本篇文章为大家展示了什么是树、二叉树以及二叉查找树,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
说起树,大家都不陌生,毕竟是日常生活中常见的事物。但是今天的主角不是树木,我们来聊聊数据结构中的树、二叉树和二叉查找树,以及它们的基本操作!
一、树与二叉树
树是一种数据结构,它是由n(n>=1)个有限结点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
树是由结点和边组成的,不存在环的一种数据结构。通过下图,我们就可以更直观的认识树的结构。

树满足递归定义的特性。也就是说,如果一个数据结构是树结构,那么剔除掉根结点后,得到的若干个子结构也是树,通常称作子树。
在一棵树中,根据结点之间层次关系的不同,对结点的称呼也有所不同。我们来看下面这棵树,如下图所示:

不同结点的关系与称呼如下:
A 结点是 B 结点和 C 结点的上级,则 A 就是 B 和 C 的父结点,B 和 C 是 A 的子结点。
B 和 C 同时是 A 的“孩子”,则可以称 B 和 C 互为兄弟结点。
A 没有父结点,则可以称 A 为根结点。
G、H、I、F 结点都没有子结点,则称 G、H、I、F 为叶子结点。
当有了一棵树之后,还需要用深度、层来描述这棵树中结点的位置。如上图所示,结点的层次从根结点算起:
根为第一层,比如:A
根的“孩子”为第二层,比如B、C
根的“孩子”的“孩子”为第三层,比如D、E、F
依此类推,第四层(最后一层)就是:G、H、I
树中结点的最大层次数,就是这棵树的树深(称为深度,也称为高度)因此这是一棵深度为 4 的树。
在树的大家族中,有一种被高频使用的特殊树,它就是二叉树。在二叉树中,每个结点最多有两个分支,即每个结点最多有两个子结点,分别称作左子结点和右子结点。
在二叉树中,有两个最为特殊的类型,如下图所示:

满二叉树,定义为除了叶子结点外,所有结点都有 2 个子结点。
完全二叉树,定义为除了最后一层以外,其他层的结点个数都达到最大,并且最后一层的叶子结点都靠左排列。
你可能会困惑,完全二叉树看上去并不完全,但为什么这样称呼它呢?这其实和二叉树的存储有关系。存储二叉树有两种办法,一种是基于指针的链式存储法,另一种是基于数组的顺序存储法。
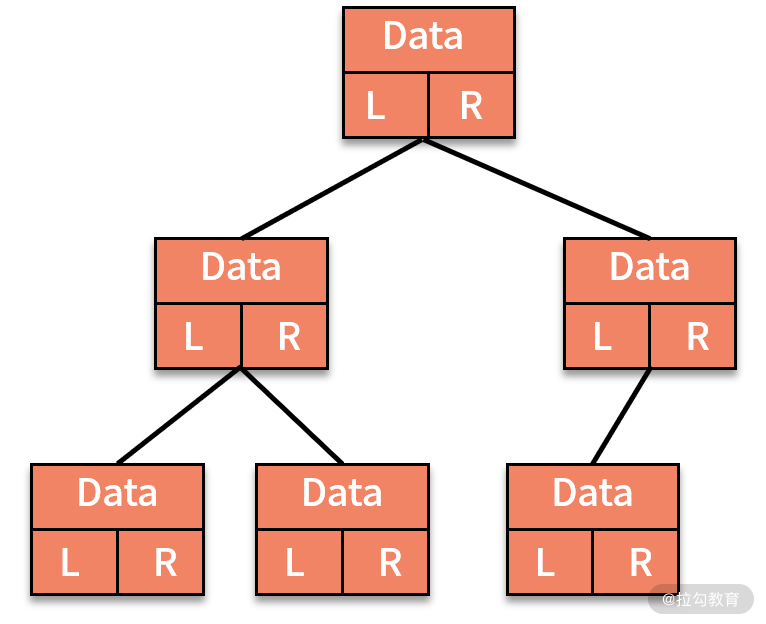
链式存储法,也就是像链表一样,每个结点有三个字段,一个存储数据,另外两个分别存放指向左右子结点的指针,如下图所示:
顺序存储法,就是按照规律把结点存放在数组里,如下图所示,为了方便计算,我们会约定把根结点放在下标为 1 的位置。随后,B 结点存放在下标为 2 的位置,C 结点存放在下标为 3 的位置,依次类推。
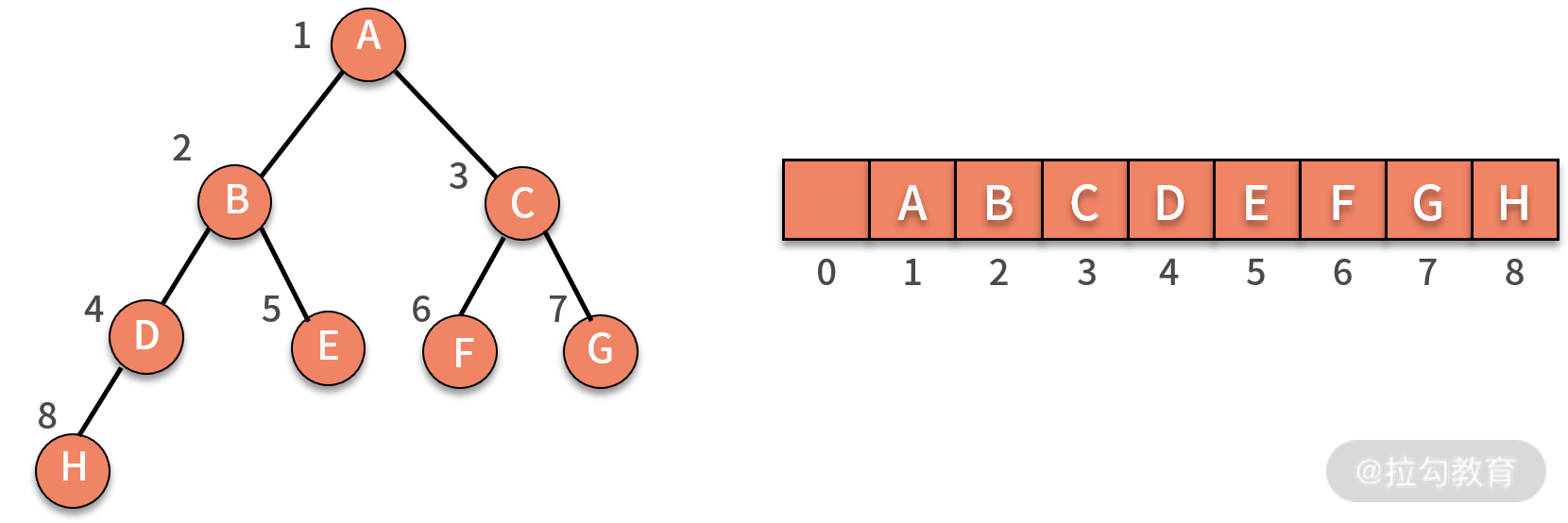
之所以称为完全二叉树,是从存储空间利用效率的视角来看的。对于一棵完全二叉树而言,仅仅浪费了下标为 0 的存储位置。而如果是一棵非完全二叉树,则会浪费大量的存储空间。
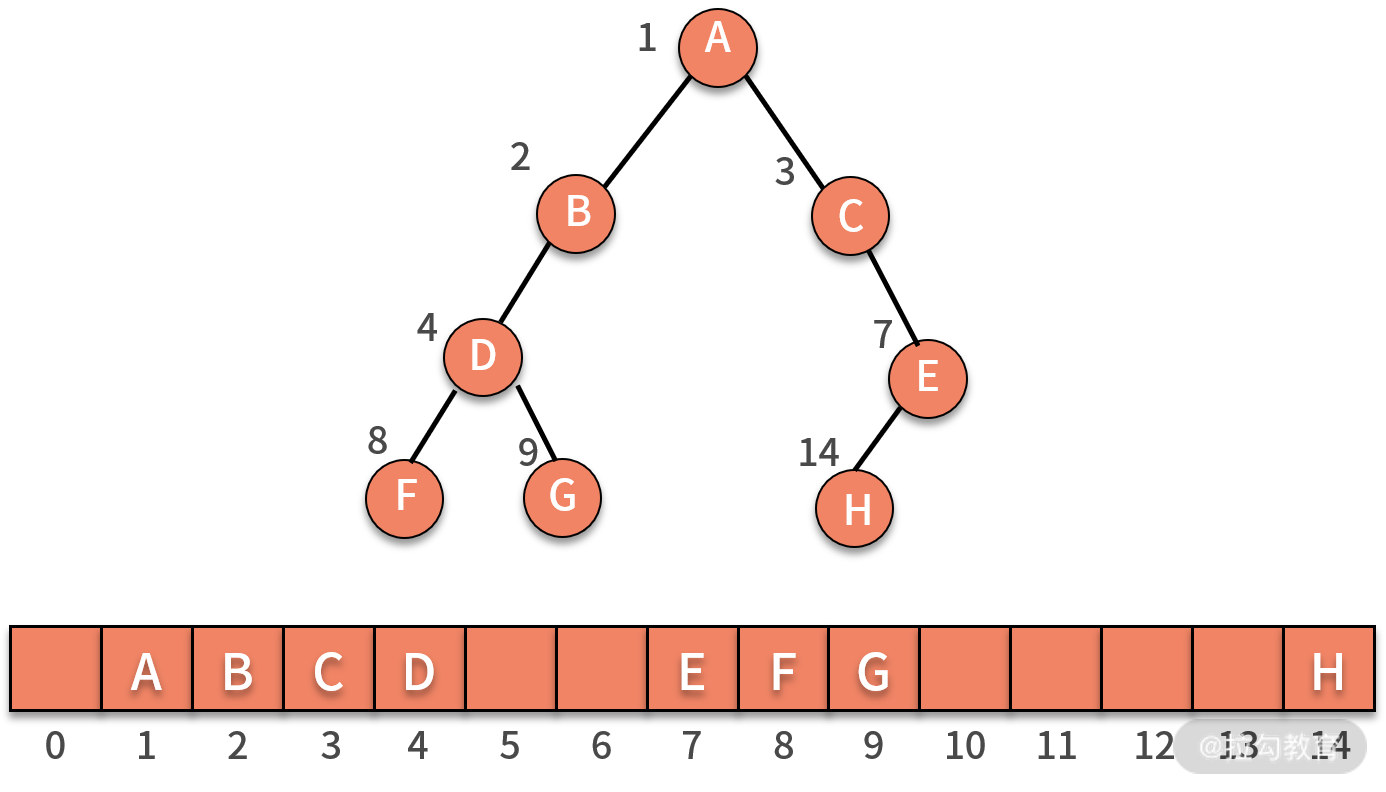
如下图所示的非完全二叉树,它既需要保留出 5 和 6 的位置。同时,还需要保留 5 的两个子结点 10 和 11 的位置,以及 6 的两个子结点 12 和 13 的位置。这样的二叉树,没有完全利用好数组的存储空间。
接下来,我们以二叉树为例介绍树的操作,其他类型的树的操作与二叉树基本相似。
可以发现,我们以前学到的数据结构都是“一对一”的关系,即前面的数据只跟下面的一个数据产生了连接关系,例如链表、栈、队列等。而树结构则是“一对多”的关系,即前面的父结点,跟下面若干个子结点产生了连接关系。
在“一对一”的结构中,查找具有某个数值,可以直接按顺序遍历每一条数据。可是,树是“一对多”的关系,那该按什么顺序遍历呢?
其实,遍历一棵树,有非常经典的三种方法,分别是前序遍历、中序遍历、后序遍历。这里的序指的是父结点的遍历顺序,前序就是先遍历父结点,中序就是中间遍历父结点,后序就是最后遍历父结点。
不管哪种遍历,都是通过递归调用完成的。如下图所示:
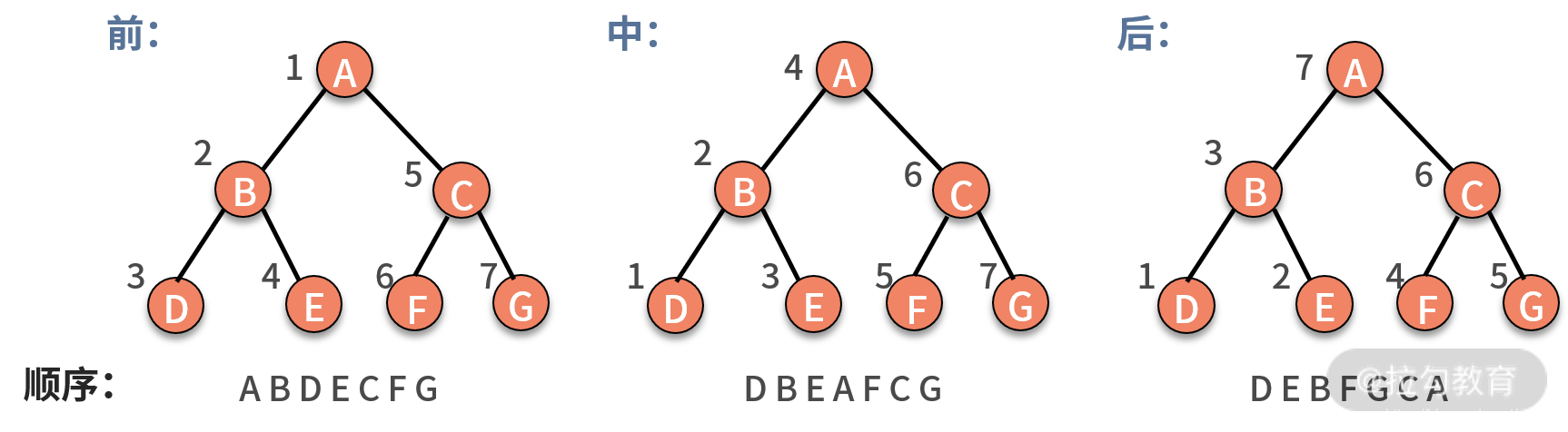
前序遍历,对树中的任意结点来说,先打印这个结点,然后前序遍历它的左子树,最后前序遍历它的右子树。
中序遍历,对树中的任意结点来说,先中序遍历它的左子树,然后打印这个结点,最后中序遍历它的右子树。
后序遍历,对树中的任意结点来说,先后序遍历它的左子树,然后后序遍历它的右子树,最后打印它本身。
对于没有任何特殊性质的二叉树而言,抛开遍历的时间复杂度以外,真正执行增加和删除操作的时间复杂度是 O(1)。树数据的查找操作和链表一样,都需要遍历每一个数据去判断,所以时间复杂度是 O(n)。
但当二叉树具备一些特性的时候(比如二叉查找树),则可以利用这些特性实现时间复杂度的降低。
二叉查找树(也称作二叉搜索树)具备以下几个的特性:
在二叉查找树中的任意一个结点,其左子树中的每个结点的值,都要小于这个结点的值;其右子树中每个结点的值,都要大于这个结点的值。
在二叉查找树中,会尽可能规避两个结点数值相等的情况。
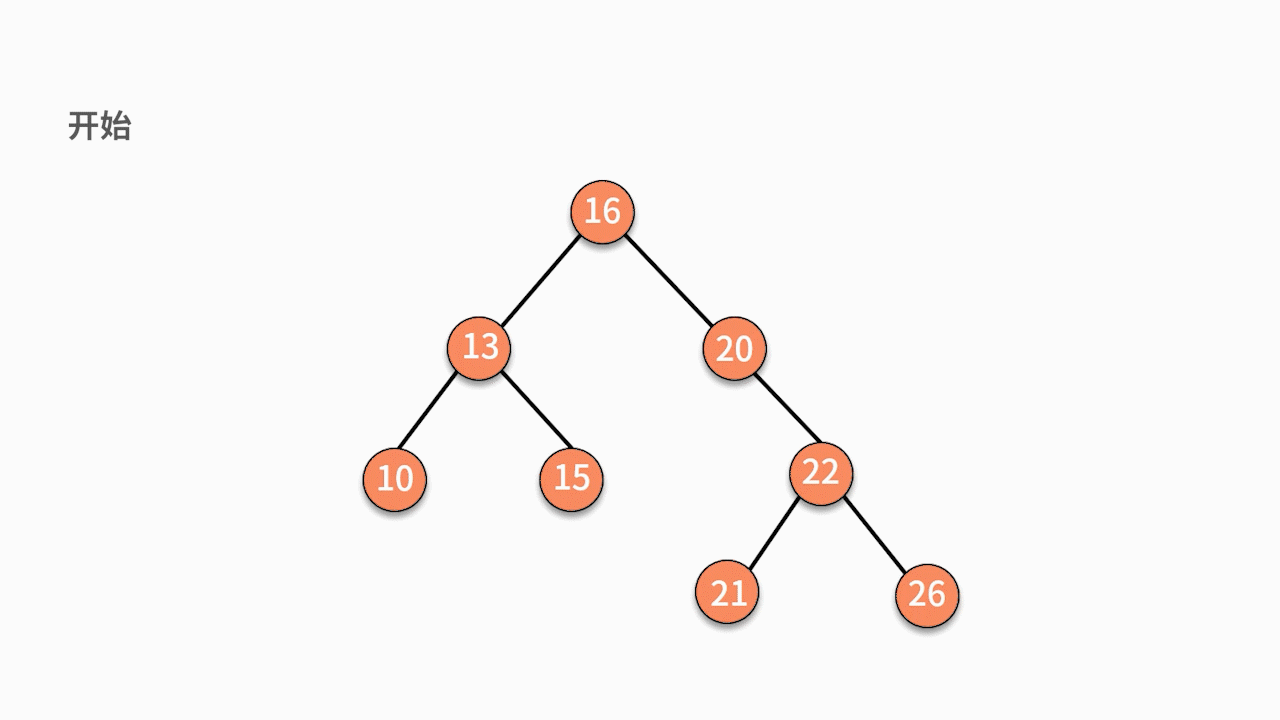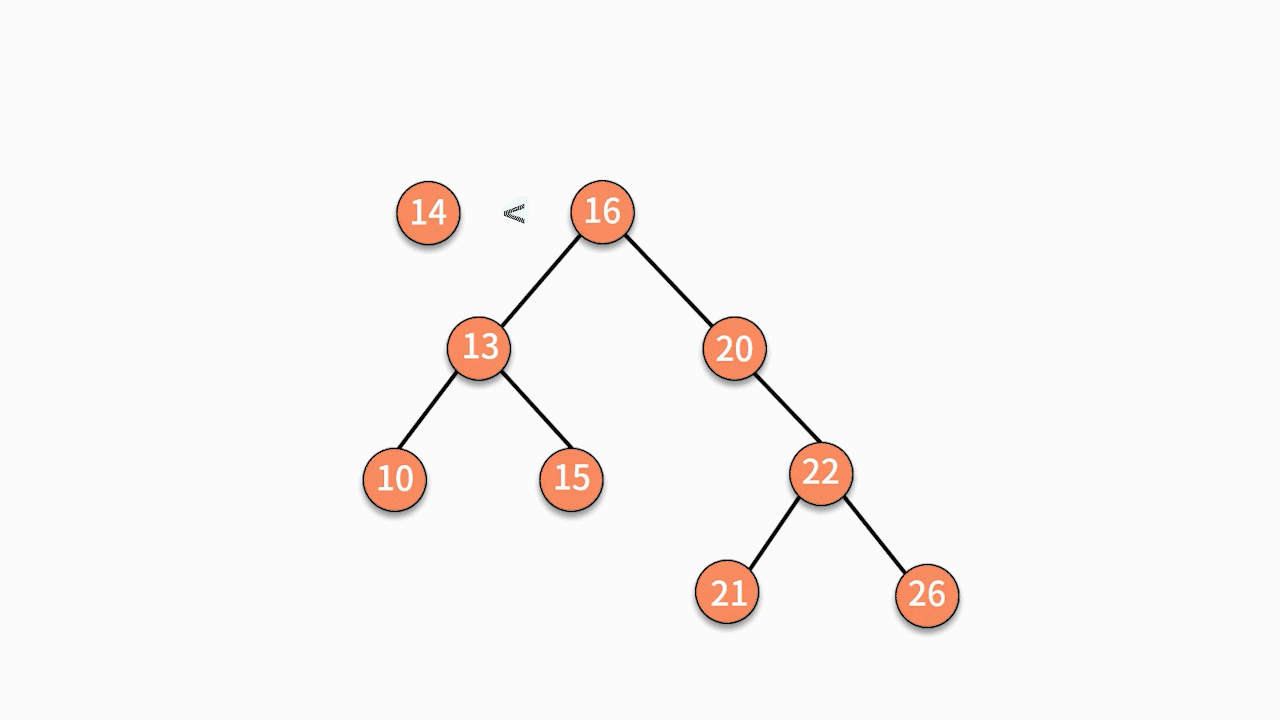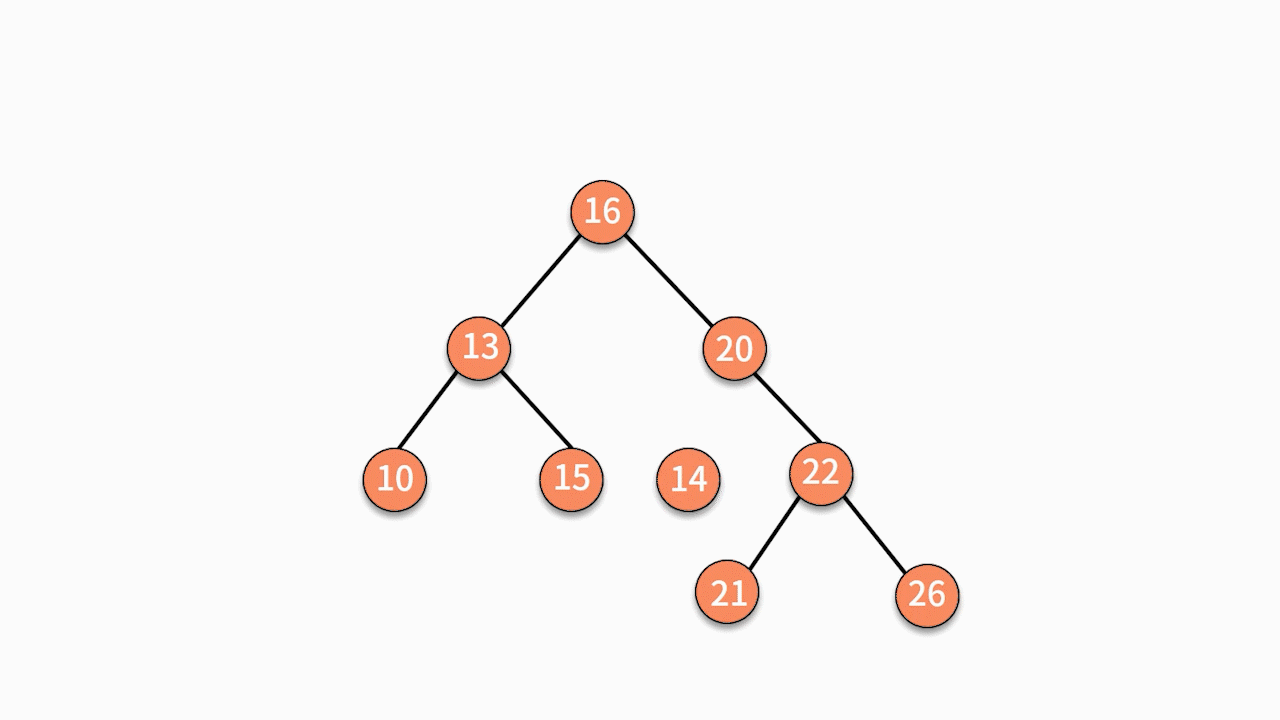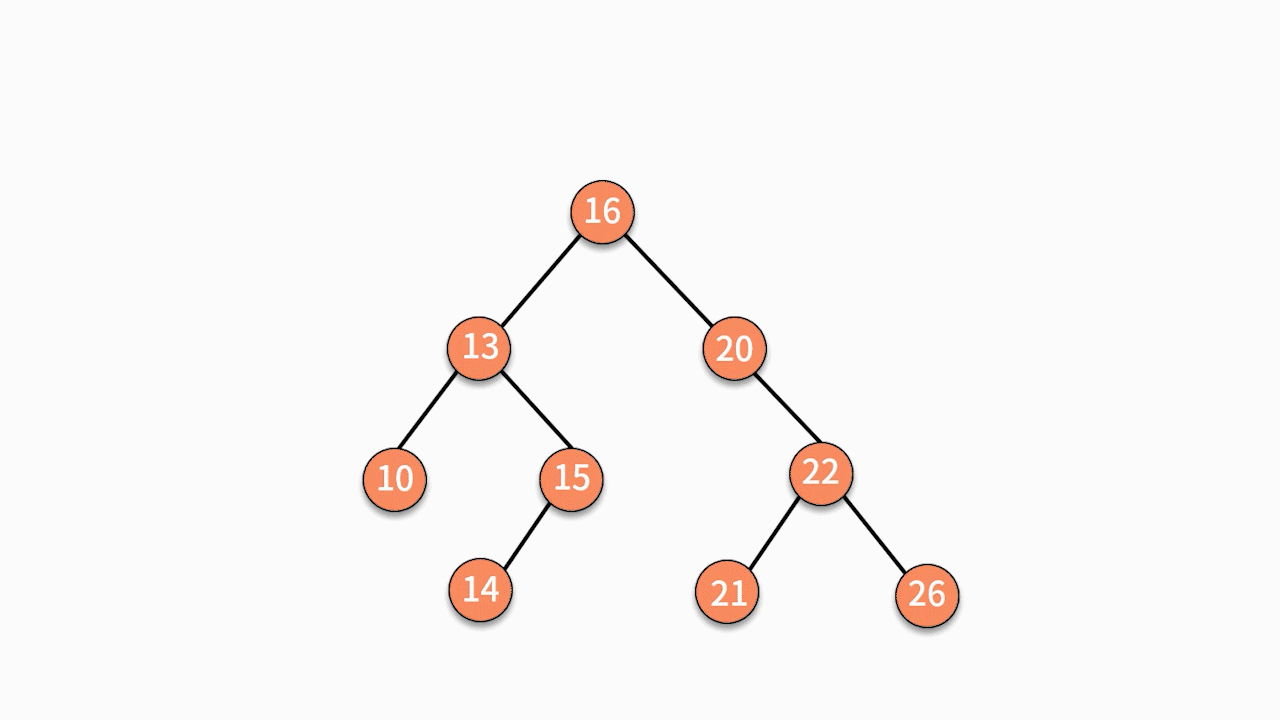
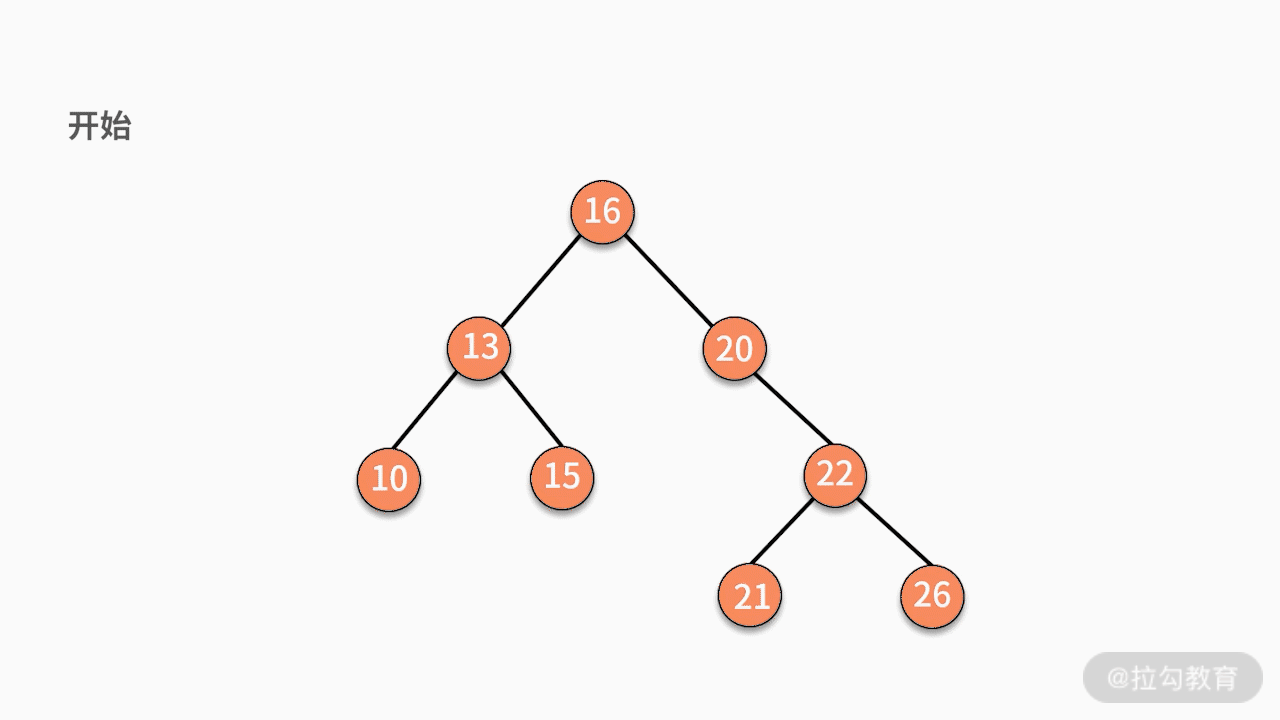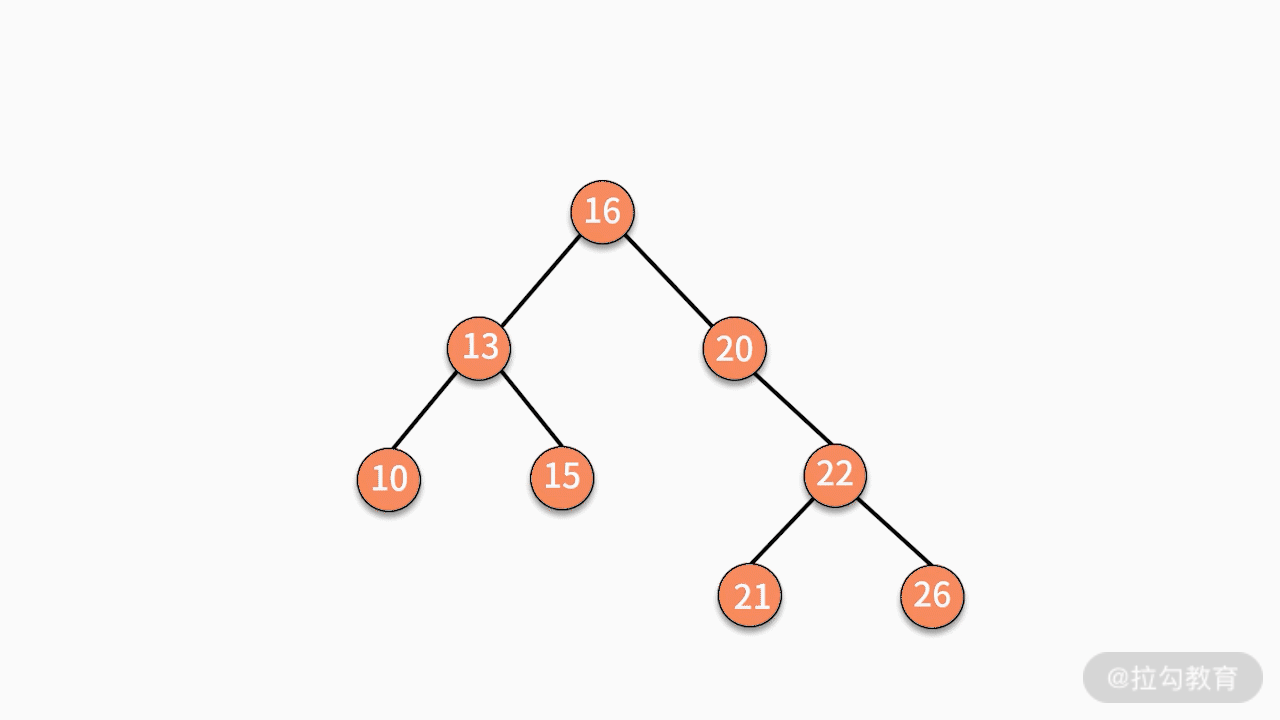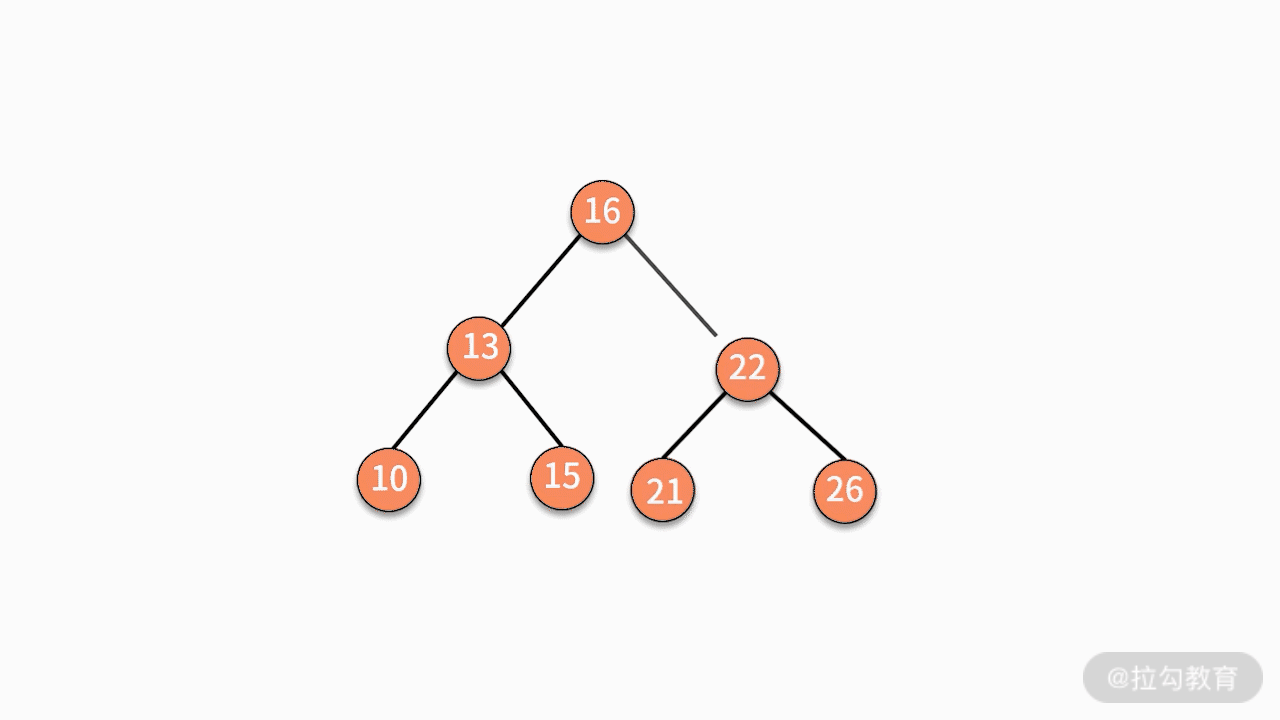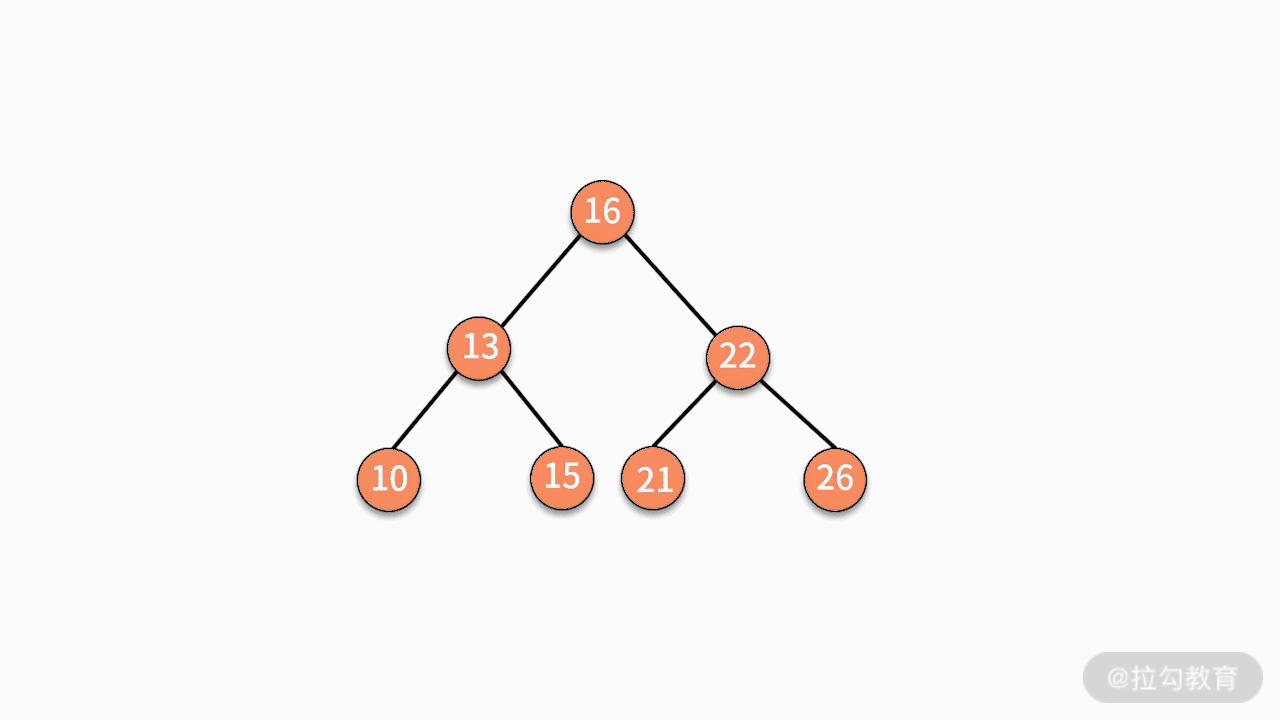
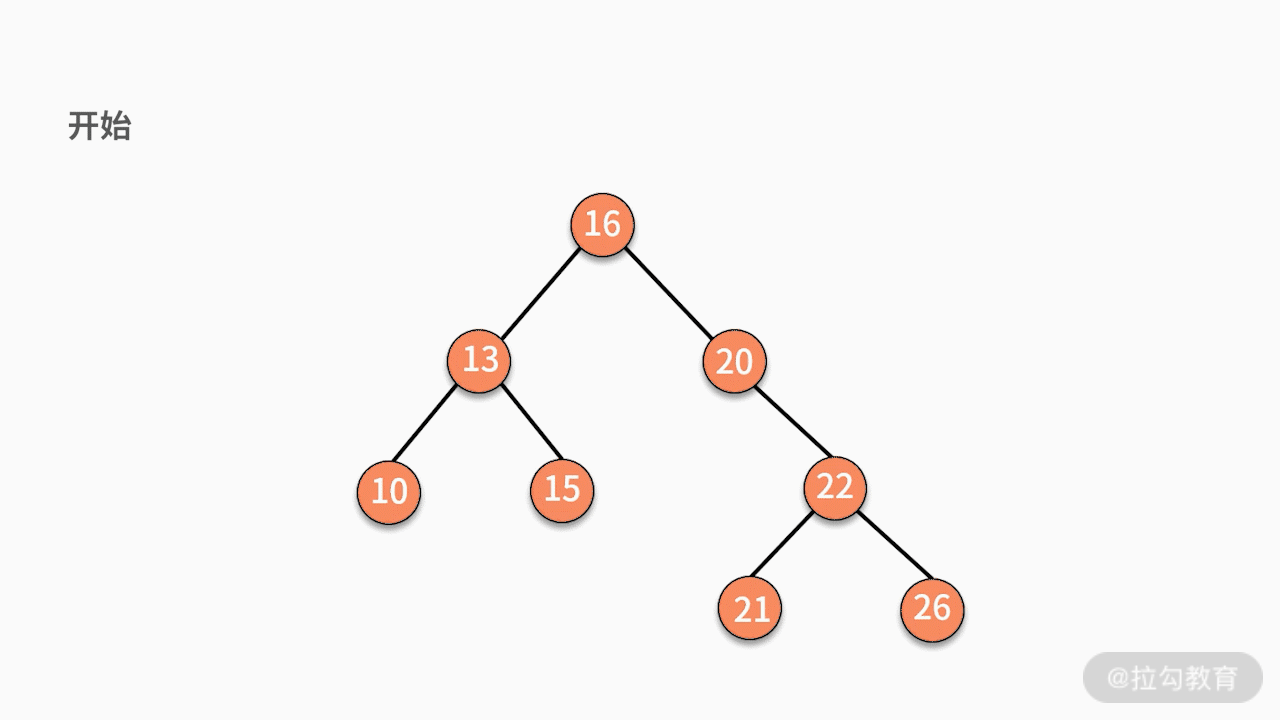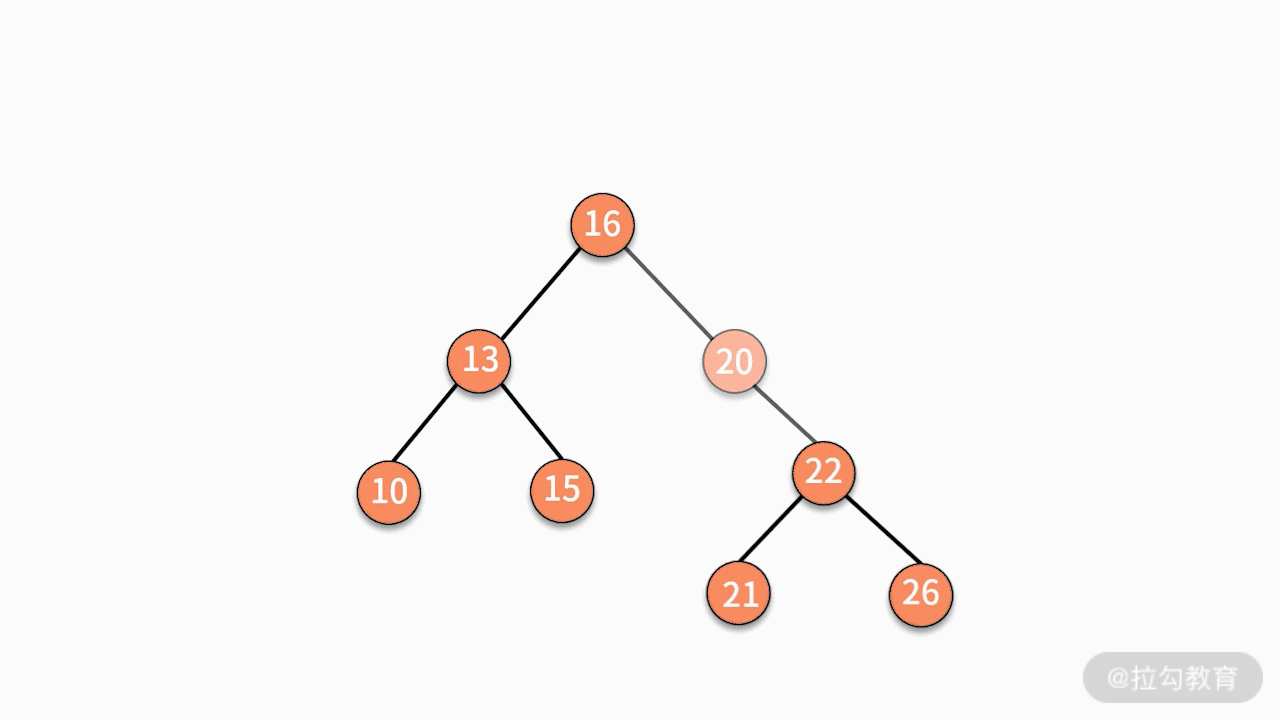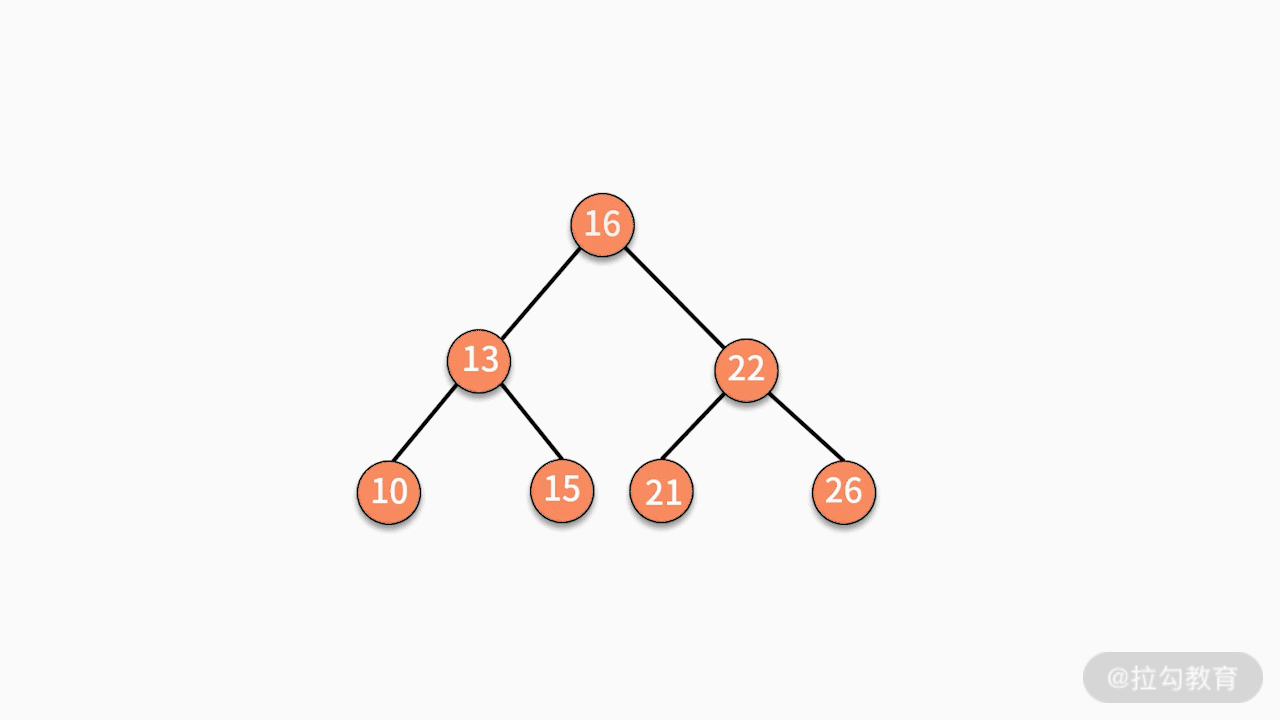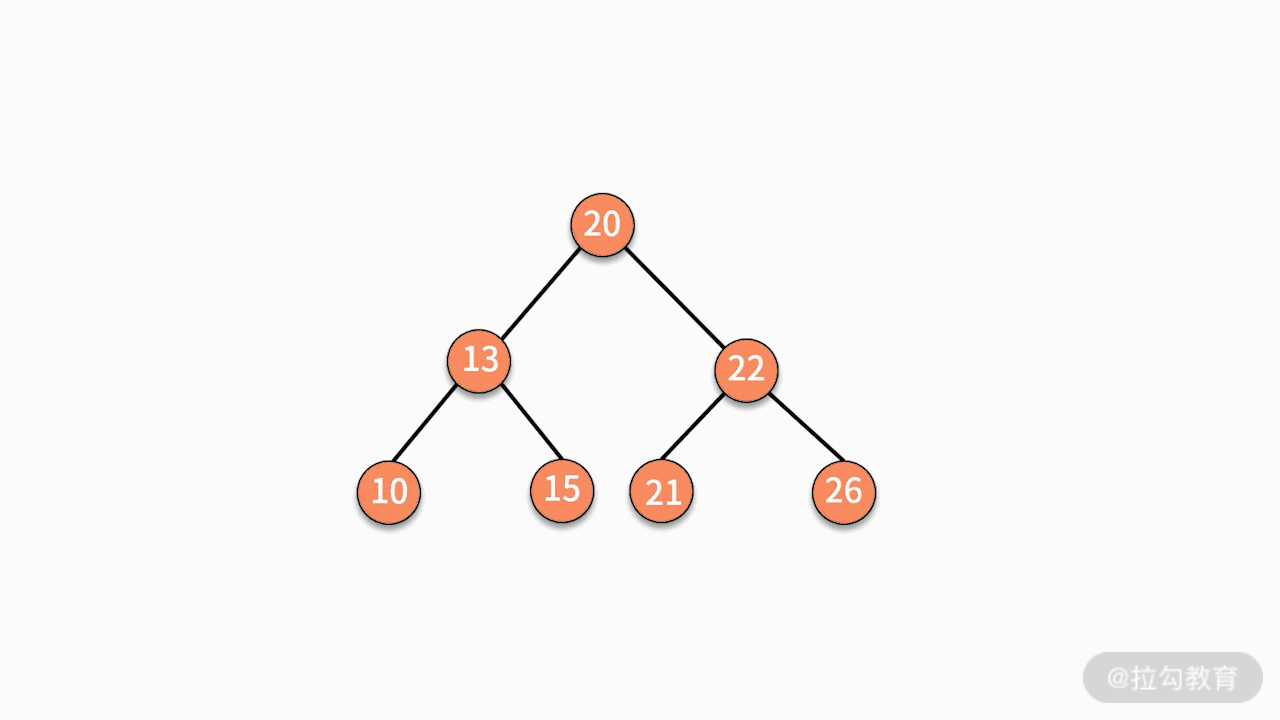
对二叉查找树进行中序遍历,就可以输出一个从小到大的有序数据队列。如下图所示,中序遍历的结果就是 10、13、15、16、20、21、22、26。
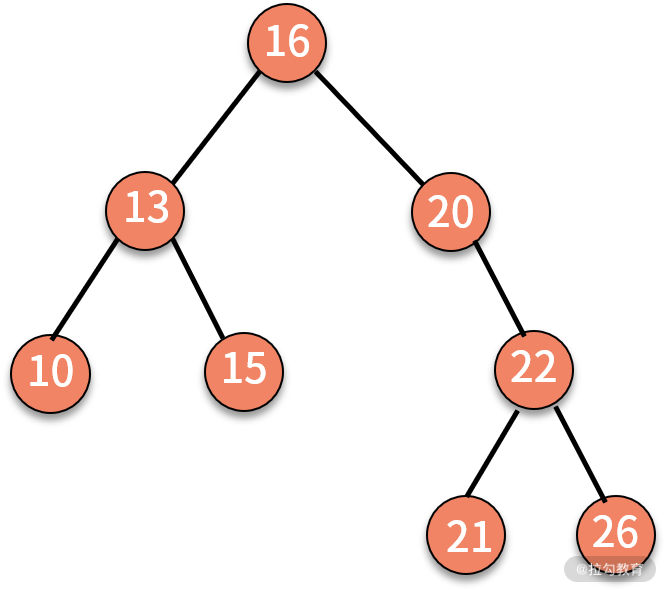
所以二叉查找树可以简单的认为是,是一个按规则排好序的二叉树。
在利用二叉查找树执行查找操作时,我们可以进行以下判断:
首先判断根结点是否等于要查找的数据,如果是就返回。
如果根结点大于要查找的数据,就在左子树中递归执行查找动作,直到叶子结点。
如果根结点小于要查找的数据,就在右子树中递归执行查找动作,直到叶子结点。
这样的“二分查找”所消耗的时间复杂度就可以降低为 O(logn)。关于二分查找,后面会在算法部分文章讲到。
在二叉查找树执行插入操作也很简单。从根结点开始,如果要插入的数据比根结点的数据大,且根结点的右子结点不为空,则在根结点的右子树中继续尝试执行插入操作。直到找到为空的子结点执行插入动作。
如下图所示,如果要插入数据 X 的值为 14,则需要判断 X 与根结点的大小关系:
由于 14 小于 16,则聚焦在其左子树,继续判断 X 与 13 的关系。
由于 14 大于 13,则聚焦在其右子树,继续判断 X 与15 的关系。
由于 14 小于 15,则聚焦在其左子树。
因为此时左子树为空,则直接通过指针建立 15 结点的左指针指向结点 X 的关系,就完成了插入动作。
二叉查找树插入数据的时间复杂度是 O(logn)。但这并不意味着它比普通二叉树要复杂。原因在于这里的时间复杂度更多是消耗在了遍历数据去找到查找位置上,真正执行插入动作的时间复杂度仍然是 O(1)。
二叉查找树的删除操作会比较复杂,这是因为删除完某个结点后的树,仍然要满足二叉查找树的性质。我们分为下面三种情况讨论。
(1)如果要删除的结点是某个叶子结点,则直接删除,将其父结点指针指向 null 即可。
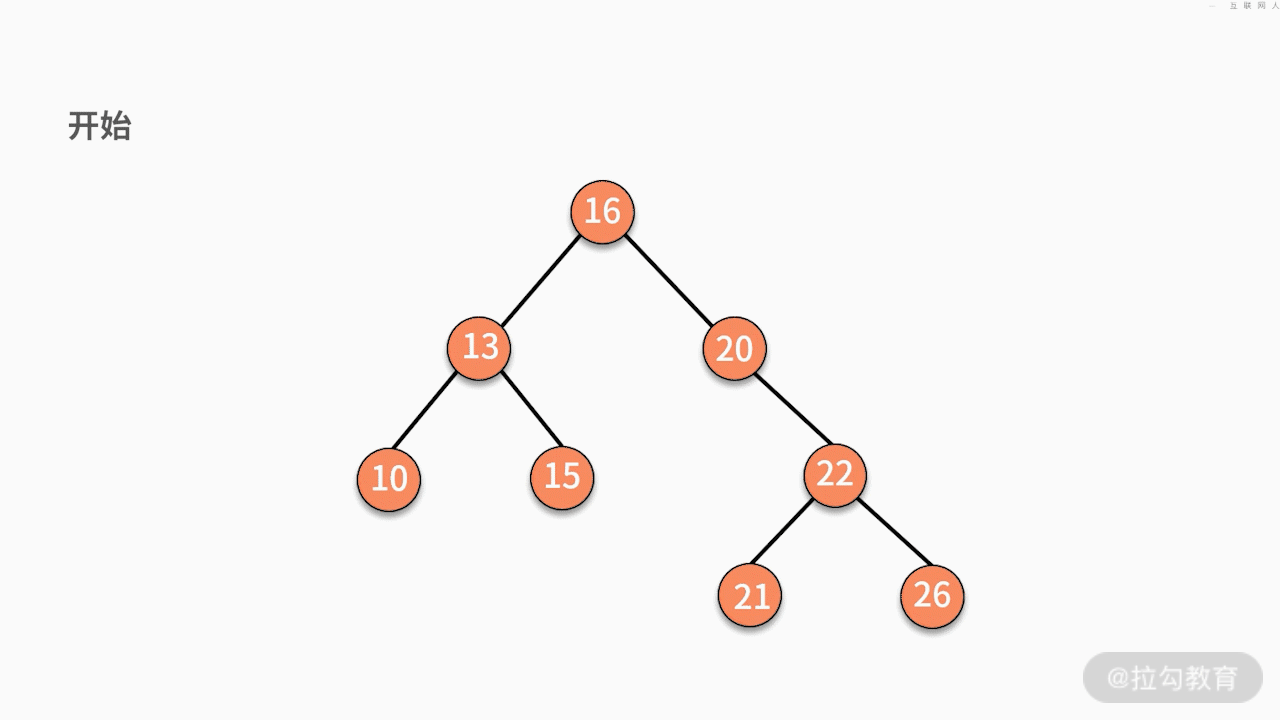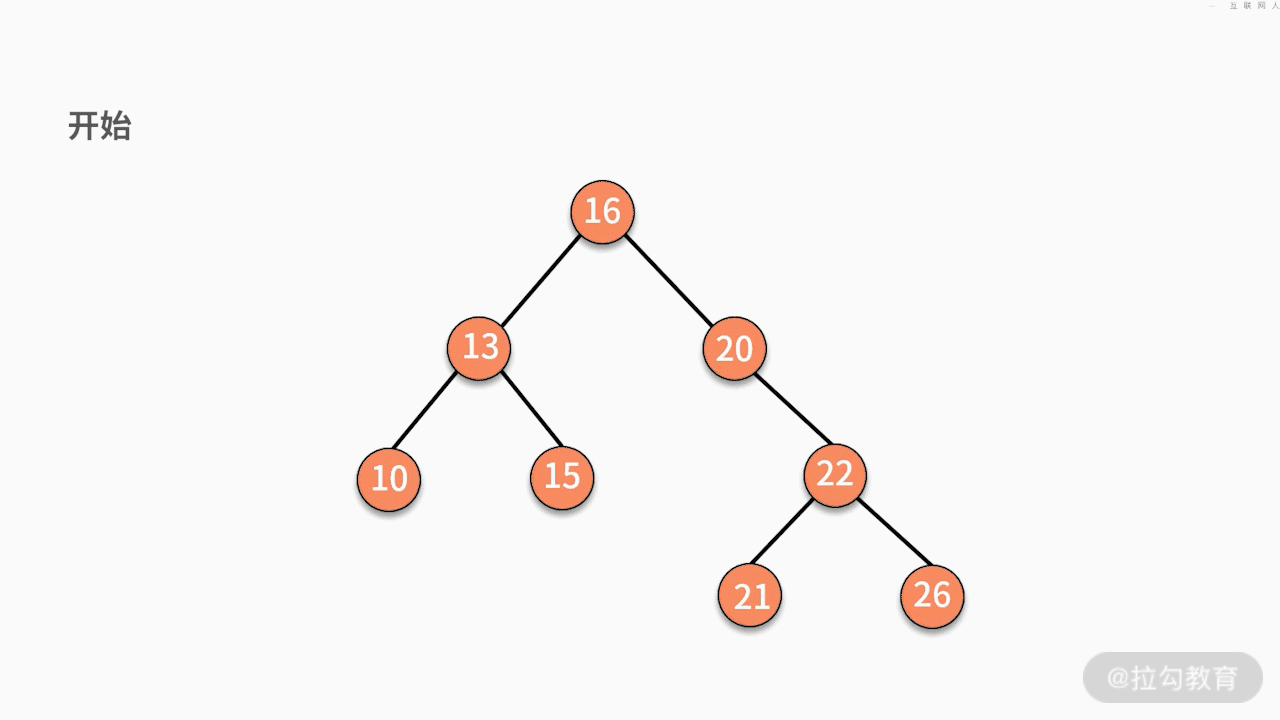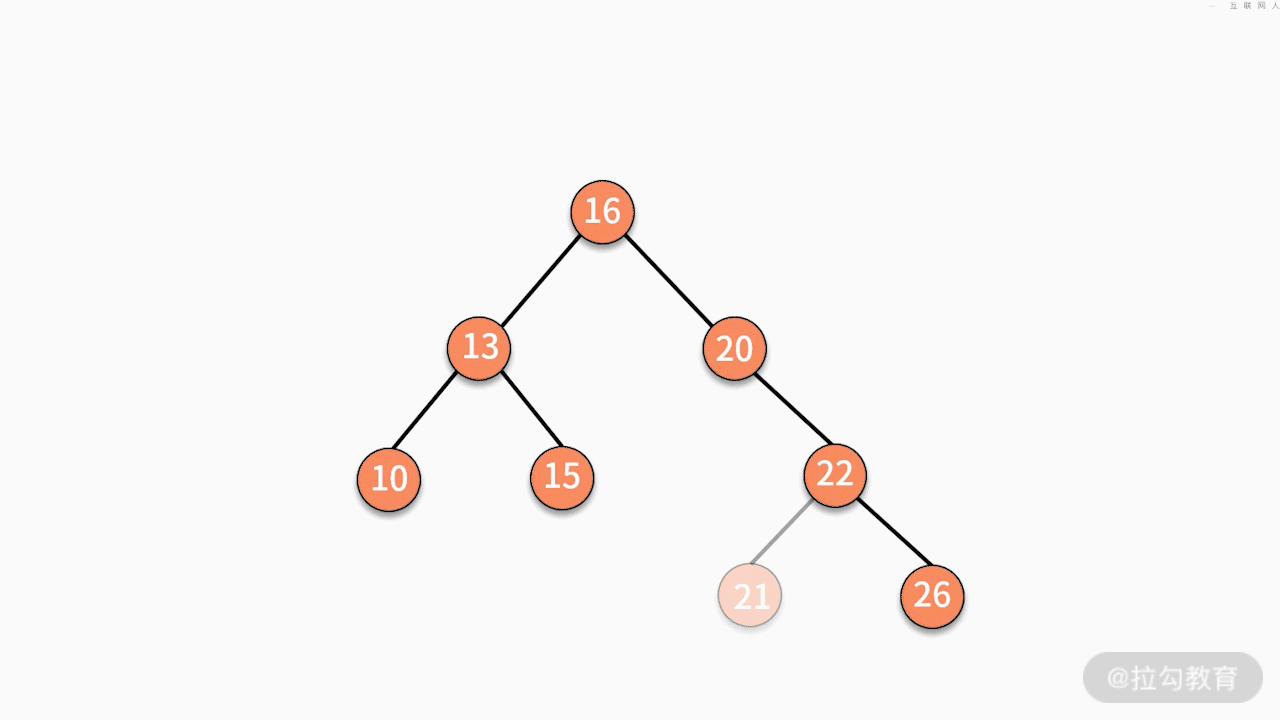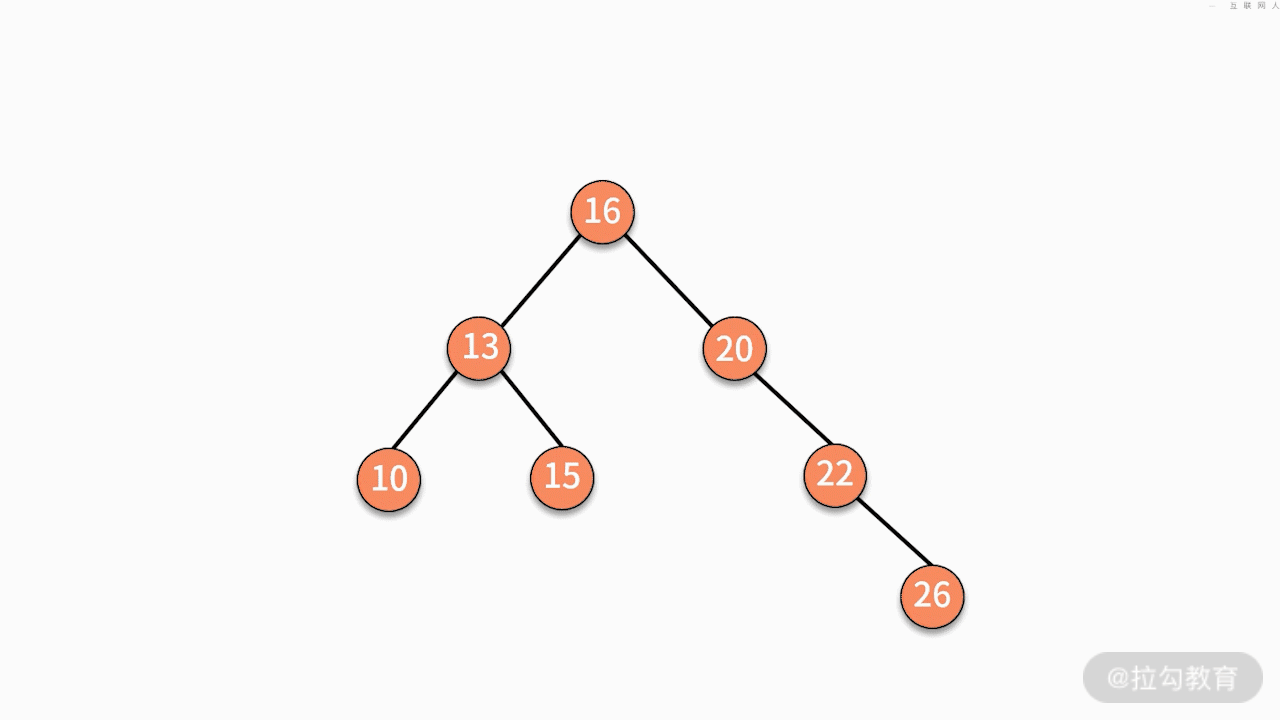
(2)如果要删除的结点只有一个子结点,只需要将其父结点指向的子结点的指针换成其子结点的指针即可。
 (3)如果要删除的结点有两个子结点,则有两种可行的操作方式。
(3)如果要删除的结点有两个子结点,则有两种可行的操作方式。
第一种,找到这个结点的左子树中最大的结点,替换要删除的结点。

第二种,找到这个结点的右子树中最小的结点,替换要删除的结点。
上述内容就是什么是树、二叉树以及二叉查找树,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





