这期内容当中小编将会给大家带来有关如何使用Nebula Graph Exchange将数据从Neo4j导入到Nebula Graph Database,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
下面主要讲述如何使用数据导入工具 Nebula Graph Exchange 将数据从 Neo4j 导入到 Nebula Graph Database。在讲述如何实操数据导入之前,我们先来了解下 Nebula Graph 内部是如何实现这个导入功能的。
我们这个导入工具名字是 Nebula Graph Exchange,采用 Spark 作为导入平台,来支持海量数据的导入和保障性能。Spark 本身提供了不错的抽象——DataFrame,使得可以轻松支持多种数据源。在 DataFrame 的支持下,添加新的数据源只需提供配置文件读取的代码和返回 DataFrame 的 Reader 类,即可支持新的数据源。
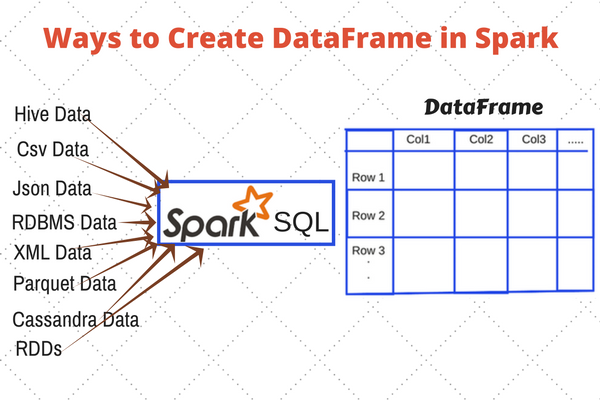
DataFrame 可以视为一种分布式存表格。DataFrame 可以存储在多个节点的不同分区中,多个分区可以存储在不同的机器上,从而支持并行操作。Spark 还提供了一套简洁的 API 使用户轻松操作 DataFrame 如同操作本地数据集一般。现在大多数数据库提供直接将数据导出成 DataFrame 功能,即使某个数据库并未提供此功能也可以通过数据库 driver 手动构建 DataFrame。
Nebula Graph Exchange 将数据源的数据处理成 DataFrame 之后,会遍历它的每一行,根据配置文件中 fields 的映射关系,按列名获取对应的值。在遍历 batchSize 个行之后,Exchange 会将获取的数据一次性写入到 Nebula Graph 中。目前,Exchange 是通过生成 nGQL 语句再由 Nebula Client 异步写入数据,下一步会支持直接导出 Nebula Graph 底层存储的 sst 文件,以获取更好的性能。接下来介绍一下 Neo4j 数据源导入的具体实现。
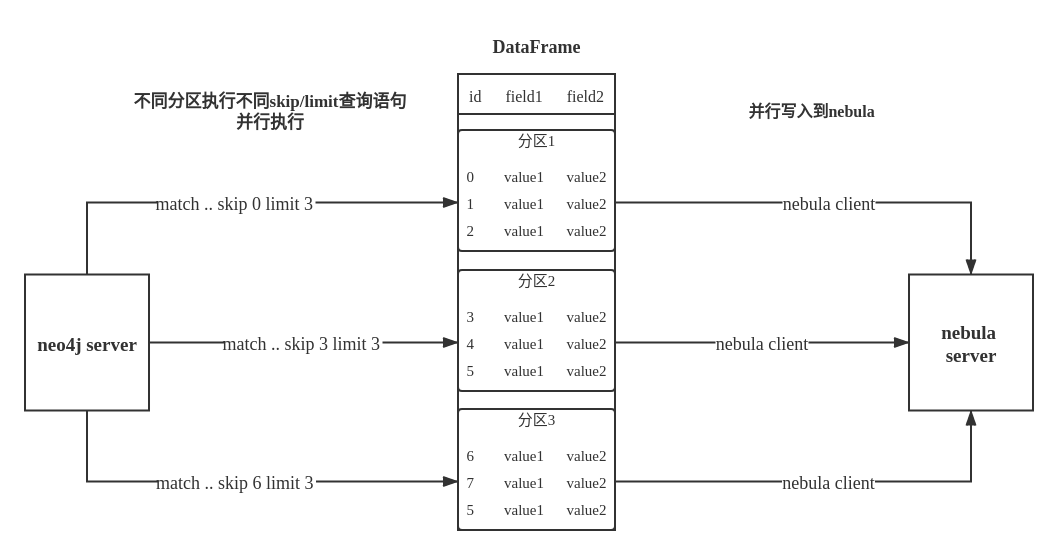
虽然 Neo4j 官方提供了可将数据直接导出为 DataFrame 的库,但使用它读取数据难以满足断点续传的需求,我们未直接使用这个库,而是使用 Neo4j 官方的 driver 实现数据读取。Exchange 通过在不同分区调取 Neo4j driver 执行不同 skip 和 limit 的 Cypher 语句,将数据分布在不同的分区,来获取更好的性能。这个分区数量由配置项 partition 指定。
Exchange 中的 Neo4jReader 类会先将用户配置中的 exec Cypher 语句,return 后边的语句替换成 count(*) 执行获取数据总量,再根据分区数计算每个分区的起始偏移量和大小。这里如果用户配置了 check_point_path 目录,会读取目录中的文件,如果处于续传的状态,Exchange 会计算出每个分区应该的偏移量和大小。然后每个分区在 Cypher 语句后边添加不同的 skip 和 limit,调用 driver 执行。最后将返回的数据处理成 DataFrame 就完成了 Neo4j 的数据导入。
过程如下图所示:
我们这里导入演示的系统环境如下:
cpu name:Intel(R) Xeon(R) CPU E5-2697 v3 @ 2.60GHz
cpu cores:14
memory size:251G
软件环境如下:
Neo4j:3.5.20 社区版
Nebula graph:docker-compose 部署,默认配置
Spark:单机版,版本为 2.4.6 pre-build for hadoop2.7
由于 Nebula Graph 是强 schema 数据库,数据导入前需先进行创建 Space,建 Tag 和 Edge 的 schema,具体的语法可以参考这里。
这里建了名为 test 的 Space,副本数为 1。这里创建了两种 Tag 分别为 tagA 和 tagB,均含有 4 个属性的点类型,此外,还创建一种名为 edgeAB 的边类型,同样含有 4 个属性。具体的 nGQL 语句如下所示:
# 创建图空间
CREATE SPACE test(replica_factor=1);
# 选择图空间 test
USE test;
# 创建标签 tagA
CREATE TAG tagA(idInt int, idString string, tboolean bool, tdouble double);
# 创建标签 tagB
CREATE TAG tagB(idInt int, idString string, tboolean bool, tdouble double);
# 创建边类型 edgeAB
CREATE EDGE edgeAB(idInt int, idString string, tboolean bool, tdouble double);同时向 Neo4j 导入 Mock 数据——标签为 tagA 和 tagB 的点,数量总共为 100 万,并且导入了连接 tagA 和 tagB 类型点边类型为 edgeAB 的边,共 1000 万个。另外需要注意的是,从 Neo4j 导出的数据在 Nebula Graph 中必须存在属性,且数据对应的类型要同 Nebula Graph 一致。
最后为了提升向 Neo4j 导入 Mock 数据的效率和 Mock 数据在 Neo4j 中的读取效率,这里为 tagA 和 tagB 的 idInt 属性建了索引。关于索引需要注意 Exchange 并不会将 Neo4j 中的索引、约束等信息导入到 Nebula Graph 中,所以需要用户在执行数据写入在 Nebula Graph 之后,自行创建索引和 REBUILD 索引(为已有数据建立索引)。
接下来就可以将 Neo4j 数据导入到 Nebula Graph 中了,首先我们需要下载和编译打包项目,项目在 nebula-java 这个仓库下 tools/exchange 文件夹中。可执行如下命令:
git clone https://github.com/vesoft-inc/nebula-java.git
cd nebula-java/tools/exchange
mvn package -DskipTests然后就可以看到 target/exchange-1.0.1.jar 这个文件。
接下来编写配置文件,配置文件的格式为:HOCON(Human-Optimized Config Object Notation),可以基于 src/main/resources/server_application.conf 文件的基础上进行更改。首先对 nebula 配置项下的 address、user、pswd 和 space 进行配置,测试环境均为默认配置,所以这里不需要额外的修改。然后进行 tags 配置,需要 tagA 和 tagB 的配置,这里仅展示 tagA 配置,tagB 和 tagA 配置相同。
{
# ======neo4j连接设置=======
name: tagA
# 必须和 Nebula Graph 的中 tag 名字一致,需要在 Nebula Graph 中事先建好 tag
server: "bolt://127.0.0.1:7687"
# neo4j 的地址配置
user: neo4j
# neo4j 的用户名
password: neo4j
# neo4j 的密码
encryption: false
# (可选): 传输是否加密,默认值为 false
database: graph.db
# (可选): neo4j database 名称,社区版不支持
# ======导入设置============
type: {
source: neo4j
# 还支持 PARQUET、ORC、JSON、CSV、HIVE、MYSQL、PULSAR、KAFKA...
sink: client
# 写入 Nebula Graph 的方式,目前仅支持 client,未来会支持直接导出 Nebula Graph 底层数据库文件
}
nebula.fields: [idInt, idString, tdouble, tboolean]
fields : [idInt, idString, tdouble, tboolean]
# 映射关系 fields,上方为 nebula 的属性名,下方为 neo4j 的属性名,一一对应
# 映射关系的配置是 List 而不是 Map,是为了保持 fields 的顺序,未来直接导出 nebula 底层存储文件时需要
vertex: idInt
# 作为 nebula vid 的 neo4j field,类型需要是整数(long or int)。
partition: 10
# 分区数
batch: 2000
# 一次写入 nebula 多少数据
check_point_path: "file:///tmp/test"
# (可选): 保存导入进度信息的目录,用于断点续传
exec: "match (n:tagA) return n.idInt as idInt, n.idString as idString, n.tdouble as tdouble, n.tboolean as tboolean order by n.idInt"
}边的设置大部分与点的设置无异,但由于边在 Nebula Graph 中有起点的 vid 和终点的 vid 标识,所以这里需要指定作为边起点 vid 的域和作为边终点 vid 的域。
下面给出边的特别配置。
source: {
field: a.idInt
# policy: "hash"
}
# 起点的 vid 设置
target: {
field: b.idInt
# policy: "uuid"
}
# 终点的 vid 设置
ranking: idInt
# (可选): 作为 rank 的 field
partition: 1
# 这里分区数设置为 1,原因在后边
exec: "match (a:tagA)-[r:edgeAB]->(b:tagB) return a.idInt, b.idInt, r.idInt as idInt, r.idString as idString, r.tdouble as tdouble, r.tboolean as tboolean order by id(r)"点的 vertex 和边的 source、target 配置项下都可以设置 policy hash/uuid,它可以将类型为字符串的域作为点的 vid,通过 hash/uuid 函数将字符串映射成整数。
上面的例子由于作为点的 vid 为整数,所以并不需要 policy 的设置。hash/uuid的 区别请看这里。
Cypher 标准中如果没有 order by 约束的话就不能保证每次查询结果的排序一致,虽然看起来即便不加 order by Neo4j 返回的结果顺序也是不变的,但为了防止可能造成的导入时数据丢失,还是强烈建议在 Cypher 语句中加入 order by,虽然这会增加导入的时间。为了提升导入效率, order by 语句最好选取有索引的属性作为排序的属性。如果没有索引,也可观察默认的排序,选择合适的排序属性以提高效率。如果默认的排序找不到规律,可以使用点/关系的 ID 作为排序属性,并且将 partition 的值尽量设小,减少 Neo4j 的排序压力,本文中边 edgeAB 的 partition 就设置为 1。
另外 Nebula Graph 在创建点和边时会将 ID 作为唯一主键,如果主键已存在则会覆盖该主键中的数据。所以假如将某个 Neo4j 属性值作为 Nebula Graph 的 ID,而这个属性值在 Neo4j 中是有重复的,就会导致“重复 ID”对应的数据有且只有一条会存入 Nebula Graph 中,其它的则会被覆盖掉。由于数据导入过程是并发地往 Nebula Graph 中写数据,最终保存的数据并不能保证是 Neo4j 中最新的数据。
这里还要留意下断点续传功能,在断点和续传之间,数据库不应该改变状态,如添加数据或删除数据,且 partition 数量也不能更改,否则可能会有数据丢失。
最后由于 Exchange 需要在不同分区执行不同 skip 和 limit 的 Cypher 语句,所以用户提供的 Cypher 语句不能含有 skip 和 limit 语句。
接下来就可以运行 Exchange 程序导数据了,执行如下命令:
$SPARK_HOME/bin/spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master "local[10]" target/exchange-1.0.1.jar -c /path/to/conf/neo4j_application.conf在上述这些配置下,导入 100 万个点用时 13s,导入 1000 万条边用时 213s,总用时是 226s。
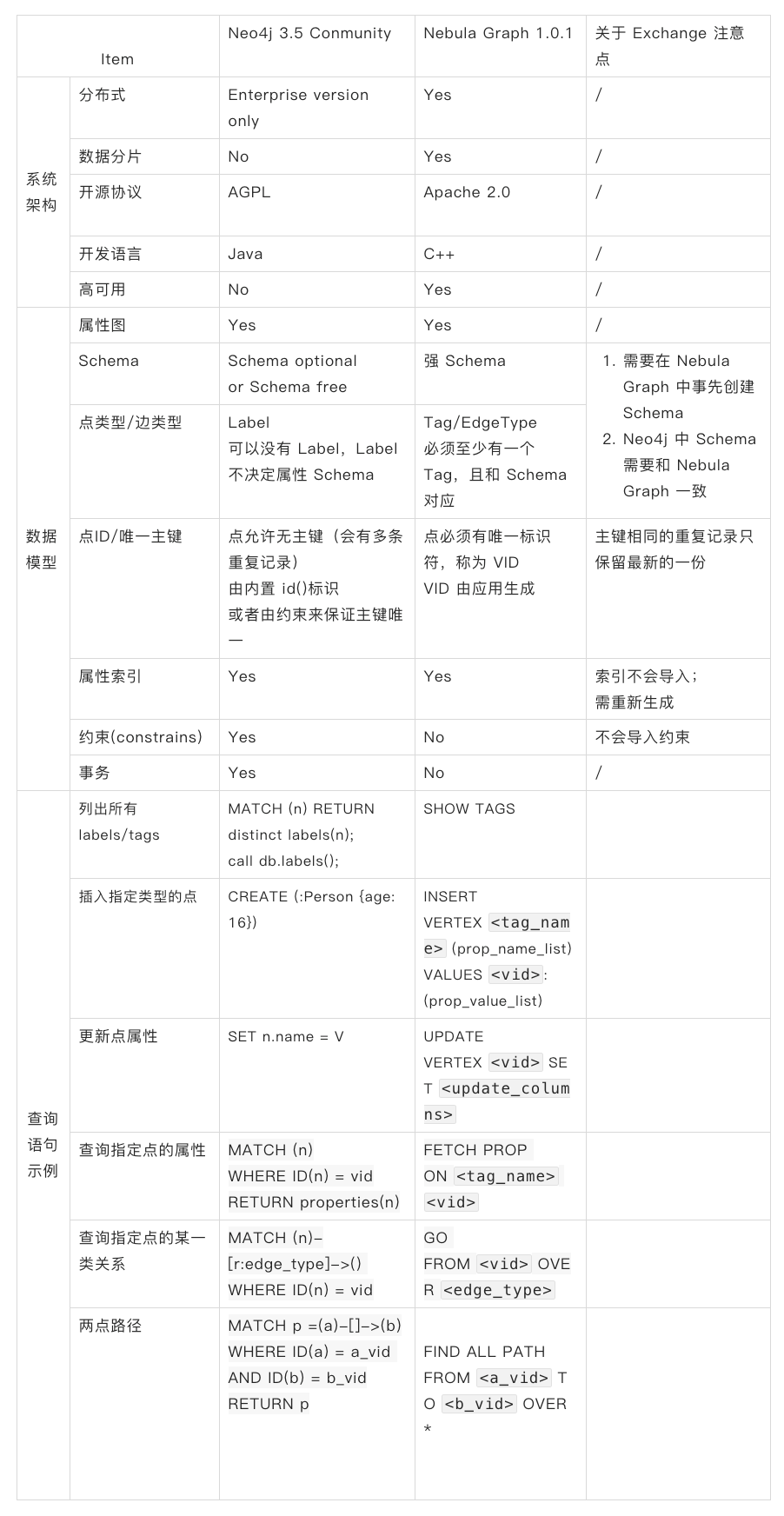
Neo4j 和 Nebula Graph 在系统架构、数据模型和访问方式上都有一些差异,下表列举了常见的异同
上述就是小编为大家分享的如何使用Nebula Graph Exchange将数据从Neo4j导入到Nebula Graph Database了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4169309/blog/4572328



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



