иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іжҖҺд№ҲзңӢжҮӮSparkзҡ„еҹәжң¬еҺҹзҗҶпјҢж–Үз« еҶ…е®№иҙЁйҮҸиҫғй«ҳпјҢеӣ жӯӨе°Ҹзј–еҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҜ№зӣёе…ізҹҘиҜҶжңүдёҖе®ҡзҡ„дәҶи§ЈгҖӮ
дёҖпјҢSparkдјҳеҠҝзү№зӮ№
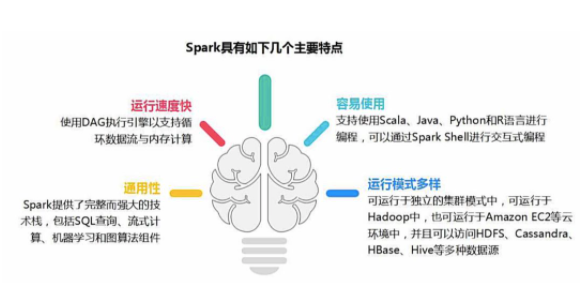
дҪңдёәеӨ§ж•°жҚ®и®Ўз®—жЎҶжһ¶MapReduceзҡ„继任иҖ…пјҢSparkе…·еӨҮд»ҘдёӢдјҳеҠҝзү№жҖ§гҖӮ
1пјҢй«ҳж•ҲжҖ§
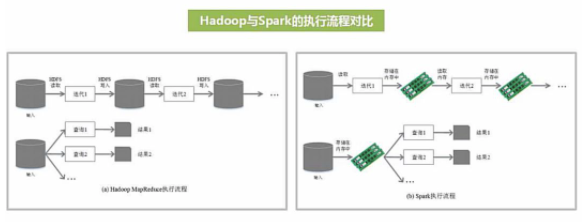
дёҚеҗҢдәҺMapReduceе°Ҷдёӯй—ҙи®Ўз®—з»“жһңж”ҫе…ҘзЈҒзӣҳдёӯпјҢSparkйҮҮз”ЁеҶ…еӯҳеӯҳеӮЁдёӯй—ҙи®Ўз®—з»“жһңпјҢеҮҸе°‘дәҶиҝӯд»Јиҝҗз®—зҡ„зЈҒзӣҳIOпјҢ并йҖҡиҝҮ并иЎҢи®Ўз®—DAGеӣҫзҡ„дјҳеҢ–пјҢеҮҸе°‘дәҶдёҚеҗҢд»»еҠЎд№Ӣй—ҙзҡ„дҫқиө–пјҢйҷҚдҪҺдәҶ延иҝҹзӯүеҫ…ж—¶й—ҙгҖӮеҶ…еӯҳи®Ўз®—дёӢпјҢSpark жҜ” MapReduce еҝ«100еҖҚгҖӮ
2пјҢжҳ“з”ЁжҖ§
дёҚеҗҢдәҺMapReduceд»…ж”ҜжҢҒMapе’ҢReduceдёӨз§Қзј–зЁӢз®—еӯҗпјҢSparkжҸҗдҫӣдәҶи¶…иҝҮ80з§ҚдёҚеҗҢзҡ„Transformationе’ҢActionз®—еӯҗпјҢеҰӮmap,reduce,filter,groupByKey,sortByKey,foreachзӯүпјҢ并且йҮҮз”ЁеҮҪж•°ејҸзј–зЁӢйЈҺж јпјҢе®һзҺ°зӣёеҗҢзҡ„еҠҹиғҪйңҖиҰҒзҡ„д»Јз ҒйҮҸжһҒеӨ§зј©е°ҸгҖӮ

3пјҢйҖҡз”ЁжҖ§
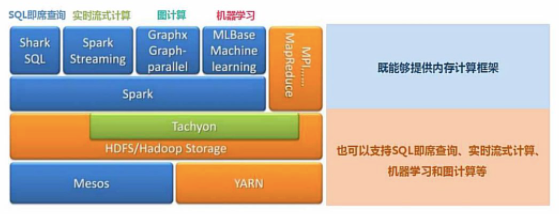
SparkжҸҗдҫӣдәҶз»ҹдёҖзҡ„и§ЈеҶіж–№жЎҲгҖӮSparkеҸҜд»Ҙз”ЁдәҺжү№еӨ„зҗҶгҖҒдәӨдә’ејҸжҹҘиҜўпјҲSpark SQLпјүгҖҒе®һж—¶жөҒеӨ„зҗҶпјҲSpark StreamingпјүгҖҒжңәеҷЁеӯҰд№ пјҲSpark MLlibпјүе’Ңеӣҫи®Ўз®—пјҲGraphXпјүгҖӮ
иҝҷдәӣдёҚеҗҢзұ»еһӢзҡ„еӨ„зҗҶйғҪеҸҜд»ҘеңЁеҗҢдёҖдёӘеә”з”Ёдёӯж— зјқдҪҝз”ЁгҖӮиҝҷеҜ№дәҺдјҒдёҡеә”з”ЁжқҘиҜҙпјҢе°ұеҸҜдҪҝз”ЁдёҖдёӘе№іеҸ°жқҘиҝӣиЎҢдёҚеҗҢзҡ„е·ҘзЁӢе®һзҺ°пјҢеҮҸе°‘дәҶдәәеҠӣејҖеҸ‘е’Ңе№іеҸ°йғЁзҪІжҲҗжң¬гҖӮ
4пјҢе…је®№жҖ§
SparkиғҪеӨҹи·ҹеҫҲеӨҡејҖжәҗе·ҘзЁӢе…је®№дҪҝз”ЁгҖӮеҰӮSparkеҸҜд»ҘдҪҝз”ЁHadoopзҡ„YARNе’ҢApache MesosдҪңдёәе®ғзҡ„иө„жәҗз®ЎзҗҶе’Ңи°ғеәҰеҷЁпјҢ并且SparkеҸҜд»ҘиҜ»еҸ–еӨҡз§Қж•°жҚ®жәҗпјҢеҰӮHDFSгҖҒHBaseгҖҒMySQLзӯүгҖӮ
дәҢпјҢSparkеҹәжң¬жҰӮеҝө
RDDпјҡжҳҜеј№жҖ§еҲҶеёғејҸж•°жҚ®йӣҶпјҲResilient Distributed Datasetпјүзҡ„з®Җз§°пјҢжҳҜеҲҶеёғејҸеҶ…еӯҳзҡ„дёҖдёӘжҠҪиұЎжҰӮеҝөпјҢжҸҗдҫӣдәҶдёҖз§Қй«ҳеәҰеҸ—йҷҗзҡ„е…ұдә«еҶ…еӯҳжЁЎеһӢгҖӮ
DAGпјҡжҳҜDirected Acyclic GraphпјҲжңүеҗ‘ж— зҺҜеӣҫпјүзҡ„з®Җз§°пјҢеҸҚжҳ RDDд№Ӣй—ҙзҡ„дҫқиө–е…ізі»гҖӮ
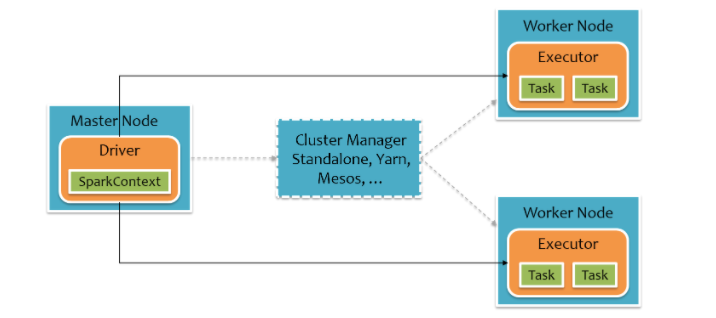
Driver ProgramпјҡжҺ§еҲ¶зЁӢеәҸпјҢиҙҹиҙЈдёәApplicationжһ„е»әDAGеӣҫгҖӮ
Cluster ManagerпјҡйӣҶзҫӨиө„жәҗз®ЎзҗҶдёӯеҝғпјҢиҙҹиҙЈеҲҶй…Қи®Ўз®—иө„жәҗгҖӮ
Worker Nodeпјҡе·ҘдҪңиҠӮзӮ№пјҢиҙҹиҙЈе®ҢжҲҗе…·дҪ“и®Ўз®—гҖӮ
ExecutorпјҡжҳҜиҝҗиЎҢеңЁе·ҘдҪңиҠӮзӮ№пјҲWorker NodeпјүдёҠзҡ„дёҖдёӘиҝӣзЁӢпјҢиҙҹиҙЈиҝҗиЎҢTaskпјҢ并дёәеә”з”ЁзЁӢеәҸеӯҳеӮЁж•°жҚ®гҖӮ
Applicationпјҡз”ЁжҲ·зј–еҶҷзҡ„Sparkеә”з”ЁзЁӢеәҸпјҢдёҖдёӘApplicationеҢ…еҗ«еӨҡдёӘJobгҖӮ
JobпјҡдҪңдёҡпјҢдёҖдёӘJobеҢ…еҗ«еӨҡдёӘRDDеҸҠдҪңз”ЁдәҺзӣёеә”RDDдёҠзҡ„еҗ„з§Қж“ҚдҪңгҖӮ
Stageпјҡйҳ¶ж®өпјҢжҳҜдҪңдёҡзҡ„еҹәжң¬и°ғеәҰеҚ•дҪҚпјҢдёҖдёӘдҪңдёҡдјҡеҲҶдёәеӨҡз»„д»»еҠЎпјҢжҜҸз»„д»»еҠЎиў«з§°дёәвҖңйҳ¶ж®өвҖқгҖӮ
Taskпјҡд»»еҠЎпјҢиҝҗиЎҢеңЁExecutorдёҠзҡ„е·ҘдҪңеҚ•е…ғпјҢжҳҜExecutorдёӯзҡ„дёҖдёӘзәҝзЁӢгҖӮ
жҖ»з»“пјҡApplicationз”ұеӨҡдёӘJobз»„жҲҗпјҢJobз”ұеӨҡдёӘStageз»„жҲҗпјҢStageз”ұеӨҡдёӘTaskз»„жҲҗгҖӮStageжҳҜдҪңдёҡи°ғеәҰзҡ„еҹәжң¬еҚ•дҪҚгҖӮ

дёүпјҢSparkжһ¶жһ„и®ҫи®Ў
SparkйӣҶзҫӨз”ұDriver, Cluster ManagerпјҲStandalone,Yarn жҲ– MesosпјүпјҢд»ҘеҸҠWorker Nodeз»„жҲҗгҖӮеҜ№дәҺжҜҸдёӘSparkеә”з”ЁзЁӢеәҸпјҢWorker NodeдёҠеӯҳеңЁдёҖдёӘExecutorиҝӣзЁӢпјҢExecutorиҝӣзЁӢдёӯеҢ…жӢ¬еӨҡдёӘTaskзәҝзЁӢгҖӮ
еҜ№дәҺpyspark,дёәдәҶдёҚз ҙеқҸSparkе·Іжңүзҡ„иҝҗиЎҢж—¶жһ¶жһ„пјҢSparkеңЁеӨ–еӣҙеҢ…иЈ…дёҖеұӮPython APIгҖӮеңЁDriverз«ҜпјҢеҖҹеҠ©Py4jе®һзҺ°Pythonе’ҢJavaзҡ„дәӨдә’пјҢиҝӣиҖҢе®һзҺ°йҖҡиҝҮPythonзј–еҶҷSparkеә”з”ЁзЁӢеәҸгҖӮеңЁExecutorз«ҜпјҢеҲҷдёҚйңҖиҰҒеҖҹеҠ©Py4jпјҢеӣ дёәExecutorз«ҜиҝҗиЎҢзҡ„TaskйҖ»иҫ‘жҳҜз”ұDriverеҸ‘иҝҮжқҘзҡ„пјҢйӮЈжҳҜеәҸеҲ—еҢ–еҗҺзҡ„еӯ—иҠӮз ҒгҖӮ
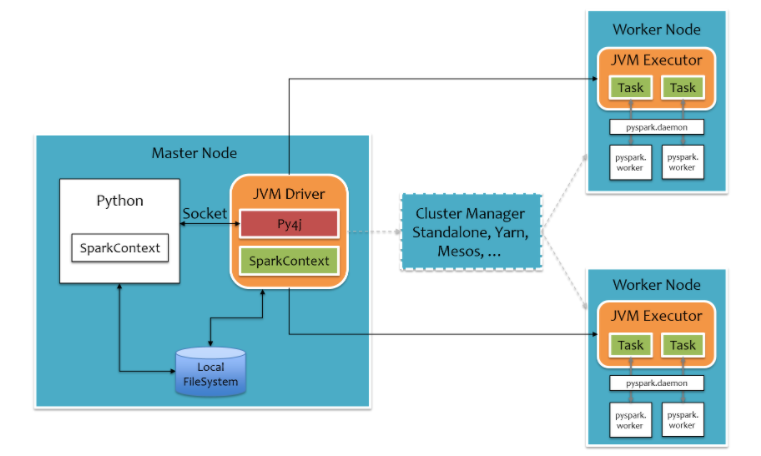
еӣӣпјҢSparkиҝҗиЎҢжөҒзЁӢ
1пјҢApplicationйҰ–е…Ҳиў«Driverжһ„е»әDAGеӣҫ并еҲҶи§ЈжҲҗStageгҖӮ
2пјҢ然еҗҺDriverеҗ‘Cluster Managerз”іиҜ·иө„жәҗгҖӮ
3пјҢCluster Managerеҗ‘жҹҗдәӣWork NodeеҸ‘йҖҒеҫҒеҸ¬дҝЎеҸ·гҖӮ
4пјҢиў«еҫҒеҸ¬зҡ„Work NodeеҗҜеҠЁExecutorиҝӣзЁӢе“Қеә”еҫҒеҸ¬пјҢ并еҗ‘Driverз”іиҜ·д»»еҠЎгҖӮ
5пјҢDriverеҲҶй…ҚTaskз»ҷWork NodeгҖӮ
6пјҢExecutorд»ҘStageдёәеҚ•дҪҚжү§иЎҢTaskпјҢжңҹй—ҙDriverиҝӣиЎҢзӣ‘жҺ§гҖӮ
7пјҢDriver收еҲ°Executorд»»еҠЎе®ҢжҲҗзҡ„дҝЎеҸ·еҗҺеҗ‘Cluster ManagerеҸ‘йҖҒжіЁй”ҖдҝЎеҸ·гҖӮ
8пјҢCluster Managerеҗ‘Work NodeеҸ‘йҖҒйҮҠж”ҫиө„жәҗдҝЎеҸ·гҖӮ
9пјҢWork NodeеҜ№еә”ExecutorеҒңжӯўиҝҗиЎҢгҖӮ

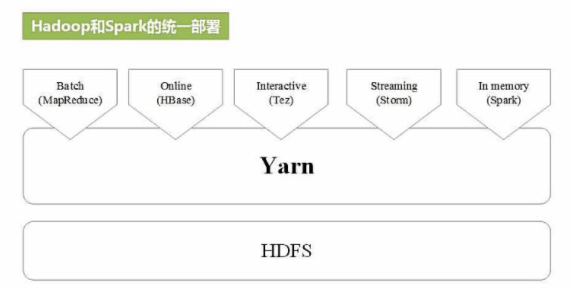
дә”пјҢSparkйғЁзҪІжЁЎејҸ
Localпјҡжң¬ең°иҝҗиЎҢжЁЎејҸпјҢйқһеҲҶеёғејҸгҖӮ
StandaloneпјҡдҪҝз”ЁSparkиҮӘеёҰйӣҶзҫӨз®ЎзҗҶеҷЁпјҢйғЁзҪІеҗҺеҸӘиғҪиҝҗиЎҢSparkд»»еҠЎгҖӮ
YarnпјҡHaoopйӣҶзҫӨз®ЎзҗҶеҷЁпјҢйғЁзҪІеҗҺеҸҜд»ҘеҗҢж—¶иҝҗиЎҢMapReduceпјҢSparkпјҢStormпјҢHbaseзӯүеҗ„з§Қд»»еҠЎгҖӮ
MesosпјҡдёҺYarnжңҖеӨ§зҡ„дёҚеҗҢжҳҜMesos зҡ„иө„жәҗеҲҶй…ҚжҳҜдәҢж¬Ўзҡ„пјҢMesosиҙҹиҙЈеҲҶй…ҚдёҖж¬ЎпјҢи®Ўз®—жЎҶжһ¶еҸҜд»ҘйҖүжӢ©жҺҘеҸ—жҲ–иҖ…жӢ’з»қгҖӮ
е…ӯпјҢRDDж•°жҚ®з»“жһ„
RDDе…Ёз§°Resilient Distributed DatasetпјҢеј№жҖ§еҲҶеёғејҸж•°жҚ®йӣҶпјҢе®ғжҳҜи®°еҪ•зҡ„еҸӘиҜ»еҲҶеҢәйӣҶеҗҲпјҢжҳҜSparkзҡ„еҹәжң¬ж•°жҚ®з»“жһ„гҖӮ
RDDд»ЈиЎЁдёҖдёӘдёҚеҸҜеҸҳгҖҒеҸҜеҲҶеҢәгҖҒйҮҢйқўзҡ„е…ғзҙ еҸҜ并иЎҢи®Ўз®—зҡ„йӣҶеҗҲгҖӮ
дёҖиҲ¬жңүдёӨз§Қж–№ејҸеҲӣе»әRDDпјҢ第дёҖз§ҚжҳҜиҜ»еҸ–ж–Ү件дёӯзҡ„ж•°жҚ®з”ҹжҲҗRDDпјҢ第дәҢз§ҚеҲҷжҳҜйҖҡиҝҮе°ҶеҶ…еӯҳдёӯзҡ„еҜ№иұЎе№¶иЎҢеҢ–еҫ—еҲ°RDDгҖӮ
#йҖҡиҝҮиҜ»еҸ–ж–Ү件з”ҹжҲҗRDD
rdd = sc.textFile("hdfs://hans/data_warehouse/test/data")
#йҖҡиҝҮе°ҶеҶ…еӯҳдёӯзҡ„еҜ№иұЎе№¶иЎҢеҢ–еҫ—еҲ°RDD
arr = [1,2,3,4,5]
rdd = sc.parallelize(arr)
еҲӣе»әRDDд№ӢеҗҺпјҢеҸҜд»ҘдҪҝз”Ёеҗ„з§Қж“ҚдҪңеҜ№RDDиҝӣиЎҢзј–зЁӢгҖӮ
RDDзҡ„ж“ҚдҪңжңүдёӨз§Қзұ»еһӢпјҢеҚіTransformationж“ҚдҪңе’ҢActionж“ҚдҪңгҖӮиҪ¬жҚўж“ҚдҪңжҳҜд»Һе·Із»ҸеӯҳеңЁзҡ„RDDеҲӣе»әдёҖдёӘж–°зҡ„RDDпјҢиҖҢиЎҢеҠЁж“ҚдҪңжҳҜеңЁRDDдёҠиҝӣиЎҢи®Ўз®—еҗҺиҝ”еӣһз»“жһңеҲ° DriverгҖӮ
Transformationж“ҚдҪңйғҪе…·жңү Lazy зү№жҖ§пјҢеҚі Spark дёҚдјҡз«ӢеҲ»иҝӣиЎҢе®һйҷ…зҡ„и®Ўз®—пјҢеҸӘдјҡи®°еҪ•жү§иЎҢзҡ„иҪЁиҝ№пјҢеҸӘжңүи§ҰеҸ‘Actionж“ҚдҪңзҡ„ж—¶еҖҷпјҢе®ғжүҚдјҡж №жҚ® DAG еӣҫзңҹжӯЈжү§иЎҢгҖӮ
ж“ҚдҪңзЎ®е®ҡдәҶRDDд№Ӣй—ҙзҡ„дҫқиө–е…ізі»гҖӮ
RDDд№Ӣй—ҙзҡ„дҫқиө–е…ізі»жңүдёӨз§Қзұ»еһӢпјҢеҚізӘ„дҫқиө–е’Ңе®Ҫдҫқиө–гҖӮзӘ„дҫқиө–ж—¶пјҢзҲ¶RDDзҡ„еҲҶеҢәе’ҢеӯҗRDDзҡ„еҲҶеҢәзҡ„е…ізі»жҳҜдёҖеҜ№дёҖжҲ–иҖ…еӨҡеҜ№дёҖзҡ„е…ізі»гҖӮиҖҢе®Ҫдҫқиө–ж—¶пјҢзҲ¶RDDзҡ„еҲҶеҢәе’ҢиҮӘRDDзҡ„еҲҶеҢәжҳҜдёҖеҜ№еӨҡжҲ–иҖ…еӨҡеҜ№еӨҡзҡ„е…ізі»гҖӮ
е®Ҫдҫқиө–е…ізі»зӣёе…ізҡ„ж“ҚдҪңдёҖиҲ¬е…·жңүshuffleиҝҮзЁӢпјҢеҚійҖҡиҝҮдёҖдёӘPatitionerеҮҪж•°е°ҶзҲ¶RDDдёӯжҜҸдёӘеҲҶеҢәдёҠkeyдёҚеҗҢзҡ„и®°еҪ•еҲҶеҸ‘еҲ°дёҚеҗҢзҡ„еӯҗRDDеҲҶеҢәгҖӮ
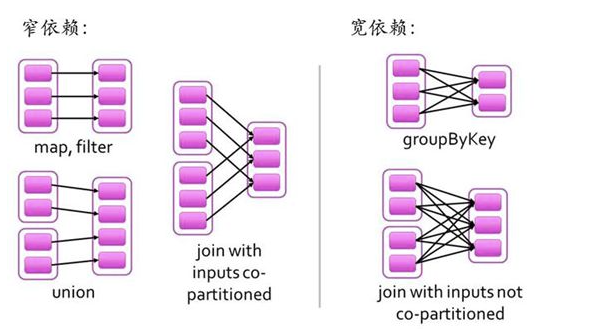
дҫқиө–е…ізі»зЎ®е®ҡдәҶDAGеҲҮеҲҶжҲҗStageзҡ„ж–№ејҸгҖӮ
еҲҮеүІи§„еҲҷпјҡд»ҺеҗҺеҫҖеүҚпјҢйҒҮеҲ°е®Ҫдҫқиө–е°ұеҲҮеүІStageгҖӮ
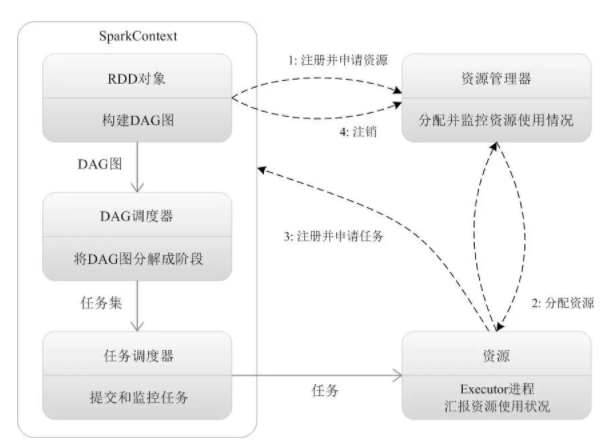
RDDд№Ӣй—ҙзҡ„дҫқиө–е…ізі»еҪўжҲҗдёҖдёӘDAGжңүеҗ‘ж— зҺҜеӣҫпјҢDAGдјҡжҸҗдәӨз»ҷDAGSchedulerпјҢDAGSchedulerдјҡжҠҠDAGеҲ’еҲҶжҲҗзӣёдә’дҫқиө–зҡ„еӨҡдёӘstageпјҢеҲ’еҲҶstageзҡ„дҫқжҚ®е°ұжҳҜRDDд№Ӣй—ҙзҡ„е®ҪзӘ„дҫқиө–гҖӮйҒҮеҲ°е®Ҫдҫқиө–е°ұеҲ’еҲҶstage,жҜҸдёӘstageеҢ…еҗ«дёҖдёӘжҲ–еӨҡдёӘtaskд»»еҠЎгҖӮ然еҗҺе°Ҷиҝҷдәӣtaskд»ҘtaskSetзҡ„еҪўејҸжҸҗдәӨз»ҷTaskSchedulerиҝҗиЎҢгҖӮ

дёғпјҢWordCountиҢғдҫӢ
import findspark
#жҢҮе®ҡspark_homeдёәеҲҡжүҚзҡ„и§ЈеҺӢи·Ҝеҫ„,жҢҮе®ҡpythonи·Ҝеҫ„
spark_home = "/Users/liangyun/ProgramFiles/spark-3.0.1-bin-hadoop3.2"
python_path = "/Users/liangyun/anaconda3/bin/python"
findspark.init(spark_home,python_path)
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("test").setMaster("local[4]")
sc = SparkContext(conf=conf)
еҸӘйңҖиҰҒ5иЎҢд»Јз Ғе°ұеҸҜд»Ҙе®ҢжҲҗWordCountиҜҚйў‘з»ҹи®ЎгҖӮ
rdd_line = sc.textFile("./data/hello.txt")
rdd_word = rdd_line.flatMap(lambda x:x.split(" "))
rdd_one = rdd_word.map(lambda t:(t,1))
rdd_count = rdd_one.reduceByKey(lambda x,y:x+y)
rdd_count.collect()
[('world', 1),
('love', 3),
('jupyter', 1),
('pandas', 1),
('hello', 2),
('spark', 4),
('sql', 1)]
е…ідәҺжҖҺд№ҲзңӢжҮӮSparkзҡ„еҹәжң¬еҺҹзҗҶе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





