今天就跟大家聊聊有关如何使用 K8s 两大利器摆脱运维困境,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
下面几个问题,相信广大 K8s 用户在日常集群运维中都曾经遇到过:
集群中的某个应用被删除了,谁干的?
Apiserver 的负载突然变高,大量访问失败,集群中到底发生了什么?
集群节点 NotReady,是什么原因导致的?
集群的节点发生了自动扩容,是什么触发的?什么时间触发的?
以前,排查这些问题,对客户来说并不容易。生产环境中的 Kubernetes 集群通常是一个相当复杂的系统,底层是各种异构的主机、网络、存储等云基础设施,上层承载着大量的应用负载,中间运行着各种原生(例如:Scheduler、Kubelet)和第三方(例如:各种 Operator)的组件,负责对基础设施和应用进行管理和调度; 此外不同角色的人员频繁地在集群上进行部署应用、添加节点等各种操作。在集群运行的过程中,为了对集群中发生的状况能够尽可能的了如指掌,我们通常会从多个维度对集群进行观测。
日志,作为实现软件可观测性的三大支柱之一,为了解系统运行状况,排查系统故障提供了关键的线索,在运维管理中起着至关重要的作用。Kubernetes 提供了两种原生的日志形式——审计(Audit)和事件(Event),它们分别记录了对于集群资源的访问以及集群中发生的事件信息。从腾讯云容器团队长期运维 K8s 集群的经验来看,审计和事件并不是可有可无的东西,善用它们可以极大的提高集群的可观测性,为运维带来巨大的便利。下面让我们先来简单认识一下它们。
Kubernetes 审计日志是 Kube-apiserver 产生的可配置策略的结构化日志,记录了对 Apiserver 的访问事件。审计日志提供 Metrics 之外的另一种集群观测维度,通过查看、分析审计日志,可以追溯对集群状态的变更;了解集群的运行状况;排查异常;发现集群潜在的安全、性能风险等等。
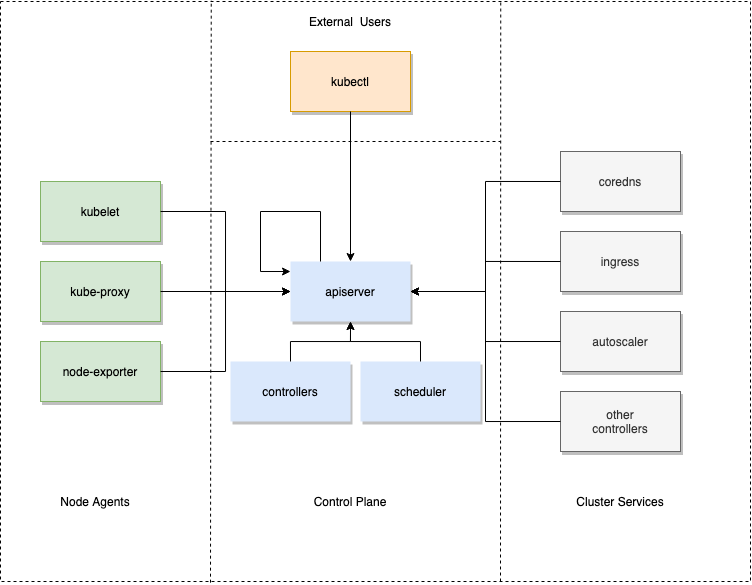
在 Kubernetes 中,所有对集群状态的查询和修改都是通过向 Apiserver 发送请求,对 Apiserver 的请求来源可以分为4类
控制面组件,例如 Scheduler,各种 Controller,Apiserver 自身
节点上的各种 Agent,例如 Kubelet、Kube-proxy 等
集群的其它服务,例如 Coredns、Ingress-controller、各种第三方的 Operator 等
外部用户,例如运维人员通过 Kubectl
每一条审计日志都是一个 JSON 格式的结构化记录,包括元数据(metadata)、请求内容(requestObject)和响应内容(responseObject)3个部分。其中元数据一定会存在,请求和响应内容是否存在取决于审计级别。元数据包含了请求的上下文信息,例如谁发起的请求,从哪里发起的,访问的 URI 等等;
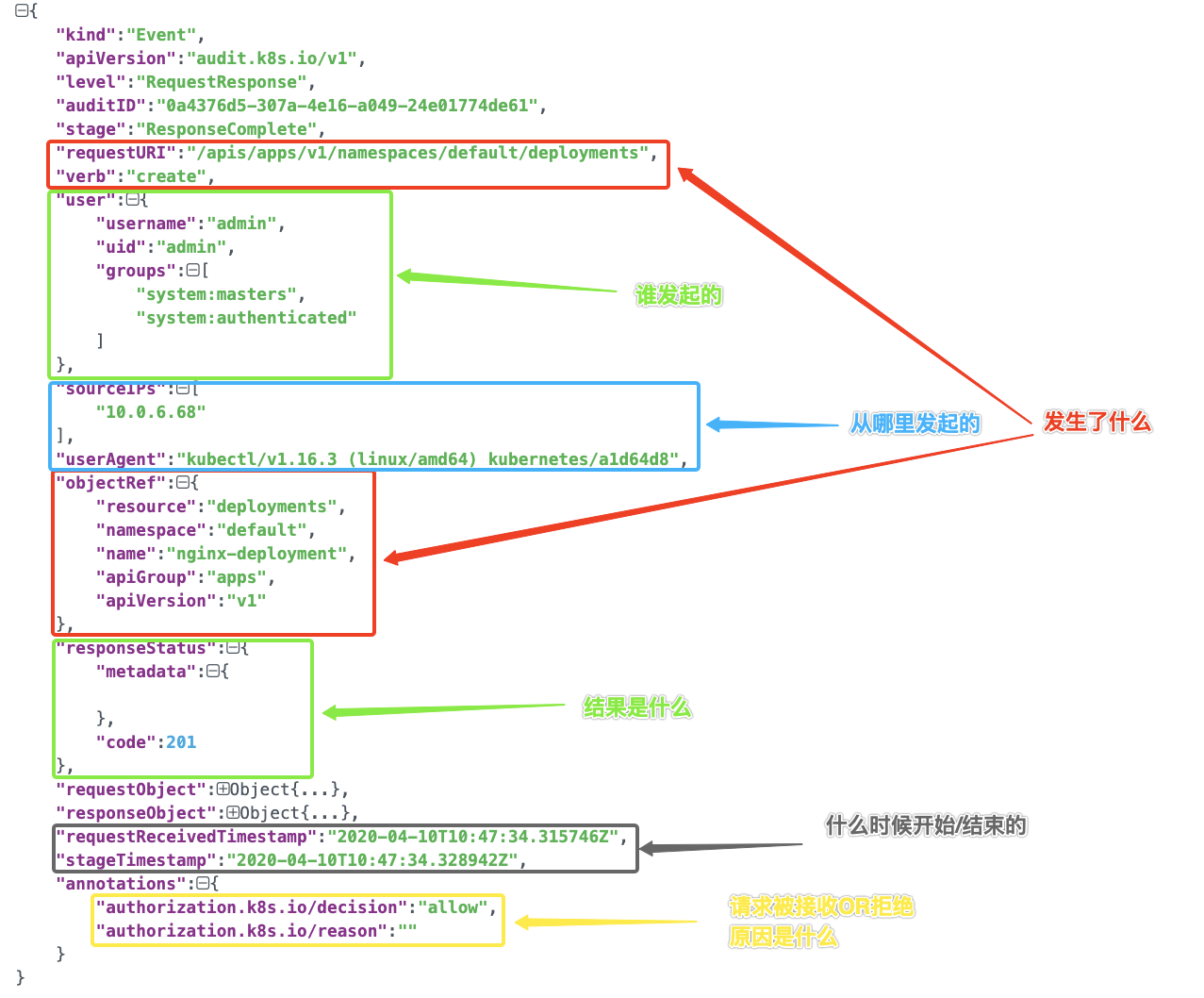
Apiserver 做为 Kubernetes 集群唯一的资源查询、变更入口,审计日志可以说记录了所有对于集群访问的流水, 通过它可以从宏观和微观了解整个集群的运行状况,比如:
资源被删掉了,什么时候删掉的,被“谁”删掉的?
服务出现问题,什么时候做过版本变更?
Apiserver 的响应延时变长,或者出现大量 5XX 响应 Status Code,Apiserver 负载变高,是什么导致的?
Apiserver 返回 401/403 请求,究竟是证书过期,非法访问,还是 RBAC 配置错误等。
Apiserver 收到大量来自外网 IP 对敏感资源的访问请求,这种请求是否合理,是否存在安全风险;
事件(Event)是 Kubernetes 中众多资源对象中的一员,通常用来记录集群内发生的状态变更,大到集群节点异常,小到 Pod 启动、调度成功等等。我们常用的kubectl describe命令就可以查看相关资源的事件信息。

级别(Type): 目前仅有“Normal”和“Warning”,但是如果需要,可以使用自定义类型。
资源类型/对象(Involved Object):事件所涉及的对象,例如 Pod,Deployment,Node 等。
事件源(Source):报告此事件的组件;如 Scheduler、Kubelet 等。
内容(Reason):当前发生事件的简短描述,一般为枚举值,主要在程序内部使用。
详细描述(Message):当前发生事件的详细描述信息。
出现次数(Count):事件发生的次数。
集群内已经翻江倒海,集群外却风平浪静,这可能是我们日常集群运维中常常遇到的情况,集群内的状况如果无法透过事件来感知,很可能会错过最佳的问题处理时间,待问题扩大,影响到业务时才发现往往已经为时已晚;除了早早发现问题,Event 也是排查问题的最佳帮手,由于 Event 记录了全面的集群状态变更信息,所以大部分的集群问题都可通过 Event 来排查。总结一下 Event 在集群中扮演两大重要角色:
“吹哨人”:当集群发生异常情况时,用户可通过事件第一时间感知;
“目击者”:集群中的大小事件都会通过 Event 记录,如果集群中发生意外情况,如:节点状态异常,Pod 重启,都可以通过事件查找发生的时间点及原因;
传统的通过输入查询语句检索日志的方式来使用审计和事件,固然可以提供很高的灵活性,但也有着较高的使用门槛,不仅要求使用者对于日志的数据结构非常了解,还要熟悉 Lucene、SQL 语法。这往往导致使用效率偏低,也无法充分发掘数据的价值。
腾讯云容器服务 TKE 联合腾讯云日志服务CLS,打造出针对 Kubernetes 审计/事件采集、存储、检索、分析的一站式产品级服务, 不仅提供了一键开启/关闭功能,免去一切繁琐的配置;而且容器团队还从长期运维海量集群的经验中,总结出对于 Kubernetes 审计/事件的最佳使用实践,通过可视化的图表,以多个维度对审计日志和集群事件进行呈现,使用者只需了解 K8s 的基本概念,就能很“直觉”地在 TKE 控制台上进行各种检索和分析操作,足以涵盖绝大多数常见集群运维场景, 让无论是发现问题还是定位问题都事半功倍,提升运维效率,真正将审计和事件数据的价值最大化 。
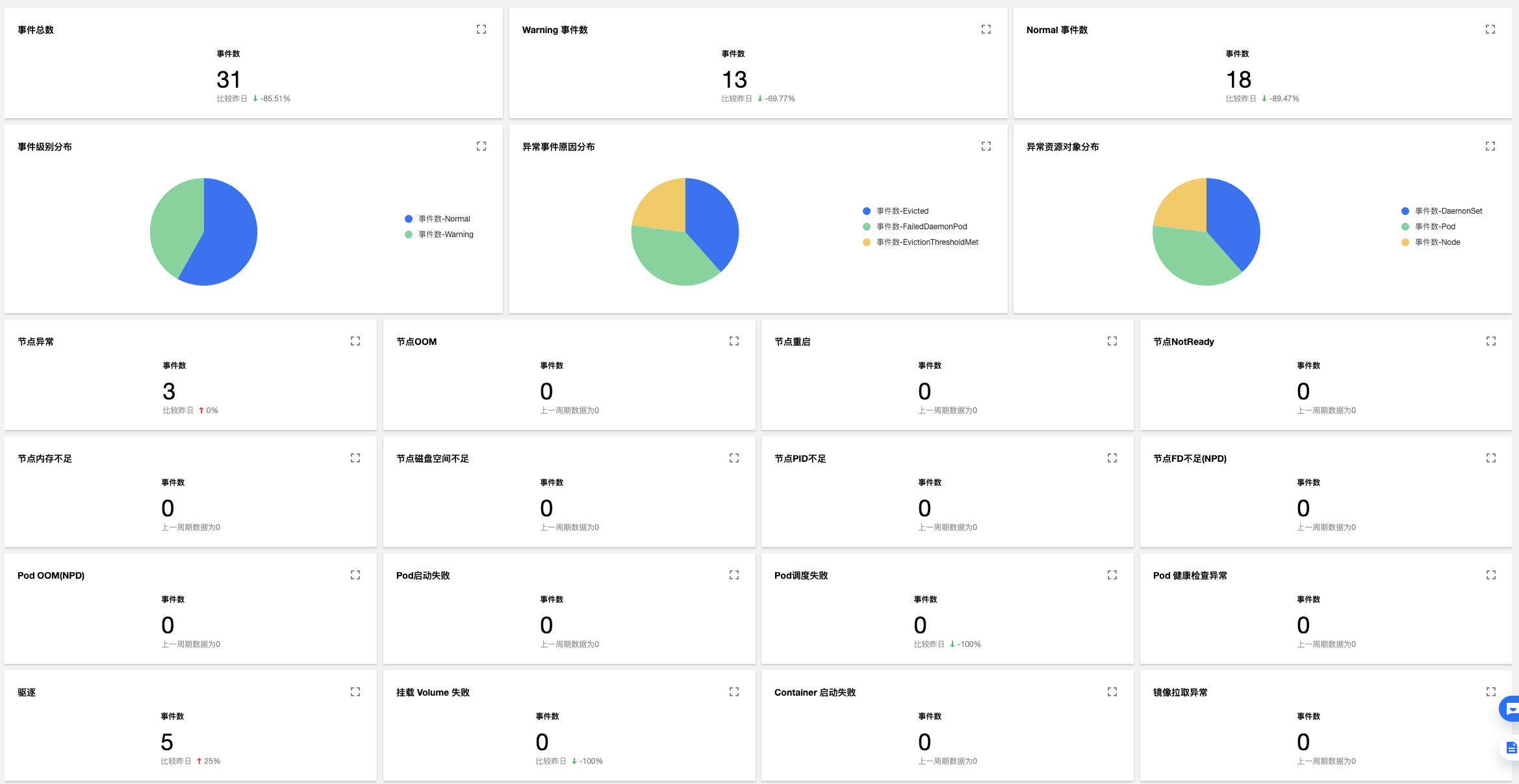
关于 TKE 的集群审计/事件简介与基础操作,请参考集群审计、事件存储的官方文档。
下面我们看几个现实中的典型场景
在审计检索页面中,单击【K8s 对象操作概览】标签,指定操作类型和资源对象
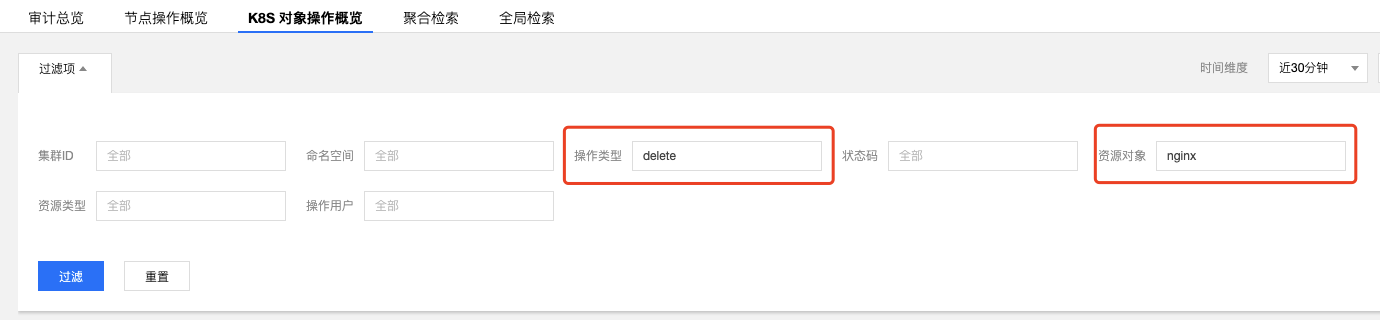
查询结果如下图所示:

由图可见,是 10001****7138 这个帐号,对应用「nginx」进行了删除。可根据帐号ID在【访问管理】>【用户列表】中找到关于此账号的详细信息。
在审计检索页面中,单击【节点操作概览】标签,填写被封锁的节点名 
查询结果如下图所示:

由图可见,是10001****7138这个帐号在2020-1-30T06:22:18时对172.16.18.13这台节点进行了封锁操作。
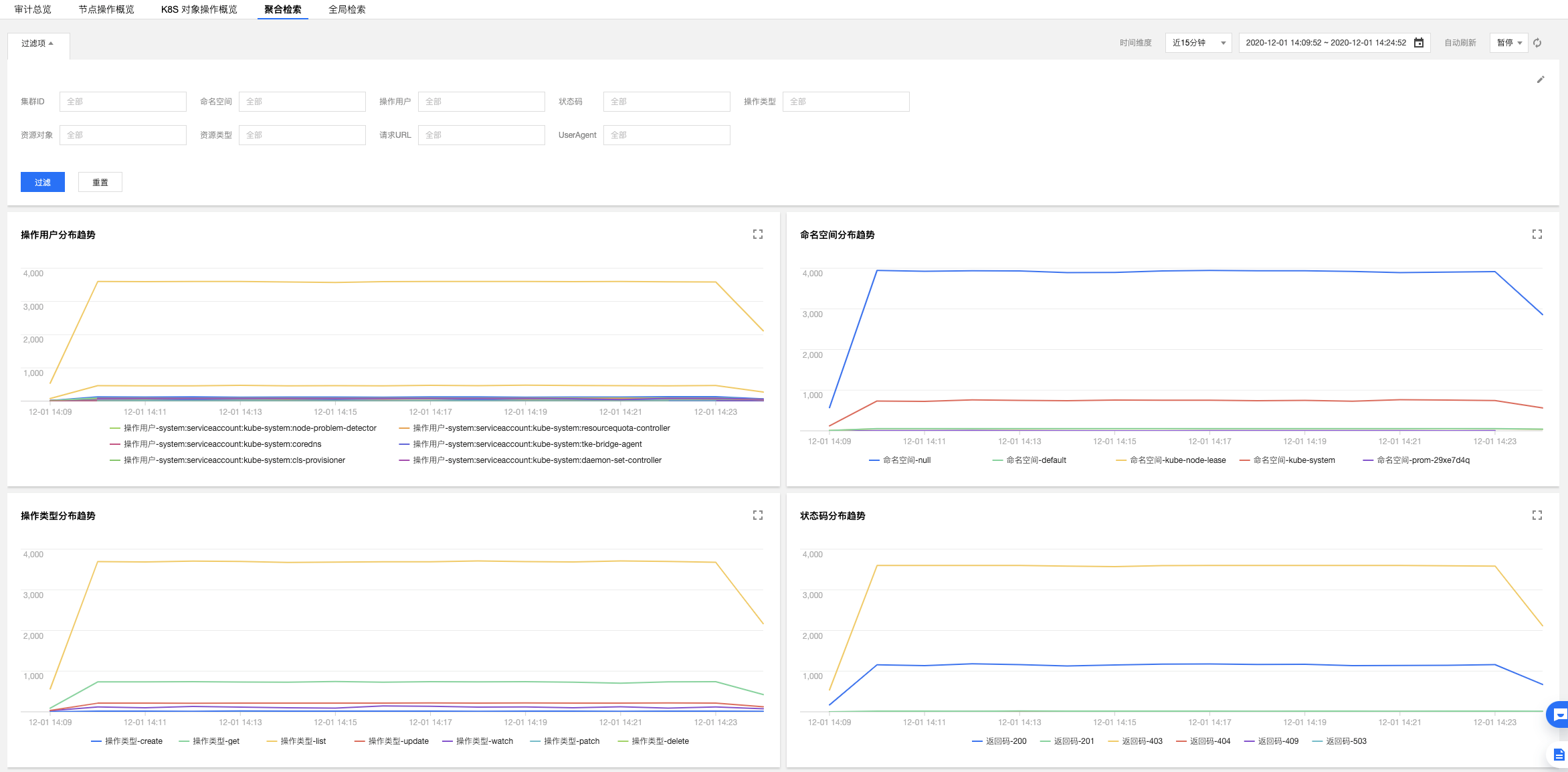
在审计检索的【聚合检索】标签页中,提供了从用户、操作类型、返回状态码等多个维度对于 Apiserver 访问聚合趋势图。
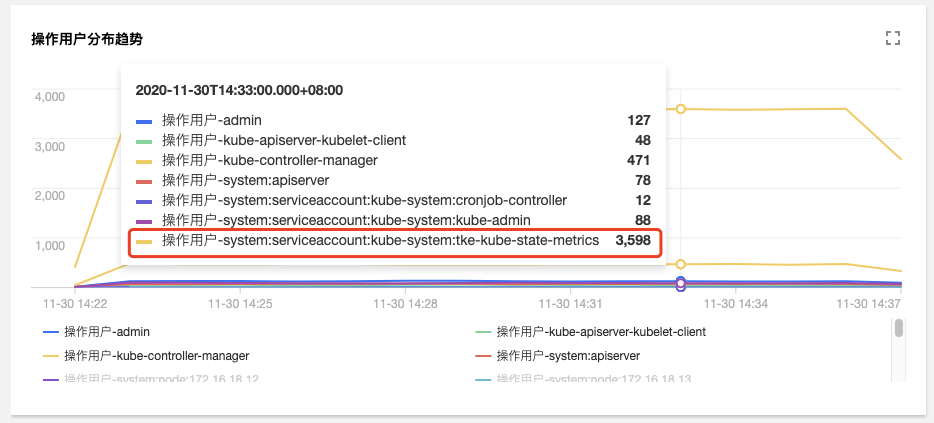
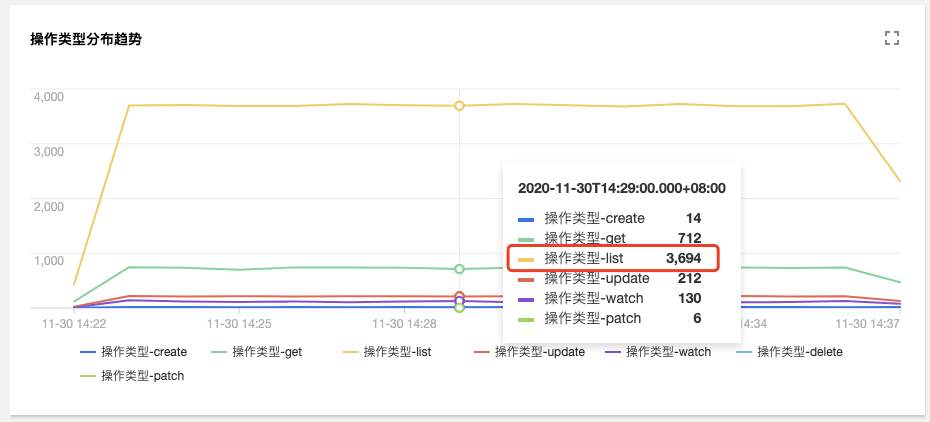
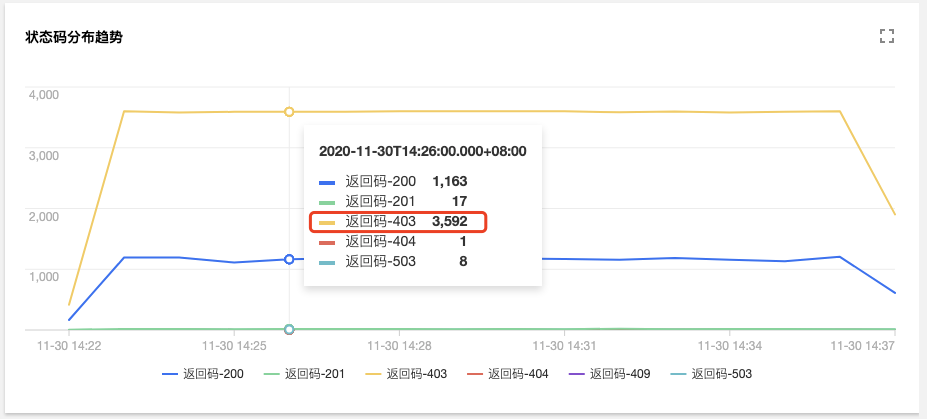
由图可见,用户tke-kube-state-metrics的访问量远高于其他用户,并且在“操作类型分布趋势”图中可以看出大多数都是 list 操作,在“状态码分布趋势”图中可以看出,状态
码大多数为 403,结合业务日志可知,由于 RBAC 鉴权问题导致tke-kube-state-metrics组件不停的请求Apiserver重试,导致 Apiserver 访问剧增。日志如下所示:
E1130 06:19:37.368981 1 reflector.go:156] pkg/mod/k8s.io/client-go@v0.0.0-20191109102209-3c0d1af94be5/tools/cache/reflector.go:108: Failed to list *v1.VolumeAttachment: volumeattachments.storage.k8s.io is forbidden: User "system:serviceaccount:kube-system:tke-kube-state-metrics" cannot list resource "volumeattachments" in API group "storage.k8s.io" at the cluster scope一台 Node 节点出现异常,在事件检索页面,点击【事件总览】,在过滤项中输入异常节点名称

查询结果显示,有一条节点磁盘空间不足的事件记录查询结果如下图:
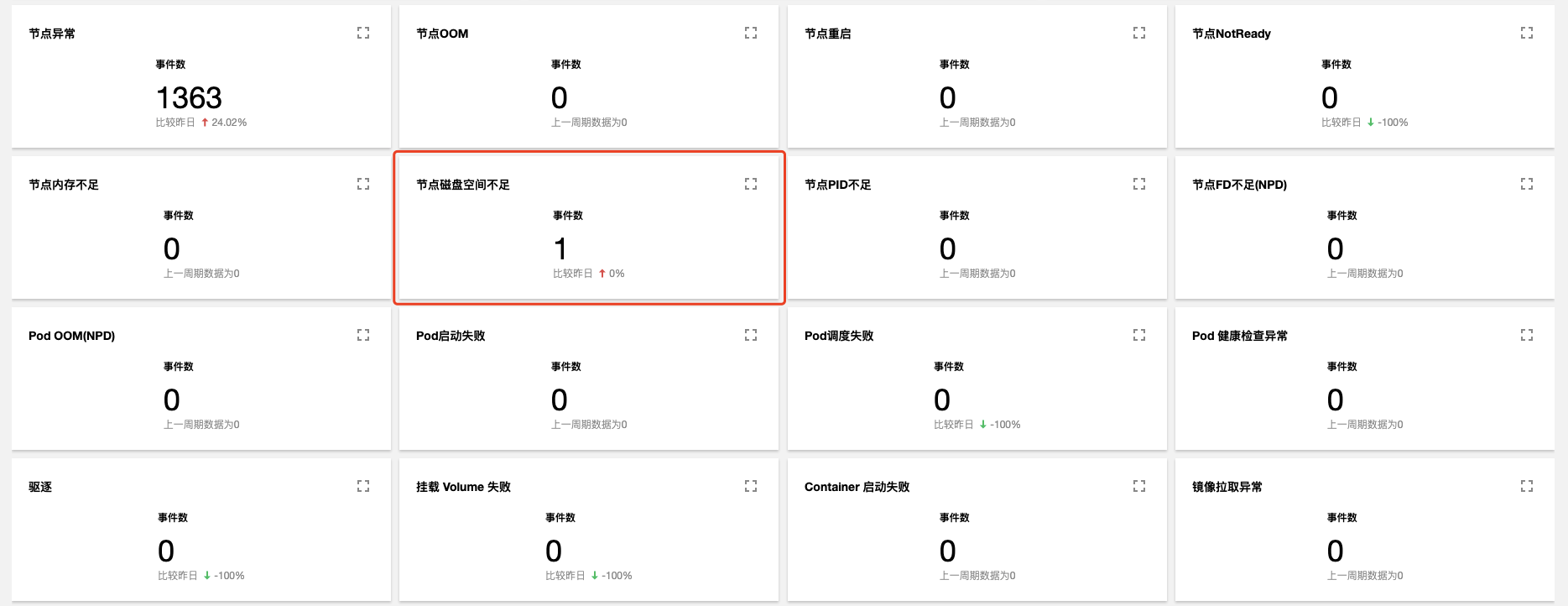
进一步查看异常事件趋势
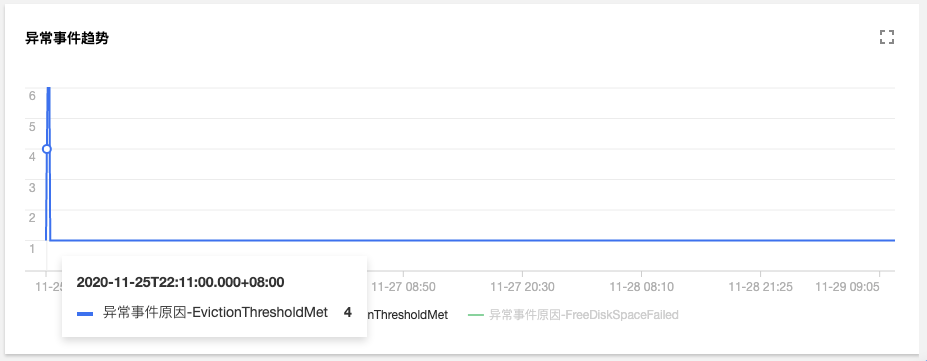
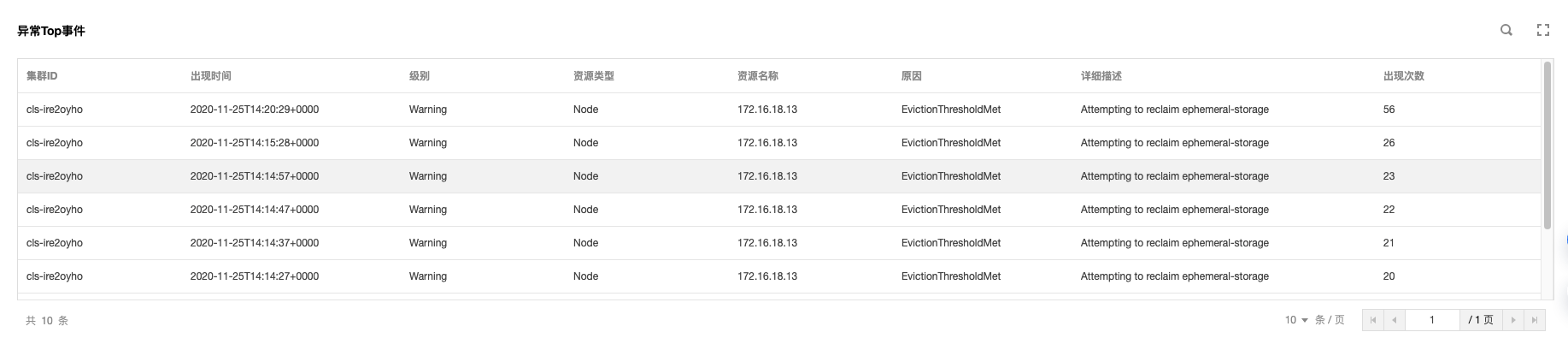
可以发现,2020-11-25号开始,节点172.16.18.13由于磁盘空间不足导致节点异常,此后 kubelet 开始尝试驱逐节点上的 pod 以回收节点磁盘空间;
开启了节点池「弹性伸缩」的集群,CA(cluster-autoscler)组件会根据负载状况自动对集群中节点数量进行增减。如果集群中的节点发生了自动扩(缩)容,用户可通过事件检索对整个扩(缩)容过程进行回溯。
在事件检索页面,点击【全局检索】,输入以下检索命令:
event.source.component : "cluster-autoscaler"在左侧隐藏字段中选择event.reason、event.message、event.involvedObject.name、event.involvedObject.name进行显示,将查询结果按照日志时间倒序排列,结果如下图所示:
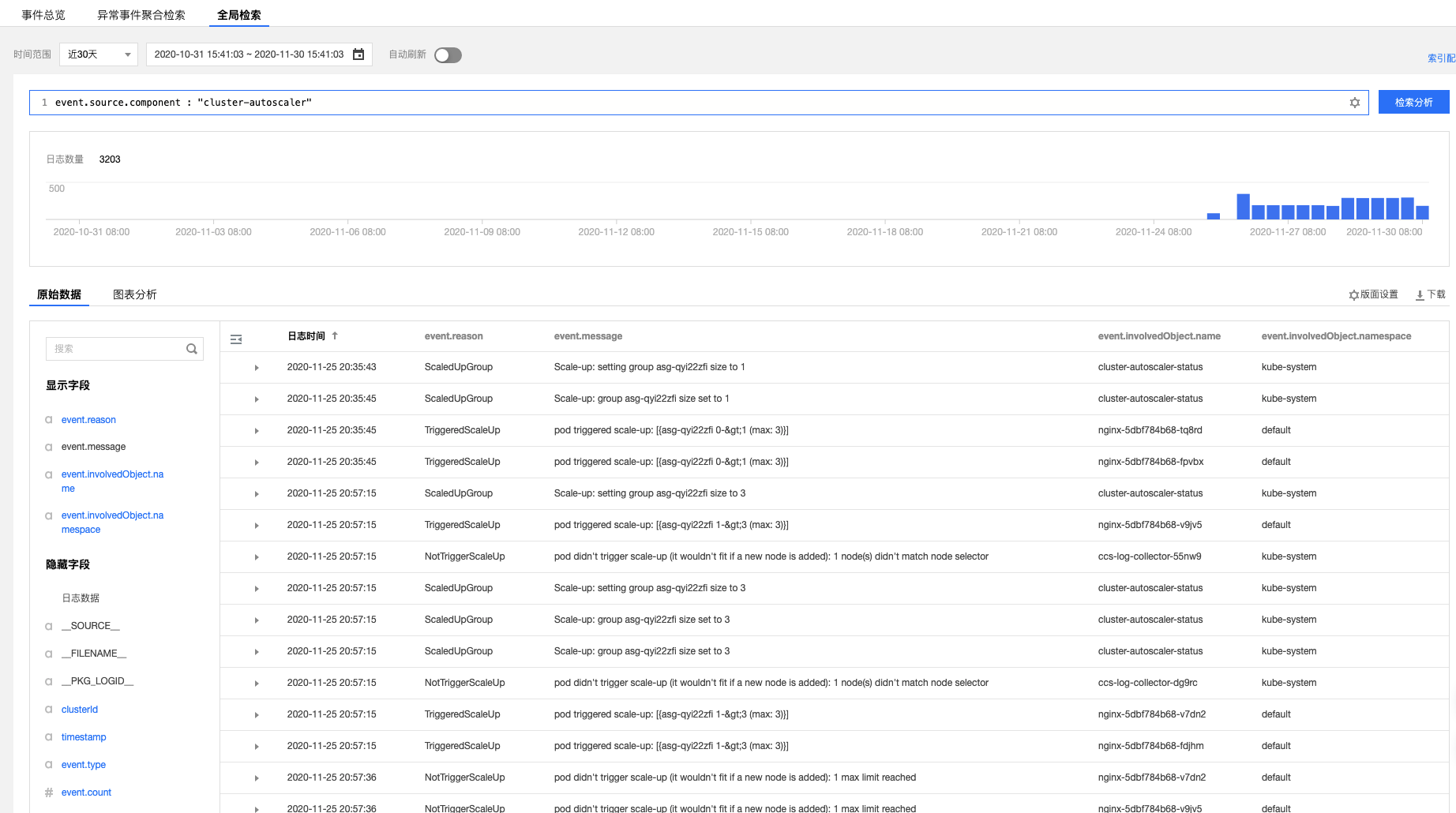
通过上图的事件流水,可以看到节点扩容操作在2020-11-25 20:35:45左右,分别由三个 nginx Pod(nginx-5dbf784b68-tq8rd、nginx-5dbf784b68-fpvbx、nginx-5dbf784b68-v9jv5) 触发,最终扩增了3个节点,后续的扩容由于达到节点池的最大节点数没有再次触发。
看完上述内容,你们对如何使用 K8s 两大利器摆脱运维困境有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4534936/blog/4779085



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



