本篇内容主要讲解“HBase面试题有哪些”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“HBase面试题有哪些”吧!
Hbase一个分布式的基于列式存储的数据库,基于Hadoop的 hdfs 存储,zookeeper 进行管理。
Hbase适合存储半结构化或非结构化数据,对于数据结构字段不够确定或者杂乱无章很难按一个概念去抽取的数据。
Hbase 为 null 的记录不会被存储。
基于的表包含 rowkey,时间戳,和列族。新写入数据时,时间戳更新, 同时可以查询到以前的版本。
hbase 是主从架构。hmaster 作为主节点,hregionserver 作为从节点。
大:一个表可以有数十亿行,上百万列;
无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一
张表中不同的行可以有截然不同的列;
面向列:面向列(族)的存储和权限控制,列(族)独立检索;
稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元
格插入时的时间戳;
数据类型单一:Hbase 中的数据都是字符串,没有类型。
通过HBase API进行批量写入数据;
使用Sqoop工具批量导数到HBase集群;
使用MapReduce批量导入;
HBase BulkLoad的方式。
HBase 通过Hive 关联导入数据
HBase API 跟 MapReduce写入方式在面对大数据量写入的时候效率会很低下,因为它们都是通过请求regionserver将数据写入,这期间数据会先写入memstore,memstore达到阈值后会刷写到磁盘生成hfile文件,hfile文件过多时会发生compaction,如果region大小过大时也会发生split。这些因素都会影响hbase数据写入的效率,因此在面临大数据写入时,这两种方式是不合适的。
而bulkload正好解决了这个问题,bulkload 工具是将数据直接写入到hfile文件中,写入完毕后,通知hbase去加载这些hfile文件,因此可以避免上述耗时的因素,大大增加了数据写入的效率。下面就来讲述下如何利用bulkloan加载数据。
共同点:
hbase与hive都是架构在hadoop之上的。都是用hadoop作为底层存储。
区别:
Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop;
Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多;
Hive本身不存储和计算数据,它完全依赖于 HDFS 和 MapReduce,Hive中的表纯逻辑;
hive借用hadoop的MapReduce来完成一些hive中的命令的执行;
hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作;
hbase是列存储;
hdfs 作为底层存储,hdfs 是存放文件的系统,而 Hbase 负责组织文件;
hive 需要用到 hdfs 存储文件,需要用到 MapReduce 计算框架。
实时查询,可以认为是从内存中查询,一般响应时间在 1 秒内。HBase 的机制是数据先写入到内存中,当数据量达到一定的量(如 128M),再写入磁盘中, 在内存中,是不进行数据的更新或合并操作的,只增加数据,这使得用户的写操作只要进入内存中就可以立即返回,保证了 HBase I/O 的高性能
联系 region 和 rowkey 关系说明,设计可参考以下三个原则.
1. rowkey 长度原则
rowkey 是一个二进制码流,可以是任意字符串,最大长度 64kb,实际应用中一般为 10-100bytes,以 byte[] 形式保存,一般设计成定长。建议越短越好,不要超过 16 个字节, 原因如下:
数据的持久化文件 HFile 中是按照 KeyValue 存储的,如果 rowkey 过长会极大影响 HFile 的存储效率 MemStore 将缓存部分数据到内存,如果 rowkey 字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率
2. rowkey 散列原则
如果 rowkey 按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将 rowkey 的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个 RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个 RegionServer 上,这样在数据检索的时候负载会集中在个别的 RegionServer 上,造成热点问题,会降低查询效率。
3. rowkey 唯一原则
必须在设计上保证其唯一性,rowkey 是按照字典顺序排序存储的,因此, 设计 rowkey 的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
按指定RowKey 获取唯 一 一 条 记 录 , get 方法( org.apache.hadoop.hbase.client.Get ) Get的方法处理分两种 : 设置了ClosestRowBefore和没有设置的 rowlock 主要是用来保证行的事务性,即每个get 是以一个 row 来标记的.一个 row 中可以有很多 family 和 column。
按指定的条件获取一批记录,scan 方法(org.apache.Hadoop.hbase.client.Scan)实现条件查询功能使用的就是 scan 方式
1. scan 可以通过 setCaching 与 setBatch 方法提高速度(以空间换时间);
2. scan 可以通过 setStartRow 与 setEndRow 来限定范围([start,end]start? 是闭区间,end 是开区间)。范围越小,性能越高;
3. scan 可以通过 setFilter 方法添加过滤器,这也是分页、多条件查询的基础。 3.全表扫描,即直接扫描整张表中所有行记录。
HBase 中通过 row 和 columns 确定的为一个存贮单元称为 cell。Cell:由{row key, CF,Columns, version}是唯一确定的单元cell 中的数据是没有类型的,全部是字节码形式存贮。
在 hbase 中每当有 memstore 数据 flush 到磁盘之后,就形成一个 storefile, 当 storeFile 的数量达到一定程度后,就需要将 storefile 文件来进行 compaction 操作。Compact 的作用:
合并文件
清除过期,多余版本的数据
提高读写数据的效率
Minor 操作只用来做部分文件的合并操作以及包括 minVersion=0 并且设置 TTL 的过期版本清理,不做任何删除数据、多版本数据的清理工作;
Major 操作是对 Region 下的 HStore 下的所有 StoreFile 执行合并操作, 最终的结果是整理合并出一个文件。
Minor and Major 合并规则
HBase 为筛选数据提供了一组过滤器,通过这个过滤器可以在 HBase 中的数据的多个维度(行,列,数据版本)上进行对数据的筛选操作,也就是说过滤器最终能够筛选的数据能够细化到具体的一个存储单元格上(由行键, 列名,时间戳定位)。
RowFilter、PrefixFilter。hbase 的 filter 是通过 scan 设置的,所以是基于 scan 的查询结果进行过滤. 过滤器的类型很多,但是可以分为两大类——比较过滤器,专用过滤器。过滤器的作用是在服务端判断数据是否满足条件,然后只将满足条件的数据返回给客户端;如在进行订单开发的时候,我们使用 rowkeyfilter 过滤出某个用户的所有订单。
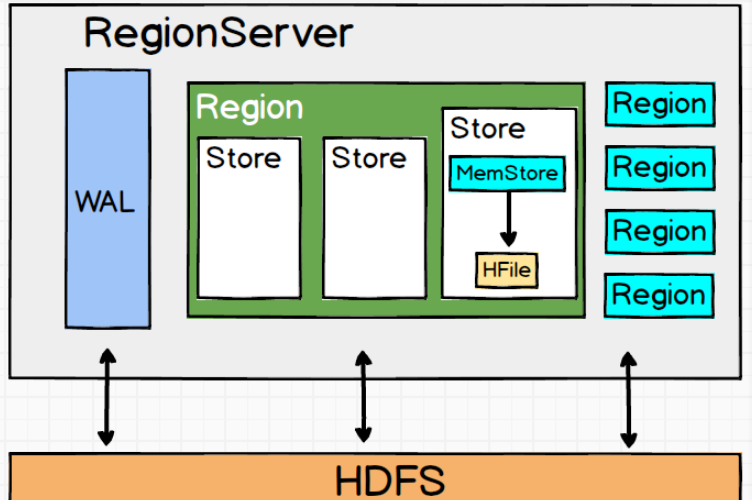
在 HBase 中无论是增加新行还是修改已有的行,其内部流程都是相同的。HBase 接到命令后存下变化信息,或者写入失败抛出异常。默认情况下,执行写入时会写到两个地方:预写式日志(write-ahead log,也称 HLog)和 MemStore。HBase 的默认方式是把写入动作记录在这两个地方,以保证数据持久化。只有当这两个地方的变化信息都写入并确认后,才认为写动作完成。
MemStore 是内存里的写入缓冲区,HBase 中数据在永久写入硬盘之前在这里累积。当MemStore 填满后,其中的数据会刷写到硬盘,生成一个HFile。HFile 是HBase 使用的底层存储格式。HFile 对应于列族,一个列族可以有多个 HFile,但一个 HFile 不能存储多个列族的数据。在集群的每个节点上,每个列族有一个MemStore。大型分布式系统中硬件故障很常见,HBase 也不例外。
设想一下,如果MemStore 还没有刷写,服务器就崩溃了,内存中没有写入硬盘的数据就会丢失。HBase 的应对办法是在写动作完成之前先写入 WAL。HBase 集群中每台服务器维护一个 WAL 来记录发生的变化。WAL 是底层文件系统上的一个文件。直到WAL 新记录成功写入后,写动作才被认为成功完成。这可以保证 HBase 和支撑它的文件系统满足持久性。
大多数情况下,HBase 使用Hadoop分布式文件系统(HDFS)来作为底层文件系统。如果 HBase 服务器宕机,没有从 MemStore 里刷写到 HFile 的数据将可以通过回放 WAL 来恢复。你不需要手工执行。Hbase 的内部机制中有恢复流程部分来处理。每台 HBase 服务器有一个 WAL,这台服务器上的所有表(和它们的列族)共享这个 WAL。你可能想到,写入时跳过 WAL 应该会提升写性能。但我们不建议禁用 WAL, 除非你愿意在出问题时丢失数据。如果你想测试一下,如下代码可以禁用 WAL: 注意:不写入 WAL 会在 RegionServer 故障时增加丢失数据的风险。关闭 WAL, 出现故障时 HBase 可能无法恢复数据,没有刷写到硬盘的所有写入数据都会丢失。
宕机分为 HMaster 宕机和 HRegisoner 宕机.
如果是 HRegisoner 宕机,HMaster 会将其所管理的 region 重新分布到其他活动的 RegionServer 上,由于数据和日志都持久在 HDFS 中,该操作不会导致数据丢失,所以数据的一致性和安全性是有保障的。
如果是 HMaster 宕机, HMaster 没有单点问题, HBase 中可以启动多个HMaster,通过 Zookeeper 的 Master Election 机制保证总有一个 Master 运行。即ZooKeeper 会保证总会有一个 HMaster 在对外提供服务。
ZooKeeper 会监控 HRegionServer 的上下线情况,当 ZK 发现某个 HRegionServer 宕机之后会通知 HMaster 进行失效备援;
HRegionServer 会停止对外提供服务,就是它所负责的 region 暂时停止对外提供服务
HMaster 会将该 HRegionServer 所负责的 region 转移到其他 HRegionServer 上,并且会对 HRegionServer 上存在 memstore 中还未持久化到磁盘中的数据进行恢复;
这个恢复的工作是由 WAL重播 来完成,这个过程如下:
1. wal实际上就是一个文件,存在/hbase/WAL/对应RegionServer路径下 2. 宕机发生时,读取该RegionServer所对应的路径下的wal文件,然后根据不同的region切分成不同的临时文件recover.edits 3. 当region被分配到新的RegionServer中,RegionServer读取region时会进行是否存在recover.edits,如果有则进行恢复
写数据和读数据一般都会获取hbase的region的位置信息。大概步骤为:
从zookeeper中获取.ROOT.表的位置信息,在zookeeper的存储位置为/hbase/root-region-server;
根据.ROOT.表中信息,获取.META.表的位置信息;
META.表中存储的数据为每一个region存储位置;
hbase中缓存分为两层:Memstore 和 BlockCache
首先写入到 WAL文件 中,目的是为了数据不丢失;
再把数据插入到 Memstore缓存中,当 Memstore达到设置大小阈值时,会进行flush进程;
flush过程中,需要获取每一个region存储的位置。
BlockCache 主要提供给读使用。读请求先到 Memtore中查数据,查不到就到 BlockCache 中查,再查不到就会到磁盘上读,并把读的结果放入 BlockCache 。
BlockCache 采用的算法为 LRU(最近最少使用算法),因此当 BlockCache 达到上限后,会启动淘汰机制,淘汰掉最老的一批数据。
一个 RegionServer 上有一个 BlockCache 和N个 Memstore,它们的大小之和不能大于等于 heapsize * 0.8,否则 hbase 不能启动。默认 BlockCache 为 0.2,而 Memstore 为 0.4。对于注重读响应时间的系统,应该将 BlockCache 设大些,比如设置BlockCache =0.4,Memstore=0.39。这会加大缓存命中率。
优化手段主要有以下四个方面
减少调整这个如何理解呢?HBase中有几个内容会动态调整,如region(分区)、HFile,所以通过一些方法来减少这些会带来I/O开销的调整
Region
如果没有预建分区的话,那么随着region中条数的增加,region会进行分裂,这将增加I/O开销,所以解决方法就是根据你的RowKey设计来进行预建分区,减少region的动态分裂。
HFile
HFile是数据底层存储文件,在每个memstore进行刷新时会生成一个HFile,当HFile增加到一定程度时,会将属于一个region的HFile进行合并,这个步骤会带来开销但不可避免,但是合并后HFile大小如果大于设定的值,那么HFile会重新分裂。为了减少这样的无谓的I/O开销,建议估计项目数据量大小,给HFile设定一个合适的值
数据库事务机制就是为了更好地实现批量写入,较少数据库的开启关闭带来的开销,那么HBase中也存在频繁开启关闭带来的问题。
1. 关闭Compaction,在闲时进行手动Compaction
因为HBase中存在Minor Compaction和Major Compaction,也就是对HFile进行合并,所谓合并就是I/O读写,大量的HFile进行肯定会带来I/O开销,甚至是I/O风暴,所以为了避免这种不受控制的意外发生,建议关闭自动Compaction,在闲时进行compaction
2. 批量数据写入时采用BulkLoad
如果通过HBase-Shell或者JavaAPI的put来实现大量数据的写入,那么性能差是肯定并且还可能带来一些意想不到的问题,所以当需要写入大量离线数据时建议使用BulkLoad
虽然我们是在进行大数据开发,但是如果可以通过某些方式在保证数据准确性同时减少数据量,何乐而不为呢?
1. 开启过滤,提高查询速度
开启BloomFilter,BloomFilter是列族级别的过滤,在生成一个StoreFile同时会生成一个MetaBlock,用于查询时过滤数据
2. 使用压缩:一般推荐使用Snappy和LZO压缩
在一张HBase表格中RowKey和ColumnFamily的设计是非常重要,好的设计能够提高性能和保证数据的准确性
RowKey设计:应该具备以下几个属性
散列性:散列性能够保证相同相似的rowkey聚合,相异的rowkey分散,有利于查询
简短性:rowkey作为key的一部分存储在HFile中,如果为了可读性将rowKey设计得过长,那么将会增加存储压力
唯一性:rowKey必须具备明显的区别性
业务性:举些例子
假如我的查询条件比较多,而且不是针对列的条件,那么rowKey的设计就应该支持多条件查询
如果我的查询要求是最近插入的数据优先,那么rowKey则可以采用叫上Long.Max-时间戳的方式,这样rowKey就是递减排列
2. 列族的设计
列族的设计需要看应用场景
多列族设计的优劣
优势:
HBase中数据时按列进行存储的,那么查询某一列族的某一列时就不需要全盘扫描,只需要扫描某一列族,减少了读I/O;
其实多列族设计对减少的作用不是很明显,适用于读多写少的场景。
劣势:
降低了写的I/O性能。原因如下:数据写到store以后是先缓存在memstore中,同一个region中存在多个列族则存在多个store,每个store都一个memstore,当其实memstore进行flush时,属于同一个region的store中的memstore都会进行flush,增加I/O开销。
在 Hbase 的表中,每个列族对应 Region 中的一个Store,Region的大小达到阈值时会分裂,因此如果表中有多个列族,则可能出现以下现象:
一个Region中有多个Store,如果每个CF的数据量分布不均匀时,比如CF1为100万,CF2为1万,则Region分裂时导致CF2在每个Region中的数据量太少,查询CF2时会横跨多个Region导致效率降低。
如果每个CF的数据分布均匀,比如CF1有50万,CF2有50万,CF3有50万,则Region分裂时导致每个CF在Region的数据量偏少,查询某个CF时会导致横跨多个Region的概率增大。
多个CF代表有多个Store,也就是说有多个MemStore(2MB),也就导致内存的消耗量增大,使用效率下降。
Region 中的 缓存刷新 和 压缩 是基本操作,即一个CF出现缓存刷新或压缩操作,其它CF也会同时做一样的操作,当列族太多时就会导致IO频繁的问题。
延迟: Mapreduce编程框架延迟较高,无法满足大规模数据实时处理应用的需求
访问: HDFS面向批量访问而不是随机访问
为什么用HBase而不用传统关系型数据库? / 关系型数据库和HBase有什么区别?
数据类型: 传统关系型数据库有丰富的数据类型,HBase把数据存储为未经解释的字符串
数据操作: 关系数据库包含了丰富的操作,可涉及复杂的多表连接,而HBase只有简单的插入查询删除清空等,不涉及表与表的连接
存储模式: 关系数据库基于行存储,HBase基于列存储
数据索引: 关系数据库可构建复杂的多个索引以提高检索效率;HBase只有一个索引:行键(RowKey),经过巧妙地设计,通过rowkey索引或扫描,不会使系统慢下来
数据维护: 关系数据库更新会覆盖原值,HBase则是生成一个新的版本,旧数据依然保留
可伸缩性: 关系数据库很难实现横向扩展,而HBase能够容易地通过在集群中增加或减少硬件实现性能地伸缩
一个HBase表, 由多个Region组成,这些Region可以不在一个Region Server上;
根据RowKey切分Region,某个或某个连续范围内的RowKey会被切分到一个Region
一个Store 对应 一个列族的数据,但一个列族由于Region的切分,可能对应多个store
寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器
到此,相信大家对“HBase面试题有哪些”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





