 原生 Kubernetes 集群节点,和 kubeadm join 的节点完全一样;
如果执行过程中没有问题,新的 Node 成功加入集群,会输出如下内容:
This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
执行过程中如果出现问题会直接返回相应的错误信息,并中断节点的添加,可使用./edgeadm reset命令回滚加入节点的操作,重新 join。
提示:如果边缘节点 join 成功后都会给边缘节点打一个label:
superedge.io/edge-node=enable,方便后续应用用 nodeSelector 选择应用调度到边缘节点;原生 Kubernetes 节点和 kubeadm 的 join 一样,不会做任何操作。
准备一个Master VIP,做为可用负载均衡统一入口;
3台满足 kubeadm 的最低要求 的机器作为Master节点;
3台满足 kubeadm 的最低要求 的机器做worker节点;
在 Master 上安装 Haproxy 作为集群总入口
注意:替换配置文件中的 < Master VIP >
# yum install -y haproxy# cat << EOF >/etc/haproxy/haproxy.cfgglobal log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon stats socket /var/lib/haproxy/statsdefaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000frontend main *:5000 acl url_static path_beg -i /static /images /javascript /stylesheets acl url_static path_end -i .jpg .gif .png .css .js use_backend static if url_static default_backend appfrontend kubernetes-apiserver mode tcp bind *:16443 option tcplog default_backend kubernetes-apiserverbackend kubernetes-apiserver mode tcp balance roundrobin server master-0 <Master VIP>:6443 check # 这里替换 Master VIP 为用户自己的 VIPbackend static balance roundrobin server static 127.0.0.1:4331 checkbackend app balance roundrobin server app1 127.0.0.1:5001 check server app2 127.0.0.1:5002 check server app3 127.0.0.1:5003 check server app4 127.0.0.1:5004 checkEOF
在所有 Master 安装 Keepalived,执行同样操作: 注意:
替换配置文件中的 < Master VIP >
下面的 keepalived.conf 配置文件中 < Master 本机外网 IP > 和 < 其他 Master 外网 IP > 在不同 Master 的配置需要调换位置,不要填错。
## 安装keepalived yum install -y keepalived cat << EOF >/etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { smtp_connect_timeout 30 router_id LVS_DEVEL_EDGE_1 } vrrp_script checkhaproxy{ script "/etc/keepalived/do_sth.sh" interval 5 } vrrp_instance VI_1 { state BACKUP interface eth0 nopreempt virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass aaa } virtual_ipaddress { <master VIP> # 这里替换 Master VIP 为用户自己的 VIP } unicast_src_ip <Master 本机外网 IP> unicast_peer { <其他 Master 外网 IP> <其他 Master 外网 IP> } notify_master "/etc/keepalived/notify_action.sh master" notify_backup "/etc/keepalived/notify_action.sh BACKUP" notify_fault "/etc/keepalived/notify_action.sh FAULT" notify_stop "/etc/keepalived/notify_action.sh STOP" garp_master_delay 1 garp_master_refresh 5 track_interface { eth0 } track_script { checkhaproxy } } EOF在其中一台 Master 中执行集群初始化操作
./edgeadm init --control-plane-endpoint <Master VIP> --upload-certs --kubernetes-version=1.18.2 --image-repository superedge.tencentcloudcr.com/superedge --service-cidr=10.96.0.0/12 --pod-network-cidr=192.168.0.0/16 --apiserver-cert-extra-sans=<Master节点外网IP/Master节点内网IP/域名/> --install-pkg-path <edegadm Kube-*静态安装包地址> -v=6
参数含义同
3. 用 edgeadm 安装边缘 Kubernetes 集群,其他和 kubeadm 一致,这里不在解释;
要是执行过程中没有问题,集群成功初始化,会输出如下内容:
Your Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster.Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: edgeadm join xxx.xxx.xxx.xxx:xxx --token xxxx \ --discovery-token-ca-cert-hash sha256:xxxxxxxxxx \ --control-plane --certificate-key xxxxxxxxxx --install-pkg-path <Path of edgeadm kube-* install package> Please note that the certificate-key gives access to cluster sensitive data, keep it secret!As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use"edgeadm init phase upload-certs --upload-certs" to reload certs afterward.Then you can join any number of worker nodes by running the following on each as root:edgeadm join xxx.xxx.xxx.xxx:xxxx --token xxxx \ --discovery-token-ca-cert-hash sha256:xxxxxxxxxx --install-pkg-path <Path of edgeadm kube-* install package>
执行过程中如果出现问题会直接返回相应的错误信息,并中断集群的初始化,使用./edgeadm reset命令回滚集群的初始化操作。
要使非 root 用户可以运行 kubectl,请运行以下命令,它们也是 edgeadm init 输出的一部分:
mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/config
或者,如果你是 root 用户,则可以运行:
export KUBECONFIG=/etc/kubernetes/admin.conf
注意保存./edgeadm init输出的./edgeadm join命令,后面添加Master节点和边缘节点需要用到。
在另一台 Master 执行./edgeadm join命令
./edgeadm join xxx.xxx.xxx.xxx:xxx --token xxxx \ --discovery-token-ca-cert-hash sha256:xxxxxxxxxx \ --control-plane --certificate-key xxxxxxxxxx \ --install-pkg-path <edgeadm Kube-*静态安装包地址
要是执行过程中没有问题,新的 Master 成功加入集群,会输出如下内容:
This node has joined the cluster and a new control plane instance was created:* Certificate signing request was sent to apiserver and approval was received.* The Kubelet was informed of the new secure connection details.* Control plane (master) label and taint were applied to the new node.* The Kubernetes control plane instances scaled up.* A new etcd member was added to the local/stacked etcd cluster.To start administering your cluster from this node, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Run 'kubectl get nodes' to see this node join the cluster.
执行过程中如果出现问题会直接返回相应的错误信息,并中断节点的添加,使用./edgeadm reset命令回滚集群的初始化操作。
./edgeadm join xxx.xxx.xxx.xxx:xxxx --token xxxx \ --discovery-token-ca-cert-hash sha256:xxxxxxxxxx --install-pkg-path <edgeadm Kube-*静态安装包地址/FTP路径>
要是执行过程中没有问题,新的 node 成功加入集群,会输出如下内容:
This node has joined the cluster:* Certificate signing request was sent to apiserver and a response was received.* The Kubelet was informed of the new secure connection details.Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
执行过程中如果出现问题会直接返回相应的错误信息,并中断节点的添加,使用./edgeadm reset命令回滚集群的初始化操作。
Kubernetes 静态安装包的目录结构如下:
kube-linux-arm64-v1.18.2.tar.gz ## kube-v1.18.2 arm64的Kubernetes静态安装包├── bin ## 二进制目录│ ├── conntrack ## 连接跟踪的二进制文件│ ├── kubectl ## kube-v1.18.2的kubectl│ ├── kubelet ## kube-v1.18.2的kubelet│ └── lite-apiserver ## 相应版本的lite-apiserver,可编译SuperEdge的lite-apiserver生成├── cni ## cin的配置│ └── cni-plugins-linux-v0.8.3.tar.gz ## v0.8.3的CNI插件二进制压缩包└── container ## 容器运行时目录 └── docker-19.03-linux-arm64.tar.gz ## docker 19.03 arm64体系的安装脚本和安装包
自定义其他 Kubernetes 版本需要做的有两件事:
替换二进制目录中的 kubectl 和 kubelet 文件,版本需要大于等于 Kubernetes v1.18.0;
确保 init 使用的镜像仓库中有相应 Kubernetes 版本的基础镜像;
自定义 Kubernetes 静态安装包其他体系需要做三件事:
将 Kubernetes 静态安装包的所有二进制换成目标体系,包括 cni 和 container 相应安装包中的二进制;
确保 init 使用的镜像仓库中有相应体系的 Kubernetes 版本的基础镜像,推荐使用多体系镜像;
充分测试,确保没有什么兼容问题。要有相关问题,也可以在 SuperEdge 社区提 Issues 一块来修复。
到此,相信大家对“怎么用edgeadm一键安装边缘K8s集群和原生K8s集群”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





