本篇内容介绍了“怎么正确设计一个订单号”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
我们经常提及到的订单号,大多数是在电商购物场景下的一个唯一标识字符串。实则订单号并不仅仅指的是电商系统,只要需要这样的业务场景,我们都可以使用订单号的模式来处理。例如我们的省份证号,要求唯一可读性强等特点,也可以将之理解为一个订单号。
1.不重复。不管你的订单号设计的是多复杂还是多简单,首先我们需要确保的是订单号在一个系统中是唯一的。
2.安全性。订单号需要做到不容易被人为的猜测或者推测出来。例如订单号包含系统的流水信息,用户信息等保密相关的信息。
3.禁用随机码。随机码从一定程度来说,更安全、不重复性更高,但是可读性差。例如生成类似这样的随机码(sdfsad12312sfsdf201),不管是从系统角度还是从人为角度去读取,完全没法直接辨别。
4.防止并发。针对系统的并发业务场景(如秒杀),一定需要做到并发场景下,订单编号生成快速、不重复等要求。
5.控制位数。订单号的位数尽量在 10 位-20 位之间。太短的情况下,如果交易量过大,很难做到防止重复,太长可读性差、意义也不大。
6.尽量使用数字。从软件角度,数字存储的订单号,占用空间小、检索快。
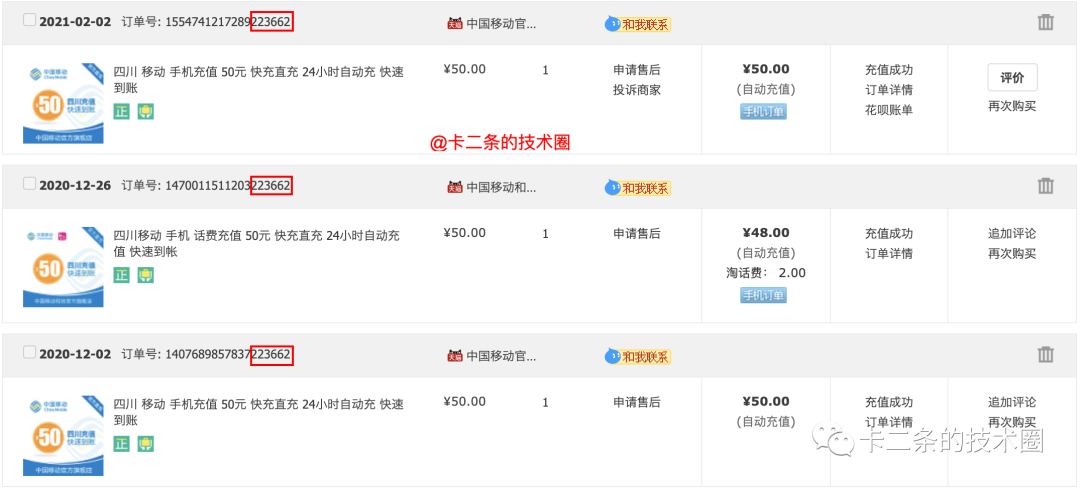
上面的截图,是个人在淘宝上面进行充值的订单编号,这里只截取了几个。在实际的过程中,发现所有订单号都有一个相似的特点(红色框出来的地方)。个人猜测,这应该是和买家相关的信息,例如买家的 ID 编号情况。
下面的的几个规则,是淘宝订单编号生成的规则(只具备参考意义,与实际存在差距)。
1.总共 18 位。
2.前 14 位为序号。
3.15-16 位卖家 ID 的倒数 1-2 位。。
4.17-18 位买家 ID 的倒数 3-4 位。
上面的几个规则具备一定的参考意义。从第 3 和 4 点,我们不难分析出来,通过这样的方式来实现订单号,在一定程度很难出现重复的订单编号。那是为什么呢?
1.卖家的 ID 和买家 ID 的都是在下单之前生成的,具备唯一性。因为这两个 ID 事先生成,即使出现并发场景,通过这两组的唯一标识就很难生成重复的单号。
2.很大程度上满足了一些并发高的业务场景下,单号重复的情况。或许你会考虑像双十一这样的场景下,实则绝大部分系统都无法达到这样的业务场景。
前面提到了生成的规则,那要实现这样的规则,该如何实现会比较好呢?下面总结几种常见的处理方式。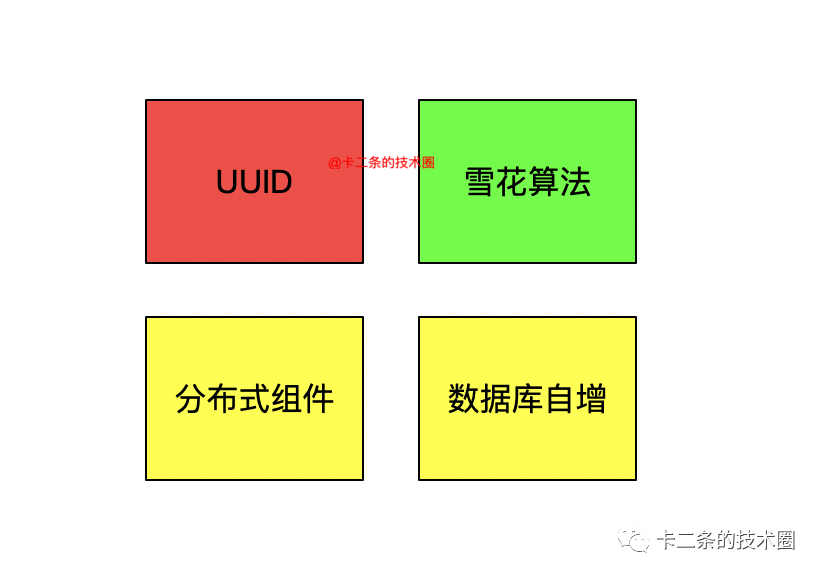
UUID 是 Universally Unique Indentifier 的缩写,翻译为通用唯一识别码,顾名思义 UUID 是一个用于唯一标识一条数据、记录的,其按照开放软件基金会(OSF)指定的标准进行计算,用到了以太网卡地址(MAC)、纳秒级时间、芯片 ID 码和许多可能的数字。
总的来说,UUID 码由以下三部分组成:
1.当前日期和时间。
2.时钟序列。
3.全局唯一的 IEEE 机器识别码(如何有网卡,从网卡获得,没有网卡则以其他方式获得)。
UUID 的标准形式包含 32 个 16 进制数字,以连字号分为五段,形式为 8-4-4-4-12 的 32 个字符。示例:550e8400-e29b-41d4-a716-446655440000。关于 UUID 的更多介绍,可以参考该文章
Snowflake 是 Twitter 内部的一个 ID 生算法,可以通过一些简单的规则保证在大规模分布式情况下生成唯一的 ID 号码。其组成为:
第一个 bit 为未使用的符号位。
第二部分由 41 位的时间戳(毫秒)构成,它的取值是当前时间相对于某一时间的偏移量。
第三部分和第四部分的 5 个 bit 位表示数据中心和机器 ID,其能表示的最大值为 2^5 -1 = 31。
最后部分由 12 个 bit 组成,其表示每个工作节点每毫秒生成的序列号 ID,同一毫秒内最多可生成 2^12 -1 即 4095 个 ID。
需要注意的是:
在分布式环境中,5 个 bit 位的 datacenter 和 worker 表示最多能部署 31 个数据中心,每个数据中心最多可部署 31 台节点。
41 位的二进制长度最多能表示 2^41 -1 毫秒即 69 年,所以雪花算法最多能正常使用 69 年,为了能最大限度的使用该算法,你应该为其指定一个开始时间。
在数据库中可以通过给订单列设置为自增列,并且给该列设置一个初始值。这样通过数据库实现订单的自增、无重复情况。但通过数据库实现并发能力低,单表存在只能有一个自增列的情况,后期对数据的分表处理也不够友好。
通过分布式组件的方式,我们也可以实现订单号的处理。例如使用 Redis 作为分布式组件。通过 Redis 的队列、incr 等功能来实现。
// 生成方式一
function uuid($prefix = '') {
$chars = md5(uniqid(mt_rand(), true));
$uuid = substr($chars,0,8) . '-';
$uuid .= substr($chars,8,4) . '-';
$uuid .= substr($chars,12,4) . '-';
$uuid .= substr($chars,16,4) . '-';
$uuid .= substr($chars,20,12);
return $prefix . $uuid;
}
echo uuid();
// output
// b2fa188c-23a8-d1b6-432d-649db4eb34c7
// 生成方式二(利用Linux内部生成的uuid)
echo exec("cat /proc/sys/kernel/random/uuid");
// output
// b2792783-7c9f-43d0-8d31-38411e17fc2f
// 生成方式三
function uniqidReal($lenght = 13) {
if (function_exists("random_bytes")) {
try {
$bytes = random_bytes(ceil($lenght / 2));
} catch (Exception $e) {
}
} elseif (function_exists("openssl_random_pseudo_bytes")) {
$bytes = openssl_random_pseudo_bytes(ceil($lenght / 2));
} else {
throw new Exception("no cryptographically secure random function available");
}
return substr(bin2hex($bytes), 0, $lenght);
}
echo uniqidReal();
// output
// 9f39aa0ecd89d
require_once __DIR__.'/vendor/autoload.php';
$snowflake = new \Godruoyi\Snowflake\Snowflake;
echo $snowflake->id();
// output
// 199778615951360000
// 更多高级用法及实现原理参考原仓库:https://github.com/godruoyi/php-snowflake/blob/master/README-zh_CN.md
// 连接Redis
$redis = new \Redis();
$redis->connect('192.168.0.112', 6379);
$cacheKey = date('Y:m:d');
$initVal = 10000;
// 实现方式一(使用队列)
for ($i = 0; $i < 10; $i++) {
$redis->lPush($cacheKey, $initVal + $i);
}
$redis->rPop($cacheKey);
// 实现方式二(使用incr)
if ($redis->get($cacheKey)) {
// 返回新增后的值
return $redis->incr($cacheKey);
} else {
// 设置一个默认的初始值
$redis->set($cacheKey, $initVal);
return $cacheKey;
}
数据库直接就不演示,直接通过设置表字段属性就行。主要设置字段值的初始值、偏移量。
mysql root@127.0.0.1:(none)> show variables like '%auto_incr%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
+--------------------------+-------+
2 rows in set
Time: 0.012s
通过上面的示例演示,下面针对这几种情况做一个分析与总结。尽可能的选择一种合理的方式。
| 实现方案 | 优势 | 劣势 |
|---|---|---|
| UUID | 实现简单、方便;重复性低;数据库查询效率低 | 可读性低;过于冗长 |
| 雪花算法 | 基于内存、速度快;性能高;不会产生额外的网络开销;数据依次成递增 | 依赖于服务器时间,如变动服务器时间则存在重复的情况 |
| Redis | 基于内存、速度库;使用简单;可分布数据、扩展性强 | 需要独立搭建一套服务、增加了维护成本;跨应用调用、存在网络开销 |
| 数据库自增 | 代码层面无需任何特殊处理;利用MySQL特点实现数据递增 | 并发性能差;MySQL负担重 |
“怎么正确设计一个订单号”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





