这期内容当中小编将会给大家带来有关 怎么简单理解Google 1.6万亿参数的Switch Transformer论文?,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
Switch Transformer 可以理解成一种如何在训练基于MOE (Mixture of Experts) 的巨模型时“偷工减料”的技巧,但这种“偷工减料”却蕴含了一些新的洞察(insights)。
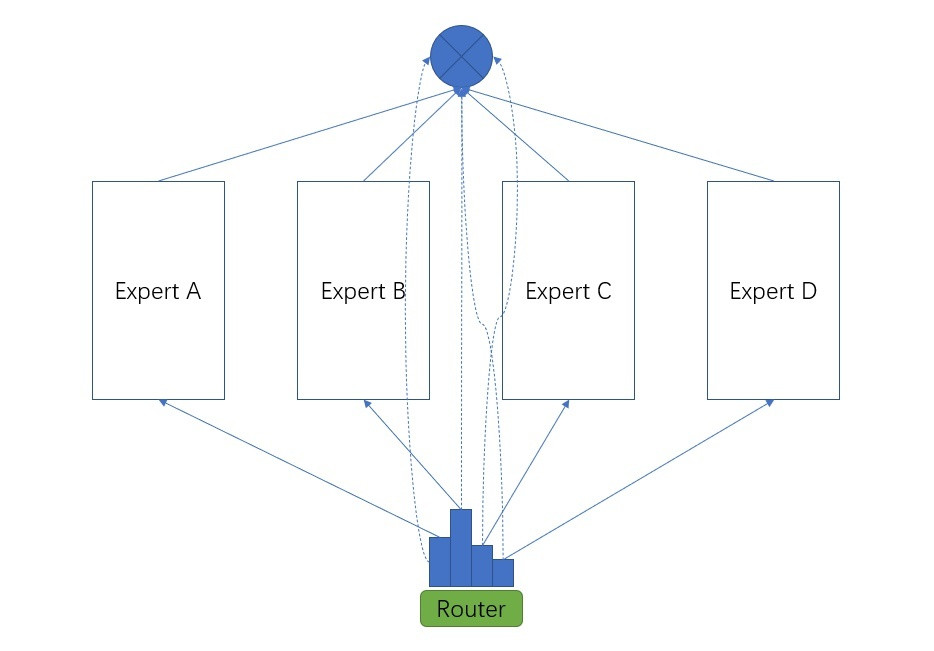
在一般情况下,基于MoE,一个样例进来,会被好几个子网络(expert)处理,这几个子网络的处理结果可以加权求和,每个子网络的权重是通过一个叫router的模块计算出来的(如下图所示)。MoE可以理解成一种模型的集成 (ensemble),根据top k 激活一部分子网络。按照我们对模型集成的经验,一般来说,集成的结果应该要比每一个子网络单独的效果好 (这一点很重要,后文还会提到)。当然,这也让MoE的不足之处展现出来,每个子网络都需要进行计算,总计算量是所有子网络计算量之和。不过,MoE 使用所有子网络不一定就比只使用一个网络好,sparsity 可以让每个子网络更“聚焦”,分工更明确,带来的优势还需进一步观察。
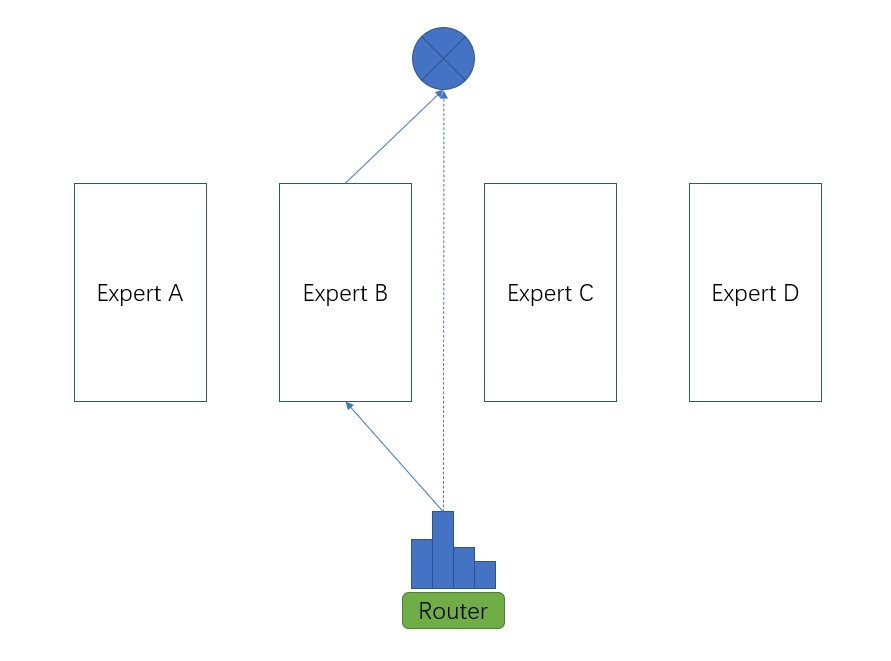
Switch Transformer 的发现是什么?如下图所示,每一个样例进来不需要被所有的子网络处理,只被router模块权重最大的子网络处理,这个子网络的结果再乘以这个权重就可以了,计算量一下子变成了MoE的四分之一。
计算量是少了,效果会有损失吗?按常规的理解来说,效果应该是有损失的,不过这篇论文并没有提供一组实验结果正面回答这个问题。Table 1 的实验结果虽然对比了Switch Transformer和 MoE 并得出了双方最接近这个结论,但其对比方式并不一致。该实验并未在固定每个expert 网络大小的情况下去对比,而是在speed-quality 的基础上对比(全文的实验结果都是这样设定),也就是让MoE和Switch Transformer在计算速度差不多的情况下对比质量,这种情况下Switch Transformer里的子网络的规模一定比MoE 里的子网络规模大。
当然Switch Transformer论文的意义也在于此。其提供了一种“增大参数量,但不增大计算量”的技巧,而且实验还发现,“增大参数量能提升效果”。
我们可以进一步考虑两个极端情况。
如果上面的A, B, C, D 子网络是被分配到不同的设备上去运行的,那么在子网络参数规模相同的情况下,MoE 计算速度和Switch Transformer 可以保持一致,MoE 四个设备同时都用满了,但Switch Transformer 里一个样例只激活一个设备,设备总体利用率可能不高。但MoE的效果应该比Switch Transformer好,因为每个样例都激活了所有的专家网络,一般情况下,集成的效果会更好(但稀疏化后也可能更好,因为每个专家会更加聚焦和专注)。当然,一个批次里包含很多样例,在Switch Transformer里,平均来说每个设备都会有活干,Switch Transformer仍会有速度优势。
如果A, B, C, D 被分配到同一个设备上了,这时,A, B, C, D 不能同时运行,那么Switch Transformer 就比MoE 快4倍,这种情况 Switch Transformer 才有速度优势。
引入sparsity,并行和负载均衡都会引入一些新的问题,Switch Transformer也都提供了一些解决办法。例如引入了倾向于负载均衡的损失函数,以及expert 并行等。其中Switch Transformer 所需要的数据并行、模型并行混合并行也正是OneFlow框架所擅长的,论文在解决这个问题时,使用了Mesh-tensorflow。
上述就是小编为大家分享的 怎么简单理解Google 1.6万亿参数的Switch Transformer论文?了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





