жҖҺд№Ҳз”Ёjsoupе®һзҺ°жҠ“еҸ–еӣҫзүҮзҲ¬иҷ«
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңжҖҺд№Ҳз”Ёjsoupе®һзҺ°жҠ“еҸ–еӣҫзүҮзҲ¬иҷ«вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
еҲқзүҲпјҡ
ThreadPoolExecutor executor = new ThreadPoolExecutor(6, 6, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(200));
for (int j = 1; j <= жҖ»йЎөж•°; j++) {
executor.execute(()->{
// 1.жҠ“еҸ–зҪ‘йЎө,иҺ·еҫ—еӣҫзүҮurl
// 2.ж №жҚ®urlдҝқеӯҳеӣҫзүҮ
// 3.дҝқеӯҳеҗҺи®°еҪ•жҲҗеҠҹе’ҢеӨұиҙҘзҡ„дҝЎжҒҜеҲ°жң¬ең°txt
});
}зЁӢеәҸзңӢиө·жқҘжІЎжңүд»Җд№Ҳй—®йўҳпјҢеҸӘејҖдәҶ6зәҝзЁӢж“ҚдҪңпјҢејҖе§ӢжІЎж•ўејҖеӨӘеӨҡзәҝзЁӢпјҢжҖ•иў«зҪ‘з«ҷжӢүй»‘гҖӮгҖӮ
дҪҶжҳҜиҝҗиЎҢиө·жқҘеӨӘж…ўдәҶпјҢдёҖжҷҡдёҠеҸӘзҲ¬дәҶ10дёӘеӨҡGпјҢзӣ®еүҚеҲҶжһҗй—®йўҳдё»иҰҒжңүдёӨзӮ№пјҡ
1.并еҸ‘ж“ҚдҪңжң¬ең°txtпјҢдјҡжӢ–ж…ўеҚ•дёӘд»»еҠЎжү§иЎҢзҡ„йҖҹеәҰ
2.зәҝзЁӢжІЎжңүе……еҲҶеҲ©з”Ё
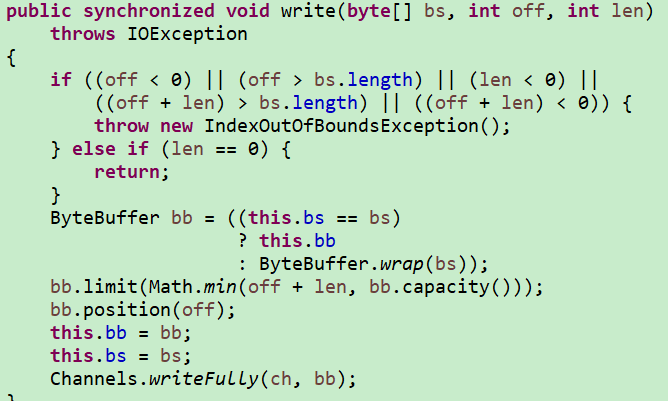
йҰ–е…ҲзңӢдёӢж“ҚдҪңж–Ү件方法еҗ§пјҢжүҖз”Ёж–№жі•жқҘиҮӘNIOпјҡ
Files.write(log, attr.getBytes("utf8"), StandardOpenOption.APPEND);йҖҡиҝҮжҹҘзңӢжәҗз ҒеҸ‘зҺ°пјҢиҜҘж–№жі•дјҡжһ„йҖ дёҖдёӘOutputStreamеҺ»и°ғз”Ёwriteж–№жі•пјҢиҖҢwriteж–№жі•дёҠжңүsynchronizedпјҢеӨҡзәҝзЁӢж“ҚдҪңж— з–‘дјҡиҪ¬дёәйҮҚйҮҸй”Ғ
йӮЈд№ҲжғіиҰҒи®°еҪ•ж—Ҙеҝ—зҡ„иҜқпјҢжңҖеҘҪжҳҜи®©е®ғ们没жңүзәҝзЁӢз«һдәүзҡ„жғ…еҶөдёӢеҶҚеҺ»ж“ҚдҪңж–Ү件пјӣ
然еҗҺжҳҜдјҳеҢ–еӨҡзәҝзЁӢж“ҚдҪңпјҢзӣёжҜ”дәҺиҺ·еҸ–urlпјҢдёӢиҪҪеӣҫзүҮиӮҜе®ҡжҳҜиҰҒжҜ”е®ғжӣҙж…ўзҡ„пјҢеҰӮжһңе…Ҳз»ҹдёҖиҺ·еҸ–urlпјҢ然еҗҺж №жҚ®urlеҶҚеҺ»дёӢиҪҪеӣҫзүҮжҳҜеҗҰдјҡжӣҙеҘҪпјҹ
第дёҖж¬ЎдјҳеҢ–пјҡ
// з”ЁдәҺи®°еҪ•жүҖжңүurl
Queue<String> queue = new ConcurrentLinkedQueue<String>();
// з”ЁдәҺи®°еҪ•жүҖжңүж—Ҙеҝ—
Queue<String> logQueue = new ConcurrentLinkedQueue<String>();
// жүҖжңүд»»еҠЎ
List<Consumer> allTasks = new ArrayList<>();
for (int j = 1; j <= жҖ»йЎөж•°; j++) {
allTasks.add(t ->{
// иҺ·еҫ—url,ж”ҫе…Ҙqueueдёӯ
});
}
// дҪҝз”ЁForkJoin并иЎҢжү§иЎҢи®°еҪ•urlзҡ„д»»еҠЎ
BatchTaskRunner.execute(allTasks, taskPerThread, tasks -> {
tasks.forEach(t->t.accept(null));
});
// е°ҶжүҖжңүurl并иЎҢжү§иЎҢдёӢиҪҪ
List<String> list = queue.stream().collect(Collectors.toList());
BatchTaskRunner.execute(list, taskPerThread, tasks -> {
tasks.forEach(
// 1.дёӢиҪҪж–Ү件
// 2.е°ҶurlжҲҗеҠҹжҲ–еӨұиҙҘж”ҫеҲ°logQueueдёӯ
);
});
// жңҖеҗҺеҶҚи®°еҪ•ж—Ҙеҝ—
logQueue.forEach(
// е°ҶжүҖжңүж—Ҙеҝ—дҝқеӯҳеҲ°жң¬ең°txtдёӯ
);иҝҷйҮҢдё»иҰҒеҲҶдёәдёүжӯҘпјҡ
1.并иЎҢжү§иЎҢд»»еҠЎпјҢжҠ“еҸ–urlж”ҫе…Ҙqueue
2.并иЎҢжү§иЎҢдёӢиҪҪпјҢд»ҺqueueдёӯеҸ–url
3.д»ҺlogQueueдёӯдҝқеӯҳж—Ҙеҝ—еҲ°жң¬ең°
еҲҶжһҗпјҡе…ҲжҳҜжҠ“еҸ–жүҖжңүurlпјҢ然еҗҺеҶҚеҺ»е№¶иЎҢжү§иЎҢдҝқеӯҳпјӣе°Ҷдҝқеӯҳж—Ҙеҝ—ж”ҫеҲ°жңҖеҗҺпјҢдҝқеӯҳдәҶеӣҫзүҮеҗҺжңҖеҗҺзҡ„ж—Ҙеҝ—еҸҚиҖҢж— е…ізҙ§иҰҒдәҶпјҢдҪҶжҳҜиҝҗиЎҢж—¶еҖҷжҲ‘еҸ‘зҺ°иҝҳжҳҜеӯҳеңЁй—®йўҳпјҡ
жҲ‘еҺ»пјҢдёәд»Җд№ҲдёҖе®ҡиҰҒе…Ҳж”ҫurlеҶҚеҺ»еӨ„зҗҶе•ҠпјҒпјҒж”ҫзҡ„еҗҢж—¶д№ҹеҸ–д»»еҠЎпјҢжңҖеҗҺеү©дҪҷзҡ„д»»еҠЎеҶҚ并иЎҢжү§иЎҢдёҚжҳҜжӣҙеҝ«пјҒ
еҘҪеҗ§пјҢжңүдәҶиҝҷдёӘжғіжі•пјҢзӣҙжҺҘејҖе№Іпјҡ
第дәҢж¬ЎдјҳеҢ–пјҡ
/****************************第дәҢж¬ЎеўһеҠ зҡ„йҖ»иҫ‘start**************************************/
// жҺ§еҲ¶дё»зәҝзЁӢжү§иЎҢ
CountDownLatch countDownLatch = new CountDownLatch(totalPageSize);
// з”ЁдәҺж¶Ҳиҙ№queueзҡ„зәҝзЁӢжұ
ThreadPoolExecutor executor = new ThreadPoolExecutor(12, 12, 0, TimeUnit.SECONDS, new SynchronousQueue<>());
// з”ЁдәҺиҮӘж—Ӣж—¶зҡ„ејҖе…і
volatile boolean flag = false;
/****************************第дәҢж¬ЎеўһеҠ зҡ„йҖ»иҫ‘end**************************************/
// з”ЁдәҺи®°еҪ•жүҖжңүurl
Queue<String> queue = new ConcurrentLinkedQueue<String>();
// з”ЁдәҺи®°еҪ•жүҖжңүж—Ҙеҝ—
Queue<String> logQueue = new ConcurrentLinkedQueue<String>();
// жүҖжңүд»»еҠЎ
List<Consumer> allTasks = new ArrayList<>();
for (int j = 1; j <= жҖ»йЎөж•°; j++) {
allTasks.add(t ->{
// иҺ·еҫ—url,ж”ҫе…Ҙqueueдёӯ
});
}
// ејҖдәҶдёҖдёӘзәҝзЁӢеҺ»жү§иЎҢпјҢдё»иҰҒжҳҜдёәдәҶи®©е®ғејӮжӯҘеҺ»ж“ҚдҪң
new Thread(()->{
// дҪҝз”ЁForkJoin并иЎҢжү§иЎҢи®°еҪ•urlзҡ„д»»еҠЎ
// finallyдёӯи°ғз”ЁcountDownLatch.countDown()
BatchTaskRunner.execute(allTasks, taskPerThread, tasks -> {
tasks.forEach(t->t.accept(null));
});
}).start();
// дёҖиҫ№жҠ“еҸ–дёҖиҫ№ж¶Ҳиҙ№
for (int i = 0; i < 12; i++) {
executor.execute(()->{
try {
takeQueue(); // д»ҺqueueиҺ·еҫ—url并ж¶Ҳиҙ№,еҰӮжһңдҝЎеҸ·йҮҸеҪ’йӣ¶еҲҷе°ҶflagзҪ®дёәtrue
} catch (InterruptedException e) {
}
});
}
for(;;) {
if(flag) {
break;
}
Thread.sleep(10000);
}
countDownLatch.await();
executor.shutdownNow();
// йғҪеҸ–е®ҢдәҶпјҢе°ұдёҚеҝ…еҶҚеҺ»е№¶иЎҢжү§иЎҢдәҶ
if(queue.size() == 0) {
return;
}
// е°ҶжүҖжңүurl并иЎҢжү§иЎҢдёӢиҪҪ
List<String> list = queue.stream().collect(Collectors.toList());
BatchTaskRunner.execute(list, taskPerThread, tasks -> {
tasks.forEach(
// 1.дёӢиҪҪж–Ү件
// 2.е°ҶurlжҲҗеҠҹжҲ–еӨұиҙҘж”ҫеҲ°logQueueдёӯ
);
});
// жңҖеҗҺеҶҚи®°еҪ•ж—Ҙеҝ—
logQueue.forEach(
// е°ҶжүҖжңүж—Ҙеҝ—дҝқеӯҳеҲ°жң¬ең°txtдёӯ
);е…¶дёӯзҡ„takeQueueж–№жі•йҖ»иҫ‘пјҡ
void takeQueue() throws InterruptedException {
for(;;) {
long count = countDownLatch.getCount();
// жңӘеҪ’йӣ¶еҲҷдёҖзӣҙеҺ»ж¶Ҳиҙ№
if(count > 0) {
String poll = queue.poll();
if(poll != null) {
consumer.accept(poll); // ж №жҚ®urlеҺ»дёӢиҪҪ
}else {
Thread.sleep(3000);
}
} else {
flag = true;
return;
}
}
}еӨ§жҰӮж’ёдәҶдёӘйҖ»иҫ‘пјҢж—Ҙеҝ—д»Җд№Ҳзҡ„е·Із»ҸдёҚйҮҚиҰҒдәҶгҖӮгҖӮгҖӮ
дё»зәҝзЁӢиҮӘж—ӢпјҢдҝқеӯҳurlеҗҢж—¶еҺ»е№¶еҸ‘дёӢиҪҪпјҢеҰӮжһңдҝқеӯҳurlзҡ„йҖ»иҫ‘жү§иЎҢе®ҢдәҶйҳҹеҲ—дёӯиҝҳжңүurlпјҢеҲҷ并иЎҢеҺ»дёӢиҪҪ
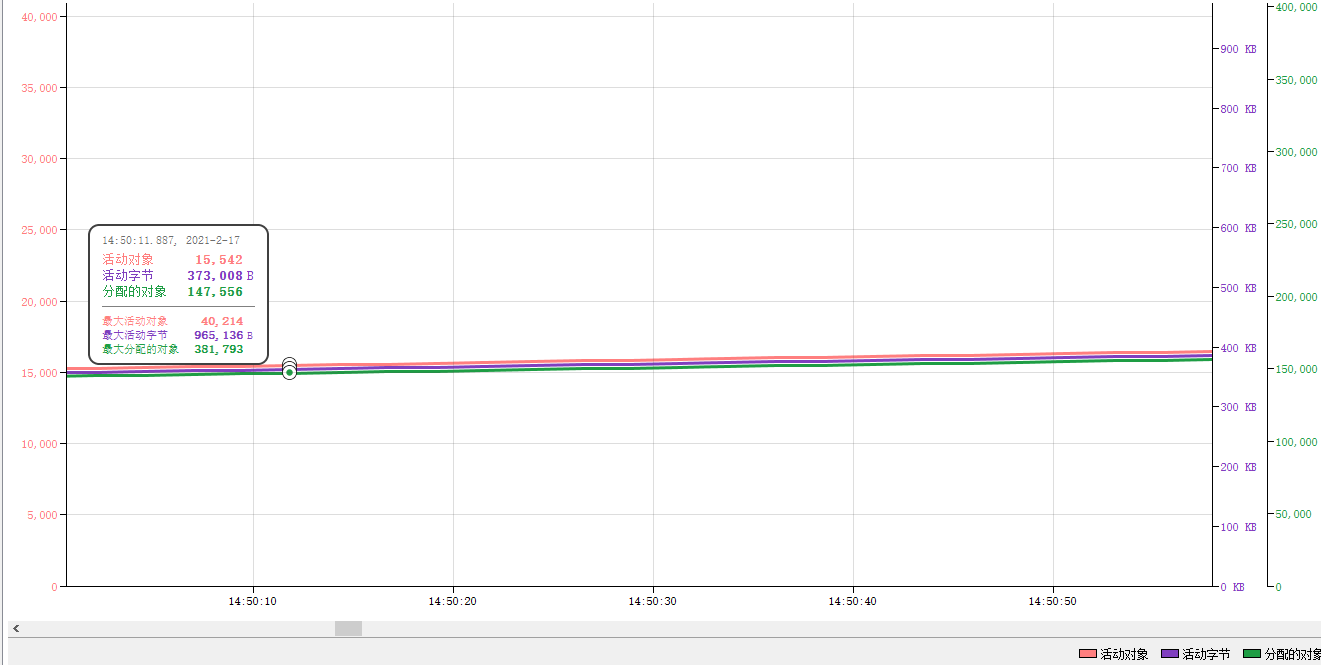
зңӢзқҖзәҝзЁӢйғҪз”ЁдёҠдәҶпјҢж„ҹи§үзҲҪеӨҡдәҶ

еҚідҪҝеңЁж¶Ҳиҙ№пјҢqueueдёӯеҜ№иұЎиҝҳжҳҜи¶ҠжқҘи¶ҠеӨҡ
вҖңжҖҺд№Ҳз”Ёjsoupе®һзҺ°жҠ“еҸ–еӣҫзүҮзҲ¬иҷ«вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





