KafkaжҖҺд№Ҳз”Ё
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңKafkaжҖҺд№Ҳз”ЁвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁKafkaжҖҺд№Ҳз”Ёй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқKafkaжҖҺд№Ҳз”ЁвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
дёҖгҖҒKafkaеә”з”Ё
еҪ“KafkaйӣҶзҫӨжөҒйҮҸиҫҫеҲ° дёҮдәҝзә§и®°еҪ•/еӨ©жҲ–иҖ…еҚҒдёҮдәҝзә§и®°еҪ•/еӨ© з”ҡиҮіжӣҙй«ҳеҗҺпјҢжҲ‘们йңҖиҰҒе…·еӨҮе“ӘдәӣиғҪеҠӣжүҚиғҪдҝқйҡңйӣҶзҫӨй«ҳеҸҜз”ЁгҖҒй«ҳеҸҜйқ гҖҒй«ҳжҖ§иғҪгҖҒй«ҳеҗһеҗҗгҖҒе®үе…Ёзҡ„иҝҗиЎҢгҖӮ
иҝҷйҮҢжҖ»з»“еҶ…е®№дё»иҰҒй’ҲеҜ№Kafka2.1.1зүҲжң¬пјҢеҢ…жӢ¬йӣҶзҫӨзүҲжң¬еҚҮзә§гҖҒж•°жҚ®иҝҒ移гҖҒжөҒйҮҸйҷҗеҲ¶гҖҒзӣ‘жҺ§е‘ҠиӯҰгҖҒиҙҹиҪҪеқҮиЎЎгҖҒйӣҶзҫӨжү©/зј©е®№гҖҒиө„жәҗйҡ”зҰ»гҖҒйӣҶзҫӨе®№зҒҫгҖҒйӣҶзҫӨе®үе…ЁгҖҒжҖ§иғҪдјҳеҢ–гҖҒе№іеҸ°еҢ–гҖҒејҖжәҗзүҲжң¬зјәйҷ·гҖҒзӨҫеҢәеҠЁжҖҒзӯүж–№йқўгҖӮжң¬ж–Үдё»иҰҒжҳҜд»Ӣз»Қж ёеҝғи„үз»ңпјҢдёҚеҒҡиҝҮеӨҡз»ҶиҠӮи®Іи§ЈгҖӮдёӢйқўжҲ‘们е…ҲжқҘзңӢзңӢKafkaдҪңдёәж•°жҚ®дёӯжһўзҡ„дёҖдәӣж ёеҝғеә”з”ЁеңәжҷҜгҖӮ
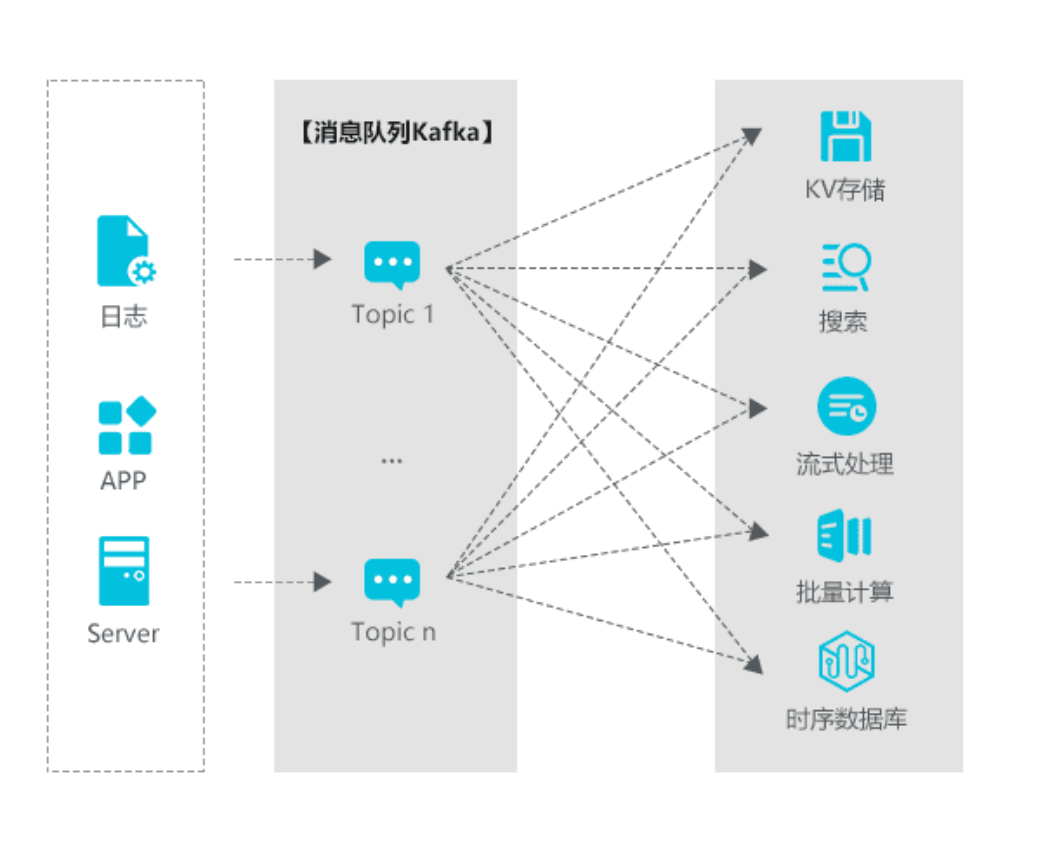
дёӢеӣҫеұ•зӨәдәҶдёҖдәӣдё»жөҒзҡ„ж•°жҚ®еӨ„зҗҶжөҒзЁӢпјҢKafkaиө·еҲ°дёҖдёӘж•°жҚ®дёӯжһўзҡ„дҪңз”ЁгҖӮ
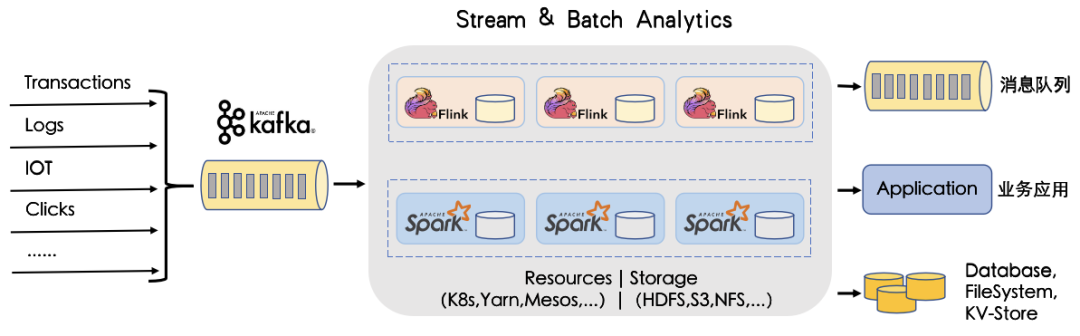
жҺҘдёӢжқҘзңӢзңӢжҲ‘们Kafkaе№іеҸ°ж•ҙдҪ“жһ¶жһ„пјӣ
1.1 зүҲжң¬еҚҮзә§
1.1.1 ејҖжәҗзүҲжң¬еҰӮдҪ•иҝӣиЎҢзүҲжң¬ж»ҡеҠЁеҚҮзә§дёҺеӣһйҖҖ
е®ҳзҪ‘ең°еқҖпјҡhttp://kafka.apache.org
1.1.1.2 жәҗз Ғж”№йҖ еҰӮдҪ•еҚҮзә§дёҺеӣһйҖҖ
з”ұдәҺеңЁеҚҮзә§иҝҮзЁӢдёӯпјҢеҝ…然еҮәзҺ°ж–°ж—§д»Јз ҒйҖ»иҫ‘дәӨжӣҝзҡ„жғ…еҶөгҖӮйӣҶзҫӨеҶ…йғЁйғЁеҲҶиҠӮзӮ№жҳҜејҖжәҗзүҲжң¬пјҢеҸҰеӨ–дёҖйғЁеҲҶиҠӮзӮ№жҳҜж”№йҖ еҗҺзҡ„зүҲжң¬гҖӮжүҖд»ҘпјҢйңҖиҰҒиҖғиҷ‘еңЁеҚҮзә§иҝҮзЁӢдёӯпјҢж–°ж—§д»Јз Ғж··еҗҲзҡ„жғ…еҶөпјҢеҰӮдҪ•е…је®№д»ҘеҸҠеҮәзҺ°ж•…йҡңж—¶еҰӮдҪ•еӣһйҖҖгҖӮ
1.2 ж•°жҚ®иҝҒ移
з”ұдәҺKafkaйӣҶзҫӨзҡ„жһ¶жһ„зү№зӮ№пјҢиҝҷеҝ…然еҜјиҮҙйӣҶзҫӨеҶ…жөҒйҮҸиҙҹиҪҪдёҚеқҮиЎЎзҡ„жғ…еҶөпјҢжүҖд»ҘжҲ‘们йңҖиҰҒеҒҡдёҖдәӣж•°жҚ®иҝҒ移жқҘе®һзҺ°йӣҶзҫӨдёҚеҗҢиҠӮзӮ№й—ҙзҡ„жөҒйҮҸеқҮиЎЎгҖӮKafkaејҖжәҗзүҲжң¬дёәж•°жҚ®иҝҒ移жҸҗдҫӣдәҶдёҖдёӘи„ҡжң¬е·Ҙе…·вҖңbin/kafka-reassign-partitions.shвҖқпјҢеҰӮжһңиҮӘе·ұжІЎжңүе®һзҺ°иҮӘеҠЁиҙҹиҪҪеқҮиЎЎпјҢеҸҜд»ҘдҪҝз”ЁжӯӨи„ҡжң¬гҖӮ
ејҖжәҗзүҲжң¬жҸҗдҫӣзҡ„иҝҷдёӘи„ҡжң¬з”ҹжҲҗиҝҒ移计еҲ’е®Ңе…ЁжҳҜдәәе·Ҙе№Ійў„зҡ„пјҢеҪ“йӣҶзҫӨ规模йқһеёёеӨ§ж—¶пјҢиҝҒ移ж•ҲзҺҮеҸҳеҫ—йқһеёёдҪҺдёӢпјҢдёҖиҲ¬д»ҘеӨ©дёәеҚ•дҪҚиҝӣиЎҢи®Ўз®—гҖӮеҪ“然пјҢжҲ‘们еҸҜд»Ҙе®һзҺ°дёҖеҘ—иҮӘеҠЁеҢ–зҡ„еқҮиЎЎзЁӢеәҸпјҢеҪ“иҙҹиҪҪеқҮиЎЎе®һзҺ°иҮӘеҠЁеҢ–д»ҘеҗҺпјҢеҹәжң¬дҪҝз”Ёи°ғз”ЁеҶ…йғЁжҸҗдҫӣзҡ„APIпјҢз”ұзЁӢеәҸеҺ»её®жҲ‘们з”ҹжҲҗиҝҒ移计еҲ’еҸҠжү§иЎҢиҝҒ移任еҠЎгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢиҝҒ移计еҲ’жңүжҢҮе®ҡж•°жҚ®зӣ®еҪ•е’ҢдёҚжҢҮе®ҡж•°жҚ®зӣ®еҪ•дёӨз§ҚпјҢжҢҮе®ҡж•°жҚ®зӣ®еҪ•зҡ„йңҖиҰҒй…ҚзҪ®ACLе®үе…Ёи®ӨиҜҒгҖӮ
е®ҳзҪ‘ең°еқҖпјҡhttp://kafka.apache.org
1.2.1 brokerй—ҙж•°жҚ®иҝҒ移
дёҚжҢҮе®ҡж•°жҚ®зӣ®еҪ•
//жңӘжҢҮе®ҡиҝҒ移зӣ®еҪ•зҡ„иҝҒ移计еҲ’
{
"version":1,
"partitions":[
{"topic":"yyj4","partition":0,"replicas":[1000003,1000004]},
{"topic":"yyj4","partition":1,"replicas":[1000003,1000004]},
{"topic":"yyj4","partition":2,"replicas":[1000003,1000004]}
]
}жҢҮе®ҡж•°жҚ®зӣ®еҪ•
//жҢҮе®ҡиҝҒ移зӣ®еҪ•зҡ„иҝҒ移计еҲ’
{
"version":1,
"partitions":[
{"topic":"yyj1","partition":0,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]},
{"topic":"yyj1","partition":1,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]},
{"topic":"yyj1","partition":2,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]}
]
}1.2.2 brokerеҶ…йғЁзЈҒзӣҳй—ҙж•°жҚ®иҝҒ移
з”ҹдә§зҺҜеўғзҡ„жңҚеҠЎеҷЁдёҖиҲ¬йғҪжҳҜжҢӮиҪҪеӨҡеқ—зЎ¬зӣҳпјҢжҜ”еҰӮ4еқ—/12еқ—зӯүпјӣйӮЈд№ҲеҸҜиғҪеҮәзҺ°еңЁKafkaйӣҶзҫӨеҶ…йғЁпјҢеҗ„brokerй—ҙжөҒйҮҸжҜ”иҫғеқҮиЎЎпјҢдҪҶжҳҜеңЁbrokerеҶ…йғЁпјҢеҗ„зЈҒзӣҳй—ҙжөҒйҮҸдёҚеқҮиЎЎпјҢеҜјиҮҙйғЁеҲҶзЈҒзӣҳиҝҮиҪҪпјҢд»ҺиҖҢеҪұе“ҚйӣҶзҫӨжҖ§иғҪе’ҢзЁіе®ҡпјҢд№ҹжІЎжңүиҫғеҘҪзҡ„еҲ©з”ЁзЎ¬д»¶иө„жәҗгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢжҲ‘们е°ұйңҖиҰҒеҜ№brokerеҶ…йғЁеӨҡеқ—зЈҒзӣҳзҡ„жөҒйҮҸеҒҡиҙҹиҪҪеқҮиЎЎпјҢи®©жөҒйҮҸжӣҙеқҮеҢҖзҡ„еҲҶеёғеҲ°еҗ„зЈҒзӣҳдёҠгҖӮ
1.2.3 并еҸ‘ж•°жҚ®иҝҒ移
еҪ“еүҚKafkaејҖжәҗзүҲжң¬пјҲ2.1.1зүҲжң¬пјүжҸҗдҫӣзҡ„еүҜжң¬иҝҒ移е·Ҙе…·вҖңbin/kafka-reassign-partitions.shвҖқеңЁеҗҢдёҖдёӘйӣҶзҫӨеҶ…еҸӘиғҪе®һзҺ°иҝҒ移任еҠЎзҡ„дёІиЎҢгҖӮеҜ№дәҺйӣҶзҫӨеҶ…е·Із»Ҹе®һзҺ°еӨҡдёӘиө„жәҗз»„зү©зҗҶйҡ”зҰ»зҡ„жғ…еҶөпјҢз”ұдәҺеҗ„иө„жәҗз»„дёҚдјҡзӣёдә’еҪұе“ҚпјҢдҪҶжҳҜеҚҙдёҚиғҪеҸӢеҘҪзҡ„иҝӣиЎҢ并иЎҢзҡ„жҸҗдәӨиҝҒ移任еҠЎпјҢиҝҒ移ж•ҲзҺҮжңүзӮ№дҪҺдёӢпјҢиҝҷз§ҚдёҚи¶ізӣҙеҲ°2.6.0зүҲжң¬жүҚеҫ—д»Ҙи§ЈеҶігҖӮеҰӮжһңйңҖиҰҒе®һзҺ°е№¶еҸ‘ж•°жҚ®иҝҒ移пјҢеҸҜд»ҘйҖүжӢ©еҚҮзә§KafkaзүҲжң¬жҲ–иҖ…дҝ®ж”№Kafkaжәҗз ҒгҖӮ
1.2.4 з»Ҳжӯўж•°жҚ®иҝҒ移
еҪ“еүҚKafkaејҖжәҗзүҲжң¬пјҲ2.1.1зүҲжң¬пјүжҸҗдҫӣзҡ„еүҜжң¬иҝҒ移е·Ҙе…·вҖңbin/kafka-reassign-partitions.shвҖқеңЁеҗҜеҠЁиҝҒ移任еҠЎеҗҺпјҢж— жі•з»ҲжӯўиҝҒ移гҖӮеҪ“иҝҒ移任еҠЎеҜ№йӣҶзҫӨзҡ„зЁіе®ҡжҖ§жҲ–иҖ…жҖ§иғҪжңүеҪұе“Қж—¶пјҢе°ҶеҸҳеҫ—жқҹжүӢж— зӯ–пјҢеҸӘиғҪзӯүеҫ…иҝҒ移任еҠЎжү§иЎҢе®ҢжҜ•пјҲжҲҗеҠҹжҲ–иҖ…еӨұиҙҘпјүпјҢиҝҷз§ҚдёҚи¶ізӣҙеҲ°2.6.0зүҲжң¬жүҚеҫ—д»Ҙи§ЈеҶігҖӮеҰӮжһңйңҖиҰҒе®һзҺ°з»Ҳжӯўж•°жҚ®иҝҒ移пјҢеҸҜд»ҘйҖүжӢ©еҚҮзә§KafkaзүҲжң¬жҲ–иҖ…дҝ®ж”№Kafkaжәҗз ҒгҖӮ
1.3 жөҒйҮҸйҷҗеҲ¶
1.3.1 з”ҹдә§ж¶Ҳиҙ№жөҒйҮҸйҷҗеҲ¶
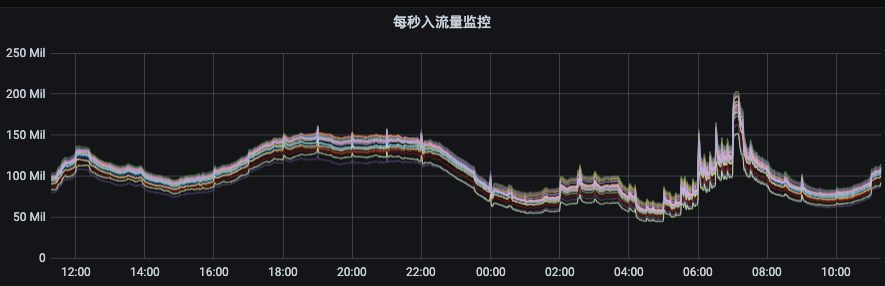
з»ҸеёёдјҡеҮәзҺ°дёҖдәӣзӘҒеҸ‘зҡ„пјҢдёҚеҸҜйў„жөӢзҡ„ејӮеёёз”ҹдә§жҲ–иҖ…ж¶Ҳиҙ№жөҒйҮҸдјҡеҜ№йӣҶзҫӨзҡ„IOзӯүиө„жәҗдә§з”ҹе·ЁеӨ§еҺӢеҠӣпјҢжңҖз»ҲеҪұе“Қж•ҙдёӘйӣҶзҫӨзҡ„зЁіе®ҡдёҺжҖ§иғҪгҖӮйӮЈд№ҲжҲ‘们еҸҜд»ҘеҜ№з”ЁжҲ·зҡ„з”ҹдә§гҖҒж¶Ҳиҙ№гҖҒеүҜжң¬й—ҙж•°жҚ®еҗҢжӯҘиҝӣиЎҢжөҒйҮҸйҷҗеҲ¶пјҢиҝҷдёӘйҷҗжөҒжңәеҲ¶е№¶дёҚжҳҜдёәдәҶйҷҗеҲ¶з”ЁжҲ·пјҢиҖҢжҳҜйҒҝе…ҚзӘҒеҸ‘зҡ„жөҒйҮҸеҪұе“ҚйӣҶзҫӨзҡ„зЁіе®ҡе’ҢжҖ§иғҪпјҢз»ҷз”ЁжҲ·еҸҜд»ҘжӣҙеҘҪзҡ„жңҚеҠЎгҖӮ
еҰӮдёӢеӣҫжүҖзӨәпјҢиҠӮзӮ№е…ҘжөҒйҮҸз”ұ140MB/sе·ҰеҸізӘҒеўһеҲ°250MB/sпјҢиҖҢеҮәжөҒйҮҸеҲҷд»Һ400MB/sе·ҰеҸізӘҒеўһиҮі800MB/sгҖӮеҰӮжһңжІЎжңүйҷҗжөҒжңәеҲ¶пјҢйӮЈд№ҲйӣҶзҫӨзҡ„еӨҡдёӘиҠӮзӮ№е°Ҷжңүиў«иҝҷдәӣејӮеёёжөҒйҮҸжү“жҢӮзҡ„йЈҺйҷ©пјҢз”ҡиҮійҖ жҲҗйӣҶзҫӨйӣӘеҙ©гҖӮ

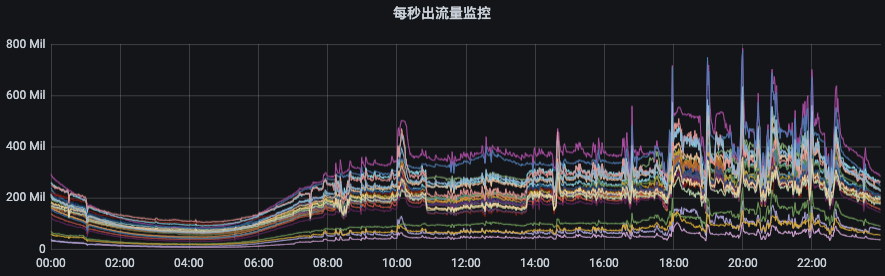
еӣҫзүҮз”ҹдә§/ж¶Ҳиҙ№жөҒйҮҸйҷҗеҲ¶е®ҳзҪ‘ең°еқҖпјҡзӮ№еҮ»й“ҫжҺҘ
еҜ№дәҺз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…зҡ„жөҒйҮҸйҷҗеҲ¶пјҢе®ҳзҪ‘жҸҗдҫӣдәҶд»ҘдёӢеҮ з§Қз»ҙеәҰз»„еҗҲиҝӣиЎҢйҷҗеҲ¶пјҲеҪ“然пјҢдёӢйқўйҷҗжөҒжңәеҲ¶еӯҳеңЁдёҖе®ҡзјәйҷ·пјҢеҗҺйқўеңЁвҖңKafkaејҖжәҗзүҲжң¬еҠҹиғҪзјәйҷ·вҖқжҲ‘们е°ҶжҸҗеҲ°пјүпјҡ
/config/users/<user>/clients/<client-id> //ж №жҚ®з”ЁжҲ·е’Ңе®ўжҲ·з«ҜIDз»„еҗҲйҷҗжөҒ
/config/users/<user>/clients/<default>
/config/users/<user>//ж №жҚ®з”ЁжҲ·йҷҗжөҒ иҝҷз§ҚйҷҗжөҒж–№ејҸжҳҜжҲ‘们жңҖеёёз”Ёзҡ„ж–№ејҸ
/config/users/<default>/clients/<client-id>
/config/users/<default>/clients/<default>
/config/users/<default>
/config/clients/<client-id>
/config/clients/<default>
еңЁеҗҜеҠЁKafkaзҡ„brokerжңҚеҠЎж—¶йңҖиҰҒејҖеҗҜJMXеҸӮж•°й…ҚзҪ®пјҢж–№дҫҝйҖҡиҝҮе…¶д»–еә”з”ЁзЁӢеәҸйҮҮйӣҶKafkaзҡ„еҗ„йЎ№JMXжҢҮж ҮиҝӣиЎҢжңҚеҠЎзӣ‘жҺ§гҖӮеҪ“з”ЁжҲ·йңҖиҰҒи°ғж•ҙйҷҗжөҒйҳҲеҖјж—¶пјҢж №жҚ®еҚ•дёӘbrokerжүҖиғҪжүҝеҸ—зҡ„жөҒйҮҸиҝӣиЎҢжҷәиғҪиҜ„дј°пјҢж— йңҖдәәе·Ҙе№Ійў„еҲӨж–ӯжҳҜеҗҰеҸҜд»Ҙи°ғж•ҙпјӣеҜ№дәҺз”ЁжҲ·жөҒйҮҸйҷҗеҲ¶пјҢдё»иҰҒйңҖиҰҒеҸӮиҖғзҡ„жҢҮж ҮеҢ…жӢ¬д»ҘдёӢдёӨдёӘпјҡ
пјҲ1пјүж¶Ҳиҙ№жөҒйҮҸжҢҮж ҮпјҡObjectNameпјҡkafka.server:type=Fetch,user=aclи®ӨиҜҒз”ЁжҲ·еҗҚз§° еұһжҖ§пјҡbyte-rateпјҲз”ЁжҲ·еңЁеҪ“еүҚbrokerзҡ„еҮәжөҒйҮҸпјүгҖҒthrottle-timeпјҲз”ЁжҲ·еңЁеҪ“еүҚbrokerзҡ„еҮәжөҒйҮҸиў«йҷҗеҲ¶ж—¶й—ҙпјү
пјҲ2пјүз”ҹдә§жөҒйҮҸжҢҮж ҮпјҡObjectNameпјҡkafka.server:type=Produce,user=aclи®ӨиҜҒз”ЁжҲ·еҗҚз§° еұһжҖ§пјҡbyte-rateпјҲз”ЁжҲ·еңЁеҪ“еүҚbrokerзҡ„е…ҘжөҒйҮҸпјүгҖҒthrottle-timeпјҲз”ЁжҲ·еңЁеҪ“еүҚbrokerзҡ„е…ҘжөҒйҮҸиў«йҷҗеҲ¶ж—¶й—ҙпјү

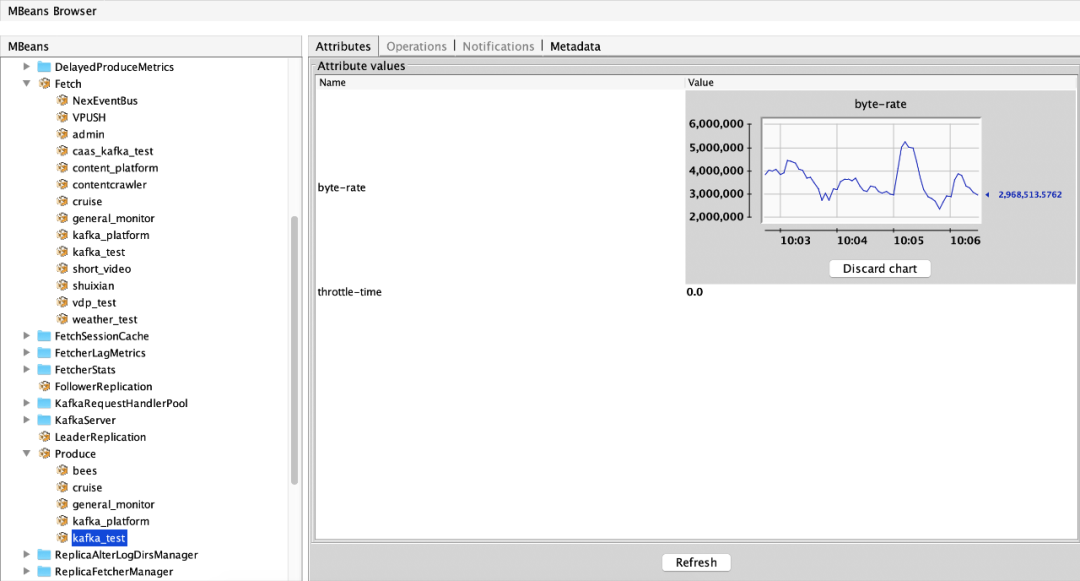
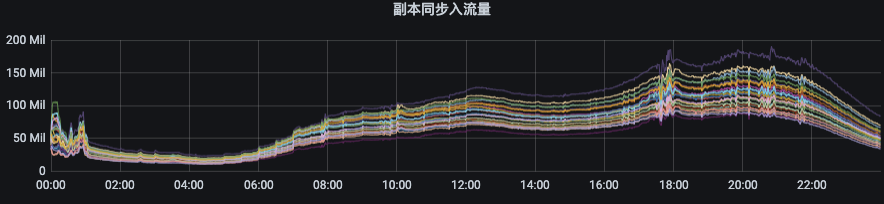
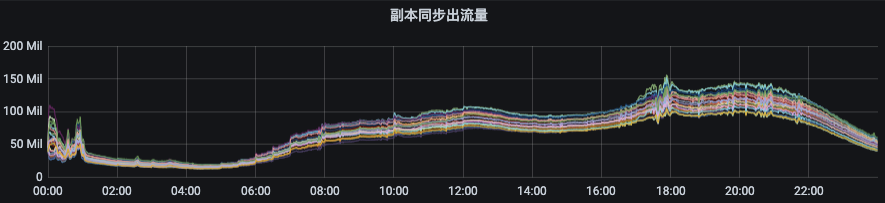
1.3.2 followerеҗҢжӯҘleader/ж•°жҚ®иҝҒ移жөҒйҮҸйҷҗеҲ¶
еүҜжң¬иҝҒ移/ж•°жҚ®еҗҢжӯҘжөҒйҮҸйҷҗеҲ¶е®ҳзҪ‘ең°еқҖпјҡй“ҫжҺҘ
ж¶үеҸҠеҸӮж•°еҰӮдёӢпјҡ
//еүҜжң¬еҗҢжӯҘйҷҗжөҒй…ҚзҪ®е…ұж¶үеҸҠд»ҘдёӢ4дёӘеҸӮж•°
leader.replication.throttled.rate
follower.replication.throttled.rate
leader.replication.throttled.replicas
follower.replication.throttled.replicas
иҫ…еҠ©жҢҮж ҮеҰӮдёӢпјҡ
пјҲ1пјүеүҜжң¬еҗҢжӯҘеҮәжөҒйҮҸжҢҮж ҮпјҡObjectNameпјҡkafka.server:type=BrokerTopicMetrics,name=ReplicationBytesOutPerSec
пјҲ2пјүеүҜжң¬еҗҢжӯҘе…ҘжөҒйҮҸжҢҮж ҮпјҡObjectNameпјҡkafka.server:type=BrokerTopicMetrics,name=ReplicationBytesInPerSec
1.4 зӣ‘жҺ§е‘ҠиӯҰ
е…ідәҺKafkaзҡ„зӣ‘жҺ§жңүдёҖдәӣејҖжәҗзҡ„е·Ҙе…·еҸҜз”ЁдҪҝз”ЁпјҢжҜ”еҰӮдёӢйқўиҝҷеҮ з§Қпјҡ
Kafka Managerпјӣ
Kafka Eagleпјӣ
Kafka Monitorпјӣ
KafkaOffsetMonitorпјӣ
жҲ‘们已з»ҸжҠҠKafka ManagerдҪңдёәжҲ‘们жҹҘзңӢдёҖдәӣеҹәжң¬жҢҮж Үзҡ„е·Ҙе…·еөҢе…Ҙе№іеҸ°пјҢ然иҖҢиҝҷдәӣејҖжәҗе·Ҙе…·дёҚиғҪеҫҲеҘҪзҡ„иһҚе…ҘеҲ°жҲ‘们иҮӘе·ұзҡ„дёҡеҠЎзі»з»ҹжҲ–иҖ…е№іеҸ°дёҠгҖӮжүҖд»ҘпјҢжҲ‘们йңҖиҰҒиҮӘе·ұеҺ»е®һзҺ°дёҖеҘ—зІ’еәҰжӣҙз»ҶгҖҒзӣ‘жҺ§жӣҙжҷәиғҪгҖҒе‘ҠиӯҰжӣҙзІҫеҮҶзҡ„зі»з»ҹгҖӮе…¶зӣ‘жҺ§иҰҶзӣ–иҢғеӣҙеә”иҜҘеҢ…жӢ¬еҹәзЎҖ硬件гҖҒж“ҚдҪңзі»з»ҹпјҲж“ҚдҪңзі»з»ҹеҒ¶е°”еҮәзҺ°зі»з»ҹиҝӣзЁӢhangдҪҸжғ…еҶөпјҢеҜјиҮҙbrokerеҒҮжӯ»пјҢж— жі•жӯЈеёёжҸҗдҫӣжңҚеҠЎпјүгҖҒKafkaзҡ„brokerжңҚеҠЎгҖҒKafkaе®ўжҲ·з«Ҝеә”з”ЁзЁӢеәҸгҖҒzookeeperйӣҶзҫӨгҖҒдёҠдёӢжёёе…Ёй“ҫи·Ҝзӣ‘жҺ§гҖӮ
1.4.1 硬件зӣ‘жҺ§
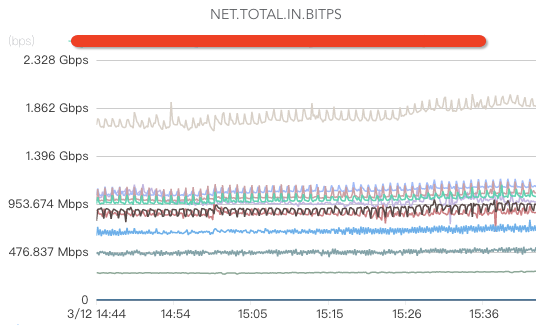
зҪ‘з»ңзӣ‘жҺ§пјҡ
ж ёеҝғжҢҮж ҮеҢ…жӢ¬зҪ‘з»ңе…ҘжөҒйҮҸгҖҒзҪ‘з»ңеҮәжөҒйҮҸгҖҒзҪ‘з»ңдёўеҢ…гҖҒзҪ‘з»ңйҮҚдј гҖҒеӨ„дәҺTIME.WAITзҡ„TCPиҝһжҺҘж•°гҖҒдәӨжҚўжңәгҖҒжңәжҲҝеёҰе®ҪгҖҒDNSжңҚеҠЎеҷЁзӣ‘жҺ§пјҲеҰӮжһңDNSжңҚеҠЎеҷЁејӮеёёпјҢеҸҜиғҪеҮәзҺ°жөҒйҮҸй»‘жҙһпјҢеј•иө·еӨ§йқўз§ҜдёҡеҠЎж•…йҡңпјүзӯүгҖӮ
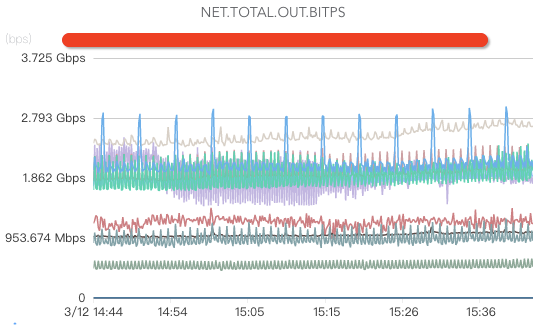

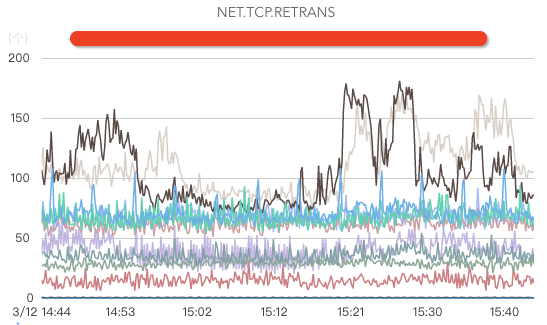
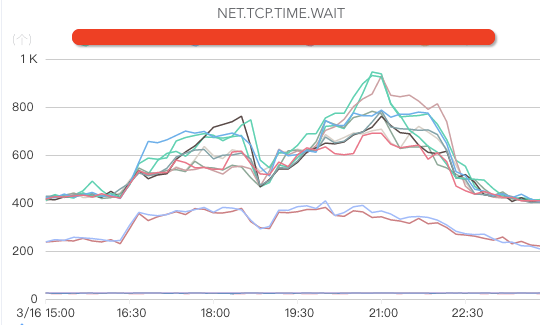
зЈҒзӣҳзӣ‘жҺ§пјҡ
ж ёеҝғжҢҮж ҮеҢ…жӢ¬зӣ‘жҺ§зЈҒзӣҳwriteгҖҒзЈҒзӣҳreadпјҲеҰӮжһңж¶Ҳиҙ№ж—¶жІЎжңү延时пјҢжҲ–иҖ…еҸӘжңүе°‘йҮҸ延时пјҢдёҖиҲ¬йғҪжІЎжңүзЈҒзӣҳreadж“ҚдҪңпјүгҖҒзЈҒзӣҳioutilгҖҒзЈҒзӣҳiowaitпјҲиҝҷдёӘжҢҮж ҮеҰӮжһңиҝҮй«ҳиҜҙжҳҺзЈҒзӣҳиҙҹиҪҪиҫғеӨ§пјүгҖҒзЈҒзӣҳеӯҳеӮЁз©әй—ҙгҖҒзЈҒзӣҳеқҸзӣҳгҖҒзЈҒзӣҳеқҸеқ—/еқҸйҒ“пјҲеқҸйҒ“жҲ–иҖ…еқҸеқ—е°ҶеҜјиҮҙbrokerеӨ„дәҺеҚҠжӯ»дёҚжҙ»зҠ¶жҖҒпјҢз”ұдәҺжңүcrcж ЎйӘҢпјҢж¶Ҳиҙ№иҖ…е°Ҷиў«еҚЎдҪҸпјүзӯүгҖӮ
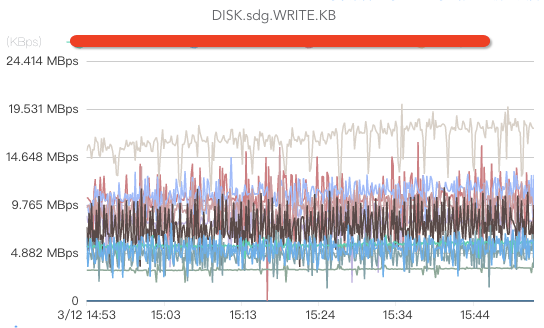
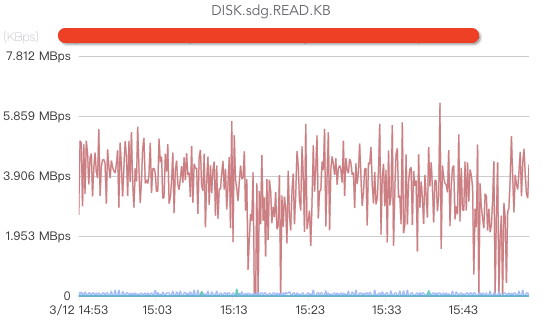
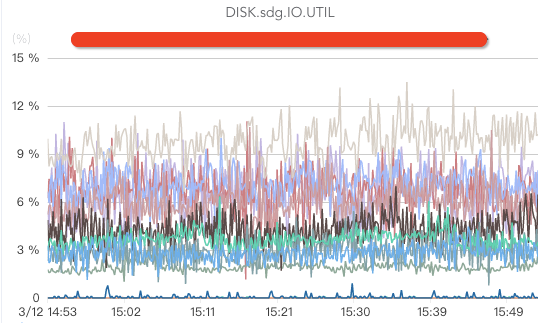
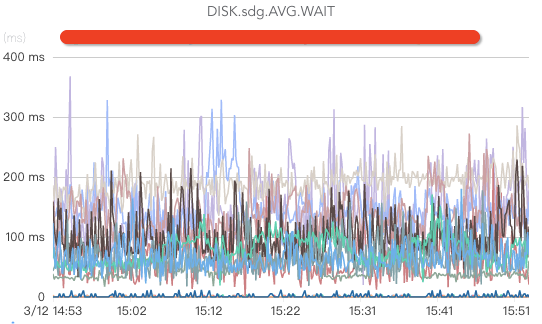
CPUзӣ‘жҺ§пјҡ
зӣ‘жҺ§CPUз©әй—ІзҺҮ/иҙҹиҪҪпјҢдё»жқҝж•…йҡңзӯүпјҢйҖҡеёёCPUдҪҝз”ЁзҺҮжҜ”иҫғдҪҺдёҚжҳҜKafkaзҡ„瓶йўҲгҖӮ
еҶ…еӯҳ/дәӨжҚўеҢәзӣ‘жҺ§пјҡ
еҶ…еӯҳдҪҝз”ЁзҺҮпјҢеҶ…еӯҳж•…йҡңгҖӮдёҖиҲ¬жғ…еҶөдёӢпјҢжңҚеҠЎеҷЁдёҠйҷӨдәҶеҗҜеҠЁKafkaзҡ„brokerж—¶еҲҶй…Қзҡ„е ҶеҶ…еӯҳд»ҘеӨ–пјҢе…¶д»–еҶ…еӯҳеҹәжң¬е…ЁйғЁиў«з”ЁжқҘеҒҡPageCacheгҖӮ
зј“еӯҳе‘ҪдёӯзҺҮзӣ‘жҺ§пјҡ
з”ұдәҺжҳҜеҗҰиҜ»зЈҒзӣҳеҜ№Kafkaзҡ„жҖ§иғҪеҪұе“ҚеҫҲеӨ§пјҢжүҖд»ҘжҲ‘们йңҖиҰҒзӣ‘жҺ§Linuxзҡ„PageCacheзј“еӯҳе‘ҪдёӯзҺҮпјҢеҰӮжһңзј“еӯҳе‘ҪдёӯзҺҮй«ҳпјҢеҲҷиҜҙжҳҺж¶Ҳиҙ№иҖ…еҹәжң¬е‘Ҫдёӯзј“еӯҳгҖӮ
иҜҰз»ҶеҶ…е®№иҜ·йҳ…иҜ»ж–Үз« пјҡгҖҠLinux Page Cacheи°ғдјҳеңЁKafkaдёӯзҡ„еә”з”ЁгҖӢгҖӮ
зі»з»ҹж—Ҙеҝ—пјҡ
жҲ‘们йңҖиҰҒеҜ№ж“ҚдҪңзі»з»ҹзҡ„й”ҷиҜҜж—Ҙеҝ—иҝӣиЎҢзӣ‘жҺ§е‘ҠиӯҰпјҢеҸҠж—¶еҸ‘зҺ°дёҖдәӣ硬件故йҡңгҖӮ
1.4.2 brokerжңҚеҠЎзӣ‘жҺ§
brokerжңҚеҠЎзҡ„зӣ‘жҺ§пјҢдё»иҰҒжҳҜйҖҡиҝҮеңЁbrokerжңҚеҠЎеҗҜеҠЁж—¶жҢҮе®ҡJMXз«ҜеҸЈпјҢ然еҗҺйҖҡиҝҮе®һзҺ°дёҖеҘ—жҢҮж ҮйҮҮйӣҶзЁӢеәҸеҺ»йҮҮйӣҶJMXжҢҮж ҮгҖӮпјҲжңҚеҠЎз«ҜжҢҮж Үе®ҳзҪ‘ең°еқҖпјү
**brokerзә§зӣ‘жҺ§пјҡ**brokerиҝӣзЁӢгҖҒbrokerе…ҘжөҒйҮҸеӯ—иҠӮеӨ§е°Ҹ/и®°еҪ•ж•°гҖҒbrokerеҮәжөҒйҮҸеӯ—иҠӮеӨ§е°Ҹ/и®°еҪ•ж•°гҖҒеүҜжң¬еҗҢжӯҘе…ҘжөҒйҮҸгҖҒеүҜжң¬еҗҢжӯҘеҮәжөҒйҮҸгҖҒbrokerй—ҙжөҒйҮҸеҒҸе·®гҖҒbrokerиҝһжҺҘж•°гҖҒbrokerиҜ·жұӮйҳҹеҲ—ж•°гҖҒbrokerзҪ‘з»ңз©әй—ІзҺҮгҖҒbrokerз”ҹдә§е»¶ж—¶гҖҒbrokerж¶Ҳиҙ№е»¶ж—¶гҖҒbrokerз”ҹдә§иҜ·жұӮж•°гҖҒbrokerж¶Ҳиҙ№иҜ·жұӮж•°гҖҒbrokerдёҠеҲҶеёғleaderдёӘж•°гҖҒbrokerдёҠеҲҶеёғеүҜжң¬дёӘж•°гҖҒbrokerдёҠеҗ„зЈҒзӣҳжөҒйҮҸгҖҒbroker GCзӯүгҖӮ
**topicзә§зӣ‘жҺ§пјҡ**topicе…ҘжөҒйҮҸеӯ—иҠӮеӨ§е°Ҹ/и®°еҪ•ж•°гҖҒtopicеҮәжөҒйҮҸеӯ—иҠӮеӨ§е°Ҹ/и®°еҪ•ж•°гҖҒж— жөҒйҮҸtopicгҖҒtopicжөҒйҮҸзӘҒеҸҳпјҲзӘҒеўһ/зӘҒйҷҚпјүгҖҒtopicж¶Ҳиҙ№е»¶ж—¶гҖӮ
**partitionзә§зӣ‘жҺ§пјҡ**еҲҶеҢәе…ҘжөҒйҮҸеӯ—иҠӮеӨ§е°Ҹ/и®°еҪ•ж•°гҖҒеҲҶеҢәеҮәжөҒйҮҸеӯ—иҠӮеӨ§е°Ҹ/и®°еҪ•ж•°гҖҒtopicеҲҶеҢәеүҜжң¬зјәеӨұгҖҒеҲҶеҢәж¶Ҳиҙ№е»¶иҝҹи®°еҪ•гҖҒеҲҶеҢәleaderеҲҮжҚўгҖҒеҲҶеҢәж•°жҚ®еҖҫж–ңпјҲз”ҹдә§ж¶ҲжҒҜж—¶пјҢеҰӮжһңжҢҮе®ҡдәҶж¶ҲжҒҜзҡ„keyе®№жҳ“йҖ жҲҗж•°жҚ®еҖҫж–ңпјҢиҝҷдёҘйҮҚеҪұе“ҚKafkaзҡ„жңҚеҠЎжҖ§иғҪпјүгҖҒеҲҶеҢәеӯҳеӮЁеӨ§е°ҸпјҲеҸҜд»ҘжІ»зҗҶеҚ•еҲҶеҢәиҝҮеӨ§зҡ„topicпјүгҖӮ
**з”ЁжҲ·зә§зӣ‘жҺ§пјҡ**з”ЁжҲ·еҮә/е…ҘжөҒйҮҸеӯ—иҠӮеӨ§е°ҸгҖҒз”ЁжҲ·еҮә/е…ҘжөҒйҮҸиў«йҷҗеҲ¶ж—¶й—ҙгҖҒз”ЁжҲ·жөҒйҮҸзӘҒеҸҳпјҲзӘҒеўһ/зӘҒйҷҚпјүгҖӮ
**brokerжңҚеҠЎж—Ҙеҝ—зӣ‘жҺ§пјҡ**еҜ№serverз«Ҝжү“еҚ°зҡ„й”ҷиҜҜж—Ҙеҝ—иҝӣиЎҢзӣ‘жҺ§е‘ҠиӯҰпјҢеҸҠж—¶еҸ‘зҺ°жңҚеҠЎејӮеёёгҖӮ
1.4.3.е®ўжҲ·з«Ҝзӣ‘жҺ§
е®ўжҲ·з«Ҝзӣ‘жҺ§дё»иҰҒжҳҜиҮӘе·ұе®һзҺ°дёҖеҘ—жҢҮж ҮдёҠжҠҘзЁӢеәҸпјҢиҝҷдёӘзЁӢеәҸйңҖиҰҒе®һзҺ°
org.apache.kafka.common.metrics.MetricsReporter жҺҘеҸЈгҖӮ然еҗҺеңЁз”ҹдә§иҖ…жҲ–иҖ…ж¶Ҳиҙ№иҖ…зҡ„й…ҚзҪ®дёӯеҠ е…Ҙй…ҚзҪ®йЎ№ metric.reportersпјҢеҰӮдёӢжүҖзӨәпјҡ
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//ClientMetricsReporterзұ»е®һзҺ°org.apache.kafka.common.metrics.MetricsReporterжҺҘеҸЈ
props.put(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG, ClientMetricsReporter.class.getName());
...
е®ўжҲ·з«ҜжҢҮж Үе®ҳзҪ‘ең°еқҖпјҡ
http://kafka.apache.org/21/documentation.html#selector_monitoring
http://kafka.apache.org/21/documentation.html#common_node_monitoring
http://kafka.apache.org/21/documentation.html#producer_monitoring
http://kafka.apache.org/21/documentation.html#producer_sender_monitoring
http://kafka.apache.org/21/documentation.html#consumer_monitoring
http://kafka.apache.org/21/documentation.html#consumer_fetch_monitoring
е®ўжҲ·з«Ҝзӣ‘жҺ§жөҒзЁӢжһ¶жһ„еҰӮдёӢеӣҫжүҖзӨәпјҡ
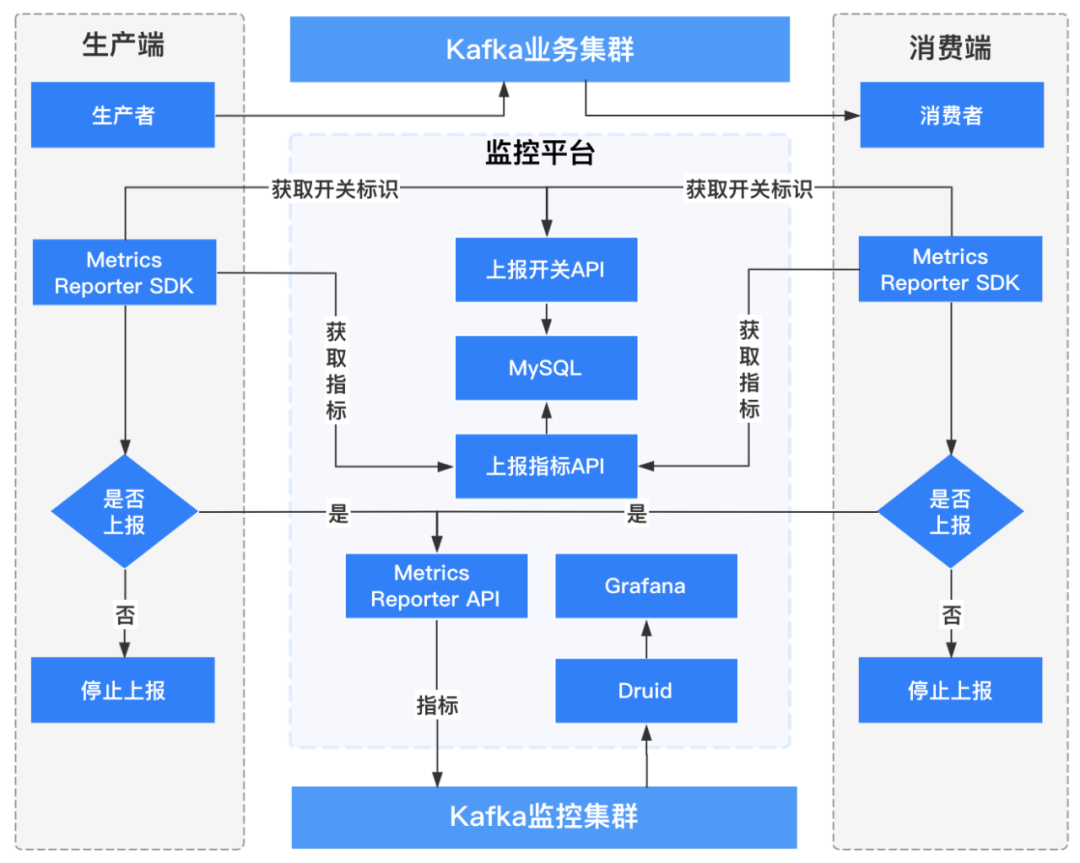
1.4.3.1 з”ҹдә§иҖ…е®ўжҲ·з«Ҝзӣ‘жҺ§
**з»ҙеәҰпјҡ**з”ЁжҲ·еҗҚз§°гҖҒе®ўжҲ·з«ҜIDгҖҒе®ўжҲ·з«ҜIPгҖҒtopicеҗҚз§°гҖҒйӣҶзҫӨеҗҚз§°гҖҒbrokerIPпјӣ
**жҢҮж Үпјҡ**иҝһжҺҘж•°гҖҒIOзӯүеҫ…ж—¶й—ҙгҖҒз”ҹдә§жөҒйҮҸеӨ§е°ҸгҖҒз”ҹдә§и®°еҪ•ж•°гҖҒиҜ·жұӮж¬Ўж•°гҖҒиҜ·жұӮ延时гҖҒеҸ‘йҖҒй”ҷиҜҜ/йҮҚиҜ•ж¬Ўж•°зӯүгҖӮ
1.4.3.2 ж¶Ҳиҙ№иҖ…е®ўжҲ·з«Ҝзӣ‘жҺ§
**з»ҙеәҰпјҡ**з”ЁжҲ·еҗҚз§°гҖҒе®ўжҲ·з«ҜIDгҖҒе®ўжҲ·з«ҜIPгҖҒtopicеҗҚз§°гҖҒйӣҶзҫӨеҗҚз§°гҖҒж¶Ҳиҙ№з»„гҖҒbrokerIPгҖҒtopicеҲҶеҢәпјӣ
**жҢҮж Үпјҡ**иҝһжҺҘж•°гҖҒioзӯүеҫ…ж—¶й—ҙгҖҒж¶Ҳиҙ№жөҒйҮҸеӨ§е°ҸгҖҒж¶Ҳиҙ№и®°еҪ•ж•°гҖҒж¶Ҳиҙ№е»¶ж—¶гҖҒtopicеҲҶеҢәж¶Ҳиҙ№е»¶иҝҹи®°еҪ•зӯүгҖӮ
1.4.4 Zookeeperзӣ‘жҺ§
ZookeeperиҝӣзЁӢзӣ‘жҺ§пјӣ
Zookeeperзҡ„leaderеҲҮжҚўзӣ‘жҺ§пјӣ
ZookeeperжңҚеҠЎзҡ„й”ҷиҜҜж—Ҙеҝ—зӣ‘жҺ§пјӣ
1.4.5 е…Ёй“ҫи·Ҝзӣ‘жҺ§
еҪ“ж•°жҚ®й“ҫи·Ҝйқһеёёй•ҝзҡ„ж—¶еҖҷпјҲжҜ”еҰӮпјҡдёҡеҠЎеә”з”Ё->еҹӢзӮ№SDk->ж•°жҚ®йҮҮйӣҶ->Kafka->е®һж—¶и®Ўз®—->дёҡеҠЎеә”з”ЁпјүпјҢжҲ‘们е®ҡдҪҚй—®йўҳйҖҡеёёйңҖиҰҒз»ҸиҝҮеӨҡдёӘеӣўйҳҹеҸҚеӨҚжІҹйҖҡдёҺжҺ’жҹҘжүҚиғҪеҸ‘зҺ°й—®йўҳеҲ°еә•еҮәзҺ°еңЁе“ӘдёӘзҺҜиҠӮпјҢиҝҷж ·жҺ’жҹҘй—®йўҳж•ҲзҺҮжҜ”иҫғдҪҺдёӢгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢжҲ‘们е°ұйңҖиҰҒдёҺдёҠдёӢжёёдёҖиө·жўізҗҶж•ҙдёӘй“ҫи·Ҝзҡ„зӣ‘жҺ§гҖӮеҮәзҺ°й—®йўҳж—¶пјҢ第дёҖж—¶й—ҙе®ҡдҪҚй—®йўҳеҮәзҺ°еңЁе“ӘдёӘзҺҜиҠӮпјҢзј©зҹӯй—®йўҳе®ҡдҪҚдёҺж•…йҡңжҒўеӨҚж—¶й—ҙгҖӮ
1.5 иө„жәҗйҡ”зҰ»
1.5.1 зӣёеҗҢйӣҶзҫӨдёҚеҗҢдёҡеҠЎиө„жәҗзү©зҗҶйҡ”зҰ»
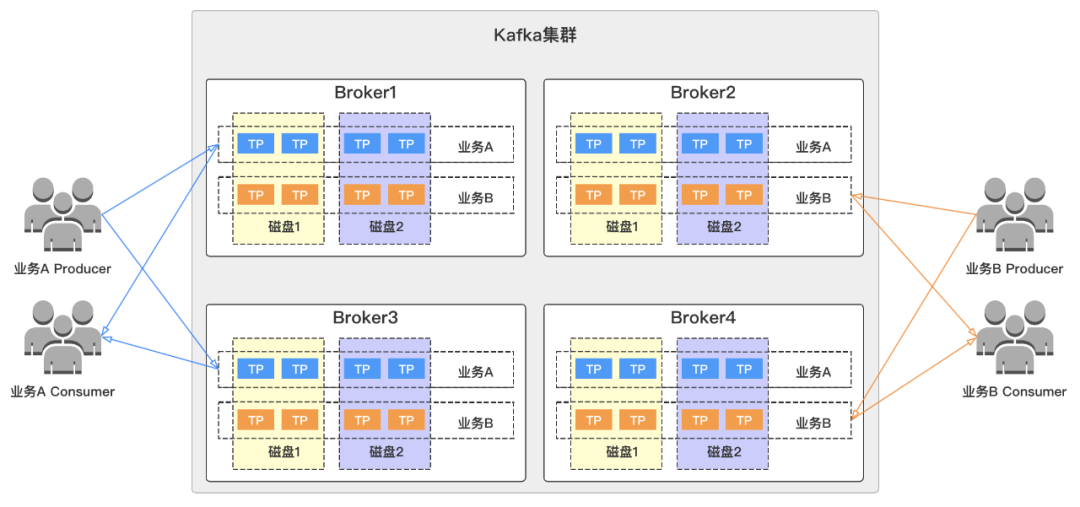
жҲ‘们еҜ№жүҖжңүйӣҶзҫӨдёӯдёҚеҗҢеҜ№дёҡеҠЎиҝӣиЎҢиө„жәҗз»„зү©зҗҶйҡ”зҰ»пјҢйҒҝе…Қеҗ„дёҡеҠЎд№Ӣй—ҙзӣёдә’еҪұе“ҚгҖӮеңЁиҝҷйҮҢпјҢжҲ‘们еҒҮи®ҫйӣҶзҫӨжңү4дёӘbrokerиҠӮзӮ№пјҲBroker1/Broker2/Broker3/Broker4пјүпјҢ2дёӘдёҡеҠЎпјҲдёҡеҠЎA/дёҡеҠЎBпјүпјҢ他们еҲҶеҲ«жӢҘжңүtopicеҲҶеҢәеҲҶеёғеҰӮдёӢеӣҫжүҖзӨәпјҢдёӨдёӘдёҡеҠЎtopicйғҪеҲҶж•ЈеңЁйӣҶзҫӨзҡ„еҗ„дёӘbrokerдёҠпјҢ并且еңЁзЈҒзӣҳеұӮйқўд№ҹеӯҳеңЁдәӨеҸүгҖӮ
иҜ•жғідёҖдёӢпјҢеҰӮжһңжҲ‘们其дёӯдёҖдёӘдёҡеҠЎејӮеёёпјҢжҜ”еҰӮжөҒйҮҸзӘҒеўһпјҢеҜјиҮҙbrokerиҠӮзӮ№ејӮеёёжҲ–иҖ…иў«жү“жҢӮгҖӮйӮЈд№Ҳиҝҷж—¶еҖҷеҸҰеӨ–дёҖдёӘдёҡеҠЎд№ҹе°ҶеҸ—еҲ°еҪұе“ҚпјҢиҝҷж ·е°ҶеӨ§еӨ§зҡ„еҪұе“ҚдәҶжҲ‘们жңҚеҠЎзҡ„еҸҜз”ЁжҖ§пјҢйҖ жҲҗж•…йҡңпјҢжү©еӨ§дәҶж•…йҡңеҪұе“ҚиҢғеӣҙгҖӮ
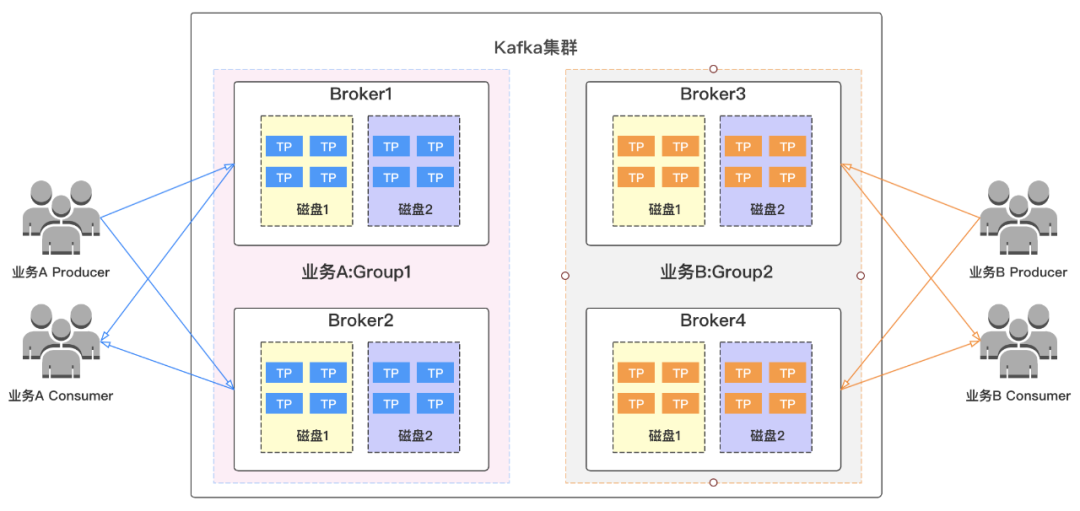
й’ҲеҜ№иҝҷдәӣз—ӣзӮ№пјҢжҲ‘们еҸҜд»ҘеҜ№йӣҶзҫӨдёӯзҡ„дёҡеҠЎиҝӣиЎҢзү©зҗҶиө„жәҗйҡ”зҰ»пјҢеҗ„дёҡеҠЎзӢ¬дә«иө„жәҗпјҢиҝӣиЎҢиө„жәҗз»„еҲ’еҲҶпјҲиҝҷйҮҢжҠҠ4еҗ„brokerеҲ’еҲҶдёәGroup1е’ҢGroup2дёӨдёӘиө„жәҗз»„пјүеҰӮдёӢеӣҫжүҖзӨәпјҢдёҚеҗҢдёҡеҠЎзҡ„topicеҲҶеёғеңЁиҮӘе·ұзҡ„иө„жәҗз»„еҶ…пјҢеҪ“е…¶дёӯдёҖдёӘдёҡеҠЎејӮеёёж—¶пјҢдёҚдјҡжіўеҸҠеҸҰеӨ–дёҖдёӘдёҡеҠЎпјҢиҝҷж ·е°ұеҸҜд»Ҙжңүж•Ҳзҡ„зј©е°ҸжҲ‘们зҡ„ж•…йҡңиҢғеӣҙпјҢжҸҗй«ҳжңҚеҠЎеҸҜз”ЁжҖ§гҖӮ
1.6 йӣҶзҫӨеҪ’зұ»
жҲ‘们жҠҠйӣҶзҫӨж №жҚ®дёҡеҠЎзү№зӮ№иҝӣиЎҢжӢҶеҲҶдёәж—Ҙеҝ—йӣҶзҫӨгҖҒзӣ‘жҺ§йӣҶзҫӨгҖҒи®Ўиҙ№йӣҶзҫӨгҖҒжҗңзҙўйӣҶзҫӨгҖҒзҰ»зәҝйӣҶзҫӨгҖҒеңЁзәҝйӣҶзҫӨзӯүпјҢдёҚеҗҢеңәжҷҜдёҡеҠЎж”ҫеңЁдёҚеҗҢйӣҶзҫӨпјҢйҒҝе…ҚдёҚеҗҢдёҡеҠЎзӣёдә’еҪұе“ҚгҖӮ
1.7 жү©е®№/зј©е®№
1.7.1 topicжү©е®№еҲҶеҢә
йҡҸзқҖtopicж•°жҚ®йҮҸеўһй•ҝпјҢжҲ‘们жңҖеҲқеҲӣе»әзҡ„topicжҢҮе®ҡзҡ„еҲҶеҢәдёӘж•°еҸҜиғҪе·Із»Ҹж— жі•ж»Ўи¶іж•°йҮҸжөҒйҮҸиҰҒжұӮпјҢжүҖд»ҘжҲ‘们йңҖиҰҒеҜ№topicзҡ„еҲҶеҢәиҝӣиЎҢжү©еұ•гҖӮжү©е®№еҲҶеҢәж—¶йңҖиҰҒиҖғиҷ‘дёҖдёӢеҮ зӮ№пјҡ
еҝ…йЎ»дҝқиҜҒtopicеҲҶеҢәleaderдёҺfollowerиҪ®иҜўзҡ„еҲҶеёғеңЁиө„жәҗз»„еҶ…жүҖжңүbrokerдёҠпјҢи®©жөҒйҮҸеҲҶеёғжӣҙеҠ еқҮиЎЎпјҢеҗҢж—¶йңҖиҰҒиҖғиҷ‘зӣёеҗҢеҲҶеҢәдёҚеҗҢеүҜжң¬и·Ёжңәжһ¶еҲҶеёғд»ҘжҸҗй«ҳе®№зҒҫиғҪеҠӣпјӣ
еҪ“topicеҲҶеҢәleaderдёӘж•°йҷӨд»Ҙиө„жәҗз»„иҠӮзӮ№дёӘж•°жңүдҪҷж•°ж—¶пјҢйңҖиҰҒжҠҠдҪҷж•°еҲҶеҢәleaderдјҳе…ҲиҖғиҷ‘ж”ҫе…ҘжөҒйҮҸиҫғдҪҺзҡ„brokerгҖӮ
1.7.2 brokerдёҠзәҝ
йҡҸзқҖдёҡеҠЎйҮҸеўһеӨҡпјҢж•°жҚ®йҮҸдёҚж–ӯеўһеӨ§пјҢжҲ‘们зҡ„йӣҶзҫӨд№ҹйңҖиҰҒиҝӣиЎҢbrokerиҠӮзӮ№жү©е®№гҖӮе…ідәҺжү©е®№пјҢжҲ‘们йңҖиҰҒе®һзҺ°д»ҘдёӢеҮ зӮ№пјҡ
жү©е®№жҷәиғҪиҜ„дј°пјҡж №жҚ®йӣҶзҫӨиҙҹиҪҪпјҢжҠҠжҳҜеҗҰйңҖиҰҒжү©е®№иҜ„дј°зЁӢеәҸеҢ–гҖҒжҷәиғҪеҢ–пјӣ
жҷәиғҪжү©е®№пјҡеҪ“иҜ„дј°йңҖиҰҒжү©е®№еҗҺпјҢжҠҠжү©е®№жөҒзЁӢд»ҘеҸҠжөҒйҮҸеқҮиЎЎе№іеҸ°еҢ–гҖӮ
1.7.3 brokerдёӢзәҝ
жҹҗдәӣеңәжҷҜдёӢпјҢжҲ‘们йңҖиҰҒдёӢзәҝжҲ‘们зҡ„brokerпјҢдё»иҰҒеҢ…жӢ¬д»ҘдёӢеҮ дёӘеңәжҷҜпјҡ
дёҖдәӣиҖҒеҢ–зҡ„жңҚеҠЎеҷЁйңҖиҰҒдёӢзәҝпјҢе®һзҺ°иҠӮзӮ№дёӢзәҝе№іеҸ°еҢ–пјӣ
жңҚеҠЎеҷЁж•…йҡңпјҢbrokerж•…йҡңж— жі•жҒўеӨҚпјҢжҲ‘们йңҖиҰҒдёӢзәҝж•…йҡңжңҚеҠЎеҷЁпјҢе®һзҺ°иҠӮзӮ№дёӢзәҝе№іеҸ°еҢ–пјӣ
жңүжӣҙдјҳй…ҚзҪ®зҡ„жңҚеҠЎеҷЁжӣҝжҚўе·ІжңүbrokerиҠӮзӮ№пјҢе®һзҺ°дёӢзәҝиҠӮзӮ№е№іеҸ°еҢ–гҖӮ
1.8 иҙҹиҪҪеқҮиЎЎ
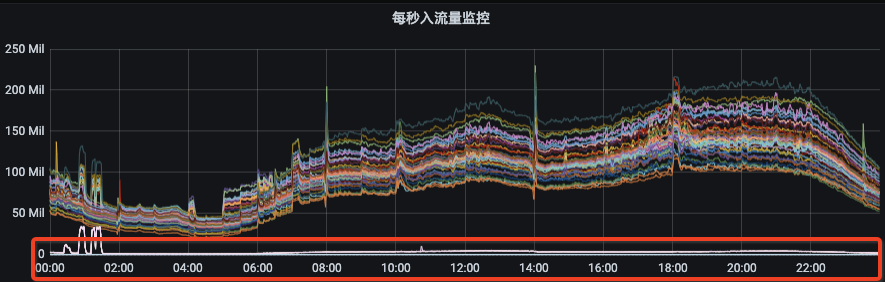
жҲ‘们дёәд»Җд№ҲйңҖиҰҒиҙҹиҪҪеқҮиЎЎе‘ўпјҹйҰ–е…ҲпјҢжҲ‘们жқҘзңӢ第дёҖеј еӣҫпјҢдёӢеӣҫжҳҜжҲ‘们йӣҶзҫӨжҹҗдёӘиө„жәҗз»„еҲҡжү©е®№еҗҺзҡ„жөҒйҮҸеҲҶеёғжғ…еҶөпјҢжөҒйҮҸж— жі•иҮӘеҠЁзҡ„еҲҶж‘ҠеҲ°жҲ‘们新жү©е®№еҗҺзҡ„иҠӮзӮ№дёҠгҖӮйӮЈд№ҲиҝҷдёӘж—¶еҖҷйңҖиҰҒжҲ‘们жүӢеҠЁеҺ»и§ҰеҸ‘ж•°жҚ®иҝҒ移пјҢжҠҠйғЁеҲҶеүҜжң¬иҝҒ移иҮіж–°иҠӮзӮ№дёҠжүҚиғҪе®һзҺ°жөҒйҮҸеқҮиЎЎгҖӮ
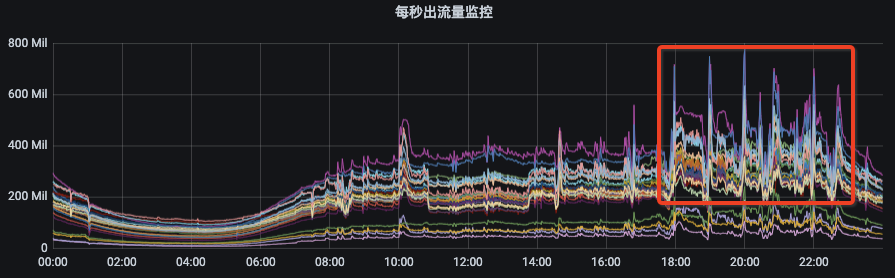
дёӢйқўпјҢжҲ‘们жқҘзңӢдёҖдёӢ第дәҢеј еӣҫгҖӮиҝҷеј еӣҫжҲ‘们еҸҜд»ҘзңӢеҮәжөҒйҮҸеҲҶеёғйқһеёёдёҚеқҮиЎЎпјҢжңҖдҪҺе’ҢжңҖй«ҳжөҒйҮҸеҒҸе·®ж•°еҖҚд»ҘдёҠгҖӮиҝҷе’ҢKafkaзҡ„жһ¶жһ„зү№зӮ№жңүе…іпјҢеҪ“йӣҶзҫӨ规模дёҺж•°жҚ®йҮҸиҫҫеҲ°дёҖе®ҡйҮҸеҗҺпјҢеҝ…然еҮәзҺ°еҪ“й—®йўҳгҖӮиҝҷз§Қжғ…еҶөдёӢпјҢжҲ‘们д№ҹйңҖиҰҒиҝӣиЎҢиҙҹиҪҪеқҮиЎЎгҖӮ

жҲ‘们еҶҚжқҘзңӢзңӢ第дёүеј еӣҫгҖӮиҝҷйҮҢжҲ‘们еҸҜд»ҘзңӢеҮәеҮәжөҒйҮҸеҸӘжңүйғЁеҲҶиҠӮзӮ№зӘҒеўһпјҢиҝҷе°ұжҳҜtopicеҲҶеҢәеңЁйӣҶзҫӨеҶ…йғЁдёҚеӨҹеҲҶж•ЈпјҢйӣҶдёӯеҲҶеёғеҲ°дәҶжҹҗеҮ дёӘbrokerеҜјиҮҙпјҢиҝҷз§Қжғ…еҶөжҲ‘们д№ҹйңҖиҰҒиҝӣиЎҢжү©е®№еҲҶеҢәе’ҢеқҮиЎЎгҖӮ
жҲ‘们жҜ”иҫғзҗҶжғізҡ„жөҒйҮҸеҲҶеёғеә”иҜҘеҰӮдёӢеӣҫжүҖзӨәпјҢеҗ„иҠӮзӮ№й—ҙжөҒйҮҸеҒҸе·®йқһеёёе°ҸпјҢиҝҷз§Қжғ…еҶөдёӢпјҢж—ўеҸҜд»ҘеўһејәйӣҶзҫӨжүӣдҪҸжөҒйҮҸејӮеёёзӘҒеўһзҡ„иғҪеҠӣеҸҲеҸҜд»ҘжҸҗеҚҮйӣҶзҫӨж•ҙдҪ“иө„жәҗеҲ©з”ЁзҺҮе’ҢжңҚеҠЎзЁіе®ҡжҖ§пјҢйҷҚдҪҺжҲҗжң¬гҖӮ

иҙҹиҪҪеқҮиЎЎжҲ‘们йңҖиҰҒе®һзҺ°д»ҘдёӢж•Ҳжһңпјҡ
1пјүз”ҹжҲҗеүҜжң¬иҝҒ移计еҲ’д»ҘеҸҠжү§иЎҢиҝҒ移任еҠЎе№іеҸ°еҢ–гҖҒиҮӘеҠЁеҢ–гҖҒжҷәиғҪеҢ–пјӣ
2пјүжү§иЎҢеқҮиЎЎеҗҺbrokerй—ҙжөҒйҮҸжҜ”иҫғеқҮеҢҖпјҢдё”еҚ•дёӘtopicеҲҶеҢәеқҮеҢҖеҲҶеёғеңЁжүҖжңүbrokerиҠӮзӮ№дёҠпјӣ
3пјүжү§иЎҢеқҮиЎЎеҗҺbrokerеҶ…йғЁеӨҡеқ—зЈҒзӣҳй—ҙжөҒйҮҸжҜ”иҫғеқҮиЎЎпјӣ
иҰҒе®һзҺ°иҝҷдёӘж•ҲжһңпјҢжҲ‘们йңҖиҰҒејҖеҸ‘дёҖеҘ—иҮӘе·ұзҡ„иҙҹиҪҪеқҮиЎЎе·Ҙе…·пјҢеҰӮеҜ№ејҖжәҗзҡ„ cruise controlиҝӣиЎҢдәҢж¬ЎејҖеҸ‘пјӣжӯӨе·Ҙе…·зҡ„ж ёеҝғдё»иҰҒеңЁз”ҹжҲҗиҝҒ移计еҲ’зҡ„зӯ–з•ҘпјҢиҝҒ移计еҲ’зҡ„з”ҹжҲҗж–№жЎҲзӣҙжҺҘеҪұе“ҚеҲ°жңҖеҗҺйӣҶзҫӨиҙҹиҪҪеқҮиЎЎзҡ„ж•ҲжһңгҖӮеҸӮиҖғеҶ…е®№пјҡ
1. linkedIn/cruise-control
2. Introduction to Kafka Cruise Control
3. Cloudera Cruise Control REST API Reference
cruise controlжһ¶жһ„еӣҫеҰӮдёӢпјҡ

еңЁз”ҹжҲҗиҝҒ移计еҲ’ж—¶пјҢжҲ‘们йңҖиҰҒиҖғиҷ‘д»ҘдёӢеҮ зӮ№пјҡ
1пјүйҖүжӢ©ж ёеҝғжҢҮж ҮдҪңдёәз”ҹжҲҗиҝҒ移计еҲ’зҡ„дҫқжҚ®пјҢжҜ”еҰӮеҮәжөҒйҮҸгҖҒе…ҘжөҒйҮҸгҖҒжңәжһ¶гҖҒеҚ•topicеҲҶеҢәеҲҶж•ЈжҖ§зӯүпјӣ
2пјүдјҳеҢ–з”ЁжқҘз”ҹжҲҗиҝҒ移计еҲ’зҡ„жҢҮж Үж ·жң¬пјҢжҜ”еҰӮиҝҮж»ӨжөҒйҮҸзӘҒеўһ/зӘҒйҷҚ/жҺүйӣ¶зӯүејӮеёёж ·жң¬пјӣ
3пјүеҗ„иө„жәҗз»„зҡ„иҝҒ移计еҲ’йңҖиҰҒдҪҝз”Ёзҡ„ж ·жң¬е…ЁйғЁдёәиө„жәҗз»„еҶ…йғЁж ·жң¬пјҢдёҚж¶үеҸҠе…¶д»–иө„жәҗз»„пјҢж— дәӨеҸүпјӣ
4пјүжІ»зҗҶеҚ•еҲҶеҢәиҝҮеӨ§topicпјҢи®©topicеҲҶеҢәеҲҶеёғжӣҙеҲҶж•ЈпјҢжөҒйҮҸдёҚйӣҶдёӯеңЁйғЁеҲҶbrokerпјҢи®©topicеҚ•еҲҶеҢәж•°жҚ®йҮҸжӣҙе°ҸпјҢиҝҷж ·еҸҜд»ҘеҮҸе°‘иҝҒ移зҡ„ж•°жҚ®йҮҸпјҢжҸҗеҚҮиҝҒ移йҖҹеәҰпјӣ
5пјүе·Із»ҸеқҮеҢҖеҲҶж•ЈеңЁиө„жәҗз»„еҶ…зҡ„topicпјҢеҠ е…ҘиҝҒ移黑еҗҚеҚ•пјҢдёҚеҒҡиҝҒ移пјҢиҝҷж ·еҸҜд»ҘеҮҸе°‘иҝҒ移зҡ„ж•°жҚ®йҮҸпјҢжҸҗеҚҮиҝҒ移йҖҹеәҰпјӣ
6пјүеҒҡtopicжІ»зҗҶпјҢжҺ’йҷӨй•ҝжңҹж— жөҒйҮҸtopicеҜ№еқҮиЎЎзҡ„е№Іжү°пјӣ
7пјүж–°е»әtopicжҲ–иҖ…topicеҲҶеҢәжү©е®№ж—¶пјҢеә”и®©жүҖжңүеҲҶеҢәиҪ®иҜўеҲҶеёғеңЁжүҖжңүbrokerиҠӮзӮ№пјҢиҪ®иҜўеҗҺдҪҷж•°еҲҶеҢәдјҳе…ҲеҲҶеёғжөҒйҮҸиҫғдҪҺзҡ„brokerпјӣ
8пјүжү©е®№brokerиҠӮзӮ№еҗҺејҖеҗҜиҙҹиҪҪеқҮиЎЎж—¶пјҢдјҳе…ҲжҠҠеҗҢдёҖbrokerеҲҶй…ҚдәҶеҗҢдёҖеӨ§жөҒйҮҸпјҲжөҒйҮҸеӨ§иҖҢдёҚжҳҜеӯҳеӮЁз©әй—ҙеӨ§пјҢиҝҷйҮҢеҸҜд»Ҙи®ӨдёәжҳҜжҜҸз§’зҡ„еҗһеҗҗйҮҸпјүtopicеӨҡдёӘеҲҶеҢәleaderзҡ„пјҢиҝҒ移дёҖйғЁеҲҶеҲ°ж–°brokerиҠӮзӮ№пјӣ
9пјүжҸҗдәӨиҝҒ移任еҠЎж—¶пјҢеҗҢдёҖжү№иҝҒ移计еҲ’дёӯзҡ„еҲҶеҢәж•°жҚ®еӨ§е°ҸеҒҸе·®еә”иҜҘе°ҪеҸҜиғҪе°ҸпјҢиҝҷж ·еҸҜд»ҘйҒҝе…ҚиҝҒ移任еҠЎдёӯе°ҸеҲҶеҢәиҝҒ移е®ҢжҲҗеҗҺй•ҝж—¶й—ҙзӯүеҫ…еӨ§еҲҶеҢәзҡ„иҝҒ移пјҢйҖ жҲҗд»»еҠЎеҖҫж–ңпјӣ
1.9 е®үе…Ёи®ӨиҜҒ
жҳҜдёҚжҳҜжҲ‘们зҡ„йӣҶзҫӨжүҖжңүдәәйғҪеҸҜд»ҘйҡҸж„Ҹи®ҝй—®е‘ўпјҹеҪ“然дёҚжҳҜпјҢдёәдәҶйӣҶзҫӨзҡ„е®үе…ЁпјҢжҲ‘们йңҖиҰҒиҝӣиЎҢжқғйҷҗи®ӨиҜҒпјҢеұҸи”Ҫйқһжі•ж“ҚдҪңгҖӮдё»иҰҒеҢ…жӢ¬д»ҘдёӢеҮ дёӘж–№йқўйңҖиҰҒеҒҡе®үе…Ёи®ӨиҜҒпјҡ
(1)з”ҹдә§иҖ…жқғйҷҗи®ӨиҜҒпјӣ
(2)ж¶Ҳиҙ№иҖ…жқғйҷҗи®ӨиҜҒпјӣ
(3)жҢҮе®ҡж•°жҚ®зӣ®еҪ•иҝҒ移е®үе…Ёи®ӨиҜҒпјӣ
е®ҳзҪ‘ең°еқҖпјҡhttp://kafka.apache.org
1.10 йӣҶзҫӨе®№зҒҫ
и·Ёжңәжһ¶е®№зҒҫпјҡ
е®ҳзҪ‘ең°еқҖпјҡhttp://kafka.apache.org
**и·ЁйӣҶзҫӨ/жңәжҲҝе®№зҒҫпјҡ**еҰӮжһңжңүејӮең°еҸҢжҙ»зӯүдёҡеҠЎеңәжҷҜж—¶пјҢеҸҜд»ҘеҸӮиҖғKafka2.7зүҲжң¬зҡ„MirrorMaker 2.0гҖӮ
GitHubең°еқҖпјҡhttps://github.com
зІҫзЎ®KIPең°еқҖ пјҡhttps://cwiki.apache.org
**ZooKeeperйӣҶзҫӨдёҠKafkaе…ғж•°жҚ®жҒўеӨҚпјҡ**жҲ‘们дјҡе®ҡжңҹеҜ№ZooKeeperдёҠзҡ„жқғйҷҗдҝЎжҒҜж•°жҚ®еҒҡеӨҮд»ҪеӨ„зҗҶпјҢеҪ“йӣҶзҫӨе…ғж•°жҚ®ејӮеёёж—¶з”ЁдәҺжҒўеӨҚгҖӮ
1.11 еҸӮж•°/й…ҚзҪ®дјҳеҢ–
**brokerжңҚеҠЎеҸӮж•°дјҳеҢ–пјҡ**иҝҷйҮҢжҲ‘еҸӘеҲ—дёҫйғЁеҲҶеҪұе“ҚжҖ§иғҪзҡ„ж ёеҝғеҸӮж•°гҖӮ
num.network.threads
#еҲӣе»әProcessorеӨ„зҗҶзҪ‘з»ңиҜ·жұӮзәҝзЁӢдёӘж•°пјҢе»әи®®и®ҫзҪ®дёәbrokerеҪ“CPUж ёеҝғж•°*2пјҢиҝҷдёӘеҖјеӨӘдҪҺз»ҸеёёеҮәзҺ°зҪ‘з»ңз©әй—ІеӨӘдҪҺиҖҢзјәеӨұеүҜжң¬гҖӮ
num.io.threads
#еҲӣе»әKafkaRequestHandlerеӨ„зҗҶе…·дҪ“иҜ·жұӮзәҝзЁӢдёӘж•°пјҢе»әи®®и®ҫзҪ®дёәbrokerзЈҒзӣҳдёӘж•°*2
num.replica.fetchers
#е»әи®®и®ҫзҪ®дёәCPUж ёеҝғж•°/4пјҢйҖӮеҪ“жҸҗй«ҳеҸҜд»ҘжҸҗеҚҮCPUеҲ©з”ЁзҺҮеҸҠfollowerеҗҢжӯҘleaderж•°жҚ®еҪ“并иЎҢеәҰгҖӮ
compression.type
#е»әи®®йҮҮз”Ёlz4еҺӢзј©зұ»еһӢпјҢеҺӢзј©еҸҜд»ҘжҸҗеҚҮCPUеҲ©з”ЁзҺҮеҗҢж—¶еҸҜд»ҘеҮҸе°‘зҪ‘з»ңдј иҫ“ж•°жҚ®йҮҸгҖӮ
queued.max.requests
#еҰӮжһңжҳҜз”ҹдә§зҺҜеўғпјҢе»әи®®й…ҚзҪ®жңҖе°‘500д»ҘдёҠпјҢй»ҳи®Өдёә500гҖӮ
log.flush.scheduler.interval.ms
log.flush.interval.ms
log.flush.interval.messages
#иҝҷеҮ дёӘеҸӮж•°иЎЁзӨәж—Ҙеҝ—ж•°жҚ®еҲ·ж–°еҲ°зЈҒзӣҳзҡ„зӯ–з•ҘпјҢеә”иҜҘдҝқжҢҒй»ҳи®Өй…ҚзҪ®пјҢеҲ·зӣҳзӯ–з•Ҙи®©ж“ҚдҪңзі»з»ҹеҺ»е®ҢжҲҗпјҢз”ұж“ҚдҪңзі»з»ҹжқҘеҶіе®ҡд»Җд№Ҳж—¶еҖҷжҠҠж•°жҚ®еҲ·зӣҳпјӣ
#еҰӮжһңи®ҫзҪ®жқҘиҝҷдёӘеҸӮж•°пјҢеҸҜиғҪеҜ№еҗһеҗҗйҮҸеҪұе“ҚйқһеёёеӨ§пјӣ
auto.leader.rebalance.enable
#иЎЁзӨәжҳҜеҗҰејҖеҗҜleaderиҮӘеҠЁиҙҹиҪҪеқҮиЎЎпјҢй»ҳи®ӨtrueпјӣжҲ‘们еә”иҜҘжҠҠиҝҷдёӘеҸӮж•°и®ҫзҪ®дёәfalseпјҢеӣ дёәиҮӘеҠЁиҙҹиҪҪеқҮиЎЎдёҚеҸҜжҺ§пјҢеҸҜиғҪеҪұе“ҚйӣҶзҫӨжҖ§иғҪе’ҢзЁіе®ҡпјӣ
**з”ҹдә§дјҳеҢ–пјҡ**иҝҷйҮҢжҲ‘еҸӘеҲ—дёҫйғЁеҲҶеҪұе“ҚжҖ§иғҪзҡ„ж ёеҝғеҸӮж•°гҖӮ
linger.ms
#е®ўжҲ·з«Ҝз”ҹдә§ж¶ҲжҒҜзӯүеҫ…еӨҡд№…ж—¶й—ҙжүҚеҸ‘йҖҒеҲ°жңҚеҠЎз«ҜпјҢеҚ•дҪҚпјҡжҜ«з§’гҖӮе’Ңbatch.sizeеҸӮж•°й…ҚеҗҲдҪҝз”ЁпјӣйҖӮеҪ“и°ғеӨ§еҸҜд»ҘжҸҗеҚҮеҗһеҗҗйҮҸпјҢдҪҶжҳҜеҰӮжһңе®ўжҲ·з«ҜеҰӮжһңdownжңәжңүдёўеӨұж•°жҚ®йЈҺйҷ©пјӣ
batch.size
#е®ўжҲ·з«ҜеҸ‘йҖҒеҲ°жңҚеҠЎз«Ҝж¶ҲжҒҜжү№ж¬ЎеӨ§е°ҸпјҢе’Ңlinger.msеҸӮж•°й…ҚеҗҲдҪҝз”ЁпјӣйҖӮеҪ“и°ғеӨ§еҸҜд»ҘжҸҗеҚҮеҗһеҗҗйҮҸпјҢдҪҶжҳҜеҰӮжһңе®ўжҲ·з«ҜеҰӮжһңdownжңәжңүдёўеӨұж•°жҚ®йЈҺйҷ©пјӣ
compression.type
#е»әи®®йҮҮз”Ёlz4еҺӢзј©зұ»еһӢпјҢе…·еӨҮиҫғй«ҳзҡ„еҺӢзј©жҜ”еҸҠеҗһеҗҗйҮҸпјӣз”ұдәҺKafkaеҜ№CPUзҡ„иҰҒжұӮ并дёҚй«ҳпјҢжүҖд»ҘпјҢеҸҜд»ҘйҖҡиҝҮеҺӢзј©пјҢе……еҲҶеҲ©з”ЁCPUиө„жәҗд»ҘжҸҗеҚҮзҪ‘з»ңеҗһеҗҗйҮҸпјӣ
buffer.memory
#е®ўжҲ·з«Ҝзј“еҶІеҢәеӨ§е°ҸпјҢеҰӮжһңtopicжҜ”иҫғеӨ§пјҢдё”еҶ…еӯҳжҜ”иҫғе……и¶іпјҢеҸҜд»ҘйҖӮеҪ“и°ғй«ҳиҝҷдёӘеҸӮж•°пјҢй»ҳи®ӨеҸӘдёә33554432(32MB)
retries
#з”ҹдә§еӨұиҙҘеҗҺзҡ„йҮҚиҜ•ж¬Ўж•°пјҢй»ҳи®Ө0пјҢеҸҜд»ҘйҖӮеҪ“еўһеҠ гҖӮеҪ“йҮҚиҜ•и¶…иҝҮдёҖе®ҡж¬Ўж•°еҗҺпјҢеҰӮжһңдёҡеҠЎиҰҒжұӮж•°жҚ®еҮҶзЎ®жҖ§иҫғй«ҳпјҢе»әи®®еҒҡе®№й”ҷеӨ„зҗҶгҖӮ
retry.backoff.ms
#з”ҹдә§еӨұиҙҘеҗҺпјҢйҮҚиҜ•ж—¶й—ҙй—ҙйҡ”пјҢй»ҳи®Ө100msпјҢе»әи®®дёҚиҰҒи®ҫзҪ®еӨӘеӨ§жҲ–иҖ…еӨӘе°ҸгҖӮ
йҷӨдәҶдёҖдәӣж ёеҝғеҸӮж•°дјҳеҢ–еӨ–пјҢжҲ‘们иҝҳйңҖиҰҒиҖғиҷ‘жҜ”еҰӮtopicзҡ„еҲҶеҢәдёӘж•°е’Ңtopicдҝқз•ҷж—¶й—ҙпјӣеҰӮжһңеҲҶеҢәдёӘж•°еӨӘе°‘пјҢдҝқз•ҷж—¶й—ҙеӨӘй•ҝпјҢдҪҶжҳҜеҶҷе…Ҙж•°жҚ®йҮҸйқһеёёеӨ§зҡ„иҜқпјҢеҸҜиғҪйҖ жҲҗд»ҘдёӢй—®йўҳпјҡ
1пјүtopicеҲҶеҢәйӣҶдёӯиҗҪеңЁжҹҗеҮ дёӘbrokerиҠӮзӮ№дёҠпјҢеҜјиҮҙжөҒйҮҸеүҜжң¬еӨұиЎЎпјӣ
2пјүеҜјиҮҙbrokerиҠӮзӮ№еҶ…йғЁжҹҗеҮ еқ—зЈҒзӣҳиҜ»еҶҷи¶…иҙҹиҪҪпјҢеӯҳеӮЁиў«еҶҷзҲҶпјӣ
1.11.1 ж¶Ҳиҙ№дјҳеҢ–
ж¶Ҳиҙ№жңҖеӨ§зҡ„й—®йўҳпјҢ并且з»ҸеёёеҮәзҺ°зҡ„й—®йўҳе°ұжҳҜж¶Ҳиҙ№е»¶ж—¶пјҢжӢүеҺҶеҸІж•°жҚ®гҖӮеҪ“еӨ§йҮҸжӢүеҸ–еҺҶеҸІж•°жҚ®ж—¶е°ҶеҮәзҺ°еӨ§йҮҸиҜ»зӣҳж“ҚдҪңпјҢжұЎжҹ“pagecacheпјҢиҝҷдёӘе°ҶеҠ йҮҚзЈҒзӣҳзҡ„иҙҹиҪҪпјҢеҪұе“ҚйӣҶзҫӨжҖ§иғҪе’ҢзЁіе®ҡпјӣ
еҸҜд»ҘжҖҺж ·еҮҸе°‘жҲ–иҖ…йҒҝе…ҚеӨ§йҮҸж¶Ҳиҙ№е»¶ж—¶е‘ўпјҹ
1пјүеҪ“topicж•°жҚ®йҮҸйқһеёёеӨ§ж—¶пјҢе»әи®®дёҖдёӘеҲҶеҢәејҖеҗҜдёҖдёӘзәҝзЁӢеҺ»ж¶Ҳиҙ№пјӣ
2пјүеҜ№topicж¶Ҳиҙ№е»¶ж—¶ж·»еҠ зӣ‘жҺ§е‘ҠиӯҰпјҢеҸҠж—¶еҸ‘зҺ°еӨ„зҗҶпјӣ
3пјүеҪ“topicж•°жҚ®еҸҜд»Ҙдёўејғж—¶пјҢйҒҮеҲ°и¶…еӨ§е»¶ж—¶пјҢжҜ”еҰӮеҚ•дёӘеҲҶеҢә延иҝҹи®°еҪ•и¶…иҝҮеҚғдёҮз”ҡиҮіж•°дәҝпјҢйӮЈд№ҲеҸҜд»ҘйҮҚзҪ®topicзҡ„ж¶Ҳиҙ№зӮ№дҪҚиҝӣиЎҢзҙ§жҖҘеӨ„зҗҶпјӣгҖҗжӯӨж–№жЎҲдёҖиҲ¬еңЁжһҒз«ҜеңәжҷҜжүҚдҪҝз”ЁгҖ‘
4пјүйҒҝе…ҚйҮҚзҪ®topicзҡ„еҲҶеҢәoffsetеҲ°еҫҲж—©зҡ„дҪҚзҪ®пјҢиҝҷеҸҜиғҪйҖ жҲҗжӢүеҸ–еӨ§йҮҸеҺҶеҸІж•°жҚ®пјӣ
1.11.2 LinuxжңҚеҠЎеҷЁеҸӮж•°дјҳеҢ–
жҲ‘们йңҖиҰҒеҜ№Linuxзҡ„ж–Ү件еҸҘжҹ„гҖҒpagecacheзӯүеҸӮж•°иҝӣиЎҢдјҳеҢ–гҖӮеҸҜеҸӮиҖғгҖҠLinux Page Cacheи°ғдјҳеңЁKafkaдёӯзҡ„еә”з”ЁгҖӢгҖӮ
1.12.硬件дјҳеҢ–
зЈҒзӣҳдјҳеҢ–
еңЁжқЎд»¶е…Ғи®ёзҡ„жғ…еҶөдёӢпјҢеҸҜд»ҘйҮҮз”ЁSSDеӣәжҖҒзЎ¬зӣҳжӣҝжҚўHDDжңәжў°зЎ¬зӣҳпјҢи§ЈеҶіжңәжў°зӣҳIOжҖ§иғҪиҫғдҪҺзҡ„й—®йўҳпјӣеҰӮжһңжІЎжңүSSDеӣәжҖҒзЎ¬зӣҳпјҢеҲҷеҸҜд»ҘеҜ№жңҚеҠЎеҷЁдёҠзҡ„еӨҡеқ—зЎ¬зӣҳеҒҡзЎ¬RAIDпјҲдёҖиҲ¬йҮҮз”ЁRAID10пјүпјҢи®©brokerиҠӮзӮ№зҡ„IOиҙҹиҪҪжӣҙеҠ еқҮиЎЎгҖӮеҰӮжһңжҳҜHDDжңәжў°зЎ¬зӣҳпјҢдёҖдёӘbrokerеҸҜд»ҘжҢӮиҪҪеӨҡеқ—зЎ¬зӣҳпјҢжҜ”еҰӮ 12еқ—*4TBгҖӮ
еҶ…еӯҳ
з”ұдәҺKafkaеұһдәҺй«ҳйў‘иҜ»еҶҷеһӢжңҚеҠЎпјҢиҖҢLinuxзҡ„иҜ»еҶҷиҜ·жұӮеҹәжң¬иө°зҡ„йғҪжҳҜPage CacheпјҢжүҖд»ҘеҚ•иҠӮзӮ№еҶ…еӯҳеӨ§дёҖдәӣеҜ№жҖ§иғҪдјҡжңүжҜ”иҫғжҳҺжҳҫзҡ„жҸҗеҚҮгҖӮдёҖиҲ¬йҖүжӢ©256GBжҲ–иҖ…жӣҙй«ҳгҖӮ
зҪ‘з»ң
жҸҗеҚҮзҪ‘з»ңеёҰе®ҪпјҡеңЁжқЎд»¶е…Ғи®ёзҡ„жғ…еҶөдёӢпјҢзҪ‘з»ңеёҰе®Ҫи¶ҠеӨ§и¶ҠеҘҪгҖӮеӣ дёәиҝҷж ·зҪ‘з»ңеёҰе®ҪжүҚдёҚдјҡжҲҗдёәжҖ§иғҪ瓶йўҲпјҢжңҖе°‘д№ҹиҰҒиҫҫеҲ°дёҮе…ҶзҪ‘з»ңпјҲ 10GbпјҢзҪ‘еҚЎдёәе…ЁеҸҢе·ҘпјүжүҚиғҪе…·еӨҮзӣёеҜ№иҫғй«ҳзҡ„еҗһеҗҗйҮҸгҖӮеҰӮжһңжҳҜеҚ•йҖҡйҒ“пјҢзҪ‘з»ңеҮәжөҒйҮҸдёҺе…ҘжөҒйҮҸд№Ӣе’Ңзҡ„дёҠйҷҗзҗҶи®әеҖјжҳҜ1.25GB/sпјӣеҰӮжһңжҳҜеҸҢе·ҘеҸҢйҖҡйҒ“пјҢзҪ‘з»ңеҮәе…ҘжөҒйҮҸзҗҶи®әеҖјйғҪеҸҜд»ҘиҫҫеҲ°1.25GB/sгҖӮ
зҪ‘з»ңйҡ”зҰ»жү“ж Үпјҡз”ұдәҺдёҖдёӘжңәжҲҝеҸҜиғҪж—ўйғЁзҪІжңүзҰ»зәҝйӣҶзҫӨпјҲжҜ”еҰӮHBaseгҖҒSparkгҖҒHadoopзӯүпјүеҸҲйғЁзҪІжңүе®һж—¶йӣҶзҫӨпјҲеҰӮKafkaпјүгҖӮйӮЈд№Ҳе®һж—¶йӣҶзҫӨе’ҢзҰ»зәҝйӣҶзҫӨжҢӮиҪҪеҲ°еҗҢдёҖдёӘдәӨжҚўжңәдёӢзҡ„жңҚеҠЎеҷЁе°ҶеҮәзҺ°з«һдәүзҪ‘з»ңеёҰе®Ҫзҡ„й—®йўҳпјҢзҰ»зәҝйӣҶзҫӨеҸҜиғҪеҜ№е®һж—¶йӣҶзҫӨйҖ жҲҗеҪұе“ҚгҖӮжүҖд»ҘжҲ‘们йңҖиҰҒиҝӣиЎҢдәӨжҚўжңәеұӮйқўзҡ„йҡ”зҰ»пјҢи®©зҰ»зәҝжңәеҷЁе’Ңе®һж—¶йӣҶзҫӨдёҚиҰҒжҢӮиҪҪеҲ°зӣёеҗҢзҡ„дәӨжҚўжңәдёӢгҖӮеҚідҪҝжңүжҢӮиҪҪеҲ°зӣёеҗҢдәӨжҚўжңәдёӢйқўзҡ„пјҢжҲ‘们д№ҹе°ҶиҝӣиЎҢзҪ‘з»ңйҖҡиЎҢдјҳе…Ҳзә§пјҲйҮ‘гҖҒ银гҖҒй“ңгҖҒй“Ғпјүж Үи®°пјҢеҪ“зҪ‘з»ңеёҰе®Ҫзҙ§еј зҡ„ж—¶еҖҷпјҢи®©е®һж—¶дёҡеҠЎдјҳе…ҲйҖҡиЎҢгҖӮ
CPU
Kafkaзҡ„瓶йўҲдёҚеңЁCPUпјҢеҚ•иҠӮзӮ№дёҖиҲ¬жңү32ж ёзҡ„CPUйғҪи¶іеӨҹдҪҝз”ЁгҖӮ
1.13.е№іеҸ°еҢ–
зҺ°еңЁй—®йўҳжқҘдәҶпјҢеүҚйқўжҲ‘们жҸҗеҲ°еҫҲеӨҡзӣ‘жҺ§гҖҒдјҳеҢ–зӯүжүӢж®өпјӣйҡҫйҒ“жҲ‘们管зҗҶе‘ҳжҲ–иҖ…дёҡеҠЎз”ЁжҲ·еҜ№йӣҶзҫӨжүҖжңүзҡ„ж“ҚдҪңйғҪйңҖиҰҒзҷ»еҪ•йӣҶзҫӨжңҚеҠЎеҷЁеҗ—пјҹзӯ”жЎҲеҪ“然жҳҜеҗҰе®ҡзҡ„пјҢжҲ‘们йңҖиҰҒдё°еҜҢзҡ„е№іеҸ°еҢ–еҠҹиғҪжқҘж”ҜжҢҒгҖӮдёҖж–№йқўжҳҜдёәдәҶжҸҗеҚҮжҲ‘们ж“ҚдҪңзҡ„ж•ҲзҺҮпјҢеҸҰеӨ–дёҖж–№йқўд№ҹжҳҜдёәдәҶжҸҗеҚҮйӣҶзҫӨзҡ„зЁіе®ҡе’ҢйҷҚдҪҺеҮәй”ҷзҡ„еҸҜиғҪгҖӮ
й…ҚзҪ®з®ЎзҗҶ
й»‘еұҸж“ҚдҪңпјҢжҜҸж¬Ўдҝ®ж”№brokerзҡ„server.propertiesй…ҚзҪ®ж–Ү件йғҪжІЎжңүеҸҳжӣҙи®°еҪ•еҸҜиҝҪжәҜпјҢжңүж—¶еҸҜиғҪеӣ дёәжңүдәәдҝ®ж”№дәҶйӣҶзҫӨй…ҚзҪ®еҜјиҮҙдёҖдәӣж•…йҡңпјҢеҚҙжүҫдёҚеҲ°зӣёе…іи®°еҪ•гҖӮеҰӮжһңжҲ‘们жҠҠй…ҚзҪ®з®ЎзҗҶеҒҡеҲ°е№іеҸ°дёҠпјҢжҜҸж¬ЎеҸҳжӣҙйғҪжңүиҝ№еҸҜеҫӘпјҢеҗҢж—¶йҷҚдҪҺдәҶеҸҳжӣҙеҮәй”ҷзҡ„йЈҺйҷ©гҖӮ
ж»ҡеҠЁйҮҚеҗҜ
еҪ“жҲ‘们йңҖиҰҒеҒҡзәҝдёҠеҸҳжӣҙж—¶пјҢжңүж—¶еҖҷйңҖиҰҒеҜ№йӣҶзҫӨеҜ№еӨҡдёӘиҠӮзӮ№еҒҡж»ҡеҠЁйҮҚеҗҜпјҢеҰӮжһңеҲ°е‘Ҫд»ӨиЎҢеҺ»ж“ҚдҪңпјҢйӮЈж•ҲзҺҮе°ҶеҸҳеҫ—еҫҲдҪҺпјҢиҖҢдё”йңҖиҰҒдәәе·ҘеҺ»е№Ійў„пјҢжөӘиҙ№дәәеҠӣгҖӮиҝҷдёӘж—¶еҖҷжҲ‘们е°ұйңҖиҰҒжҠҠиҝҷз§ҚйҮҚеӨҚжҖ§зҡ„е·ҘдҪңиҝӣиЎҢе№іеҸ°еҢ–пјҢжҸҗеҚҮжҲ‘们зҡ„ж“ҚдҪңж•ҲзҺҮгҖӮ
йӣҶзҫӨз®ЎзҗҶ
йӣҶзҫӨз®ЎзҗҶдё»иҰҒжҳҜжҠҠеҺҹжқҘеңЁе‘Ҫд»ӨиЎҢзҡ„дёҖзі»еҲ—ж“ҚдҪңеҒҡеҲ°е№іеҸ°дёҠпјҢз”ЁжҲ·е’Ңз®ЎзҗҶе‘ҳдёҚеҶҚйңҖиҰҒй»‘еұҸж“ҚдҪңKafkaйӣҶзҫӨпјӣиҝҷж ·еҒҡдё»иҰҒжңүд»ҘдёӢдјҳзӮ№пјҡ
жҸҗеҚҮж“ҚдҪңж•ҲзҺҮпјӣ
ж“ҚдҪңеҮәй”ҷжҰӮзҺҮжӣҙе°ҸпјҢйӣҶзҫӨжӣҙе®үе…Ёпјӣ
жүҖжңүж“ҚдҪңжңүиҝ№еҸҜеҫӘпјҢеҸҜд»ҘиҝҪжәҜпјӣ
йӣҶзҫӨз®ЎзҗҶдё»иҰҒеҢ…жӢ¬пјҡbrokerз®ЎзҗҶгҖҒtopicз®ЎзҗҶгҖҒз”ҹдә§/ж¶Ҳиҙ№жқғйҷҗз®ЎзҗҶгҖҒз”ЁжҲ·з®ЎзҗҶзӯү
1.13.1 mockеҠҹиғҪ
еңЁе№іеҸ°дёҠдёәз”ЁжҲ·зҡ„topicжҸҗдҫӣз”ҹдә§ж ·дҫӢж•°жҚ®дёҺж¶Ҳиҙ№жҠҪж ·зҡ„еҠҹиғҪпјҢз”ЁжҲ·еҸҜд»ҘдёҚз”ЁиҮӘе·ұеҶҷд»Јз Ғд№ҹеҸҜд»ҘжөӢиҜ•topicжҳҜеҗҰеҸҜд»ҘдҪҝз”ЁпјҢжқғйҷҗжҳҜеҗҰжӯЈеёёпјӣ
еңЁе№іеҸ°дёҠдёәз”ЁжҲ·зҡ„topicжҸҗдҫӣз”ҹдә§/ж¶Ҳиҙ№жқғйҷҗйӘҢиҜҒеҠҹиғҪпјҢи®©з”ЁжҲ·еҸҜд»ҘжҳҺзЎ®иҮӘе·ұзҡ„иҙҰеҸ·еҜ№жҹҗдёӘtopicжңүжІЎжңүиҜ»еҶҷжқғйҷҗпјӣ
1.13.2 жқғйҷҗз®ЎзҗҶ
жҠҠз”ЁжҲ·иҜ»/еҶҷжқғйҷҗз®ЎзҗҶзӯүзӣёе…іж“ҚдҪңиҝӣиЎҢе№іеҸ°еҢ–гҖӮ
1.13.3 жү©е®№/зј©е®№
жҠҠbrokerиҠӮзӮ№дёҠдёӢзәҝеҒҡеҲ°е№іеҸ°дёҠпјҢжүҖжңүзҡ„дёҠзәҝе’ҢдёӢзәҝиҠӮзӮ№дёҚеҶҚйңҖиҰҒж“ҚдҪңе‘Ҫд»ӨиЎҢгҖӮ
1.13.4 йӣҶзҫӨжІ»зҗҶ
1пјүж— жөҒйҮҸtopicзҡ„жІ»зҗҶпјҢеҜ№йӣҶзҫӨдёӯж— жөҒйҮҸtopicиҝӣиЎҢжё…зҗҶпјҢеҮҸе°‘иҝҮеӨҡж— з”Ёе…ғж•°жҚ®еҜ№йӣҶзҫӨйҖ жҲҗзҡ„еҺӢеҠӣпјӣ
2пјүtopicеҲҶеҢәж•°жҚ®еӨ§е°ҸжІ»зҗҶпјҢжҠҠtopicеҲҶеҢәж•°жҚ®йҮҸиҝҮеӨ§зҡ„topicпјҲеҰӮеҚ•еҲҶеҢәж•°жҚ®йҮҸи¶…иҝҮ100GB/еӨ©пјүиҝӣиЎҢжўізҗҶпјҢзңӢзңӢжҳҜеҗҰйңҖиҰҒжү©е®№пјҢйҒҝе…Қж•°жҚ®йӣҶдёӯеңЁйӣҶзҫӨйғЁеҲҶиҠӮзӮ№дёҠпјӣ
3пјүtopicеҲҶеҢәж•°жҚ®еҖҫж–ңжІ»зҗҶпјҢйҒҝе…Қе®ўжҲ·з«ҜеңЁз”ҹдә§ж¶ҲжҒҜзҡ„ж—¶еҖҷпјҢжҢҮе®ҡж¶ҲжҒҜзҡ„keyпјҢдҪҶжҳҜkeyиҝҮдәҺйӣҶдёӯпјҢж¶ҲжҒҜеҸӘйӣҶдёӯеҲҶеёғеңЁйғЁеҲҶеҲҶеҢәпјҢеҜјиҮҙж•°жҚ®еҖҫж–ңпјӣ
4пјүtopicеҲҶеҢәеҲҶж•ЈжҖ§жІ»зҗҶпјҢи®©topicеҲҶеҢәеҲҶеёғеңЁйӣҶзҫӨе°ҪеҸҜиғҪеӨҡзҡ„brokerдёҠпјҢиҝҷж ·еҸҜд»ҘйҒҝе…Қеӣ topicжөҒйҮҸзӘҒеўһпјҢжөҒйҮҸеҸӘйӣҶдёӯеҲ°е°‘ж•°иҠӮзӮ№дёҠзҡ„йЈҺйҷ©пјҢд№ҹеҸҜд»ҘйҒҝе…ҚжҹҗдёӘbrokerејӮеёёеҜ№topicеҪұе“ҚйқһеёёеӨ§пјӣ
5пјүtopicеҲҶеҢәж¶Ҳиҙ№е»¶ж—¶жІ»зҗҶпјӣдёҖиҲ¬жңү延时ж¶Ҳиҙ№иҫғеӨҡзҡ„ж—¶еҖҷжңүдёӨз§Қжғ…еҶөпјҢдёҖз§ҚжҳҜйӣҶзҫӨжҖ§иғҪдёӢйҷҚпјҢеҸҰеӨ–дёҖз§ҚжҳҜдёҡеҠЎж–№зҡ„ж¶Ҳиҙ№е№¶еҸ‘еәҰдёҚеӨҹпјҢеҰӮжһңжҳҜж¶Ҳиҙ№иҖ…并еҸ‘дёҚеӨҹзҡ„еҢ–еә”иҜҘдёҺдёҡеҠЎиҒ”зі»еўһеҠ ж¶Ҳиҙ№е№¶еҸ‘гҖӮ
1.13.5 зӣ‘жҺ§е‘ҠиӯҰ
1пјүжҠҠжүҖжңүжҢҮж ҮйҮҮйӣҶеҒҡжҲҗе№іеҸ°еҸҜй…ҚзҪ®пјҢжҸҗдҫӣз»ҹдёҖзҡ„жҢҮж ҮйҮҮйӣҶе’ҢжҢҮж Үеұ•зӨәеҸҠе‘ҠиӯҰе№іеҸ°пјҢе®һзҺ°дёҖдҪ“еҢ–зӣ‘жҺ§пјӣ
2пјүжҠҠдёҠдёӢжёёдёҡеҠЎиҝӣиЎҢе…іиҒ”пјҢеҒҡжҲҗе…Ёй“ҫи·Ҝзӣ‘жҺ§пјӣ
3пјүз”ЁжҲ·еҸҜд»Ҙй…ҚзҪ®topicжҲ–иҖ…еҲҶеҢәжөҒйҮҸ延时гҖҒзӘҒеҸҳзӯүзӣ‘жҺ§е‘ҠиӯҰпјӣ
1.13.6 дёҡеҠЎеӨ§еұҸ
дёҡеҠЎеӨ§еұҸдё»иҰҒжҢҮж ҮпјҡйӣҶзҫӨдёӘж•°гҖҒиҠӮзӮ№дёӘж•°гҖҒж—Ҙе…ҘжөҒйҮҸеӨ§е°ҸгҖҒж—Ҙе…ҘжөҒйҮҸи®°еҪ•гҖҒж—ҘеҮәжөҒйҮҸеӨ§е°ҸгҖҒж—ҘеҮәжөҒйҮҸи®°еҪ•гҖҒжҜҸз§’е…ҘжөҒйҮҸеӨ§е°ҸгҖҒжҜҸз§’е…ҘжөҒйҮҸи®°еҪ•гҖҒжҜҸз§’еҮәжөҒйҮҸеӨ§е°ҸгҖҒжҜҸз§’еҮәжөҒйҮҸи®°еҪ•гҖҒз”ЁжҲ·дёӘж•°гҖҒз”ҹдә§е»¶ж—¶гҖҒж¶Ҳиҙ№е»¶ж—¶гҖҒж•°жҚ®еҸҜйқ жҖ§гҖҒжңҚеҠЎеҸҜз”ЁжҖ§гҖҒж•°жҚ®еӯҳеӮЁеӨ§е°ҸгҖҒиө„жәҗз»„дёӘж•°гҖҒtopicдёӘж•°гҖҒеҲҶеҢәдёӘж•°гҖҒеүҜжң¬дёӘж•°гҖҒж¶Ҳиҙ№з»„дёӘж•°зӯүжҢҮж ҮгҖӮ
1.13.7 жөҒйҮҸйҷҗеҲ¶
жҠҠз”ЁжҲ·жөҒйҮҸзҺ°еңЁеҒҡеҲ°е№іеҸ°пјҢеңЁе№іеҸ°иҝӣиЎҢжҷәиғҪйҷҗжөҒеӨ„зҗҶгҖӮ
1.13.8 иҙҹиҪҪеқҮиЎЎ
жҠҠиҮӘеҠЁиҙҹиҪҪеқҮиЎЎеҠҹиғҪеҒҡеҲ°е№іеҸ°пјҢйҖҡиҝҮе№іеҸ°иҝӣиЎҢи°ғеәҰе’Ңз®ЎзҗҶгҖӮ
1.13.9 иө„жәҗйў„з®—
еҪ“йӣҶзҫӨиҫҫеҲ°дёҖе®ҡ规模пјҢжөҒйҮҸдёҚж–ӯеўһй•ҝпјҢйӮЈд№ҲйӣҶзҫӨжү©е®№жңәеҷЁд»Һе“ӘйҮҢжқҘе‘ўпјҹдёҡеҠЎзҡ„иө„жәҗйў„з®—пјҢи®©йӣҶзҫӨйҮҢйқўзҡ„еӨҡдёӘдёҡеҠЎж №жҚ®иҮӘе·ұеңЁйӣҶзҫӨдёӯеҪ“жөҒйҮҸеҺ»еҲҶж‘Ҡж•ҙдёӘйӣҶзҫӨзҡ„硬件жҲҗжң¬пјӣеҪ“然пјҢзӢ¬з«ӢйӣҶзҫӨдёҺзӢ¬з«Ӣйҡ”зҰ»зҡ„иө„жәҗз»„пјҢйў„з®—ж–№ејҸеҸҜд»ҘеҚ•зӢ¬и®Ўз®—гҖӮ
1.14.жҖ§иғҪиҜ„дј°
1.14.1 еҚ•brokerжҖ§иғҪиҜ„дј°
жҲ‘们еҒҡеҚ•brokerжҖ§иғҪиҜ„дј°зҡ„зӣ®зҡ„еҢ…жӢ¬д»ҘдёӢеҮ ж–№йқўпјҡ
1)дёәжҲ‘们иҝӣиЎҢиө„жәҗз”іиҜ·иҜ„дј°жҸҗдҫӣдҫқжҚ®пјӣ
2)и®©жҲ‘们жӣҙдәҶи§ЈйӣҶзҫӨзҡ„иҜ»еҶҷиғҪеҠӣеҸҠ瓶йўҲеңЁе“ӘйҮҢпјҢй’ҲеҜ№з“¶йўҲиҝӣиЎҢдјҳеҢ–пјӣ
3)дёәжҲ‘们йҷҗжөҒйҳҲеҖји®ҫзҪ®жҸҗдҫӣдҫқжҚ®пјӣ
4)дёәжҲ‘们иҜ„дј°д»Җд№Ҳж—¶еҖҷеә”иҜҘжү©е®№жҸҗдҫӣдҫқжҚ®пјӣ
1.14.2 topicеҲҶеҢәжҖ§иғҪиҜ„дј°
1)дёәжҲ‘们еҲӣе»әtopicж—¶пјҢиҜ„дј°еә”иҜҘжҢҮе®ҡеӨҡе°‘еҲҶеҢәеҗҲзҗҶжҸҗдҫӣдҫқжҚ®пјӣ
2)дёәжҲ‘们topicзҡ„еҲҶеҢәжү©е®№иҜ„дј°жҸҗдҫӣдҫқжҚ®пјӣ
1.14.3 еҚ•зЈҒзӣҳжҖ§иғҪиҜ„дј°
1)дёәжҲ‘们дәҶи§ЈзЈҒзӣҳзҡ„зңҹжӯЈиҜ»еҶҷиғҪеҠӣпјҢдёәжҲ‘们йҖүжӢ©жӣҙеҗҲйҖӮKafkaзҡ„зЈҒзӣҳзұ»еһӢжҸҗдҫӣдҫқжҚ®пјӣ
2)дёәжҲ‘们еҒҡзЈҒзӣҳжөҒйҮҸе‘ҠиӯҰйҳҲеҖји®ҫзҪ®жҸҗдҫӣдҫқжҚ®пјӣ
1.14.4 йӣҶзҫӨ规模йҷҗеҲ¶ж‘ёеә•
1пјүжҲ‘们йңҖиҰҒдәҶи§ЈеҚ•дёӘйӣҶзҫӨ规模зҡ„дёҠйҷҗжҲ–иҖ…жҳҜе…ғж•°жҚ®и§„жЁЎзҡ„дёҠйҷҗпјҢжҺўзҙўзӣёе…ідҝЎжҒҜеҜ№йӣҶзҫӨжҖ§иғҪе’ҢзЁіе®ҡжҖ§зҡ„еҪұе“Қпјӣ
2пјүж №жҚ®ж‘ёеә•жғ…еҶөпјҢиҜ„дј°йӣҶзҫӨиҠӮзӮ№и§„жЁЎзҡ„еҗҲзҗҶиҢғеӣҙпјҢеҸҠж—¶йў„жөӢйЈҺйҷ©пјҢиҝӣиЎҢи¶…еӨ§йӣҶзҫӨзҡ„жӢҶеҲҶзӯүе·ҘдҪңпјӣ
1.15 DNS+LVSзҡ„зҪ‘з»ңжһ¶жһ„
еҪ“жҲ‘们зҡ„йӣҶзҫӨиҠӮзӮ№иҫҫеҲ°дёҖе®ҡ规模пјҢжҜ”еҰӮеҚ•йӣҶзҫӨж•°зҷҫдёӘbrokerиҠӮзӮ№пјҢйӮЈд№ҲжӯӨж—¶жҲ‘们з”ҹдә§ж¶Ҳиҙ№е®ўжҲ·з«ҜжҢҮе®ҡbootstrap.serversй…ҚзҪ®ж—¶пјҢеҰӮжһңжҢҮе®ҡе‘ўпјҹжҳҜйҡҸдҫҝйҖүжӢ©е…¶дёӯеҮ дёӘbrokerй…ҚзҪ®иҝҳжҳҜе…ЁйғЁйғҪй…ҚдёҠе‘ўпјҹ
е…¶е®һд»ҘдёҠеҒҡжі•йғҪдёҚеҗҲйҖӮпјҢеҰӮжһңеҸӘй…ҚзҪ®еҮ дёӘIPпјҢеҪ“жҲ‘们й…ҚзҪ®еҪ“еҮ дёӘbrokerиҠӮзӮ№дёӢзәҝеҗҺпјҢжҲ‘们еҪ“еә”з”Ёе°Ҷж— жі•иҝһжҺҘеҲ°KafkaйӣҶзҫӨпјӣеҰӮжһңй…ҚзҪ®жүҖжңүIPпјҢйӮЈжӣҙдёҚзҺ°е®һе•ҰпјҢеҮ зҷҫдёӘIPпјҢйӮЈд№ҲжҲ‘们еә”иҜҘжҖҺд№ҲеҒҡе‘ўпјҹ
**ж–№жЎҲпјҡ**йҮҮз”ЁDNS+LVSзҪ‘з»ңжһ¶жһ„пјҢжңҖз»Ҳз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…е®ўжҲ·з«ҜеҸӘйңҖиҰҒй…ҚзҪ®еҹҹеҗҚе°ұеҸҜд»Ҙе•ҰгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢжңүж–°иҠӮзӮ№еҠ е…ҘйӣҶзҫӨж—¶пјҢйңҖиҰҒж·»еҠ жҳ е°„пјӣжңүиҠӮзӮ№дёӢзәҝж—¶пјҢйңҖиҰҒд»Һжҳ е°„дёӯиёўжҺүпјҢеҗҰеҲҷиҝҷжү№жңәеҷЁеҰӮжһңжӢҝеҲ°е…¶д»–зҡ„ең°ж–№еҺ»дҪҝз”ЁпјҢеҰӮжһңз«ҜеҸЈе’ҢKafkaзҡ„дёҖж ·зҡ„иҜқпјҢеҺҹжқҘйӣҶзҫӨйғЁеҲҶиҜ·жұӮе°ҶеҸ‘йҖҒеҲ°иҝҷдёӘе·Із»ҸдёӢзәҝзҡ„жңҚеҠЎеҷЁдёҠжқҘпјҢйҖ жҲҗз”ҹдә§зҺҜеўғйҮҚзӮ№ж•…йҡңгҖӮ
дәҢгҖҒејҖжәҗзүҲжң¬еҠҹиғҪзјәйҷ·
RTMPеҚҸи®®дё»иҰҒзҡ„зү№зӮ№жңүпјҡеӨҡи·ҜеӨҚз”ЁпјҢеҲҶеҢ…е’Ңеә”з”ЁеұӮеҚҸи®®гҖӮд»ҘдёӢе°ҶеҜ№иҝҷдәӣзү№зӮ№иҝӣиЎҢиҜҰз»Ҷзҡ„жҸҸиҝ°гҖӮ
2.1 еүҜжң¬иҝҒ移
ж— жі•е®һзҺ°еўһйҮҸиҝҒ移пјӣгҖҗжҲ‘们已з»ҸеҹәдәҺ2.1.1зүҲжң¬жәҗз Ғж”№йҖ пјҢе®һзҺ°дәҶеўһйҮҸиҝҒ移гҖ‘
ж— жі•е®һзҺ°е№¶еҸ‘иҝҒ移пјӣгҖҗејҖжәҗзүҲжң¬зӣҙеҲ°2.6.0жүҚе®һзҺ°дәҶ并еҸ‘иҝҒ移гҖ‘
ж— жі•е®һзҺ°з»ҲжӯўиҝҒ移пјӣгҖҗжҲ‘们已з»ҸеҹәдәҺ2.1.1зүҲжң¬жәҗз Ғж”№йҖ пјҢе®һзҺ°дәҶз»ҲжӯўеүҜжң¬иҝҒ移гҖ‘гҖҗејҖжәҗзүҲжң¬зӣҙеҲ°2.6.0жүҚе®һзҺ°дәҶжҡӮеҒңиҝҒ移пјҢе’Ңз»ҲжӯўиҝҒ移жңүдәӣдёҚдёҖж ·пјҢдёҚдјҡеӣһж»ҡе…ғж•°жҚ®гҖ‘
еҪ“жҢҮе®ҡиҝҒ移数жҚ®зӣ®еҪ•ж—¶пјҢиҝҒ移иҝҮзЁӢдёӯпјҢеҰӮжһңжҠҠtopicдҝқз•ҷж—¶й—ҙж”№зҹӯпјҢtopicдҝқз•ҷж—¶й—ҙй’ҲеҜ№жӯЈеңЁиҝҒ移topicеҲҶеҢәдёҚз”ҹж•ҲпјҢtopicеҲҶеҢәиҝҮжңҹж•°жҚ®ж— жі•еҲ йҷӨпјӣгҖҗејҖжәҗзүҲжң¬bugпјҢзӣ®еүҚиҝҳжІЎжңүдҝ®еӨҚгҖ‘
еҪ“жҢҮе®ҡиҝҒ移数жҚ®зӣ®еҪ•ж—¶пјҢеҪ“иҝҒ移计еҲ’дёәд»ҘдёӢеңәжҷҜж—¶пјҢж•ҙдёӘиҝҒ移任еҠЎж— жі•е®ҢжҲҗиҝҒ移пјҢдёҖзӣҙеӨ„дәҺеҚЎжӯ»зҠ¶жҖҒпјӣгҖҗејҖжәҗзүҲжң¬bugпјҢзӣ®еүҚиҝҳжІЎжңүдҝ®еӨҚгҖ‘
иҝҒ移иҝҮзЁӢдёӯпјҢеҰӮжһңжңүйҮҚеҗҜbrokerиҠӮзӮ№пјҢйӮЈдёӘbrokerиҠӮзӮ№дёҠзҡ„жүҖжңүleaderеҲҶеҢәж— жі•еҲҮжҚўеӣһжқҘпјҢеҜјиҮҙиҠӮзӮ№жөҒйҮҸе…ЁйғЁиҪ¬з§»еҲ°е…¶д»–иҠӮзӮ№пјҢзӣҙеҲ°жүҖжңүеүҜжң¬иў«иҝҒ移е®ҢжҜ•еҗҺleaderжүҚдјҡеҲҮжҚўеӣһжқҘпјӣгҖҗејҖжәҗзүҲжң¬bugпјҢзӣ®еүҚиҝҳжІЎжңүдҝ®еӨҚгҖ‘гҖӮ
еңЁеҺҹз”ҹзҡ„KafkaзүҲжң¬дёӯеӯҳеңЁд»ҘдёӢжҢҮе®ҡж•°жҚ®зӣ®еҪ•еңәжҷҜж— жі•иҝҒ移е®ҢжҜ•зҡ„жғ…еҶөпјҢжӯӨзүҲжң¬жҲ‘们д№ҹдёҚеҶіе®ҡдҝ®еӨҚж¬Ўbugпјҡ
1.й’ҲеҜ№еҗҢдёҖдёӘtopicеҲҶеҢәпјҢеҰӮжһңйғЁеҲҶзӣ®ж ҮеүҜжң¬зӣёжҜ”еҺҹеүҜжң¬жҳҜжүҖеұһbrokerеҸ‘з”ҹеҸҳеҢ–пјҢйғЁеҲҶзӣ®ж ҮеүҜжң¬зӣёжҜ”еҺҹеүҜжң¬жҳҜbrokerеҶ…йғЁжүҖеұһж•°жҚ®зӣ®еҪ•еҸ‘з”ҹеҸҳеҢ–пјӣ
йӮЈд№ҲеүҜжң¬жүҖеұһbrokerеҸ‘з”ҹеҸҳеҢ–зҡ„йӮЈдёӘзӣ®ж ҮеүҜжң¬еҸҜд»ҘжӯЈеёёиҝҒ移е®ҢжҜ•пјҢзӣ®ж ҮеүҜжң¬жҳҜеңЁbrokerеҶ…йғЁж•°жҚ®зӣ®еҪ•еҸ‘з”ҹеҸҳеҢ–зҡ„ж— жі•жӯЈеёёе®ҢжҲҗиҝҒ移пјӣ
дҪҶжҳҜж—§еүҜжң¬дҫқ然еҸҜд»ҘжӯЈеёёжҸҗдҫӣз”ҹдә§гҖҒж¶Ҳиҙ№жңҚеҠЎпјҢ并且дёҚеҪұе“ҚдёӢдёҖж¬ЎиҝҒ移任еҠЎзҡ„жҸҗдәӨпјҢдёӢдёҖж¬ЎиҝҒ移任еҠЎеҸӘйңҖиҰҒжҠҠжӯӨtopicеҲҶеҢәзҡ„еүҜжң¬еҲ—иЎЁжүҖеұһbrokerеҲ—иЎЁеҸҳжӣҙеҗҺжҸҗдәӨдҫқ然еҸҜд»ҘжӯЈеёёе®ҢжҲҗиҝҒ移пјҢ并且еҸҜд»Ҙжё…зҗҶжҺүд№ӢеүҚжңӘе®ҢжҲҗзҡ„зӣ®ж ҮеүҜжң¬пјӣ
иҝҷйҮҢеҒҮи®ҫtopic yyj1зҡ„еҲқе§ӢеҢ–еүҜжң¬еҲҶеёғжғ…еҶөеҰӮдёӢпјҡ
{
"version":1,
"partitions":[
{"topic":"yyj","partition":0,"replicas":[1000003,1000001],"log_dirs":["/kfk211data/data31","/kfk211data/data13"]}
]
}
//иҝҒ移еңәжҷҜ1пјҡ
{
"version":1,
"partitions":[
{"topic":"yyj","partition":0,"replicas":[1000003,1000002],"log_dirs":["/kfk211data/data32","/kfk211data/data23"]}
]
}
//иҝҒ移еңәжҷҜ2пјҡ
{
"version":1,
"partitions":[
{"topic":"yyj","partition":0,"replicas":[1000002,1000001],"log_dirs":["/kfk211data/data22","/kfk211data/data13"]}
]
}
й’ҲеҜ№дёҠиҝ°зҡ„topic yyj1зҡ„еҲҶеёғеҲҶеёғжғ…еҶөпјҢжӯӨж—¶еҰӮжһңжҲ‘们зҡ„иҝҒ移计еҲ’дёәвҖңиҝҒ移еңәжҷҜ1вҖқжҲ–иҝҒ移еңәжҷҜ2вҖңпјҢйӮЈд№ҲйғҪе°ҶеҮәзҺ°жңүеүҜжң¬ж— жі•иҝҒ移е®ҢжҜ•зҡ„жғ…еҶөгҖӮ
дҪҶжҳҜиҝҷ并дёҚеҪұе“Қж—§еүҜжң¬еӨ„зҗҶз”ҹдә§гҖҒж¶Ҳиҙ№иҜ·жұӮпјҢ并且жҲ‘们еҸҜд»ҘжӯЈеёёжҸҗдәӨе…¶д»–зҡ„иҝҒ移任еҠЎгҖӮ
дёәдәҶжё…зҗҶж—§зҡ„жңӘиҝҒ移е®ҢжҲҗзҡ„еүҜжң¬пјҢжҲ‘们еҸӘйңҖиҰҒдҝ®ж”№дёҖж¬ЎиҝҒ移计еҲ’гҖҗж–°зҡ„зӣ®ж ҮеүҜжң¬еҲ—иЎЁе’ҢеҪ“еүҚеҲҶеҢәе·ІеҲҶй…ҚеүҜжң¬еҲ—иЎЁе®Ңе…ЁдёҚеҗҢеҚіеҸҜгҖ‘пјҢеҶҚж¬ЎжҸҗдәӨиҝҒ移еҚіеҸҜгҖӮ
иҝҷйҮҢпјҢжҲ‘们дҫқ然д»ҘдёҠиҝ°зҡ„дҫӢеӯҗеҒҡиҝҒ移计еҲ’дҝ®ж”№еҰӮдёӢпјҡ
{
"version":1,
"partitions":[
{"topic":"yyj","partition":0,"replicas":[1000004,1000005],"log_dirs":["/kfk211data/data42","/kfk211data/data53"]}
]
}
иҝҷж ·жҲ‘们е°ұеҸҜд»ҘжӯЈеёёе®ҢжҲҗиҝҒ移гҖӮ2.2 жөҒйҮҸеҚҸи®®
йҷҗжөҒзІ’еәҰиҫғзІ—пјҢдёҚеӨҹзҒөжҙ»зІҫеҮҶпјҢдёҚеӨҹжҷәиғҪгҖӮ
еҪ“еүҚйҷҗжөҒз»ҙеәҰз»„еҗҲ
/config/users/<user>/clients/<client-id>
/config/users/<user>/clients/<default>
/config/users/<user>
/config/users/<default>/clients/<client-id>
/config/users/<default>/clients/<default>
/config/users/<default>
/config/clients/<client-id>
/config/clients/<default>
еӯҳеңЁй—®йўҳ
еҪ“еҗҢдёҖдёӘbrokerдёҠжңүеӨҡдёӘз”ЁжҲ·еҗҢж—¶иҝӣиЎҢеӨ§йҮҸзҡ„з”ҹдә§е’Ңж¶Ҳиҙ№ж—¶пјҢжғіиҰҒи®©brokerеҸҜд»ҘжӯЈеёёиҝҗиЎҢпјҢйӮЈеҝ…йЎ»еңЁеҒҡйҷҗжөҒж—¶и®©жүҖжңүзҡ„з”ЁжҲ·жөҒйҮҸйҳҲеҖјд№Ӣе’ҢдёҚи¶…иҝҮbrokerзҡ„еҗһеҗҗдёҠйҷҗпјӣеҰӮжһңи¶…иҝҮbrokerдёҠйҷҗпјҢйӮЈд№Ҳbrokerе°ұеӯҳеңЁиў«жү“жҢӮзҡ„йЈҺйҷ©пјӣ然иҖҢпјҢеҚідҪҝз”ЁжҲ·жөҒйҮҸжІЎжңүиҫҫеҲ°brokerзҡ„жөҒйҮҸдёҠйҷҗпјҢдҪҶжҳҜпјҢеҰӮжһңжүҖжңүз”ЁжҲ·жөҒйҮҸйӣҶдёӯеҲ°дәҶжҹҗеҮ еқ—зӣҳдёҠпјҢи¶…иҝҮдәҶзЈҒзӣҳзҡ„иҜ»еҶҷиҙҹиҪҪпјҢд№ҹдјҡеҜјиҮҙжүҖжңүз”ҹдә§гҖҒж¶Ҳиҙ№иҜ·жұӮе°Ҷиў«йҳ»еЎһпјҢbrokerеҸҜиғҪеӨ„дәҺеҒҮжӯ»зҠ¶жҖҒгҖӮ
и§ЈеҶіж–№жЎҲ
(1)ж”№йҖ жәҗз ҒпјҢе®һзҺ°еҚ•дёӘbrokerжөҒйҮҸдёҠйҷҗйҷҗеҲ¶пјҢеҸӘиҰҒжөҒйҮҸиҫҫеҲ°brokerдёҠйҷҗз«ӢеҚіиҝӣиЎҢйҷҗжөҒеӨ„зҗҶпјҢжүҖжңүеҫҖиҝҷдёӘbrokerеҶҷзҡ„з”ЁжҲ·йғҪеҸҜд»Ҙиў«йҷҗеҲ¶дҪҸпјӣжҲ–иҖ…еҜ№з”ЁжҲ·иҝӣиЎҢдјҳе…Ҳзә§еӨ„зҗҶпјҢж”ҫиҝҮй«ҳдјҳе…Ҳзә§зҡ„пјҢйҷҗеҲ¶дҪҺдјҳе…Ҳзә§зҡ„пјӣ
(2)ж”№йҖ жәҗз ҒпјҢе®һзҺ°brokerдёҠеҚ•еқ—зЈҒзӣҳжөҒйҮҸдёҠйҷҗйҷҗеҲ¶пјҲеҫҲеӨҡж—¶еҖҷйғҪжҳҜжөҒйҮҸйӣҶдёӯеҲ°жҹҗеҮ еқ—зЈҒзӣҳдёҠпјҢеҜјиҮҙжІЎжңүиҫҫеҲ°brokerжөҒйҮҸдёҠйҷҗеҚҙи¶…иҝҮдәҶеҚ•зЈҒзӣҳиҜ»еҶҷиғҪеҠӣдёҠйҷҗпјүпјҢеҸӘиҰҒзЈҒзӣҳжөҒйҮҸиҫҫеҲ°дёҠйҷҗпјҢз«ӢеҚіиҝӣиЎҢйҷҗжөҒеӨ„зҗҶпјҢжүҖжңүеҫҖиҝҷдёӘзЈҒзӣҳеҶҷзҡ„з”ЁжҲ·йғҪеҸҜд»Ҙиў«йҷҗеҲ¶дҪҸпјӣжҲ–иҖ…еҜ№з”ЁжҲ·иҝӣиЎҢдјҳе…Ҳзә§еӨ„зҗҶпјҢж”ҫиҝҮй«ҳдјҳе…Ҳзә§зҡ„пјҢйҷҗеҲ¶дҪҺдјҳе…Ҳзә§зҡ„пјӣ
(3)ж”№йҖ жәҗз ҒпјҢе®һзҺ°topicз»ҙеәҰйҷҗжөҒд»ҘеҸҠеҜ№topicеҲҶеҢәзҡ„зҰҒеҶҷеҠҹиғҪпјӣ
(4)ж”№йҖ жәҗз ҒпјҢе®һзҺ°з”ЁжҲ·гҖҒbrokerгҖҒзЈҒзӣҳгҖҒtopicзӯүз»ҙеәҰз»„еҗҲзІҫеҮҶйҷҗжөҒпјӣ
еҲ°жӯӨпјҢе…ідәҺвҖңKafkaжҖҺд№Ҳз”ЁвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





