今天就跟大家聊聊有关Kudu如何使用布隆过滤器优化联接和过滤,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
在数据库系统中,提高性能的最有效方法之一是避免执行不必要的工作,例如网络传输和从磁盘读取数据。Apache Kudu实现此目的的方法之一是通过使用扫描器支持列谓词。将列谓词过滤器下推到Kudu可以通过跳过读取已过滤行的列值并减少客户端(例如分布式查询引擎Apache Impala和Kudu)之间的网络IO来优化执行。有关详细信息,请参见Impala中有关运行时筛选的文档。
CDP Runtime 7.1.5和CDP公共云在Kudu中增加了对布隆过滤器列谓词下推的支持,在Impala中增加了相关的集成。
布隆过滤器是一种节省空间的概率数据结构,用于测试可能存在假阳性匹配的集合成员资格。在数据库系统中,这些仅用于确定仅需要记录的子集时是否可以忽略一组数据。有关更多详细信息,请参见Wikipedia页面。
Kudu中使用的实现是Putze等人的“高速,散列和空间高效的布隆过滤器”中的一种基于空间,哈希和高速缓存的基于块的布隆过滤器。此布隆过滤器来自Impala的实现,并得到了进一步增强。基于块的布隆过滤器设计为适合CPU缓存,并且允许使用AVX2(如果可用)进行SIMD操作,以进行有效的查找和插入。
考虑在谓词下推不可用的小表和大表之间进行广播哈希联接的情况。这通常涉及以下步骤:
读取整个小表并从中构造一个哈希表。
将生成的哈希表广播到所有工作节点。
在工作节点上,开始对大表的切片进行获取和迭代,检查哈希表中是否存在大表中的键,并仅返回匹配的行。
步骤3任务最重,因为它涉及读取整个大表,并且如果工作程序和承载大表的节点不在同一服务器上,则可能涉及繁重的网络IO。
在7.1.5之前,Impala支持仅将“最小/最大(MIN_MAX)”运行时过滤器下推至Kudu,从而过滤掉不在指定范围内的值。除了MIN_MAX运行时过滤器之外,CDP 7.1.5+中的Impala现在还支持将运行时布隆过滤器下推到Kudu。借助Kudu中新引入的布隆过滤谓词支持,Impala可以使用此功能对存储在Kudu中的数据执行更加高效的联接。
与上述情况一样,我们运行了一个Impala查询,该查询将存储在Kudu上的一个大表和存储在HDFS上Parquet格式的一个小表连接在一起。该小表是使用HDFS上的Parquet创建的,以隔离新功能,但也可以将其存储在Kudu中。我们首先仅使用MIN_MAX过滤器,然后使用MIN_MAX和布隆过滤器(所有运行时过滤器)运行查询。为了进行比较,我们在HDFS的Parquet中创建了相同的大表。在HDFS上使用Parquet是比较的不错的基准,因为Impala已经支持HDFS上Parquet的MIN_MAX和布隆过滤器。
在具有CDP运行时7.1.5的6节点集群上执行了以下测试。
硬件配置:
Dell PowerEdge R430、2.2chz @ 20c / 40t Xeon e5-2630 v4、128GB Ram,4块2TB的硬盘用于WAL,3个磁盘用于数据目录。
Schema:
大表由2.6亿行组成,其中随机生成的数据哈希由主键跨Kudu上的20个分区进行分区。Kudu表已明确进行了重新平衡,以确保加载后保持平衡的布局。
小表由存储在HDFS上的Parquet的大表中的前1000个键和后1000个键的2000行组成。这将阻止MIN_MAX过滤器对大表进行任何过滤,因为所有行都将落在MIN_MAX过滤器的范围内。
在所有表上都运行了COMPUTE STATS,以帮助收集有关表元数据的信息并帮助Impala优化查询计划。
所有查询都运行了10次,平均查询运行时间如下所示。
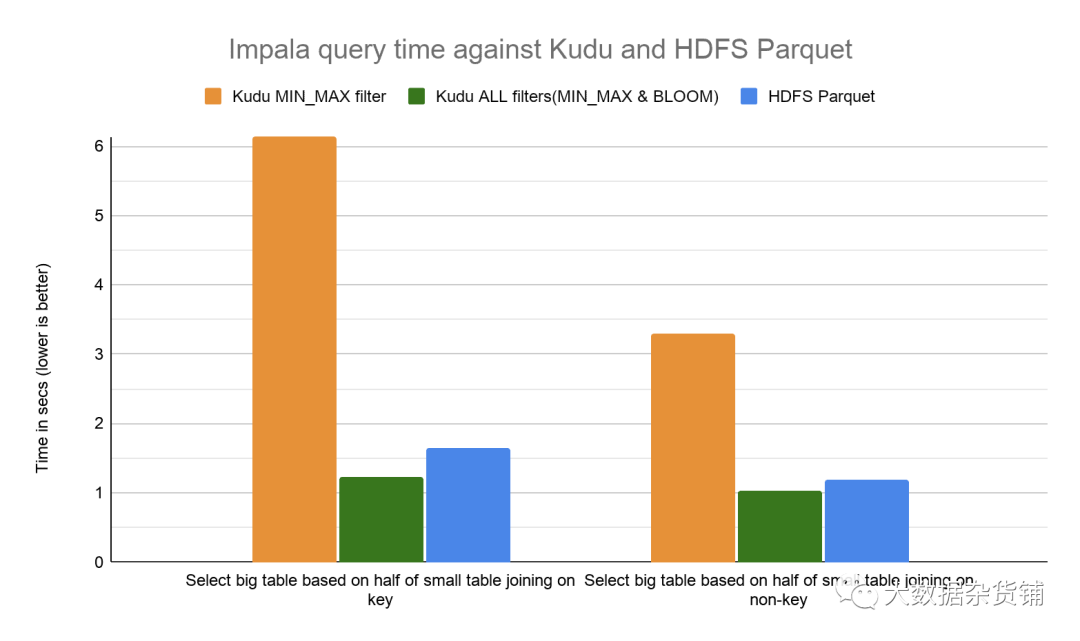
对于联接查询,通过使用布隆过滤器谓词下推,我们发现Kudu的性能提高了3倍至5倍。我们期望通过更大的数据大小和更多的选择性查询,看到更好的性能倍数。
与HDFS上的Parquet相比,Kudu的性能现在提高了约17-33%。
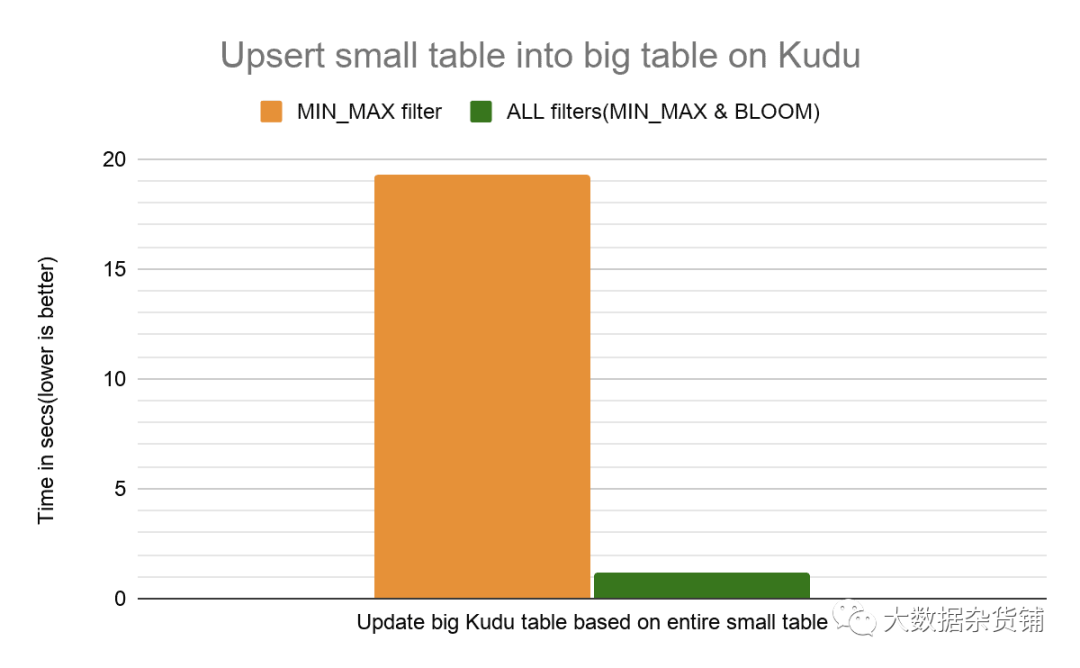
对于基本上将整个小表插入现有大表的更新查询,我们看到了15倍的改进。这主要是由于在选择要更新的行时提高了查询性能。
有关表的模式、加载过程和运行的查询的详细信息,请参见下面的参考部分。
我们还在具有比例因子为30的单节点集群上运行了TPC-H基准测试,并且在不同的块缓存容量设置下,性能提高了19%到31%。
Kudu会自动禁用无法有效过滤数据的布隆过滤谓词,以避免新功能对性能造成的损失。在功能开发过程中,TPCH基准(TPCH-Q9)中的查询9表现出50-96%的回归。在进一步调查中,扫描来自Kudu的行所需的时间最多增加了2倍。在调查此回归时,我们发现被下推的布隆过滤器谓词筛选出的行数不到10%,从而导致Kudu中CPU使用率的增加,其价值超过了过滤器的优势。为了解决回归问题,我们在Kudu中添加了一种启发式方法,其中,如果布隆过滤器谓词未筛选出足够百分比的行,则在其余扫描期间将自动禁用它。
使用Impala查询Kudu的用户将默认从CDP 7.1.5起和CDP公共云启用此功能。我们强烈建议用户升级以在版本中获得此性能增强和许多其他性能增强。对于直接使用Kudu客户端API的自定义应用程序,Kudu C ++客户端还具有从CDP 7.1.5开始可用的布隆过滤器谓词。Kudu Java客户端尚未提供布隆过滤器谓词KUDU-3221。
看完上述内容,你们对Kudu如何使用布隆过滤器优化联接和过滤有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/bigdatagrocery/blog/4913512



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



