这篇文章主要讲解了“数据库中经典的同期群举例分析”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“数据库中经典的同期群举例分析”吧!
同期群分析是数据分析中一个hin经典的思维,核心是将用户按初始行为的发生时间,划分为不同的群组,进而分析相似群组的行为如何随时间变化而变化。一般是通过像这样的留存表来实现: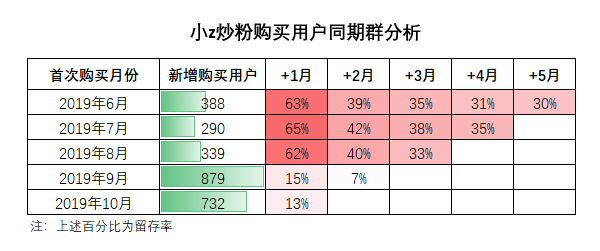
每一行,代表当月新增客户,在接下来几个月的留存情况。
通过横向对比,能够对客户留存和生命周期有初步的认识。基于纵向观察,可以发现不同期客户,留存情况的差异,以反推该期引入的客户是否精准。
这个表看起来简单明晰,也有一些成熟的工具能够实现,但是,真要基于订单数据用Python来实现,还是要绞一番脑汁的。
首先,导入订单数据,顺带看一看源数据长什么样子: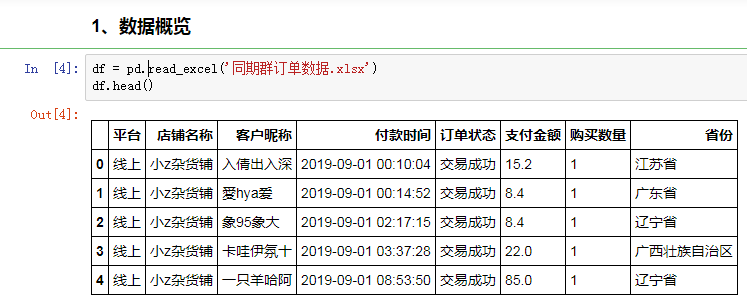
后续分析会用到的关键字段有客户昵称,付款时间,订单状态和支付金额。
再查看数据量和缺失情况: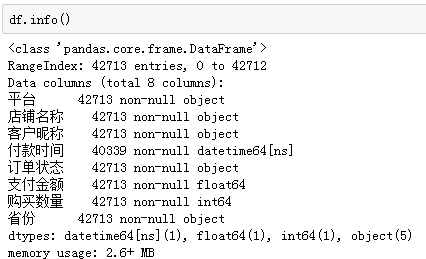
订单共计42713行,除付款时间外,其他都是完整的(不含缺失值)。格式整体规整,付款时间为datetime格式,购买金额和数量则是数值型。
清洗的重点在于搞清楚为什么会有那么多付款时间是缺失的。我们先筛选出付款时间为空值的行,一探究竟: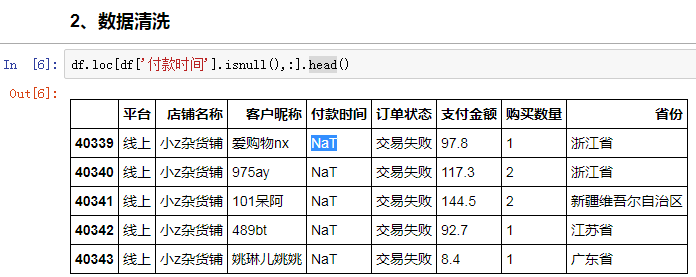
貌似,缺失付款时间的数据,订单状态主要是交易失败。这里做一个初步推断,之所以缺失付款时间,是因为没有产生实际交易。
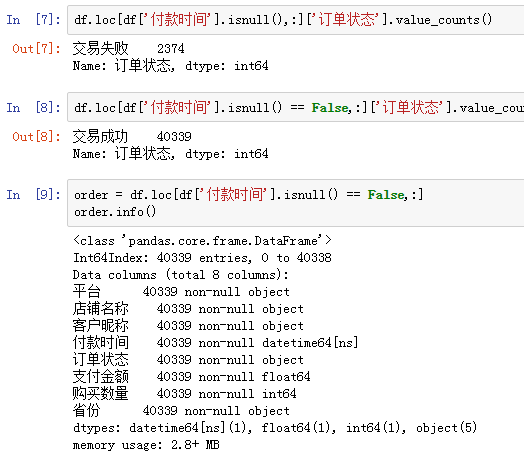
果然,缺失付款时间的订单都是交易失败状态,而完整的数据则是交易成功。接下来,只需要筛选出交易成功的订单就好,40339行数据,就是同期群分析的主战场。
再让最开始的留存表刷一下存在感:
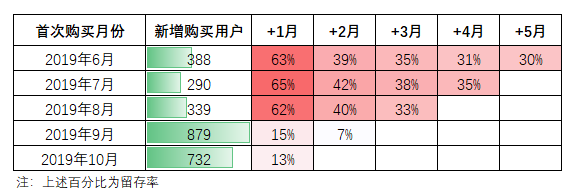
直接思考怎么样一次性生成这张表,着实费头发。更合理的方式是用搭积木的思维来拆解这张表。这张表的每一行,代表一个同期群,而他们的本质逻辑是一样的。
首先计算出当月新增的客户数,并记录客户昵称。
然后拿这部分客户,分别去和后面每个月购买的客户做匹配,并统计有多少客户出现复购(留存)
只要我们计算出每个月的新增客户和对应留存情况,把这些数据拼接在一起,就得到了梦寐以求的同期群留存表。
循着上一步的思路,问题变得简单起来,实现一个月的计算逻辑,其他月份套用即可。给同期群留存表添加一列标记数据归属与哪个年月。

我们以2019年10月的数据为样板,实现单行的同期群分析。
显而易见,2019年10月份一共有7336位客户,购买了8096笔订单。
接下来,我们要计算的是每个月的新增客户数,这个新增,是需要和之前的月份遍历匹配来验证的,2019年10月之前的客户就是2019年9月的数据: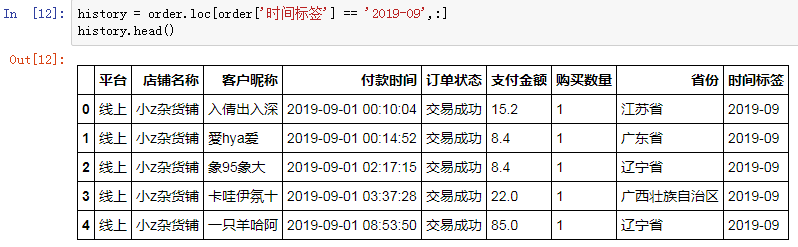
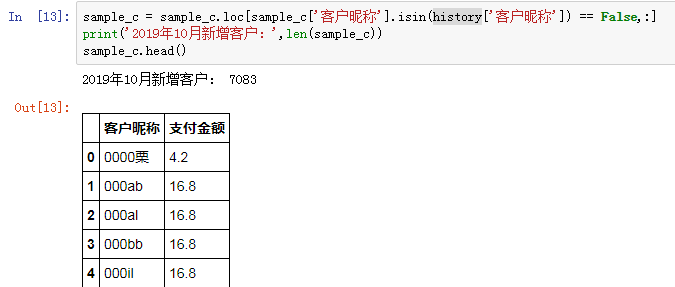
和历史数据做匹配,验证并筛选出2019年10月新增的客户数:
然后,和10月之后每个月的客户昵称进行匹配,计算出每个月的留存情况,把最开始的当月新增客户加入到列表:
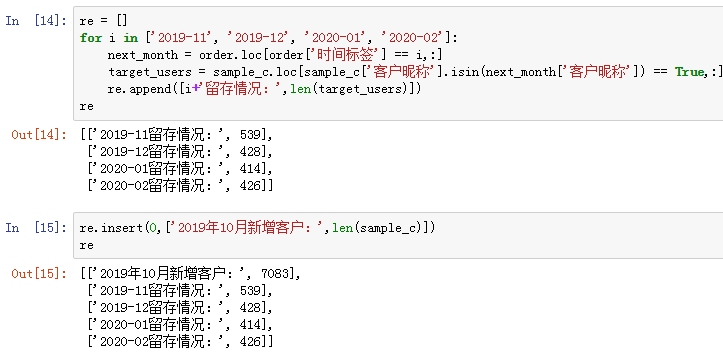
2019年10月新增客户7083位,次月(11月)留存539人,随后有所降低,而到了2020年2月留存回购客户数较上月有小幅上升。
#引入时间标签month_lst = order['时间标签'].unique()final = pd.DataFrame()for i in range(len(month_lst) - 1):#构造和月份一样长的列表,方便后续格式统一count = [0] * len(month_lst)#筛选出当月订单,并按客户昵称分组target_month = order.loc[order['时间标签'] == month_lst[i],:]target_users = target_month.groupby('客户昵称')['支付金额'].sum().reset_index()#如果是第一个月份,则跳过(因为不需要和历史数据验证是否为新增客户)if i == 0:new_target_users = target_month.groupby('客户昵称')['支付金额'].sum().reset_index()else:#如果不是,找到之前的历史订单history = order.loc[order['时间标签'].isin(month_lst[:i]),:]#筛选出未在历史订单出现过的新增客户new_target_users = target_users.loc[target_users['客户昵称'].isin(history['客户昵称']) == False,:]#当月新增客户数放在第一个值中count[0] = len(new_target_users)#以月为单位,循环遍历,计算留存情况for j,ct in zip(range(i + 1,len(month_lst)),range(1,len(month_lst))):#下一个月的订单next_month = order.loc[order['时间标签'] == month_lst[j],:]next_users = next_month.groupby('客户昵称')['支付金额'].sum().reset_index()#计算在该月仍然留存的客户数量isin = new_target_users['客户昵称'].isin(next_users['客户昵称']).sum()count[ct] = isin#格式转置result = pd.DataFrame({
month_lst[i]:count}).T#合并final = pd.concat([final,result])final.columns = ['当月新增','+1月','+2月','+3月','+4月','+5月']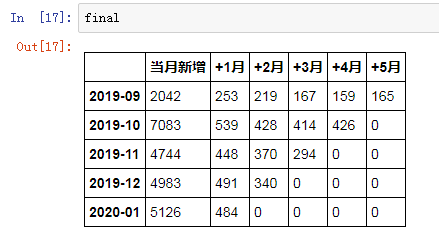
不过,真实数据是留存率形式体现,再稍做加工即可:
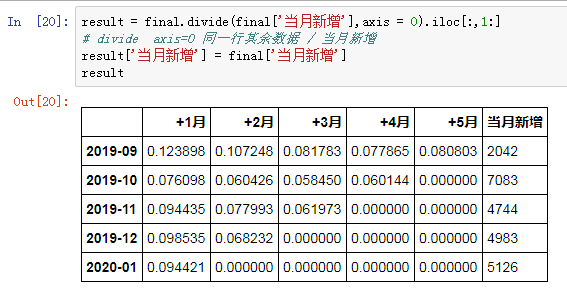
终于,大功告成!实现了我们所希望的同期群分析表。简单扫两眼,可以发现:
横向观察,次月流失严重,表现最好的月份次月留存也只有12%,随后平稳降低,稳定在6%左右。
纵向对比,2019年当月新增客户最少,仅有2042位,但人群相对精准,留存率表现优于其他月份。
感谢各位的阅读,以上就是“数据库中经典的同期群举例分析”的内容了,经过本文的学习后,相信大家对数据库中经典的同期群举例分析这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





