本篇内容主要讲解“Spark分区并行度决定机制”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Spark分区并行度决定机制”吧!
大家都知道Spark job中最小执行单位为task,合理设置Spark job每个stage的task数是决定性能好坏的重要因素之一,但是Spark自己确定最佳并行度的能力有限,这就要求我们在了解其中内在机制的前提下,去各种测试、计算等来最终确定最佳参数配比。
对于通过SparkContext的parallelize方法或者makeRDD生成的RDD分区数可以直接在方法中指定,如果未指定,则参考spark.default.parallelism的参数配置。下面是默认情况下确定defaultParallelism的源码:
override def defaultParallelism(): Int = {
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
}
通常,RDD的分区数与其所依赖的RDD的分区数相同,除非shuffle。但有几个特殊的算子:
1.coalesce和repartition算子
笔者先放两张关于该coalesce算子分别在RDD和DataSet中的源码图:(DataSet是Spark SQL中的分布式数据集,后边说到Spark时再细讲)
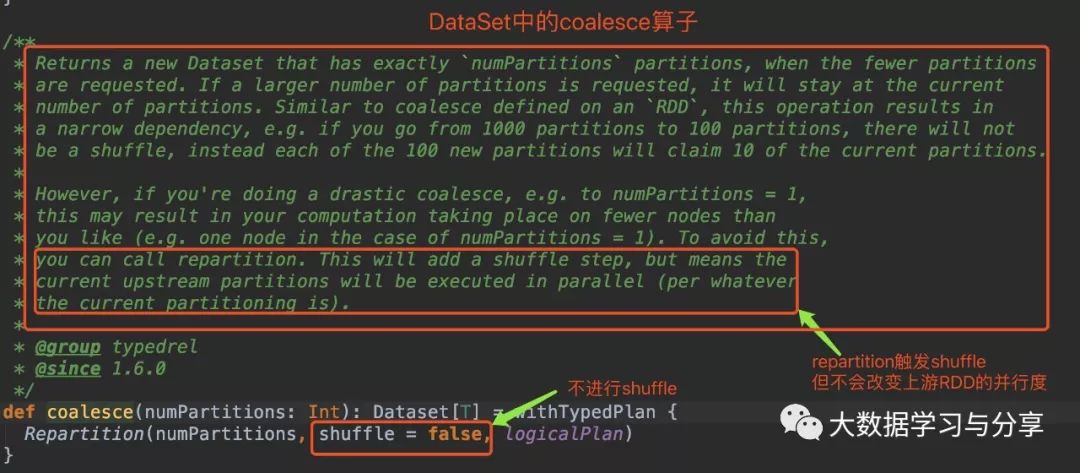
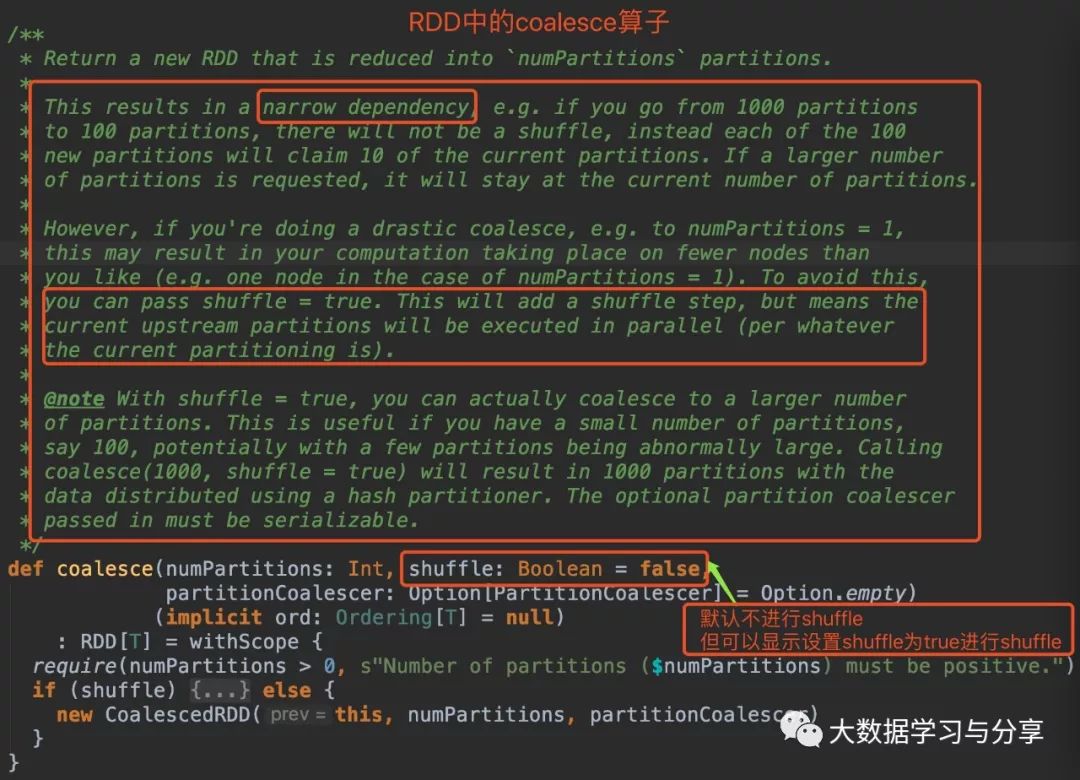
通过coalesce源码分析,无论是在RDD中还是DataSet,默认情况下coalesce不会产生shuffle,此时通过coalesce创建的RDD分区数小于等于父RDD的分区数。
笔者这里就不放repartition算子的源码了,分析起来也比较简单,图中我有所提示。但笔者建议,如下两种情况,请使用repartition算子:
coalesce默认不触发shuffle,即使调用该算子增加分区数,实际情况是分区数仍然是当前的分区数。
2.union算子
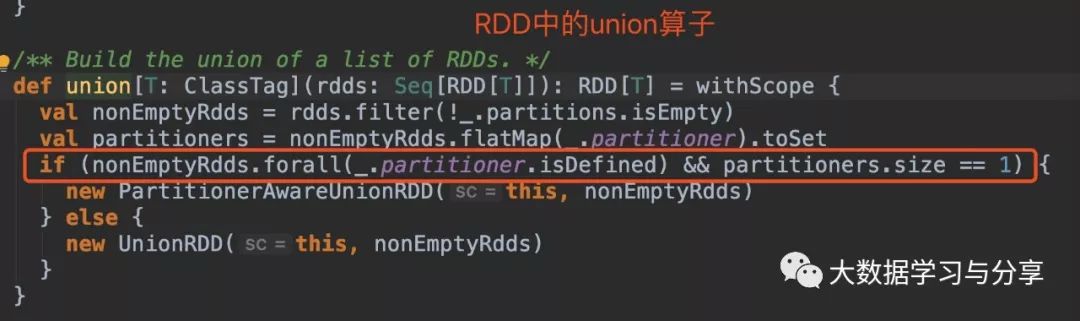
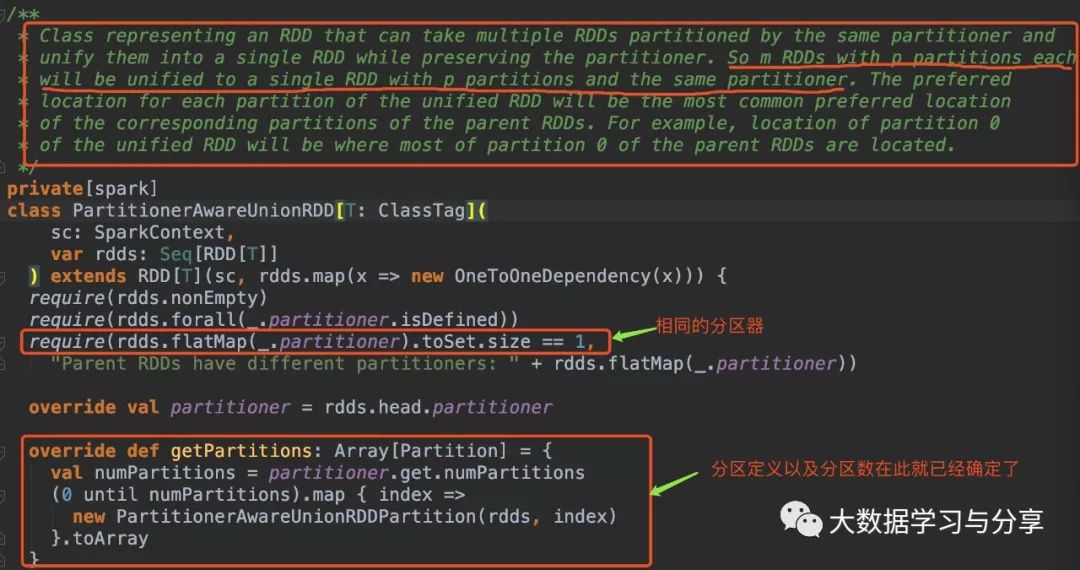

多个父RDD具有相同的分区器,union后产生的RDD的分区器与父RDD相同且分区数也相同。比如,n个RDD的分区器相同且是defined,分区数是m个。那么这n个RDD最终union生成的一个RDD的分区数仍是m,分区器也是相同的
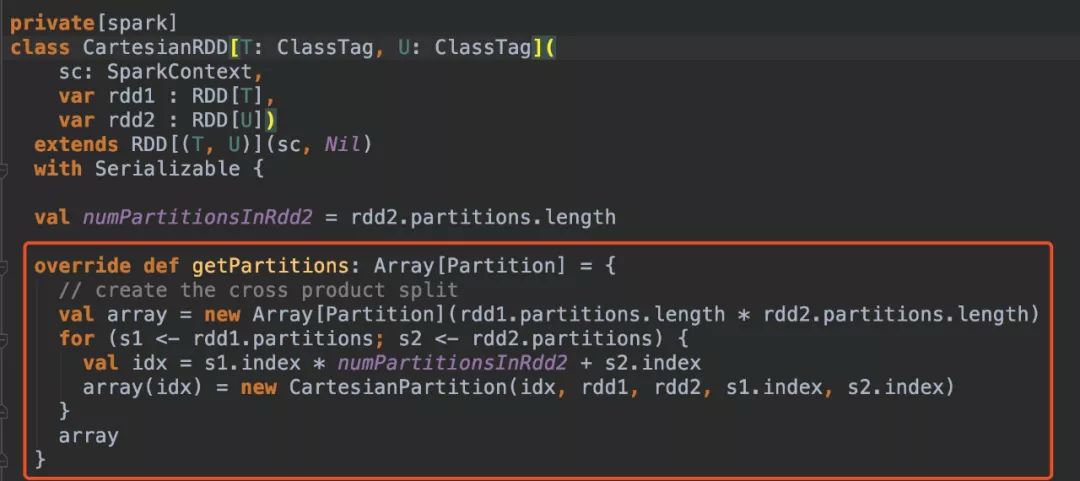
通过上述coalesce、repartition、union算子介绍和源码分析,很容易分析cartesian算子的源码。通过cartesian得到RDD分区数是其父RDD分区数的乘积。
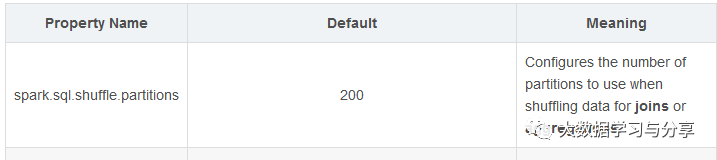
在Spark SQL中,任务并行度参数则要参考spark.sql.shuffle.partitions,笔者这里先放一张图,详细的后面讲到Spark SQL时再细说:
看下图在Spark流式计算中,通常将SparkStreaming和Kafka整合,这里又分两种情况:
1.Receiver方式生成的微批RDD即BlockRDD,分区数就是block数
到此,相信大家对“Spark分区并行度决定机制”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





