本篇内容介绍了“如何用Java实现一致性Hash算法”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
现在通常使用Redis来做分布式缓存,下面我们就以Redis为例:

假如当前我们系统的业务发展很快,需要缓存的数据很多,所以我们做了一个由三组主从复制的redis组成的高可用的redis集群,如何将请求路由的不同的redis集群上,这是我们需要考虑的,常用的路由算法:
随机算法:每次将请求随机的发送到其中一组Redis集群中,这种算法的好处是请求会被均匀的分发到每组Redis集群上;缺点也很明显,由于随机分发请求,为了提高缓存的命中率,所以同一份数据需要在每组集群中都存在,这样就会造成了数据的冗余,浪费了存储空间
Hash算法:针对随机算法的问题,我们可以考虑Hash算法,举例: 现在有三组redis集群,我们可以对每次缓存key的hash值取模,公式:index=hash(key) % 3,index的值就对应着3组集群,这样就可以保证同一个请求每次都被分发到同一个redis集群上,无需对数据做冗余,完美的解决了刚才随机算法的缺点;
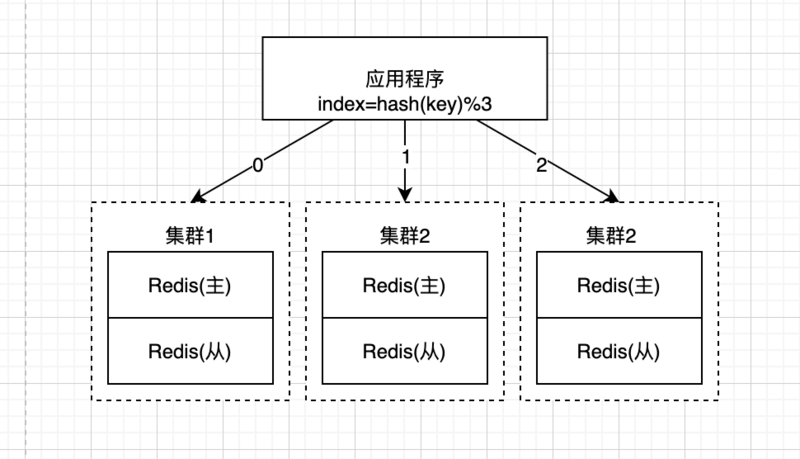
但是hash算法也有缺点:对于容错性和伸缩性支持很差,举例:当我们三组redis集群中其中一组节点宕机了,那么此时的redis集群中可用的数量变成了2,公式变成了index=hash(key) % 2, 所有数据缓存的节点位置就发生了变化,造成缓存的命中率直线下降;
同理,当我们需要扩展一组新的redis机器,计算的公式index=hash(key) % 4,大量的key会被重新定位到其他服务器,也会造成缓存的命中率下降。
为了解决hash算法容错性和伸缩性的问题,一致性hash算法由此而生~
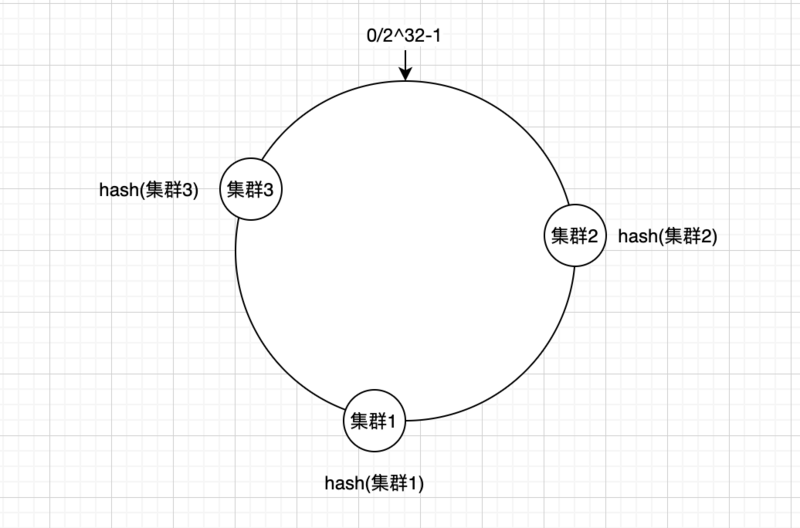
先构造一个长度为2^32-1的整数环(称为一致性hash环),然后给每组redis集群命名,根据名字的hash值计算出每组集群应该放在什么位置
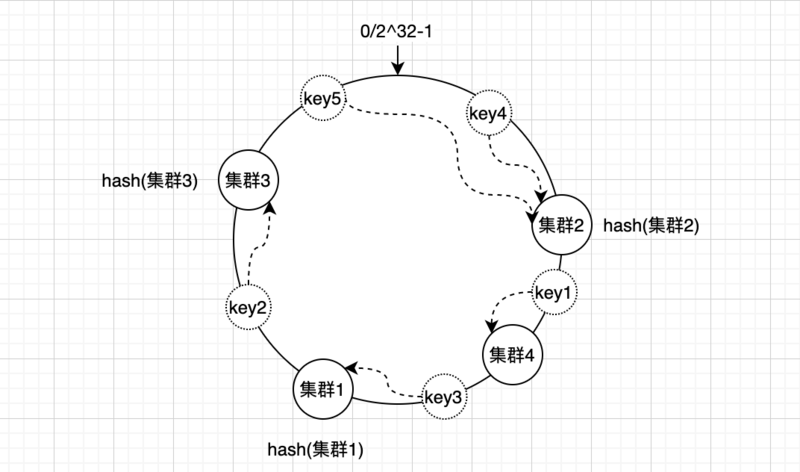
根据缓存数据的key计算出hash值,计算出出来的hash值同样也分布在一致性hash环上; 假如现在有5个数据需要缓存对应的key分别为key1、key2、key3、key4、key5,计算hash值之后的分部如下图
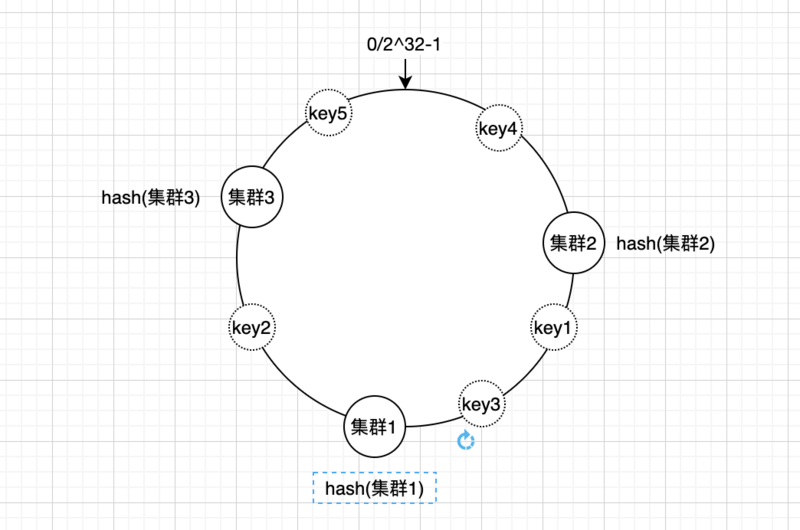
然后顺着hash环顺时针方向查找reids集群,把数据存放到最近的集群上
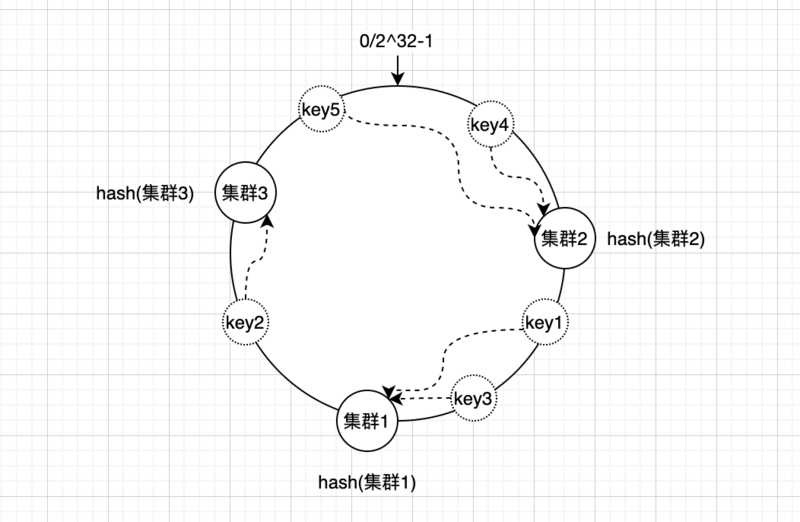
最后所有key4、key5存放在了集群2,key1、key3存放在了集群1,key2存放在了集群3
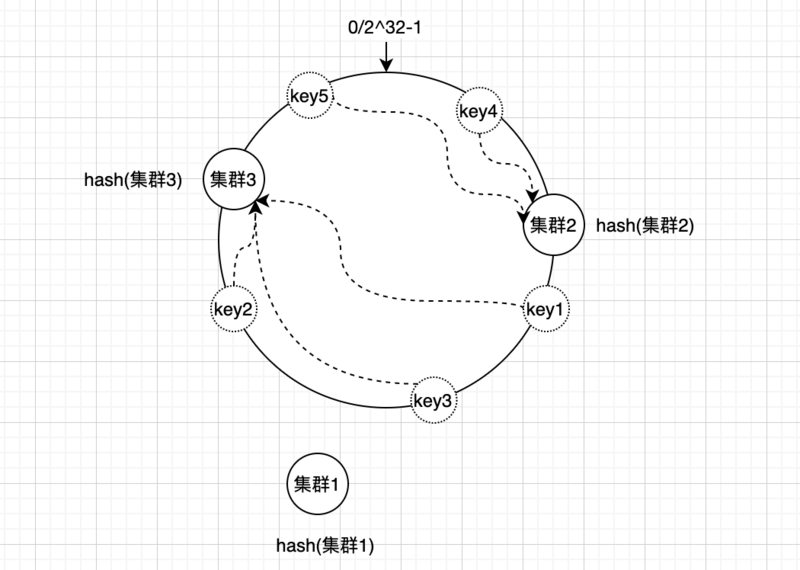
还是继续沿用上面的例子,我们来看下一致性哈希算法的容错性如何呢?假如其中 集群1 跪了,那么影响的数据只有key1和key3,其他数据存放的位置不受影响;当再次缓存key1、key3的时候根据顺时针查找,会把数据存放到集群3上面
如果我们需要在当前的基础上再添加一组redis集群4,根据名字hash之后的位置在集群1和集群2之间
新加redis集群4之后影响的只有key1数据,其他数据不受影响。
经过容错性、伸缩性的验证证明了一致性哈希算法确实能解决Hash算法的问题,但是现在的算法就是完美的吗?让我们继续来看刚才容错性的例子,加入集群1跪了,那么原来落在集群1上的所有数据会直接落在集群3上面,如果说每组redis集群的配置都是一样的,那么集群3的压力会增大,数据分布不均匀造成数据倾斜问题。
怎么搞呢?
歪果仁的脑子就是好使,给的解决方案就是加一层虚拟层,假如每组集群都分配了2个虚拟节点
| 集群 | 虚拟节点 |
|---|---|
| 集群1 | vnode1, vnode2 |
| 集群2 | vnode3, vnode4 |
| 集群3 | vnode5, vnode6 |
接下来就是把虚拟节点放入到一致性hash环上,在缓存数据的时候根据顺时针查找虚拟节点,在根据虚拟节点的和实际集群的对应关系把数据存放到redis集群,这样数据就会均匀的分布到各组集群中。

这时候如果有一组redis集群出现了问题,那么这组集群上面的key会相对均匀的分摊到其他集群上。
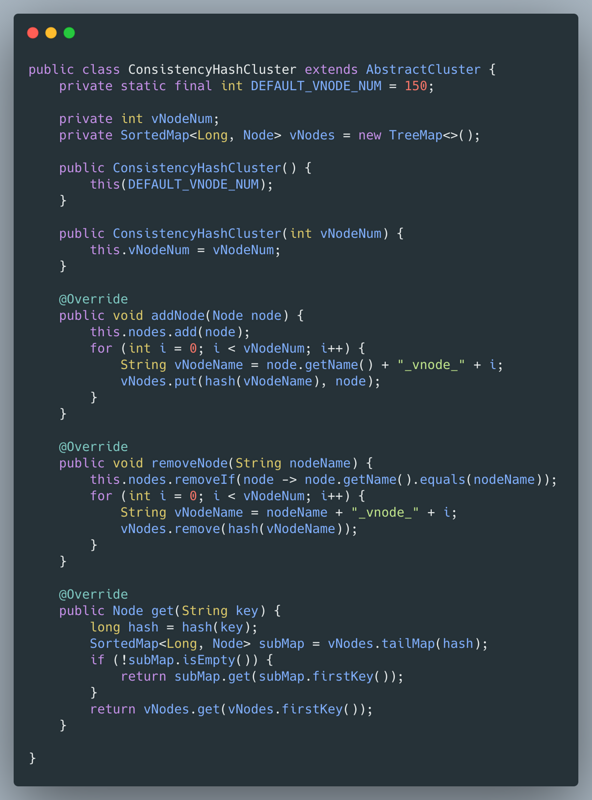
从上面的结果来看,只要每组集群对应的虚拟节点越多,那么各个物理集群的数据分布越均匀,当新增加或者减少物理集群影响也会最小,但是如果虚拟节点太多会影响查找的性能,太少数据又会不均匀,那么多少合适呢?根据一些大神的经验给出的建议是 150 个虚拟节点。
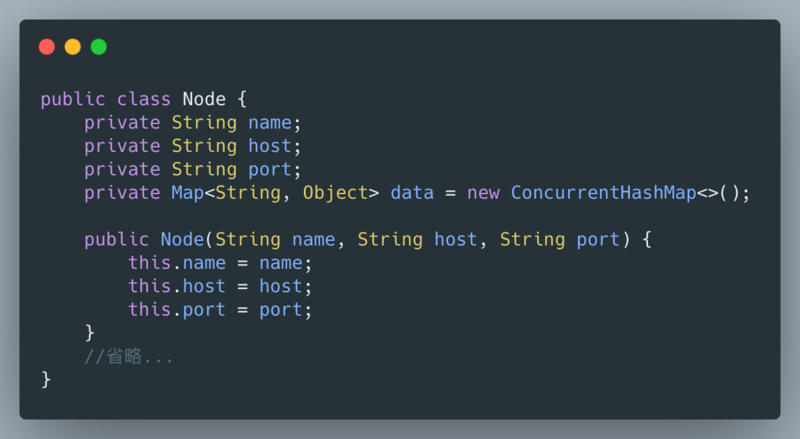
实现思路:在每次添加物理节点的时候,根据物理节点的名字生成虚拟节点的名字,把虚拟节点的名字求hash值,然后把hash值作为key,物理节点作为value存放到Map中;这里我们选择使用TreeMap,因为需要key是顺序的存储;在计算数据key需要存放到哪个物理节点时,先计算出key的hash值,然后调用TreeMap.tailMap()返回比hash值大的map子集,如果子集为空就需要把TreeMap的第一个元素返回,如果不为空,那么取子集中的第一个元素。
> 不扯废话,直接上代码,No BB . Show me the code
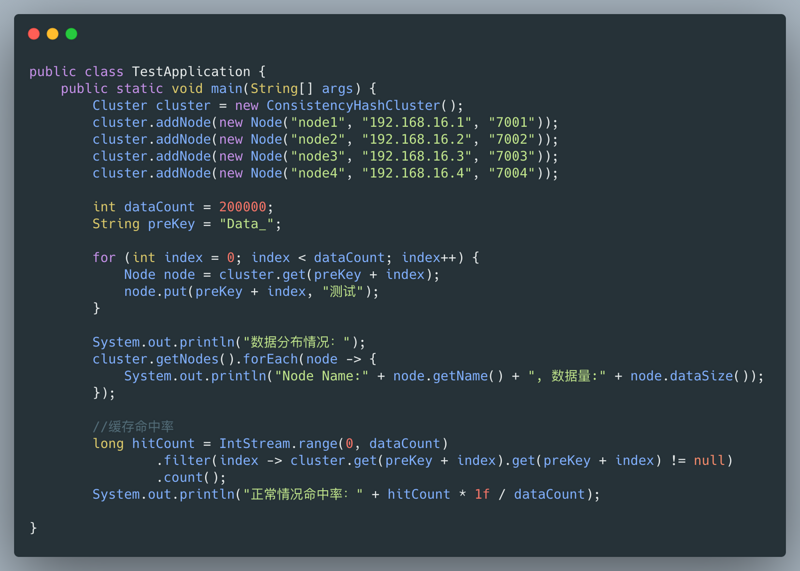
测试删除节点node3,对比命中率影响了多少 添加如下代码:
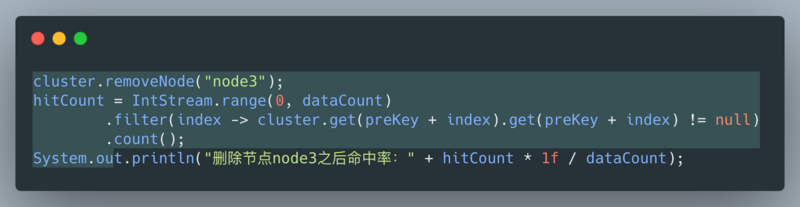
执行结果:
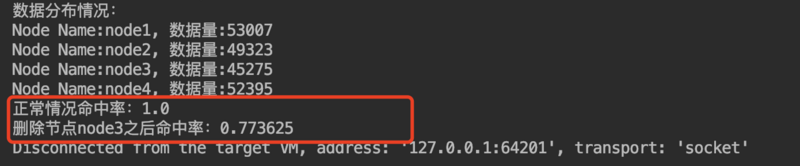
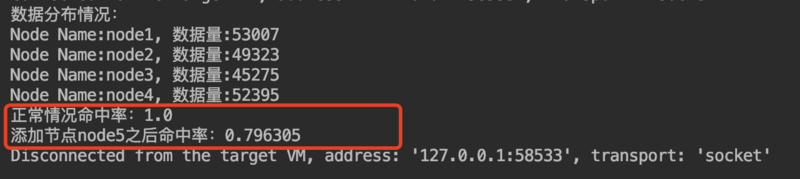
测试添加节点node5,对比命中率影响了多少 添加如下代码:
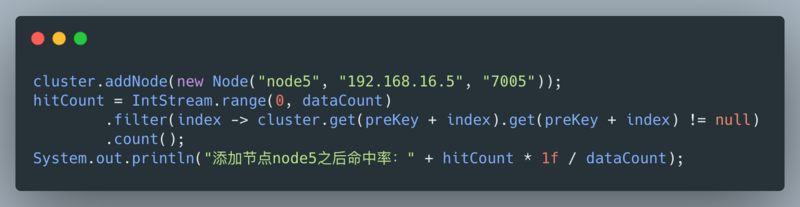
执行结果:

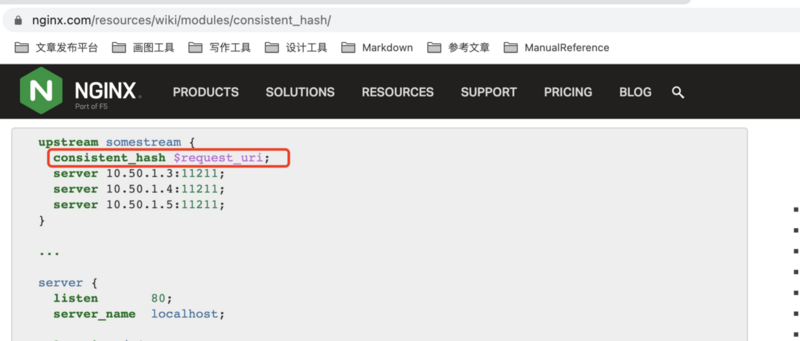
看上图,在Nginx请求的分发过程中,为了让应用本地的缓存命中率最高,我们希望根据请求的URL或者URL参数将相同的请求转发到同一个应用服务器中,这个时候也可以选择使用一致性hash算法。具体配置可以参考官方文档: https://www.nginx.com/resources/wiki/modules/consistent_hash/
“如何用Java实现一致性Hash算法”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3230120/blog/4893445



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



