基于位置信息的聚类算法介绍及模型选择
百度百科
聚类:将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类分析起源于分类学,但是聚类不等于分类。聚类与分类的不同在于,聚类所要求划分的类是未知的。
分类和聚类算法一直以来都是数据挖掘,机器学习领域的热门课题,因此产生了众多的算法及改进算法,以应对现实世界中业务需求。正因为算法的多样性,选择一个合适的算法,就需要对常用的算法进行了解,并进行比较。最终选择一个适合业务需求的算法模型。
1. 对聚类分析的要求
可伸缩性:许多聚类算法在小数据集合上运行良好,然而在大型数据库可能包含数百万甚至数十亿个对象。在大型数据集上进行聚类可能会导致有偏的结果,甚至程序在一定时间内根本无法计算出结果。因此需要高度可伸缩性的聚类算法。
处理不同属性类型:许多算法是为聚类数值的数据设计的。然而,应用可能要求聚类其他类型的数据,如二元、标称、序数或者这些数据类型的混合。现在,越来越多的应用需要对诸如图、序列、图像和文档等复杂的数据类型进行聚类分析。
发现任意形状的簇:许多聚类算法基于欧几里得或曼哈顿距离度量来确定簇。基于这些距离度量的算法趋向于发现具有相近尺寸和密度的球状簇。然而,一个簇可能是任意形状的。
对于确定输入参数的领域知识的要求:许多聚类算法都要求用户以输入参数(如希望产生的簇数)的形式提供领域知识。因此,聚类结果可能对这些参数十分敏感。通常,参数很难确定,对于高维数据集和用户尚未深入理解的数据来说更是如此。
处理噪声数据的能力:现实世界中的大部分数据集都包含离群点/缺失数据、未知或错误的数据。一些聚类算法可能对这样的噪声敏感,从而产生低质量的聚类结果。
增量聚类和对输入次序不敏感:在许多应用中,增量更新可能是需要的。一些聚类算法不能将新插入的数据(如数据库更新)合并到已有的聚类结构中去,而是需要从头开始聚类。一些算法还可能对输入数据的次序敏感。也就是说,给定数据对象集合,当以不同的次序提供时,算法可能产生差别很大的聚类结果。需要开发增量聚类算法和对数据输入不敏感的算法。
聚类高维数据的能力:数据集可能包含大量的维。例如,在文档聚类时,每个关键词都可以看成一个维,并且常常有数以千计的关键词。许多算法擅长处理低维数据,发现高维空闲中数据对象的簇是一个挑战,特别是考虑这样的数据可能非常稀疏,并且高度倾斜。
基于约束的聚类:现实世界的应用可能需要在各种约束条件下进行聚类。找到既满足特定的约束又具有良好聚类特性的数据分组是一项具有挑战性的任务。
可解释性和可用性:用户希望聚类结果是可解释的、可理解的和可用的。也就是说,聚类算法可能需要与特定的语义解释和应用相联系。
划分准则:在某些方法中,所有的对象都被划分,使得簇之间不存在层次结。也就是说,在概念上,所有的簇都在相同的层。另外,其他方法利用分层的思想划分数据对象,其中簇可以在不同语义层形成。
簇的分离性:有些聚类方法把数据分成互斥的簇。但在一些情况下,簇可以不是互斥的,即一个数据对象可以属于多个簇。如在把文档聚类到主题时,一个文档可能与多个主题有关。因此作为簇的主题可能不是互斥的。
相似性度量:有些方法用对象之间的距离确定两个对象之间的相似性。这种距离可以在欧式空间,公路网,向量空间或其他空间中定义。在其他方法中,相似性可以用基于密度的连接性和邻近性定义,并且不依赖两个对象之间的绝对距离。
聚类空间:许多聚类方法都在整个给定的数据空间中搜索簇。这些方法对于低维数据集是有用的。然而,对于高维数据,可能有许多不相关的属性,使得相似性度量不可靠。因此,在整个空间中发现的簇常常是没有意义的。最好在相同的数据集的不同子空间内搜索簇。子空间聚类发现揭示对象相似性的簇和子空间。
以上内容大多来自《数据挖掘-概念与技术》。总之,聚类算法具有多种要求。因此在开始选择算法时,就需要根据实际业务需求确定聚类算法的要求。
2. 基本聚类方法
2.1 划分方法
给定一个n个对象的集合,划分方法构建数据的k个分区,其中每个分区表示一个簇。也就是说它把数据划分为k个簇,使得每个簇至少包含一个对象。典型的,基本划分方法采取互斥的簇划分,这一要求,例如在模糊划分技术中,可以放宽。
特点:
─发现球形互斥的簇;
─基于距离;
─可以用均值或中心点等代表簇中心;
─对中小规模数据集有效;
最常用划分方法:
2.1.1 k-均值:
算法把簇的形心定义为簇内点的均值。它的处理流程如下。首先,在D中随机地选择k个对象,每个对象代表一个簇的初始均值(中心)。对剩下的每个对象,根据其与各个簇中心的欧式距离,将它分配到最相近的簇。然后,重新计算簇内对象的均值(中心),不断迭代,直到各个簇内对象不再发生变化(或者满足要求)。
算法流程如下:
输入:
k:簇的数目
D:包含n个对象的数据集
输出:k个簇的集合
算法:
(1) 从D中任意选择k个对象作为初始簇中心;
(2) Repeat
(3) 根据簇中对象的均值,将每个对象分配到最相似的簇;
(4) 更新簇中心;
(5) Until不再发生变化(或者满足要求)。

k-均值缺点:
(1) 聚类质量依赖于初始簇中心,解决办法:以不同的初始簇中心,多次运行k-均值算法;二分k-均值算法,该算法对初始簇中心较不敏感。
(2) 当涉及具有标称属性的数据时,均值可能无定义,解决办法:k-众数(k-modes)方法,用簇众数取代簇均值,采用基于频率的方法来更新簇的众数。可以集成k-均值和k-众数方法。对混合类型的数据进行聚类。
(3) K值的选择:提供k值的近似范围,通过比较不同k值得到的聚类结果,确定最佳的值;
(4) 不适合发现非凸球形的簇,或大小差别很大的簇;
(5) 对噪声和离群点敏感:k-中心点算法;
(6) 可伸缩性有待提高:在聚类时使用合适规模的样本;过滤方法,使用空间层次数据索引节省计算均值的开销;利用微聚类的思想,首先把近邻的对象划分到一些“微簇”,然后对这些微簇使用k-均值算法进行聚类。
2.1.2 k-中心点:
不采用簇中对象的均值作为参照点,而是挑选实际对象来代表簇,每个簇使用一个代表对象。其余的每个对象被分配到与其最近的代表对象所在的簇中。基于最小化所有对象p与其对应的代表之间的相异度之和的原则来进行划分。

算法流程如下:
算法描述:k-中心点。围绕中心点划分(PAM),一种基于中心点或中心对象进行划分的k-中心点算法。
输入:
k:簇的数目
D:包含n个对象的数据集
输出:k个簇的集合
算法:

2.2 层次方法
尽管划分方法满足把对象划分成一些互斥的组群的基本聚类要求,但是在某些情况下,我们想把数据划分成不同层上的组群,如层次。层次聚类方法(hierarchical clustering method)将数据对象组成层次结构或簇的“树”。
2.2.1 层次凝聚方法
使用自底向上的策略,令每个对象形成自己的簇开始,并且迭代地把簇合并成越来越大的簇,直到所有对象都在一个簇中,或者满足某个终止条件。在合并过程中,找出两个最接近的簇(根据某种相似性度量),并且合并它们,形成一个簇。因为每次迭代合并两个簇,其中每个簇至少包含一个对象,因此凝聚方法最多需要n次迭代。
2.2.2 层次分裂方法
使用自顶向下的策略。它把所有对象置于一个簇中,该簇是层次结构的根。然后把根上的簇划分成多个较小的子簇,并且递归地把这些簇划分成更小的簇。直到最底层的簇都足够凝聚,或者仅包含一个对象。
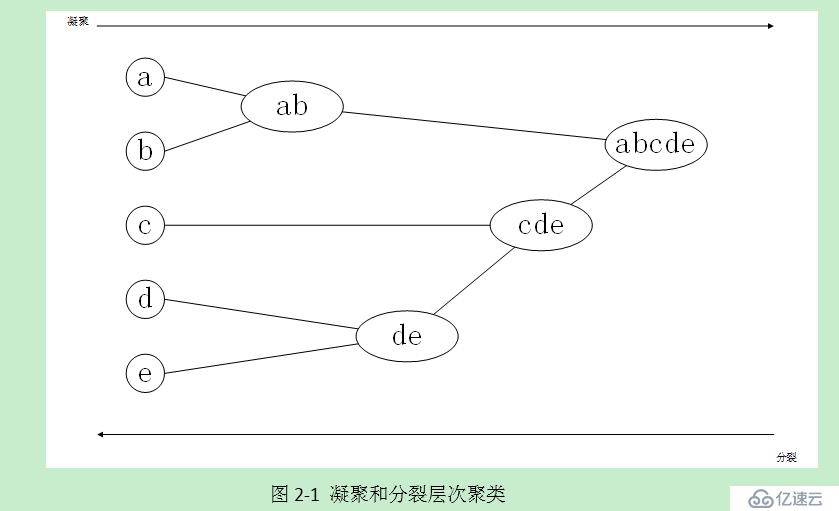
特点:
─聚类时一个层次分解(即多层);
─不能纠正错误的合并或划分;
─可以集成其他技术,如微聚类或考虑对象“连接”;
─凝聚方法远比分裂方法多。
 它们趋向对离群点和噪声数据过分敏感。使用均值或平均距离是一种折中方法,可以克服离群点敏感性问题。平均距离既能够处理数值数据又能处理分类数据。
它们趋向对离群点和噪声数据过分敏感。使用均值或平均距离是一种折中方法,可以克服离群点敏感性问题。平均距离既能够处理数值数据又能处理分类数据。
2.3 实际应用分析
由于本次实际应用需求较简单,上述常用算法能够很好地运用,并且原理简单,实现方便。
2.1.3 问题简述
位置信息是基于GPS上传的经纬度信息,每个一定时间周期设备会上传所在位置的经纬度信息。如下图所示,红圈位置表示车辆停留聚集的地方,在定义上属于异常点或离群点。因为这些点一般都比较固定,所以不需要每次都在整个数据集上进行识别。不然不仅效率低,而且算法更加复杂。
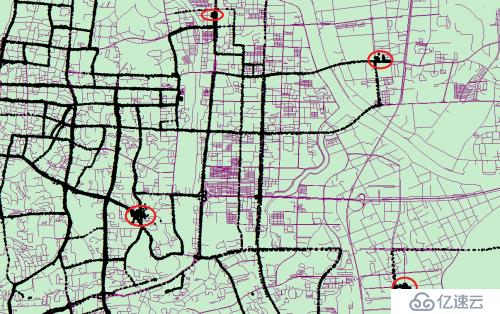
图3-1

图3-2
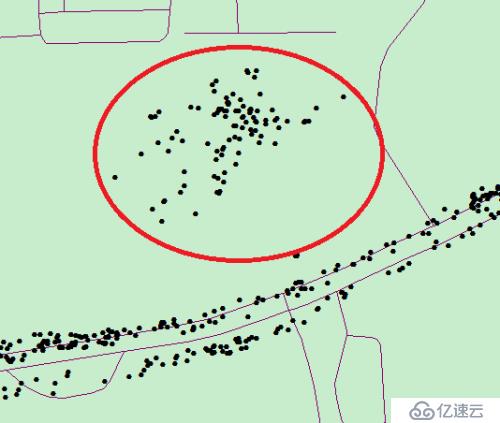
图3-3
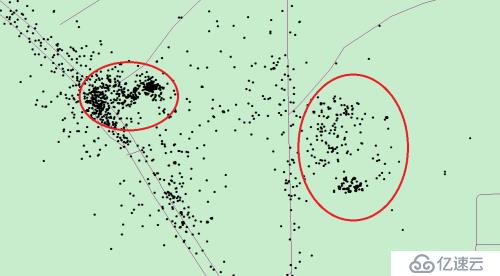
图3-4
2.1.4 算法思路
问题关键:
(1) 位置信息24小时上传,位置信息遍布于路段附近的整张路网,且有些目标区域的密度并不比正常区域的密度大,因此基于密度的方法无效。
(2) 利用位置信息+时间信息。
(3) 由于簇数量K未知,所以不建议使用划分方法,本次采用层次方法。
(4) 采用距离度量来确定簇内的相似性与簇间的相异性。且距离度量采用经纬度计算,通常采用google的距离计算公司。
(5) 聚类完成后根据结果划分区域,一般可划分为矩形区域或圆形区域。
由于算法涉及实际项目,考虑到机密问题,具体算法不在此详细描述。
2.4 总结
本文档介绍了最基本的聚类算法原理,及简单应用。聚类算法要较好的应用实际项目,还有很多的算法可以比较。如基于密度的方法,基于概率的方法,模糊集聚类,网格聚类,基于高维空间的谱聚类,图聚类。后续考虑进一步补充完善。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





