R语言怎样做Logistic回归,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
当因变量为二值型结果变量,自变量包括连续型和类别型的数据时,Logistic回归是一个非常常用的工具。比如今天的例子中用到的婚外情数据 “Fair's Affairs”。因变量是是否有过婚外情,自变量有8个,分别是
因变量y是出轨次数,我们将其转换成二值型,出轨次数大于等于1赋值为1,相反赋值为0
这个数据集来自R语言包AER,如果要用这个数据集需要先安装这个包
install.packages("AER")
然后使用data()函数获取这个数据集
data(Affairs,package = "AER")
然后就可以在环境的窗口里看到如下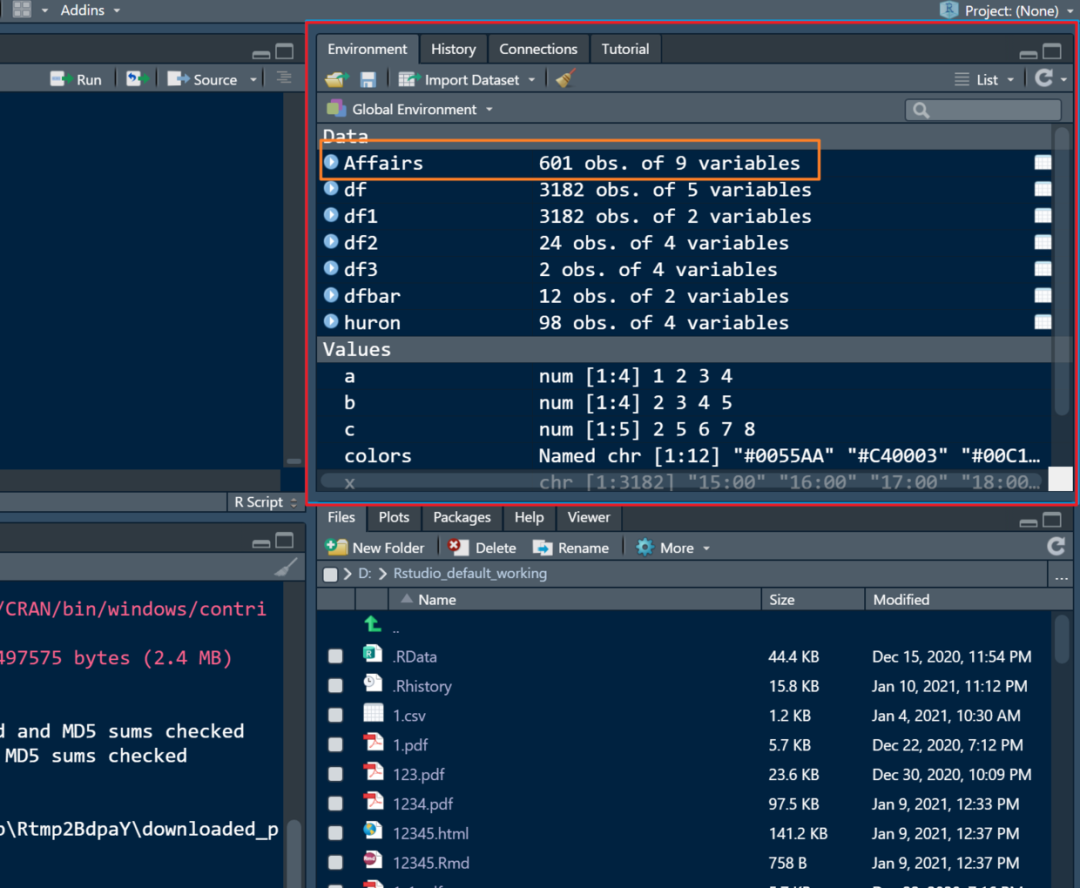
这个数据集总共有601个观察值,总共9个变量
df<-Affairs
df$ynaffairs<-ifelse(df$affairs>0,1,0)
table(df$ynaffairs)
df$ynaffairs<-factor(df$ynaffairs,
levels = c(0,1),
labels = c("No","Yes"))table
table(df$ynaffairs)
拟合模型用到的是glm()函数
fit.full<-glm(ynaffairs~gender+age+yearsmarried+
children+religiousness+education+occupation+rating,
data=df,family = binomial())
通过summary()函数查看拟合结果
summary(fit.full)

根据回归系数的P值可以看到 性别、是否有孩子、学历、职业对方程的贡献都不显著。去除这些变量重新拟合模型
fit.reduced<-glm(ynaffairs~age+yearsmarried+
religiousness+rating,
data=df,family = binomial())
anova(fit.full,fit.reduced,test = "Chisq")
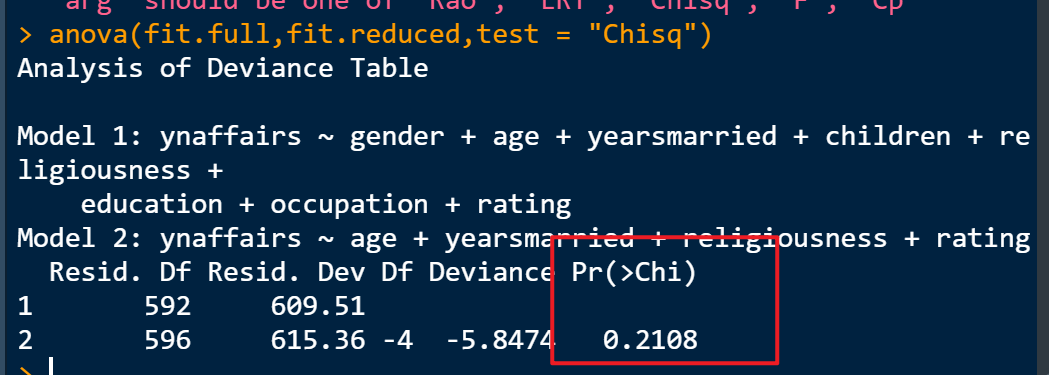
可以看到结果中p值等于0.2108大于0.05,表明四个变量和9个变量的模型你和程度没有差别
构造一个测试集
testdata<-data.frame(rating=c(1,2,3,4,5),
age=mean(df$age),
yearsmarried=mean(df$yearsmarried),
religiousness=mean(df$religiousness)
预测概率
testdata$prob<-predict(fit.reduced,newdata = testdata,
type = "response")
library(ggplot2)
ggplot(testdata,aes(x=rating,y=prob))+
geom_col(aes(fill=factor(rating)),show.legend = F)+
geom_label(aes(label=round(prob,2)))+
theme_bw()
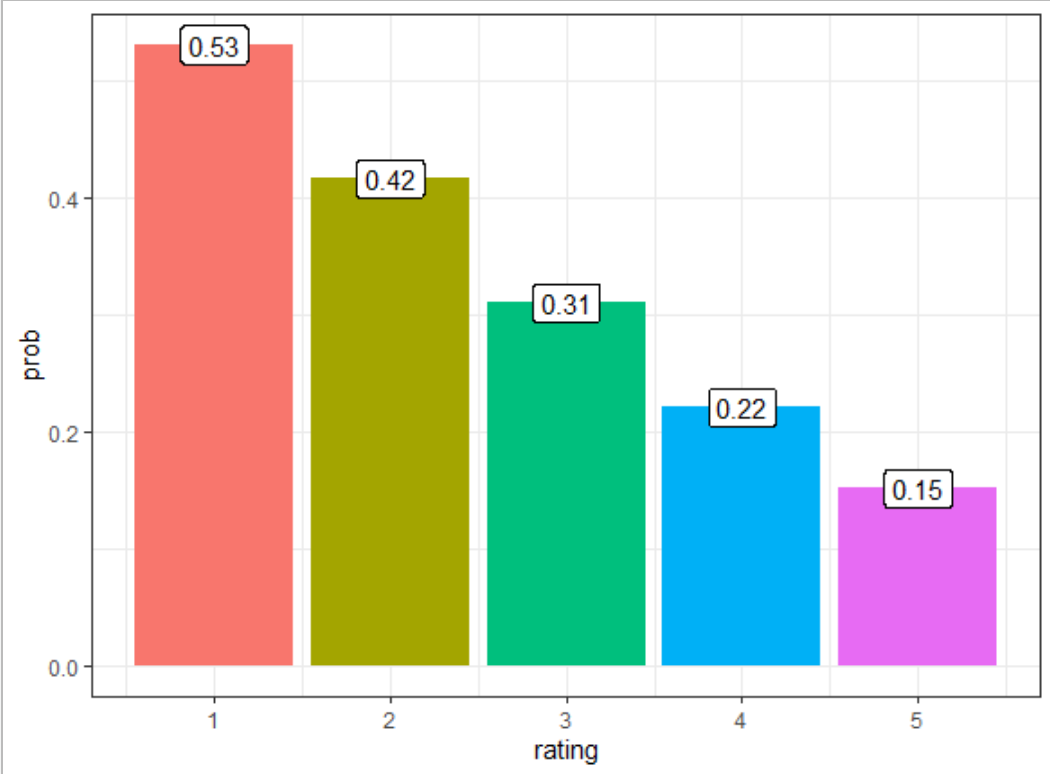
从这些结果可以看到,当婚姻评分从1(很不幸福)变为5(非常幸福)时,婚外情概率从0.53降低到了0.15。模型的预测结果和我们的经验还挺符合的
关于R语言怎样做Logistic回归问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





