PythonеҰӮдҪ•зҲ¬еҸ–зҢ«е’ӘзҪ‘з«ҷдәӨжҳ“ж•°жҚ®
иҝҷжңҹеҶ…е®№еҪ“дёӯе°Ҹзј–е°Ҷдјҡз»ҷеӨ§е®¶еёҰжқҘжңүе…іPythonеҰӮдҪ•зҲ¬еҸ–зҢ«е’ӘзҪ‘з«ҷдәӨжҳ“ж•°жҚ®пјҢж–Үз« еҶ…е®№дё°еҜҢдё”д»Ҙдё“дёҡзҡ„и§’еәҰдёәеӨ§е®¶еҲҶжһҗе’ҢеҸҷиҝ°пјҢйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еёҢжңӣеӨ§е®¶еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒеүҚиЁҖ
зңӢеҲ°еҸҜзҲұзҡ„зҢ«е’ӘиЎЁжғ…еҢ…пјҢжҖ»жҳҜдјҡеҝҚдёҚдҪҸ收и—ҸпјҢжҷ’йғЁеҲҶеӣҫеҰӮдёӢпјҡ

д»ҺиҝҷдёӘзҪ‘з«ҷйҮҢзҲ¬еҸ–дәҶзҢ«зҢ«е“Ғз§Қд»Ӣз»Қзҡ„ж•°жҚ®пјҢд»ҘеҸҠ 20W+ жқЎзҢ«зҢ«дәӨжҳ“ж•°жҚ®пјҢд»ҘжӯӨжқҘдәҶи§ЈдёҖдёӢеҸҜзҲұзҡ„зҢ«е’ӘгҖӮ
дәҢгҖҒж•°жҚ®иҺ·еҸ–
жү“ејҖзҢ«зҢ«дәӨжҳ“зҪ‘пјҢе…ҲзҲ¬еҸ–зҢ«е’Әе“Ғз§Қж•°жҚ®пјҢжү“ејҖйЎөйқўеҸҜд»ҘзңӢеҲ°зҢ«зҢ«е“Ғз§ҚеҲ—иЎЁпјҡ
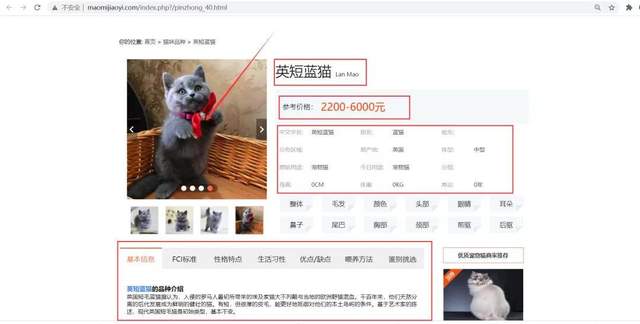
жЈҖжҹҘзҪ‘йЎөпјҢеҸҜд»ҘеҸ‘зҺ°зҪ‘йЎөз»“жһ„з®ҖеҚ•пјҢе®№жҳ“и§Јжһҗе’ҢжҸҗеҸ–ж•°жҚ®гҖӮзҲ¬иҷ«д»Јз ҒеҰӮдёӢпјҡ
import requests
import re
import csv
from lxml import etree
from tqdm import tqdm
from fake_useragent import UserAgent
# йҡҸжңәдә§з”ҹиҜ·жұӮеӨҙ
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
def random_ua(): # з”ЁдәҺйҡҸжңәеҲҮжҚўиҜ·жұӮеӨҙ
headers = {
"Accept-Encoding": "gzip",
"Accept-Language": "zh-CN",
"Connection": "keep-alive",
"Host": "www.maomijiaoyi.com",
"User-Agent": ua.random
}
return headers
def create_csv(): # еҲӣе»әдҝқеӯҳж•°жҚ®зҡ„csv
with open('./data/cat_kind.csv', 'w', newline='', encoding='utf-8') as f:
wr = csv.writer(f)
wr.writerow(['е“Ғз§Қ', 'еҸӮиҖғд»·ж ј', 'дёӯж–ҮеӯҰеҗҚ', 'еҲ«еҗҚ', 'зҘ–е…Ҳ', 'еҲҶеёғеҢәеҹҹ',
'еҺҹдә§ең°', 'дҪ“еһӢ', 'еҺҹе§Ӣз”ЁйҖ”', 'д»Ҡж—Ҙз”ЁйҖ”', 'еҲҶз»„', 'иә«й«ҳ',
'дҪ“йҮҚ', 'еҜҝе‘Ҫ', 'ж•ҙдҪ“', 'жҜӣеҸ‘', 'йўңиүІ', 'еӨҙйғЁ', 'зңјзқӣ',
'иҖіжңө', 'йј»еӯҗ', 'е°ҫе·ҙ', 'иғёйғЁ', 'йўҲйғЁ', 'еүҚй©ұ', 'еҗҺй©ұ',
'еҹәжң¬дҝЎжҒҜ', 'FCIж ҮеҮҶ', 'жҖ§ж јзү№зӮ№', 'з”ҹжҙ»д№ жҖ§', 'дјҳзӮ№/зјәзӮ№',
'е–Ӯе…»ж–№жі•', 'йүҙеҲ«жҢ‘йҖү'])
def scrape_page(url1): # иҺ·еҸ–HTMLзҪ‘йЎөжәҗд»Јз Ғ иҝ”еӣһж–Үжң¬
response = requests.get(url1, headers=random_ua())
# print(response.status_code)
response.encoding = 'utf-8'
return response.text
def get_cat_urls(html1): # иҺ·еҸ–жҜҸдёӘе“Ғз§ҚзҢ«е’ӘиҜҰжғ…йЎөurl
dom = etree.HTML(html1)
lis = dom.xpath('//div[@class="pinzhong_left"]/a')
cat_urls = []
for li in lis:
cat_url = li.xpath('./@href')[0]
cat_url = 'http://www.maomijiaoyi.com' + cat_url
cat_urls.append(cat_url)
return cat_urls
def get_info(html2): # зҲ¬еҸ–жҜҸдёӘе“Ғз§ҚзҢ«е’ӘиҜҰжғ…йЎөйҮҢзҡ„жңүе…ідҝЎжҒҜ
# е“Ғз§Қ
kind = re.findall('div class="line1">.*?<div class="name">(.*?)<span>', html2, re.S)[0]
kind = kind.replace('\r','').replace('\n','').replace('\t','')
# еҸӮиҖғд»·ж ј
price = re.findall('<div>еҸӮиҖғд»·ж јпјҡ</div>.*?<div>(.*?)</div>', html2, re.S)[0]
price = price.replace('\r', '').replace('\n', '').replace('\t', '')
# дёӯж–ҮеӯҰеҗҚ
chinese_name = re.findall('<div>дёӯж–ҮеӯҰеҗҚ:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
chinese_name = chinese_name.replace('\r', '').replace('\n', '').replace('\t', '')
# еҲ«еҗҚ
other_name = re.findall('<div>еҲ«еҗҚ:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
other_name = other_name.replace('\r', '').replace('\n', '').replace('\t', '')
# зҘ–е…Ҳ
ancestor = re.findall('<div>зҘ–е…Ҳ:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
ancestor = ancestor.replace('\r', '').replace('\n', '').replace('\t', '')
# еҲҶеёғеҢәеҹҹ
area = re.findall('<div>еҲҶеёғеҢәеҹҹ:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
area = area.replace('\r', '').replace('\n', '').replace('\t', '')
# еҺҹдә§ең°
source_area = re.findall('<div>еҺҹдә§ең°:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
source_area = source_area.replace('\r', '').replace('\n', '').replace('\t', '')
# дҪ“еһӢ
body_size = re.findall('<div>дҪ“еһӢ:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
body_size = body_size.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# еҺҹе§Ӣз”ЁйҖ”
source_use = re.findall('<div>еҺҹе§Ӣз”ЁйҖ”:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
source_use = source_use.replace('\r', '').replace('\n', '').replace('\t', '')
# д»Ҡж—Ҙз”ЁйҖ”
today_use = re.findall('<div>д»Ҡж—Ҙз”ЁйҖ”:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
today_use = today_use.replace('\r', '').replace('\n', '').replace('\t', '')
# еҲҶз»„
group = re.findall('<div>еҲҶз»„:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
group = group.replace('\r', '').replace('\n', '').replace('\t', '')
# иә«й«ҳ
height = re.findall('<div>иә«й«ҳ:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
height = height.replace('\r', '').replace('\n', '').replace('\t', '')
# дҪ“йҮҚ
weight = re.findall('<div>дҪ“йҮҚ:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
weight = weight.replace('\r', '').replace('\n', '').replace('\t', '')
# еҜҝе‘Ҫ
lifetime = re.findall('<div>еҜҝе‘Ҫ:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
lifetime = lifetime.replace('\r', '').replace('\n', '').replace('\t', '')
# ж•ҙдҪ“
entirety = re.findall('<div>ж•ҙдҪ“</div>.*?<!-- йЎөйқўе°ҸжҠҳи§’ -->.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
entirety = entirety.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# жҜӣеҸ‘
hair = re.findall('<div>жҜӣеҸ‘</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
hair = hair.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# йўңиүІ
color = re.findall('<div>йўңиүІ</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
color = color.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# еӨҙйғЁ
head = re.findall('<div>еӨҙйғЁ</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
head = head.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# зңјзқӣ
eye = re.findall('<div>зңјзқӣ</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
eye = eye.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# иҖіжңө
ear = re.findall('<div>иҖіжңө</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
ear = ear.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# йј»еӯҗ
nose = re.findall('<div>йј»еӯҗ</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
nose = nose.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# е°ҫе·ҙ
tail = re.findall('<div>е°ҫе·ҙ</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
tail = tail.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# иғёйғЁ
chest = re.findall('<div>иғёйғЁ</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
chest = chest.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# йўҲйғЁ
neck = re.findall('<div>йўҲйғЁ</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
neck = neck.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# еүҚй©ұ
font_foot = re.findall('<div>еүҚй©ұ</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
font_foot = font_foot.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# еҗҺй©ұ
rear_foot = re.findall('<div>еүҚй©ұ</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
rear_foot = rear_foot.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# дҝқеӯҳеүҚйқўзҢ«зҢ«зҡ„еҗ„з§Қжңүе…ідҝЎжҒҜ
cat = [kind, price, chinese_name, other_name, ancestor, area, source_area,
body_size, source_use, today_use, group, height, weight, lifetime,
entirety, hair, color, head, eye, ear, nose, tail, chest, neck, font_foot, rear_foot]
# жҸҗеҸ–ж Үзӯҫж ҸдҝЎжҒҜпјҲеҹәжң¬дҝЎжҒҜ-FCIж ҮеҮҶ-жҖ§ж јзү№зӮ№-з”ҹжҙ»д№ жҖ§-дјҳзјәзӮ№-е–Ӯе…»ж–№жі•-йүҙеҲ«жҢ‘йҖүпјү
html2 = etree.HTML(html2)
labs = html2.xpath('//div[@class="property_list"]/div')
for lab in labs:
text1 = lab.xpath('string(.)')
text1 = text1.replace('\n','').replace('\t','').replace('\r','').replace(' ','')
cat.append(text1)
return cat
def write_to_csv(data): # дҝқеӯҳж•°жҚ® иҝҪеҠ еҶҷе…Ҙ
with open('./data/cat_kind.csv', 'a+', newline='', encoding='utf-8') as fn:
wr = csv.writer(fn)
wr.writerow(data)
if __name__ == '__main__':
# еҲӣе»әдҝқеӯҳж•°жҚ®зҡ„csv
create_csv()
# зҢ«е’Әе“Ғз§ҚйЎөйқўurl
base_url = 'http://www.maomijiaoyi.com/index.php?/pinzhongdaquan_5.html'
# иҺ·еҸ–е“Ғз§ҚйЎөйқўдёӯзҡ„жүҖжңүurl
html = scrape_page(base_url)
urls = get_cat_urls(html)
# иҝӣеәҰжқЎеҸҜи§ҶеҢ–иҝҗиЎҢжғ…еҶө е°ұдёҚжү“еҚ°дёңиҘҝжқҘзңӢдәҶ
pbar = tqdm(urls)
# ејҖе§ӢзҲ¬еҸ–
for url in pbar:
text = scrape_page(url)
info = get_info(text)
write_to_csv(info)иҝҗиЎҢж•ҲжһңеҰӮдёӢпјҡ
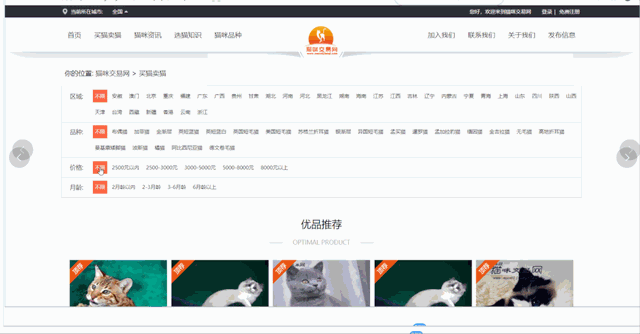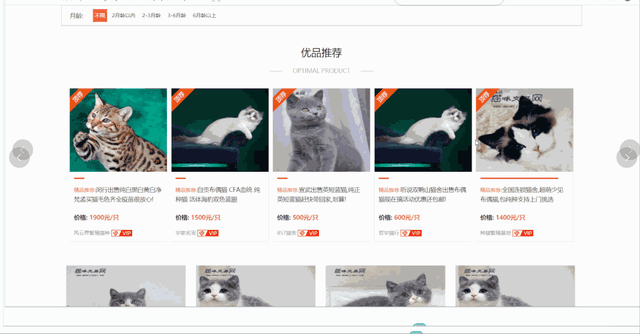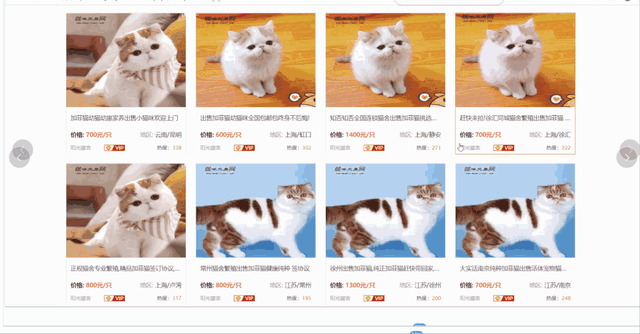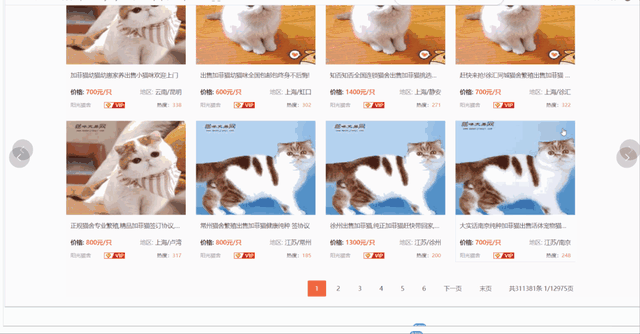
зҲ¬еҸ–жӣҙиҜҰз»Ҷзҡ„ж•°жҚ®йңҖиҰҒиҝӣе…ҘиҜҰжғ…йЎөпјҢеҢ…еҗ«е•Ҷ家дҝЎжҒҜгҖҒзҢ«е’Әе“Ғз§ҚгҖҒзҢ«йҫ„гҖҒд»·ж јгҖҒж ҮйўҳгҖҒеңЁе”®еҸӘж•°гҖҒйў„йҳІзӯүдҝЎжҒҜгҖӮ

зңӢеҗ„з§ҚзҢ«е’Әзҡ„дҪ“еһӢеҲҶеёғ

ж©ҳзҢ«жҳҜдё–з•Ңеҗ„ең°йғҪжңүзҡ„пјҢдёҚ愧жҳҜжҲ‘еӨ§ж©ҳзҢ«гҖӮдҝ—иҜқиҜҙ "еҚҒдёӘж©ҳзҢ«д№қдёӘиғ–иҝҳжңүдёҖдёӘеҺӢеЎҢзӮ•"гҖӮж©ҳзҢ«жҜ”иө·е…¶д»–иҠұиүІзҡ„зҢ«е’Әжӣҙе–ңж¬ўеҗғдёңиҘҝпјҢе®ғ们зҡ„йЈҹж¬ІеҫҲеҘҪпјҢиғҪжӣҙеҘҪең°з”ҹеӯҳпјҢеҸҜиғҪиҝҷд№ҹжҳҜж©ҳзҢ«еңЁдё–з•ҢиҢғеӣҙйғҪжңүзҡ„еҺҹеӣ еҗ§гҖӮеҸҜе®ғеҚҙжҳҜе°ҸеһӢзҢ«пјҢж©ҳзҢ«е°Ҹж—¶еҖҷйўңеҖјдёҖиҲ¬жҢәй«ҳпјҢзңӢиө·жқҘе°Ҹе°Ҹзҡ„дёҖеҸӘпјҢеҸҲе«©еҸҲеҸҜзҲұзҡ„пјҢдҪҶзӯүж©ҳзҢ«й•ҝеӨ§д»ҘеҗҺпјҢжүҚзңҹжӯЈең°ж„ҸиҜҶеҲ°д»Җд№ҲжҳҜ "ж©ҳи¶іиҪ»йҮҚ"гҖӮ

ж©ҳзҢ«зҡ„дәӨжҳ“ж•°йҮҸжңҖеӨҡе‘ҖпјҢд№ӢеүҚд№ҹжҸҗеҲ°ж©ҳзҢ«дё–з•Ңеҗ„ең°йғҪжңүпјҢд»ҺиҝҷйҮҢд№ҹеҸҜд»ҘзңӢеҲ°ж©ҳзҢ«ж•°йҮҸжңҖеӨҡгҖӮе…¶ж¬ЎжҳҜе’–е•ЎзҢ«пјҢеёғеҒ¶зҢ«пјҢиӢұзҹӯи“қзҷҪзҢ«зӯүгҖӮ
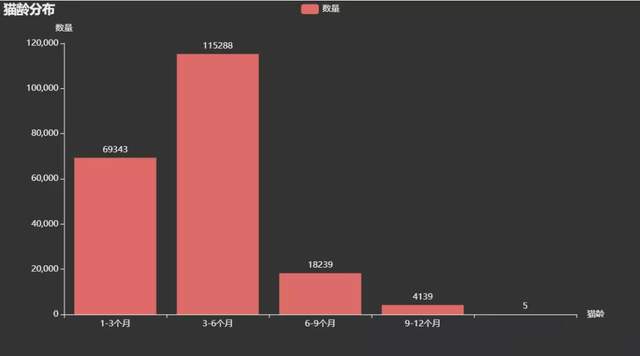
е”®еҚ–зҡ„зҢ«е’ӘзҢ«йҫ„дё»иҰҒеңЁ1-6дёӘжңҲпјҢйғҪжҳҜеҲҡеҮәз”ҹиҝҳжңӘж»ЎеҚҠеІҒзҡ„е°ҸзҢ«е’Әе‘ҖгҖӮиҝҷж—¶еҖҷзҡ„е°ҸзҢ«е’Әеә”иҜҘеҫҲеҸҜзҲұеҗ§пјҢзӯүеҫ…жңүзјҳзҡ„дё»дәәжҠҠе®ғеёҰеӣһ家гҖӮ
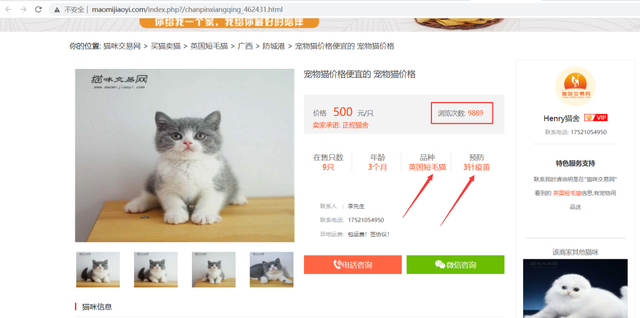
жңҖеҗҺжқҘзңӢдёҖдёӢзҪ‘з«ҷйҮҢд»·ж јжңҖиҙөзҡ„зҢ«е’Әе’ҢжөҸи§Ҳж¬Ўж•°жңҖеӨҡзҡ„зҢ«е’Ә
import pandas as pd
df = pd.read_excel('еӨ„зҗҶеҗҺж•°жҚ®.xlsx')
print(df.info())
df1 = df.sort_values(by='жөҸи§Ҳж¬Ўж•°', ascending=False)
print(df1.iloc[:3, ::].values)
print('----------------------------------------------------------')
df2 = df.sort_values(by='д»·ж ј', ascending=False)
print(df2.iloc[:3, ::].values)# жөҸи§Ҳж¬Ўж•°жңҖеӨҡзҡ„
http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_441879.html
http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_462431.html
http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_455366.html
![]()
еҸҚи§ӮжөҸи§Ҳж¬Ўж•°жҺ’第дәҢгҖҒ第дёүзҡ„пјҢд»·ж јдҫҝе®ңдёҚе°‘пјҢйў„йҳІйғҪжү“дәҶ3й’Ҳз–«иӢ—пјҢеңЁе”®еҸӘж•°иҝҳжҜ”иҫғе……иЈ•пјҢиҝҳжҜ”第дёҖеҸҜзҲұеҘҪеӨҡпјҲдёӘдәәж„ҹи§үпјүгҖӮ
# д»·ж јжңҖиҙөзҡ„еҰӮдёӢ
http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_265770.html
http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_281910.html
http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_230417.html
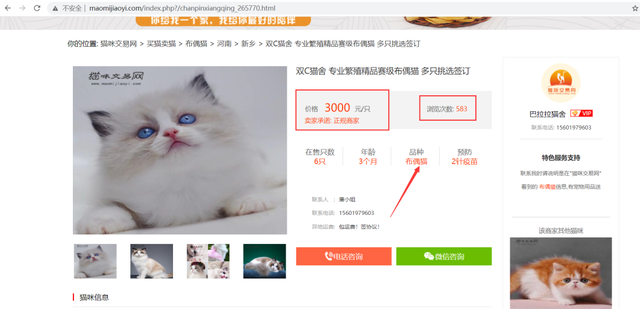

д»·ж јжңҖиҙөзҡ„еҸ‘зҺ°еқҮдёә 3000 е…ғзҡ„еёғеҒ¶зҢ«гҖӮжҹҘйҳ…иө„ж–ҷеҸ‘зҺ°пјҢеёғеҒ¶зҢ«пјҢеӨ§еһӢзҢ«е’ӘпјҢдёҚд»…иҙӯд№°зҡ„ж—¶еҖҷд»·ж јй«ҳжҳӮпјҢйҘІе…»жҲҗжң¬д№ҹжҜ”иҫғй«ҳпјҢеӣ дёәйЈҹйҮҸе’ҢиҝҗеҠЁйҮҸйғҪжҜ”иҫғеӨ§пјҢиҖҢдё”зҫҺе®№зӯүзӣёе…іиҙ№з”Ёд№ҹдјҡй«ҳдёҖдәӣгҖӮ
дёҠиҝ°е°ұжҳҜе°Ҹзј–дёәеӨ§е®¶еҲҶдә«зҡ„PythonеҰӮдҪ•зҲ¬еҸ–зҢ«е’ӘзҪ‘з«ҷдәӨжҳ“ж•°жҚ®дәҶпјҢеҰӮжһңеҲҡеҘҪжңүзұ»дјјзҡ„з–‘жғ‘пјҢдёҚеҰЁеҸӮз…§дёҠиҝ°еҲҶжһҗиҝӣиЎҢзҗҶи§ЈгҖӮеҰӮжһңжғізҹҘйҒ“жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





