本篇内容介绍了“Classification算法指标是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
常见的分类(Classification)算法指标主要有精度(Accuracy)、准确率和召回率、ROC曲线和AUC空间这几种。
分类是机器学习中的一类重要问题,很多重要的算法都在解决分类问题,例如决策树,支持向量机等,其中二分类问题是分类问题中的一个重要的课题。
常见的分类模型包括:逻辑回归、决策树、朴素贝叶斯、SVM、神经网络等,模型评估指标包括以下几种:
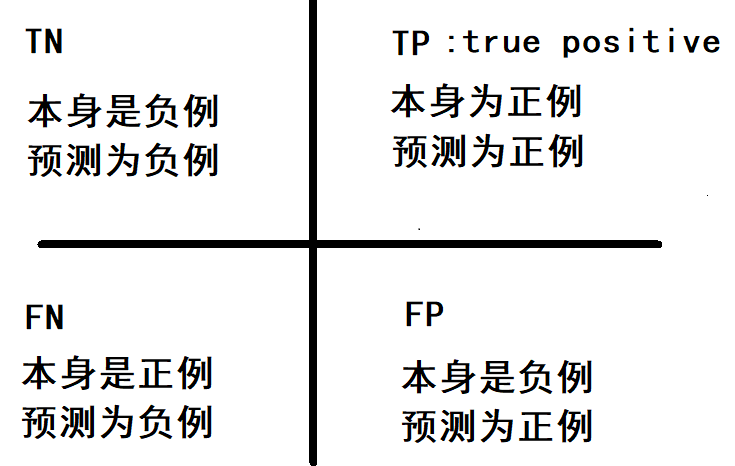
什么是混淆矩阵(Confusionmatrix)。这个名字起得是真的好,初学者很容易被这个矩阵搞得晕头转向。下图a就是有名的混淆矩阵,而下图b则是由混淆矩阵推出的一些有名的评估指标。
在二分类问题中,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也被 预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。
True Positive (真正, TP) 被模型预测为正的正样本;可以称作判断为真的正确率
True Negative (真负 , TN) 被模型预测为负的负样本 ;可以称作判断为假的正确率
False Positive (假正, FP) 被模型预测为正的负样本;可以称作误报率
False Negative(假负 , FN) 被模型预测为负的正样本;可以称作漏报率
True Positive Rate(真正率 , TPR)或灵敏度(sensitivity)
TPR = TP /(TP + FN)
正样本预测结果数 / 正样本实际数
True Negative Rate(真负率 , TNR)或特指度(specificity)
TNR = TN /(TN + FP)
负样本预测结果数 / 负样本实际数
False Positive Rate (假正率, FPR)
FPR = FP /(FP + TN)
被预测为正的负样本结果数 /负样本实际数
False Negative Rate(假负率 , FNR)
FNR = FN /(TP + FN)
被预测为负的正样本结果数 / 正样本实际数
精确度(Precision):
P = TP/(TP+FP) ; 反映了被分类器判定的正例中真正的正例样本的比重
准确率(Accuracy)
A = (TP + TN)/(P+N) = (TP + TN)/(TP + FN + FP + TN);
反映了分类器统对整个样本的判定能力——能将正的判定为正,负的判定为负
召回率(Recall),也称为 True Positive Rate:
R = TP/(TP+FN) = 1 - FN/T; 反映了被正确判定的正例占总的正例的比重
from sklearn.metrics import confusion_matrix
# y_pred是预测标签
y_pred, y_true =[1,0,1,0], [0,0,1,0]
confusion_matrix(y_true=y_true, y_pred=y_pred)精确率(正确率)和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了,两者的定义分别如下:
Precision = 提取出的正确信息条数 / 提取出的信息条数
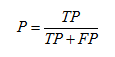
Recall = 提取出的正确信息条数 / 样本中的信息条数
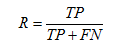
Precision和Recall指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下:
F1值 = 正确率 * 召回率 * 2 / (正确率 + 召回率)
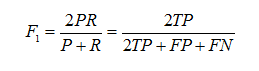
F-Measure是Precision和Recall加权调和平均:
当参数α=1时,就是最常见的F1。因此,F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。

准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。当精确率和召回率都高时,F1的值也会高。在两者都要求高的情况下,可以用F1来衡量
地震的预测
对于地震的预测,我们希望的是RECALL非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。
嫌疑人定罪
基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。及时有时候放过了一些罪犯(recall低),但也是值得的。
不妨举这样一个例子:
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F1值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F1值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
代码补充:
from sklearn.metrics import precision_score, recall_score, f1_score
# 正确率 (提取出的正确信息条数 / 提取出的信息条数)
print('Precision: %.3f' % precision_score(y_true=y_test, y_pred=y_pred))
# 召回率 (提出出的正确信息条数 / 样本中的信息条数)
print('Recall: %.3f' % recall_score(y_true=y_test, y_pred=y_pred))
# F1-score (正确率*召回率*2 /(正确率+召回率))
print('F1: %.3f' % f1_score(y_true=y_test, y_pred=y_pred))AUC是一种模型分类指标,且仅仅是二分类模型的评价指标。AUC是Area Under Curve的简称,那么Curve就是ROC(Receiver Operating Characteristic),翻译为"接受者操作特性曲线"。也就是说ROC是一条曲线,AUC是一个面积值。
ROC曲线应该尽量偏离参考线,越靠近左上越好
AUC:ROC曲线下面积,参考线面积为0.5,AUC应大于0.5,且偏离越多越好
Motivation1:在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例 的比类,即TPR,但同时也将更多的负实例当作了正实例,即提高了FPR。为了形象化这一变化,引入ROC,ROC曲线可以用于评价一个分类器。
Motivation2:在类不平衡的情况下,如正样本90个,负样本10个,直接把所有样本分类为正样本,得到识别率为90%。但这显然是没有意义的。单纯根据Precision和Recall来衡量算法的优劣已经不能表征这种病态问题。
绘制ROC曲线
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
# y_test:实际的标签, dataset_pred:预测的概率值。
fpr, tpr, thresholds = roc_curve(y_test, dataset_pred)
roc_auc = auc(fpr, tpr)
#画图,只需要plt.plot(fpr,tpr),变量roc_auc只是记录auc的值,通过auc()函数能计算出来
plt.plot(fpr, tpr, lw=1, label='ROC(area = %0.2f)' % (roc_auc))
plt.xlabel("FPR (False Positive Rate)")
plt.ylabel("TPR (True Positive Rate)")
plt.title("Receiver Operating Characteristic, ROC(AUC = %0.2f)"% (roc_auc))
plt.show()ROC(Receiver Operating Characteristic)翻译为"接受者操作特性曲线"。曲线由两个变量1-specificity 和 Sensitivity绘制. 1-specificity=FPR,即负正类率。Sensitivity即是真正类率,TPR(True positive rate),反映了正类覆盖程度。这个组合以1-specificity对sensitivity,即是以代价(costs)对收益(benefits)。显然收益越高,代价越低,模型的性能就越好。
此外,ROC曲线还可以用来计算“均值平均精度”(mean average precision),这是当你通过改变阈值来选择最好的结果时所得到的平均精度(PPV)。
x 轴为假阳性率(FPR):在所有的负样本中,分类器预测错误的比例

为了更好地理解ROC曲线,我们使用具体的实例来说明:
如在医学诊断中,判断有病的样本。那么尽量把有病的揪出来是主要任务,也就是第一个指标TPR,要越高越好。而把没病的样本误诊为有病的,也就是第二个指标FPR,要越低越好。
不难发现,这两个指标之间是相互制约的。如果某个医生对于有病的症状比较敏感,稍微的小症状都判断为有病,那么他的第一个指标应该会很高,但是第二个指标也就相应地变高。最极端的情况下,他把所有的样本都看做有病,那么第一个指标达到1,第二个指标也为1。
我们以FPR为横轴,TPR为纵轴,得到如下ROC空间。
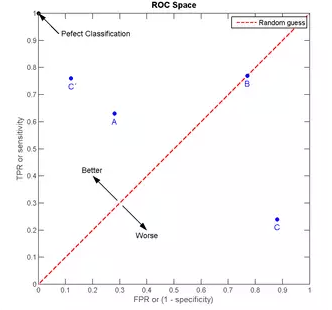
我们可以看出,左上角的点(TPR=1,FPR=0),为完美分类,也就是这个医生医术高明,诊断全对。点A(TPR>FPR),医生A的判断大体是正确的。中线上的点B(TPR=FPR),也就是医生B全都是蒙的,蒙对一半,蒙错一半;下半平面的点C(TPR<FPR),这个医生说你有病,那么你很可能没有病,医生C的话我们要反着听,为真庸医。上图中一个阈值,得到一个点。现在我们需要一个独立于阈值的评价指标来衡量这个医生的医术如何,也就是遍历所有的阈值,得到ROC曲线。
假设下图是某医生的诊断统计图,为未得病人群(上图)和得病人群(下图)的模型输出概率分布图(横坐标表示模型输出概率,纵坐标表示概率对应的人群的数量),显然未得病人群的概率值普遍低于得病人群的输出概率值(即正常人诊断出疾病的概率小于得病人群诊断出疾病的概率)。
竖线代表阈值。显然,图中给出了某个阈值对应的混淆矩阵,通过改变不同的阈值 

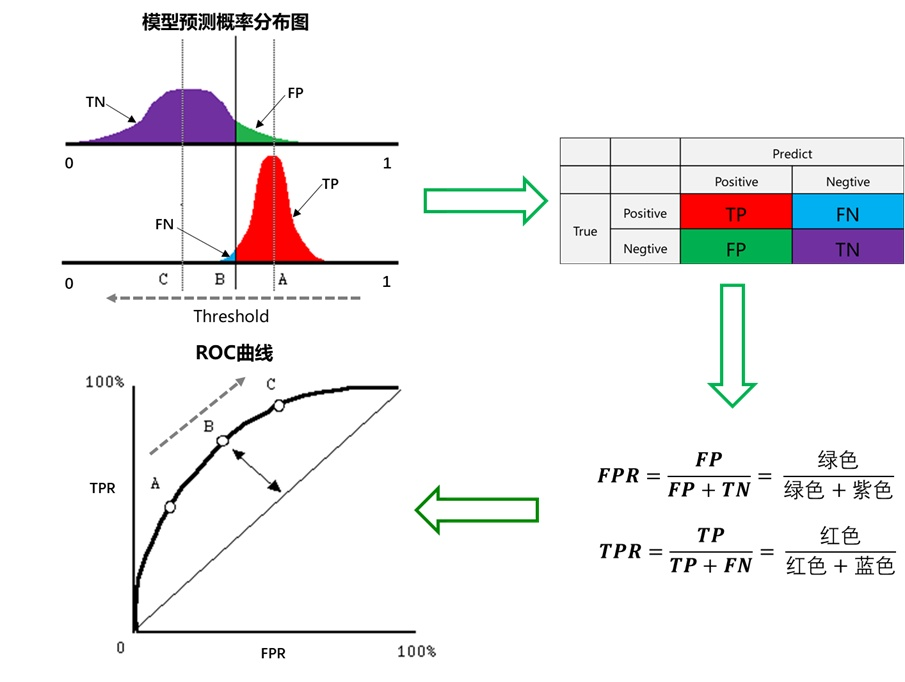
还是一开始的那幅图,假设如下就是某个医生的诊断统计图,直线代表阈值。我们遍历所有的阈值,能够在ROC平面上得到如下的ROC曲线。
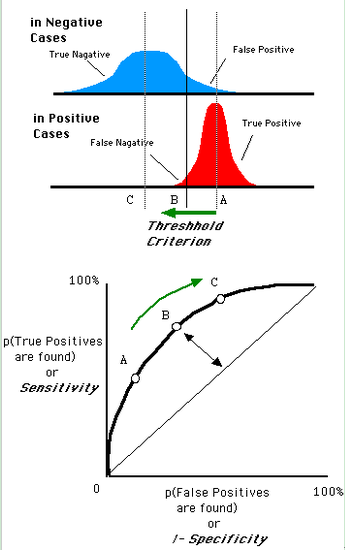
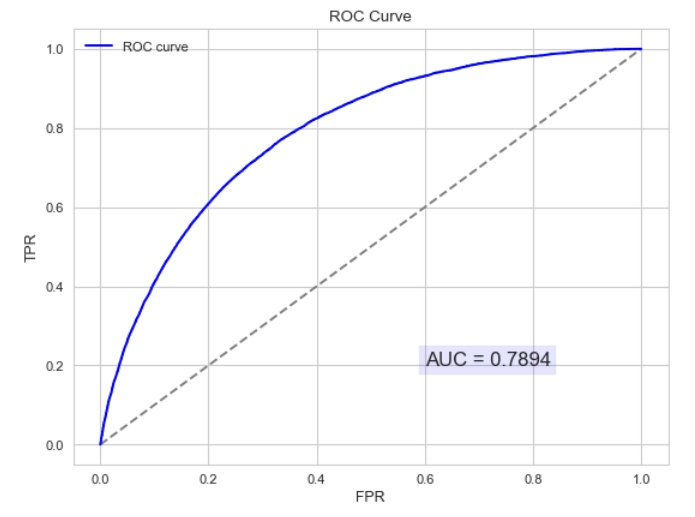
曲线距离左上角越近,证明分类器效果越好。
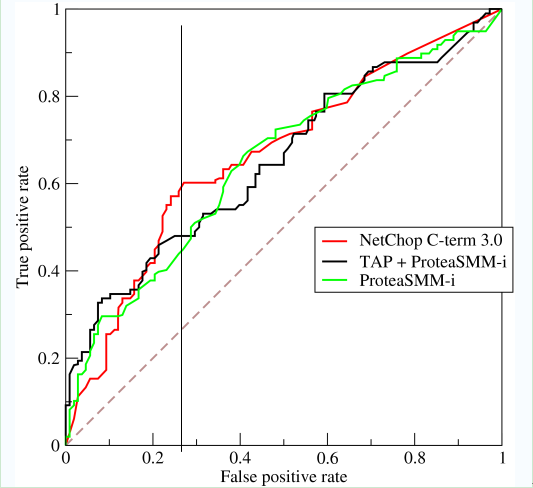
如上,是三条ROC曲线,在0.23处取一条直线。那么,在同样的低FPR=0.23的情况下,红色分类器得到更高的PTR。也就表明,ROC越往上,分类器效果越好。我们用一个标量值AUC来量化它。
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
以下为ROC曲线和AUC值得实例:
AUC的物理意义:假设分类器的输出是样本属于正类的socre(置信度),则AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率。
AUC的物理意义正样本的预测结果大于负样本的预测结果的概率。所以AUC反应的是分类器对样本的排序能力。
另外值得注意的是,AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常用AUC评价分类器性能的一个原因。
下面从一个小例子解释AUC的含义:小明一家四口,小明5岁,姐姐10岁,爸爸35岁,妈妈33岁建立一个逻辑回归分类器,来预测小明家人为成年人概率,假设分类器已经对小明的家人做过预测,得到每个人为成人的概率。
AUC更多的是关注对计算概率的排序,关注的是概率值的相对大小,与阈值和概率值的绝对大小没有关系
例子中并不关注小明是不是成人,而关注的是,预测为成人的概率的排序。
第一种方法:AUC为ROC曲线下的面积,那我们直接计算面积可得。面积为一个个小的梯形面积之和。计算的精度与阈值的精度有关。
第二种方法:根据AUC的物理意义,我们计算正样本score大于负样本的score的概率。取N*M(N为正样本数,M为负样本数)个二元组,比较score,最后得到AUC。时间复杂度为O(N*M)。
第三种方法:与第二种方法相似,直接计算正样本score大于负样本的概率。我们首先把所有样本按照score排序,依次用rank表示他们,如最大score的样本,rank=n(n=N+M),其次为n-1。那么对于正样本中rank最大的样本,rank_max,有M-1个其他正样本比他score小,那么就有(rank_max-1)-(M-1)个负样本比他score小。其次为(rank_second-1)-(M-2)。最后我们得到正样本大于负样本的概率为

时间复杂度为O(N+M)。
from sklearn.metrics import roc_auc_score
# y_test:实际的标签, dataset_pred:预测的概率值。
roc_auc_score(y_test, dataset_pred)“Classification算法指标是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3209854/blog/3132290



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



