本篇文章为大家展示了怎么进行Spark和MapReduce的对比,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
下面给大家介绍Spark和MapReduce,并且能够在遇到诸如"MapReduce相对于Spark的局限性?"
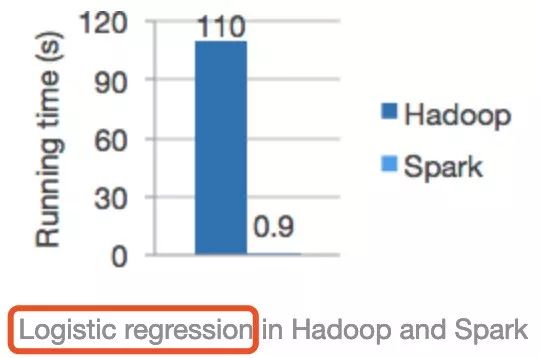
首先,大多数机器学习算法的核心是什么?就是对同一份数据在训练模型时,进行不断的迭代、调参然后形成一个相对优的模型。而Spark作为一个基于内存迭代式大数据计算引擎很适合这样的场景,之前的文章《Spark RDD详解》也有介绍,对于相同的数据集,我们是可以在第一次访问它之后,将数据集加载到内存,后续的访问直接从内存中取即可。但是MapReduce由于运行时中间结果必然刷磁盘等因素,导致不适合机器学习等的迭代场景应用,还有就是HDFS本身也有缓存功能,官方的对比极有可能在运行逻辑回归时没有很好配置该缓存功能,否则性能差距也不至于这么大。
1.集流批处理、交互式查询、机器学习及图计算等于一体
2.基于内存迭代式计算,适合低延迟、迭代运算类型作业
3.可以通过缓存共享rdd、DataFrame,提升效率【尤其是SparkSQL可以将数据以列式的形式存储于内存中】
4.中间结果支持checkpoint,遇错可快速恢复
5.支持DAG、map之间以pipeline方式运行,无需刷磁盘
6.多线程模型,每个worker节点运行一个或多个executor服务,每个task作为线程运行在executor中,task间可共享资源
1.适合离线数据处理,不适合迭代计算、交互式处理、流式处理
2.中间结果需要落地,需要大量的磁盘IO和网络IO影响性能
3.虽然MapReduce中间结果可以存储于HDFS,利用HDFS缓存功能,但相对Spark缓存功能较低效
4.多进程模型,任务调度(频繁申请、释放资源)和启动开销大,不适合低延迟类型作业
5.MR编程不够灵活,仅支持map和reduce两种操作。当一个计算逻辑复杂的时候,需要写多个MR任务运行【并且这些MR任务生成的结果在下一个MR任务使用时需要将数据持久化到磁盘才行,这就不可避免的进行遭遇大量磁盘IO影响效率】
上述内容就是怎么进行Spark和MapReduce的对比,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





