这篇文章主要讲解了“如何理解编辑器思维与系统设计思想”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何理解编辑器思维与系统设计思想”吧!
与人类社会的历史相比,计算机的历史非常短暂,上世纪五、六十年代都能称为远古时期了。但计算机的历史又很神奇,早期的思想往往都很超前、很先进。比如EJB技术虽然是1998年提出的,但它的设计很超前,诸如微服务等后面出现的技术都或多或少借鉴了它的思想。通过了解计算机技术的发展历史,往往能从中找到很多有创意的想法,能帮我们解决当下的问题。所以,今天想来掰扯一下Emacs和Vim这两款经久不衰的老古董软件的历史八卦,看看有没有值得借鉴的地方。
Vim族谱
首先从Vim编辑器的起源说起,下图Vim的族谱:
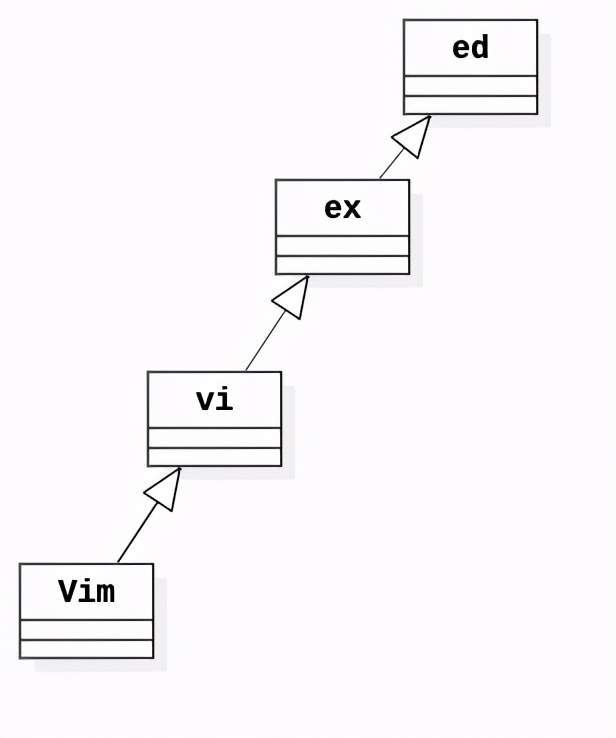
Vim的前身是ed编辑器:
ed是UNIX系统上最古老的程序之一,从第一版本开始就入驻了,作者是Ken Thompson(UNIX作者之一)。它提供了面向行(Line)的基本编辑命令。
ex是ed的超集,是Bill Joy(Sun公司创始人之一)在开发BSD时增强了ed,于是取名叫ex。但ex仍然是面向行的编辑器。
Bill Joy后续又为ex提供了可视化界面(Viusal Interface),提供全屏编辑能力,因此命名为vi。
为了将vi移植到Amiga机器,Bram Moolenaar开发了Vi IMitation(Vi仿制品)。随着功能的不断增加,名字也升级为Vi IMproved(Vi改良版),即Vim。
ed编辑器
ed与VSCode、Sublime Text等现代编辑器有很大不同,如前文所说,它是一款行编辑器(此处已帮大家划重点),即编辑的对象是一整行文本。
ed分命令模式与编辑模式。启动ed后,默认进入命令模式,等待用户输入一条条命令。ed通过执行这些命令,最终达到编辑文件的目的。使用Mac电脑的同学可以试试在终端里执行ed。ed命令的格式是[寻址][命令]:
寻址:选中待操作的目标行。ed提供了三种寻址方法:行号:从1开始的整数;$代表最后一行。模式:选中与正则表达式匹配的行。默认从当前行开始,选中第一个匹配的行。如/re/。添加前缀g,则做全局匹配。如g/re/范围:由两个地址组成的寻址范围,[地址],[地址]。如/BEGIN/,/END/
命令:用单个字符表示。以下是最常用的命令:p:展示,输出目标行。i:插入,将内容插入到目标行的上一行。a:追加,将内容追加到目标行的下一行。c:更改,替换目标行的内容。d:删除,删除目标行。s:替换,用正则表达式替换匹配行内容。
其中i、a、c命令会使ed从命令模式进入编辑模式,在编辑模式中输入一行.则返回命令模式。以下是ed编辑的几个示例:
删除所有空行:g/^$/d。用前缀g全局搜索正则表达式/^$/,并执行删除命令。
输出所有包含“re”的行:g/re/p。同样全局搜索正则表达式/re/,并执行展示命令。因为该功能实在太常用了,所以还特地开发了一个命令“grep”。
编辑器思维
如前文所说,ed编辑器与现代编辑器很不同,它其实是一个编辑命令解释器;但ed编辑器又与现代编辑器很相同,所有编辑器的本质都是在不断执行“寻址”与“命令”,不同类型编辑器之间的差异只是编辑的对象不同:
ed是文本行编辑器:编辑的对象是文本行。
Microsoft Word是文档编辑器:编辑的对象是章节、段落、词句等文档元素。
Sketch是图形编辑器:编辑的对象是点、线、面等图形元素。
IntelliJ IDEA包含Java代码编辑器:编辑的对象是类、方法、语句等Java语义元素。
jQuery是DOM编辑器:编辑的对象是DOM元素。先用CSS Selector寻址,选中要处理的DOM元素;再用连缀表达式执行一系列编辑动作。
……
由此可见,编辑器思维无处不在,只要符合“寻址+命令”模式都可称作编辑器,因此万物皆可编辑!编辑器思维或编辑的本质,用开发者更熟悉的话术来讲就是CRUD:
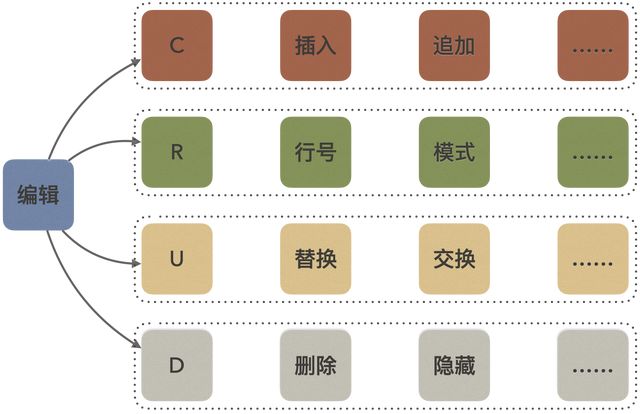
若以后有人质疑开发同学只是在做简单的增删改查,请勇敢地告诉他们:其实我是在做一个垂直领域的编辑器!

若意识到自己在做的其实是一个编辑器,就能利用编辑器思维快速发现系统能力的短板。以商品管理系统为例,若商品管理只提供通过ID查询商品的功能,就犹如ed编辑器只支持用行号来寻址一样,使用就非常不方便,可以借鉴ed通过正则表达式的模式匹配寻址能力,提供通过商品名称等信息来匹配商品、甚至通过商品照片来匹配相似商品的能力;类似的,创建商品能力也可以借鉴编辑器复制粘贴的能力,提供用相似商品快速新建商品的能力,甚至还可以提供从其他平台搬家的能力。
ed的族谱
前文只介绍了ed交互式编辑的功能,其实ed还支持脚本化编辑,就是将输入到终端的编辑命令保存成一个脚本文件,供后续反复运行。好处是可以用相同的编辑命令批量编辑任意多个文件。
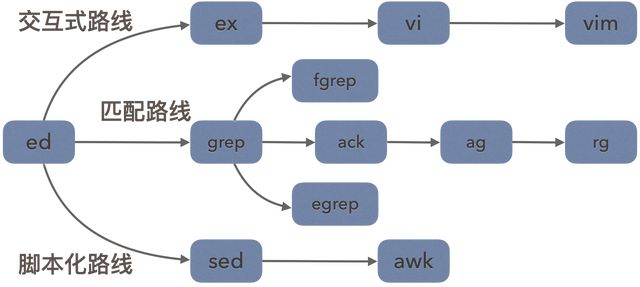
上图是ed编辑器的族谱,后续的衍生程序都是选择并增量了ed的部分能力。比如:
ex、vi、vim这条分支选择了交互式路线。
grep、fgrep、egrep选择了模式匹配路线。
sed、awk选择了脚本化路线。
从Vim阵营叛逃
我曾经是一名Vim重度用户,因为在大学利用的操作系统是Debian Linux,无论是写C代码还是Java代码,都是在Vim里一把梭。好处是闭卷笔试时可以直接默写,而用Eclipse的同学基本是记不住JDK API的全名。:-p
毕业后进了一家外企,不得不开始使用Windows XP系统,某天在记事本里写东西,发现自己会经常无意识地按一下Esc键。用过Vim的同学肯定知道,这是在切换模式。这我意识到:Vim这种多模式的设计非常反人类。Vim启动时默认进入的不是编辑模式,当新手用户什么都还没学会时,他没办法把Vim当成普通的记事本来用。曾有一则关于Vim的笑话,说如何获得一串随机码,答案是让Vim新手尝试退出Vim。
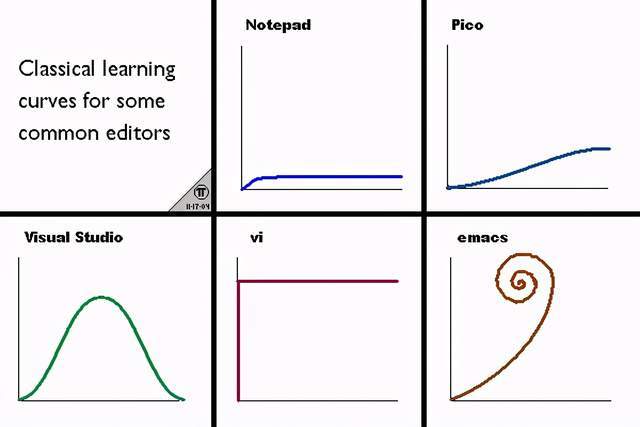
这种方式不符合我的口味,我尝试去寻找新的编辑器——当什么都没学会的时候,可以当成最普通的记事本来用;当需要高级功能时,再通过快捷键等方式呼唤出来。结果发现Emacs恰好符合这个要求,所以从2010年开始我就从Vim阵营叛逃到了Emacs阵营。我认为这个使用方式的差异是Vim与Emacs最本质的区别:Vim会强迫用户从一开始就按照它的规则来做事情;而Emacs则相对不需要过多前置知识。网络上曾流传过一张编辑器的学习曲线,还蛮贴切的:
Emacs的起源
Vim的前身ed源自UNIX系统,而Emacs的前身TECO源自UNIX系统的前身——Multics系统。
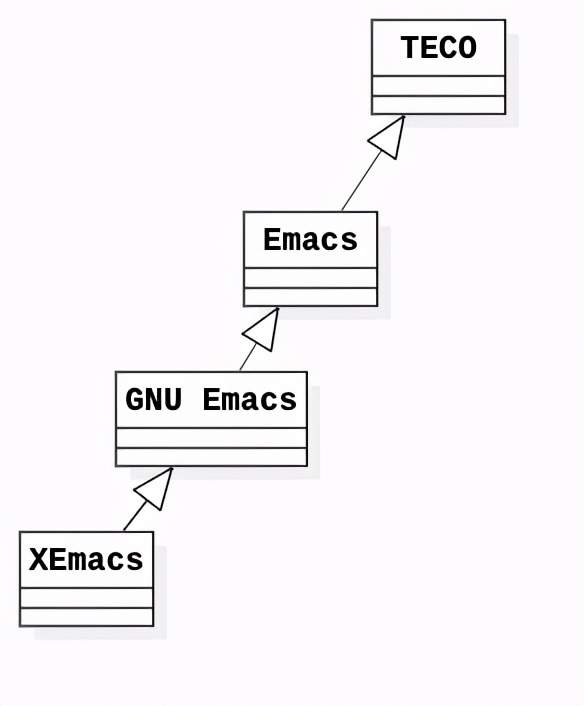
上世纪70年代,GNU的创始人Richard Stallman在MIT的AI实验室打工时,发明了TECO编辑器,运行在PDP-10机器上。与ed类似,TECO也是命令解释器——接收并执行编辑命令——并且也采用单个字符作为命令名称,比如“l”是移动一行,“5l”是移动5行。MIT那群大佬们想用TECO命令完成一些复杂的编辑工作,于是加入了分支判断、循环等功能;但由于先天不足,TECO最开始设计的时候,没有把命令设计成一套完备的编程语言,导致后续改进也很困难,比如命令名称只能是单个字符,很快字符就不够用了。
所谓基础不牢地动山摇,大伙儿都认为需要用一套严谨完备的编程语言替代TECO的半成品脚本语言。于是有一位叫Bernie的教授在Multics系统上用MacLisp重写了TECO,并命名为Emacs,还为它写了详细的手册,教大家如何扩展这个编辑器来满足自己的工作需要。结果,这个版本的Emacs取得巨大成功,连Bernie的秘书——一个号称自己不懂编程的人——都在照着手册,有模有样地写Lisp代码来扩展编辑器功能。这件事儿在实验室引起轰动后,Bernie为此做了一个总结:如果有一个应用——一个能帮你做点有用事情的程序——内嵌了Lisp,并且能通过Lisp程序扩充它的功能,对于学习编程而言,这是一种非常不错的入门方式!那些自认为不会编程的人,这种方式会给他们编写小但有用的程序的机会,让他们在实践中不断成长,直到他们发现自己就是在编程。
Stallman他们觉得这个想法简直屌炸天!同时他们想把这个好用的Emacs版本迁移到Multics系统之外的其他系统,但当时只有Multics系统上有完备的Lisp环境——既有编译器又有解释器——诸如UNIX等系统上都没有。
这里还有一个小插曲,Java之父James Gosling当年还写了一个能跨平台的Emacs版本,叫Gosmacs。本来社区想来一起完善这个版本,结果Gosling把它卖给了一家商业公司,同时它底层的Lisp不是一个真实完备的Lisp,而是一个叫Mocklisp的假Lisp,只是语法上和Lisp长得像而已。所以社区最终放弃了这个选项,决定从头开始做一个全新的Emacs,也就是GNU Emacs。Stallman先用C语言开发一个跨平台的Lisp解释器——Emacs Lisp,再用Lisp实现编辑逻辑。这样既能在所有平台上用统一的Lisp方言来写Emacs扩展,又能兼顾性能。
GNU Emacs有一段时间发展比较之后,因为Stallman自己一个人忙不过来,所以社区又创建了一个分支叫XEmacs,增强了字体抗锯齿等功能。后来GNU Emacs的维护又变得积极了,把很多XEmacs的特性合并回GNU Emacs,所以现在XEmacs差不多是废弃状态,主流版本还是GNU Emacs。
编辑器圣战
程序员的世界里充满了鄙视链,有编辑器鄙视链、编程语言鄙视链、操作系统鄙视链……为什么这些圣战永远打不完,到底是像《格列夫游记》里小人国因争论剥鸡蛋先打破大头还是小头而发动了战争,还是真的鱼和熊掌不可兼得?
前文提到,Vim喜欢强迫用户按照它的套路来做事。Vim从ed继承了行编辑器的特性,底层模型是基于“行”的,所以会强行要求所有被编辑的对象适配成它的底层模型。你用Vim写Java代码,你编辑的是文本行;你用Vim写一篇博客,你编辑的是文本行;你用Vim写一篇论文,你编辑的还是文本行;无论你编辑的是类、函数、段落、目录还是任何其他内容,都要先在脑海中翻译成对应的dd、yy等面向行的编辑命令。
Emacs则是允许用户先把Emacs改造成目标对象的个性化编辑器,能认识目标模型,比如段落、章节、目录等。用一句时髦的话讲就是Emacs有行业Know-How。同样的例子:用Emacs写Java代码,你编辑的是类、方法、语句……;你用Emacs写一篇博客,你编辑的是段落、句子……;你用Emacs写一篇论文,你编辑的是目录、章节、正文、索引……。
两种设计方法
造成上述差异的原因是背后两种不同的设计方法,分别称作自顶向下(Top Down)与自底向上(Bottom Up):
方法自顶向下自底向上描述将大任务逐级拆分到颗粒度合适——足够小、又能做些实际的事情——的小任务完善底层编程语言等——让底层基建不断逼近业务领域——来适应任务优点难度较低,目标明确,迭代快速功能完整,适应性强缺点与当前需求耦合过紧,应对变化能力稍弱难度较高,进展较慢
用Vim编辑属于自顶向下方法——将编辑任务持续拆分,最终拆解到面向行的编辑命令;就像Java日常开发,会逐级拆分,最终拆解到JDK的API。用Emacs编辑属于自底向上方法——先完善底层Emacs Lisp语言,逐步抽象出面向业务的领域特定语言,最终用DSL完成编辑任务;例如要编辑Markdown文档,就会提供诸如移动到下一个段落、下一个列表项、表格下一个单元等面向Markdown领域的特定编辑操作。
这两种设计方法的差异并不意味着只是换个顺序写代码,而是系统抽象过程的差异,最终体现在系统扩展性的差异上。我个人把系统的可扩展分成4个等级:
硬编码:系统运行时,数据和行为都已写死,不能变化。
可配置:系统运行时,数据可动态变化,但行为固定不变。
可控制:系统运行时,数据可动态变化,并且由多种预定义的行为可供动态选择。
可编程:系统运行时,数据可动态变化,同时行为可在运行过程中动态新增,即用户可重新系统行为。
自顶向下的极端是硬编码,会过早地把功能限制在当前的需求里,后来的需求只能尽量逼近初始模型;自底向上的极端是可编程,容易过渡设计,为未来不可能变化的场景提供灵活性,甚至会变成一门通用的编程语言。
两种设计方法没有绝对的对错,都有各自适用的场景,单一地采用任何一种方法都会有问题,需要根据实际情况在快速实现和系统扩展性之间做权衡。也正因为没有对错之分,所以编辑器的圣战永远也打不完。
感谢各位的阅读,以上就是“如何理解编辑器思维与系统设计思想”的内容了,经过本文的学习后,相信大家对如何理解编辑器思维与系统设计思想这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/1464083/blog/4809459



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



