本篇内容介绍了“KubeVela+KEDA有什么作用”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
当管理 Kubernetes 集群和应用程序时,你需要仔细监视各种事情,比如:
集群容量——我们是否有足够的可用资源来运行我们的工作负载?
应用程序工作负载——应用程序有足够的可用资源吗?它能跟上待完成的工作吗?(像队列深度)
为了实现自动化,你通常会设置警报以获得通知,甚至使用自动伸缩。Kubernetes 是一个很好的平台,它可以帮助你实现这个即时可用的功能。 通过使用 Cluster Autoscaler 组件可以轻松地伸缩集群,该组件将监视集群,以发现由于资源短缺而无法调度的 pod,并开始相应地添加/删除节点。 因为 Cluster Autoscaler 只在 pod 调度过度时才会启动,所以你可能会有一段时间间隔,在此期间你的工作负载没有启动和运行。 Virtual Kubelet(一个 CNCF 沙箱项目)是一个巨大的帮助,它允许你向 Kubernetes 集群添加一个“虚拟节点”,pod 可以在其上调度。 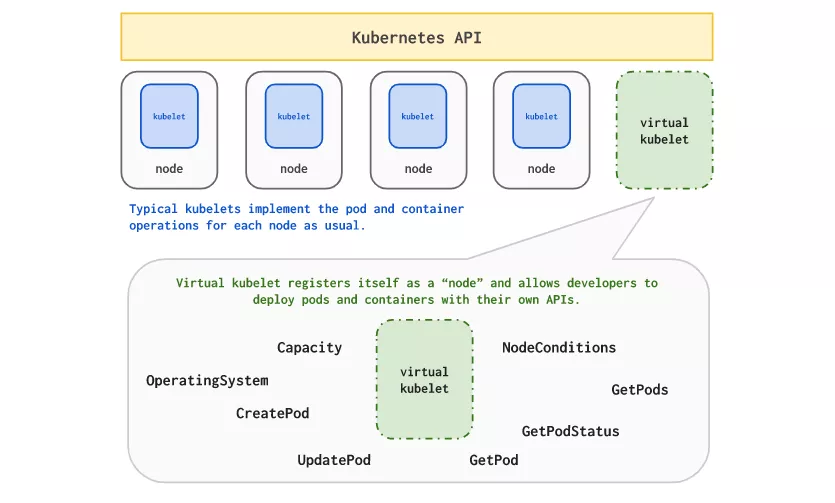
通过这样做,平台供应商(如阿里巴巴、Azure、HashiCorp 和其他)允许你将挂起的 pod 溢出到集群之外,直到它提供所需的集群容量来缓解这个问题。 除了伸缩集群,Kubernetes 还允许你轻松地伸缩应用程序:
Horizontal Pod Autoscaler(HPA)允许你添加/删除更多的 Pod 到你的工作负载中,以 scale in/out(添加或删除副本)。
Vertical Pod Autoscaler(VPA)允许你添加/删除资源到你的 Pod 以 scale up/down(添加或删除 CPU 或内存)。
所有这些为你伸缩应用程序提供了一个很好的起点。
虽然 HPA 是一个很好的起点,但它主要关注 pod 本身的指标,允许你基于 CPU 和内存伸缩它。也就是说,你可以完全配置它应该如何自动缩放,这使它强大。 虽然这对于某些工作负载来说是理想的,但你通常想要基于其他地方如 Prometheus、Kafka、云供应商或其他事件上的指标进行伸缩。 多亏了外部指标支持,用户可以安装指标适配器,从外部服务中提供各种指标,并通过使用指标服务器对它们进行自动伸缩。 但是,有一点需要注意,你只能在集群中运行一个指标服务器,这意味着你必须选择自定义指标的来源。 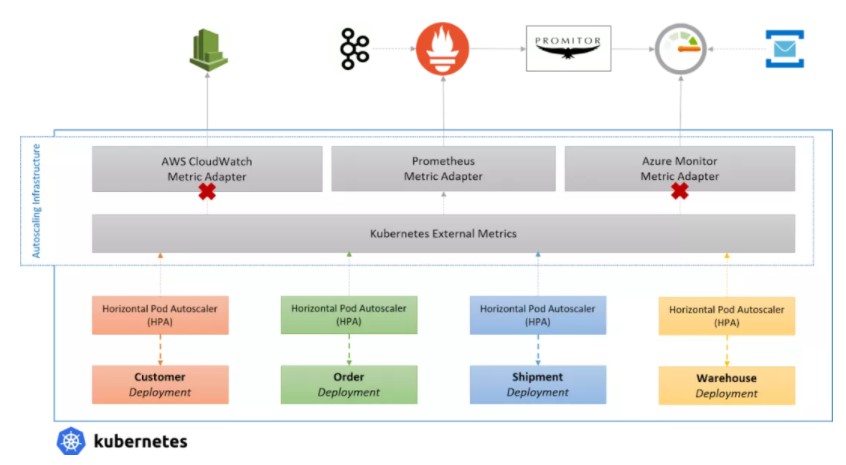
你可以使用 Prometheus 和工具,比如 Promitor,从其他提供商那里获取你的指标,并将其作为单一的真相来源来进行伸缩,但这需要大量的管道(plumbing)和工作来进行扩展。 肯定有更简单的方法……是的,使用 Kubernetes Event-Driven Autoscaling(KEDA)!
Kubernetes Event-Driven Autoscaling(KEDA)是一个用于 Kubernetes 的单用途事件驱动自动伸缩器,可以很容易地将其添加到 Kubernetes 集群中以伸缩应用程序。 它的目标是使应用程序自动扩展非常简单,并通过支持伸缩到零(scale-to-zero)来优化成本。 KEDA 去掉了所有的伸缩基础设施,并为你管理一切,允许你在 30 多个系统上进行伸缩或使用自己的伸缩器进行扩展。 用户只需要创建 ScaledObject 或 ScaledJob 来定义你想要伸缩的对象和你想要使用的触发器;KEDA 会处理剩下的一切! 
你可以伸缩任何东西;即使它是你正在使用的另一个工具的 CRD,只要它实现/scale 子资源。 那么,KEDA 重新发明轮子了吗?不!相反,它通过在底层使用 HPA 来扩展 Kubernetes,HPA 使用我们的外部指标,这些指标由我们自己的指标适配器提供,该适配器取代了所有其他适配器。 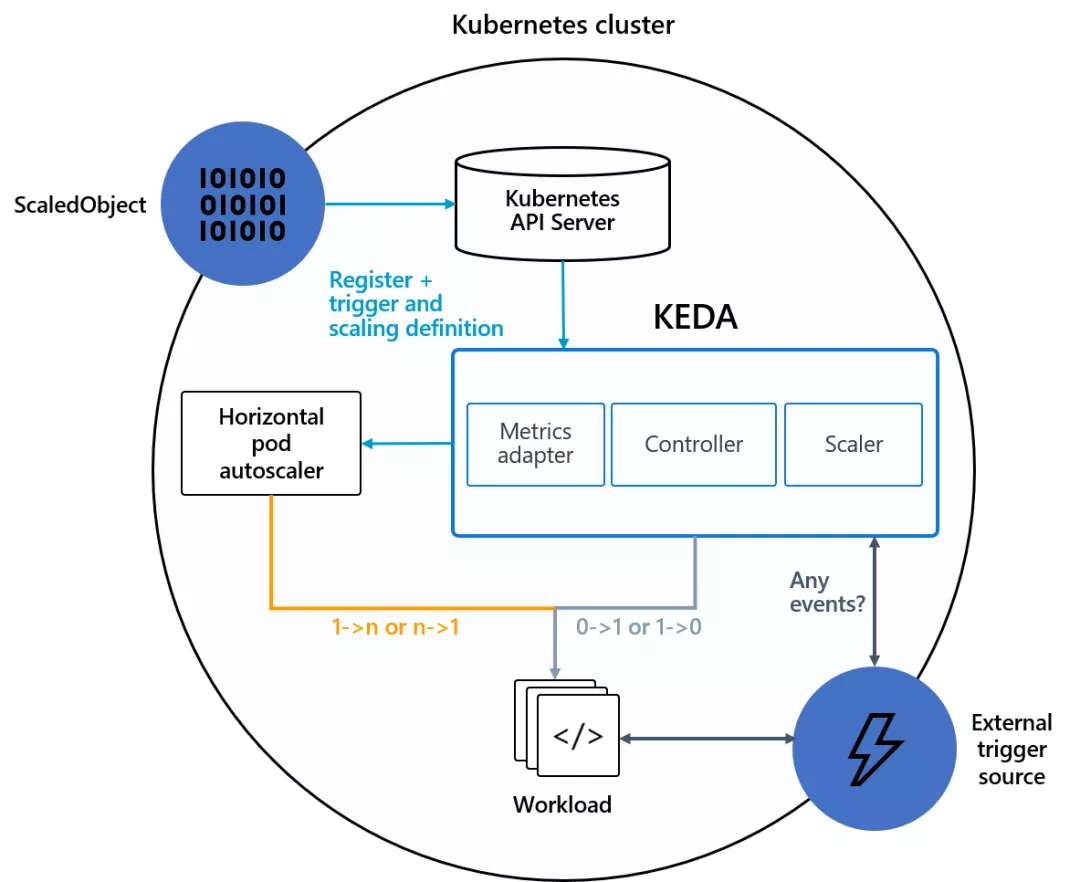
去年,KEDA 加入了 CNCF,作为 CNCF 沙箱项目,计划今年晚些时候提案升级到孵化阶段。
企业分布式应用服务(EDAS)作为阿里云上的主要企业 PaaS 产品,多年来以巨大的规模服务于公有云上的无数开发者。从架构的角度来看,EDAS 是与 KubeVela 项目一起构建的。其总体架构如下图所示。 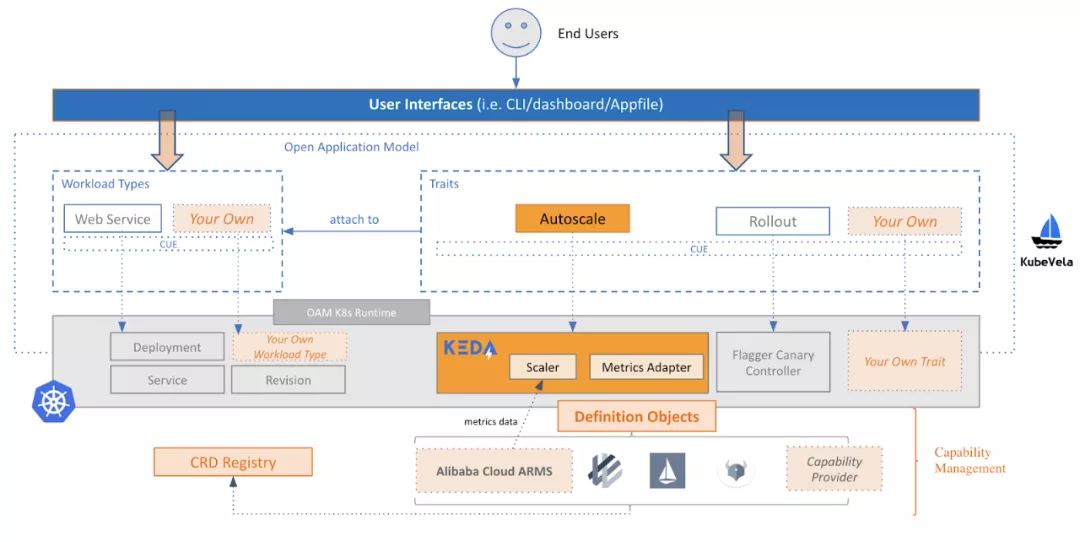
在生产上,EDAS 在阿里云上集成了 ARMS 监控服务,提供监控和应用的细粒度指标。EDAS 团队在 KEDA 项目中添加了一个 ARMS Scaler 来执行自动缩放。他们还添加了一些特性,并修复了 KEDA v1 版本中的一些 bug。包括:
当有多个触发器时,这些值将被求和,而不是作为单独的值留下。
当创建 KEDA HPA 时,名称的长度将被限制为 63 个字符,以避免触发 DNS 投诉。
不能禁用触发器,这可能会在生产中引起麻烦。
EDAS 团队正在积极地将这些修复程序发送给上游 KEDA,尽管其中一些已经添加到 V2 版本中。
当涉及到自动扩展特性时,EDAS 最初使用上游 Kubernetes HPA 的 CPU 和内存作为两个指标。然而,随着用户群的增长和需求的多样化,EDAS 团队很快发现了上游 HPA 的局限性:
对定制指标的支持有限,特别是对应用程序级细粒度指标的支持。上游 HPA 主要关注容器级指标,比如 CPU 和内存,这些指标对于应用程序来说太粗糙了。反映应用程序负载的指标(如 RT 和 QPS)不受现成支持。是的,HPA 可以扩展。然而,当涉及到应用程序级指标时,这种能力是有限的。EDAS 团队在尝试引入细粒度的应用程序级指标时,经常被迫分叉代码。
不支持伸缩到零。当他们的微服务没有被使用时,许多用户都有将规模伸缩到零的需求。这一需求不仅限于 FaaS/无服务器工作负载。它为所有用户节省成本和资源。目前,上游 HPA 不支持此功能。
不支持预定的伸缩。EDAS 用户的另一个强烈需求是预定的伸缩能力。同样,上游 HPA 不提供此功能,EDAS 团队需要寻找非供应商锁定的替代方案。
基于这些需求,EDAS 团队开始规划 EDAS 自动伸缩特性的新版本。与此同时,EDAS 在 2020 年初引入了 OAM,对其底层核心组件进行了彻底改革。OAM 为 EDAS 提供了标准化的、可插入的应用程序定义,以取代其内部的 Kubernetes 应用程序 CRD。该模型的可扩展性使 EDAS 能够轻松地与 Kubernetes 社区的任何新功能集成。在这种情况下,EDAS 团队试图将对 EDAS 新的自动伸缩特性的需求与 OAM 自动伸缩特性的标准实现相结合。 基于用例,EDAS 团队总结了三个标准:
自动伸缩特性应该将自己呈现为一个简单的原子功能,而不需要附加任何复杂的解决方案。
指标应该是可插入的,因此 EDAS 团队可以对其进行定制,并在其之上构建以支持各种需求。
它需要开箱即用地支持伸缩到零。
经过详细的评估,EDAS 团队选择了 KEDA 项目,该项目是由微软和红帽开源的,已捐赠给 CNCF。KEDA 默认提供了几个有用的 Scaler,并开箱即用地支持伸缩到零。它为应用程序提供了细粒度的自动伸缩。它具有 Scalar 和 Metric 适配器的概念,支持强大的插件架构,同时提供统一的 API 层。最重要的是,KEDA 的设计只关注自动伸缩,这样就可以轻松地将其集成为 OAM 特性。总的来说,KEDA 非常适合 EDAS。
“KubeVela+KEDA有什么作用”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





