д»Җд№ҲжҳҜDPDK
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңд»Җд№ҲжҳҜDPDKвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁд»Җд№ҲжҳҜDPDKй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқд»Җд№ҲжҳҜDPDKвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
дёҖгҖҒзҪ‘з»ңIOзҡ„еӨ„еўғе’Ңи¶ӢеҠҝ
д»ҺжҲ‘们用жҲ·зҡ„дҪҝз”Ёе°ұеҸҜд»Ҙж„ҹеҸ—еҲ°зҪ‘йҖҹдёҖзӣҙеңЁжҸҗеҚҮпјҢиҖҢзҪ‘з»ңжҠҖжңҜзҡ„еҸ‘еұ•д№ҹд»Һ1GE/10GE/25GE/40GE/100GEзҡ„жј”еҸҳпјҢд»ҺдёӯеҸҜд»Ҙеҫ—еҮәеҚ•жңәзҡ„зҪ‘з»ңIOиғҪеҠӣеҝ…йЎ»и·ҹдёҠж—¶д»Јзҡ„еҸ‘еұ•гҖӮ
1. дј з»ҹзҡ„з”өдҝЎйўҶеҹҹ
IPеұӮеҸҠд»ҘдёӢпјҢдҫӢеҰӮи·Ҝз”ұеҷЁгҖҒдәӨжҚўжңәгҖҒйҳІзҒ«еўҷгҖҒеҹәз«ҷзӯүи®ҫеӨҮйғҪжҳҜйҮҮ用硬件解еҶіж–№жЎҲгҖӮеҹәдәҺдё“з”ЁзҪ‘з»ңеӨ„зҗҶеҷЁпјҲNPпјүпјҢжңүеҹәдәҺFPGAпјҢжӣҙжңүеҹәдәҺASICзҡ„гҖӮдҪҶжҳҜеҹәдәҺ硬件зҡ„еҠЈеҠҝйқһеёёжҳҺжҳҫпјҢеҸ‘з”ҹBugдёҚжҳ“дҝ®еӨҚпјҢдёҚжҳ“и°ғиҜ•з»ҙжҠӨпјҢ并且зҪ‘з»ңжҠҖжңҜдёҖзӣҙеңЁеҸ‘еұ•пјҢдҫӢеҰӮ2G/3G/4G/5Gзӯү移еҠЁжҠҖжңҜзҡ„йқ©ж–°пјҢиҝҷдәӣеұһдәҺдёҡеҠЎзҡ„йҖ»иҫ‘еҹәдәҺ硬件е®һзҺ°еӨӘз—ӣиӢҰпјҢдёҚиғҪеҝ«йҖҹиҝӯд»ЈгҖӮдј з»ҹйўҶеҹҹйқўдёҙзҡ„жҢ‘жҲҳжҳҜжҖҘйңҖдёҖеҘ—иҪҜ件жһ¶жһ„зҡ„й«ҳжҖ§иғҪзҪ‘з»ңIOејҖеҸ‘жЎҶжһ¶гҖӮ
2. дә‘зҡ„еҸ‘еұ•
з§Ғжңүдә‘зҡ„еҮәзҺ°йҖҡиҝҮзҪ‘з»ңеҠҹиғҪиҷҡжӢҹеҢ–пјҲNFVпјүе…ұдә«зЎ¬д»¶жҲҗдёәи¶ӢеҠҝпјҢNFVзҡ„е®ҡд№үжҳҜйҖҡиҝҮж ҮеҮҶзҡ„жңҚеҠЎеҷЁгҖҒж ҮеҮҶдәӨжҚўжңәе®һзҺ°еҗ„з§Қдј з»ҹзҡ„жҲ–ж–°зҡ„зҪ‘з»ңеҠҹиғҪгҖӮжҖҘйңҖдёҖеҘ—еҹәдәҺеёёз”Ёзі»з»ҹе’Ңж ҮеҮҶжңҚеҠЎеҷЁзҡ„й«ҳжҖ§иғҪзҪ‘з»ңIOејҖеҸ‘жЎҶжһ¶гҖӮ
3. еҚ•жңәжҖ§иғҪзҡ„йЈҷеҚҮ
зҪ‘еҚЎд»Һ1GеҲ°100Gзҡ„еҸ‘еұ•пјҢCPUд»ҺеҚ•ж ёеҲ°еӨҡж ёеҲ°еӨҡCPUзҡ„еҸ‘еұ•пјҢжңҚеҠЎеҷЁзҡ„еҚ•жңәиғҪеҠӣйҖҡиҝҮжЁӘиЎҢжү©еұ•иҫҫеҲ°ж–°зҡ„й«ҳзӮ№гҖӮдҪҶжҳҜиҪҜ件ејҖеҸ‘еҚҙж— жі•и·ҹдёҠиҠӮеҘҸпјҢеҚ•жңәеӨ„зҗҶиғҪеҠӣжІЎиғҪе’Ң硬件门еҪ“жҲ·еҜ№пјҢеҰӮдҪ•ејҖеҸ‘еҮәдёҺ时并иҝӣй«ҳеҗһеҗҗйҮҸзҡ„жңҚеҠЎпјҢеҚ•жңәзҷҫдёҮеҚғдёҮ并еҸ‘иғҪеҠӣгҖӮеҚідҪҝжңүдёҡеҠЎеҜ№QPSиҰҒжұӮдёҚй«ҳпјҢдё»иҰҒжҳҜCPUеҜҶйӣҶеһӢпјҢдҪҶжҳҜзҺ°еңЁеӨ§ж•°жҚ®еҲҶжһҗгҖҒдәәе·ҘжҷәиғҪзӯүеә”з”ЁйғҪйңҖиҰҒеңЁеҲҶеёғејҸжңҚеҠЎеҷЁд№Ӣй—ҙдј иҫ“еӨ§йҮҸж•°жҚ®е®ҢжҲҗдҪңдёҡгҖӮиҝҷзӮ№еә”иҜҘжҳҜжҲ‘们дә’иҒ”зҪ‘еҗҺеҸ°ејҖеҸ‘жңҖеә”е…іжіЁпјҢд№ҹжңҖе…іиҒ”зҡ„гҖӮ
жғідәҶи§ЈжӣҙеӨҡзҡ„е°Ҹдјҷдјҙж¬ўиҝҺиҝӣзҫӨ973961276жқҘдёҖиө·дәӨжөҒеӯҰд№ пјҢжӣҙжңүжө·йҮҸеӯҰд№ иө„ж–ҷи·ҹеӨ§еҺӮйқўиҜ•з»ҸйӘҢеҲҶдә«гҖӮ
дәҢгҖҒLinux + x86зҪ‘з»ңIO瓶йўҲ
еңЁж•°е№ҙеүҚжӣҫз»ҸеҶҷиҝҮгҖҠзҪ‘еҚЎе·ҘдҪңеҺҹзҗҶеҸҠй«ҳ并еҸ‘дёӢзҡ„и°ғдјҳгҖӢдёҖж–ҮпјҢжҸҸиҝ°дәҶLinuxзҡ„收еҸ‘жҠҘж–ҮжөҒзЁӢгҖӮж №жҚ®з»ҸйӘҢпјҢеңЁC1пјҲ8ж ёпјүдёҠи·‘еә”з”ЁжҜҸ1WеҢ…еӨ„зҗҶйңҖиҰҒж¶ҲиҖ—1%иҪҜдёӯж–ӯCPUпјҢиҝҷж„Ҹе‘ізқҖеҚ•жңәзҡ„дёҠйҷҗжҳҜ100дёҮPPSпјҲPacket Per SecondпјүгҖӮд»ҺTGWпјҲNetfilterзүҲпјүзҡ„жҖ§иғҪ100дёҮPPSпјҢAliLVSдјҳеҢ–дәҶд№ҹеҸӘеҲ°150дёҮPPSпјҢ并且他们дҪҝз”Ёзҡ„жңҚеҠЎеҷЁзҡ„й…ҚзҪ®иҝҳжҳҜжҜ”иҫғеҘҪзҡ„гҖӮеҒҮи®ҫпјҢжҲ‘们иҰҒи·‘ж»Ў10GEзҪ‘еҚЎпјҢжҜҸдёӘеҢ…64еӯ—иҠӮпјҢиҝҷе°ұйңҖиҰҒ2000дёҮPPSпјҲжіЁпјҡд»ҘеӨӘзҪ‘дёҮе…ҶзҪ‘еҚЎйҖҹеәҰдёҠйҷҗжҳҜ1488дёҮPPSпјҢеӣ дёәжңҖе°Ҹеё§еӨ§е°Ҹдёә84BгҖҠBandwidth, Packets Per Second, and Other Network Performance MetricsгҖӢпјүпјҢ100GжҳҜ2дәҝPPSпјҢеҚіжҜҸдёӘеҢ…зҡ„еӨ„зҗҶиҖ—ж—¶дёҚиғҪи¶…иҝҮ50зәіз§’гҖӮиҖҢдёҖж¬ЎCache MissпјҢдёҚз®ЎжҳҜTLBгҖҒж•°жҚ®CacheгҖҒжҢҮд»ӨCacheеҸ‘з”ҹMissпјҢеӣһеҶ…еӯҳиҜ»еҸ–еӨ§зәҰ65зәіз§’пјҢNUMAдҪ“зі»дёӢи·ЁNodeйҖҡи®ҜеӨ§зәҰ40зәіз§’гҖӮжүҖд»ҘпјҢеҚідҪҝдёҚеҠ дёҠдёҡеҠЎйҖ»иҫ‘пјҢеҚідҪҝзәҜ收еҸ‘еҢ…йғҪеҰӮжӯӨиү°йҡҫгҖӮжҲ‘们иҰҒжҺ§еҲ¶Cacheзҡ„е‘ҪдёӯзҺҮпјҢжҲ‘们иҰҒдәҶи§Ји®Ўз®—жңәдҪ“зі»з»“жһ„пјҢдёҚиғҪеҸ‘з”ҹи·ЁNodeйҖҡи®ҜгҖӮ
д»Һиҝҷдәӣж•°жҚ®пјҢжҲ‘еёҢжңӣеҸҜд»ҘзӣҙжҺҘж„ҹеҸ—дёҖдёӢиҝҷйҮҢзҡ„жҢ‘жҲҳжңүеӨҡеӨ§пјҢзҗҶжғіе’ҢзҺ°е®һпјҢжҲ‘们йңҖиҰҒд»Һдёӯе№іиЎЎгҖӮй—®йўҳйғҪжңүиҝҷдәӣ
1.дј з»ҹзҡ„收еҸ‘жҠҘж–Үж–№ејҸйғҪеҝ…йЎ»йҮҮз”ЁзЎ¬дёӯж–ӯжқҘеҒҡйҖҡи®ҜпјҢжҜҸж¬ЎзЎ¬дёӯж–ӯеӨ§зәҰж¶ҲиҖ—100еҫ®з§’пјҢиҝҷиҝҳдёҚз®—еӣ дёәз»ҲжӯўдёҠдёӢж–ҮжүҖеёҰжқҘзҡ„Cache MissгҖӮ
2.ж•°жҚ®еҝ…йЎ»д»ҺеҶ…ж ёжҖҒз”ЁжҲ·жҖҒд№Ӣй—ҙеҲҮжҚўжӢ·иҙқеёҰжқҘеӨ§йҮҸCPUж¶ҲиҖ—пјҢе…ЁеұҖй”Ғз«һдәүгҖӮ
3.收еҸ‘еҢ…йғҪжңүзі»з»ҹи°ғз”Ёзҡ„ејҖй”ҖгҖӮ
4.еҶ…ж ёе·ҘдҪңеңЁеӨҡж ёдёҠпјҢдёәеҸҜе…ЁеұҖдёҖиҮҙпјҢеҚідҪҝйҮҮз”ЁLock FreeпјҢд№ҹйҒҝе…ҚдёҚдәҶй”ҒжҖ»зәҝгҖҒеҶ…еӯҳеұҸйҡңеёҰжқҘзҡ„жҖ§иғҪжҚҹиҖ—гҖӮ
5.д»ҺзҪ‘еҚЎеҲ°дёҡеҠЎиҝӣзЁӢпјҢз»ҸиҝҮзҡ„и·Ҝеҫ„еӨӘй•ҝпјҢжңүдәӣе…¶е®һжңӘеҝ…иҰҒзҡ„пјҢдҫӢеҰӮnetfilterжЎҶжһ¶пјҢиҝҷдәӣйғҪеёҰжқҘдёҖе®ҡзҡ„ж¶ҲиҖ—пјҢиҖҢдё”е®№жҳ“Cache MissгҖӮ
дёүгҖҒDPDKзҡ„еҹәжң¬еҺҹзҗҶ
д»ҺеүҚйқўзҡ„еҲҶжһҗеҸҜд»Ҙеҫ—зҹҘIOе®һзҺ°зҡ„ж–№ејҸгҖҒеҶ…ж ёзҡ„瓶йўҲпјҢд»ҘеҸҠж•°жҚ®жөҒиҝҮеҶ…ж ёеӯҳеңЁдёҚеҸҜжҺ§еӣ зҙ пјҢиҝҷдәӣйғҪжҳҜеңЁеҶ…ж ёдёӯе®һзҺ°пјҢеҶ…ж ёжҳҜеҜјиҮҙ瓶йўҲзҡ„еҺҹеӣ жүҖеңЁпјҢиҰҒи§ЈеҶій—®йўҳйңҖиҰҒз»•иҝҮеҶ…ж ёгҖӮжүҖд»Ҙдё»жөҒи§ЈеҶіж–№жЎҲйғҪжҳҜж—Ғи·ҜзҪ‘еҚЎIOпјҢз»•иҝҮеҶ…ж ёзӣҙжҺҘеңЁз”ЁжҲ·жҖҒ收еҸ‘еҢ…жқҘи§ЈеҶіеҶ…ж ёзҡ„瓶йўҲгҖӮ
LinuxзӨҫеҢәд№ҹжҸҗдҫӣдәҶж—Ғи·ҜжңәеҲ¶NetmapпјҢе®ҳж–№ж•°жҚ®10GзҪ‘еҚЎ1400дёҮPPSпјҢдҪҶжҳҜNetmapжІЎе№ҝжіӣдҪҝз”ЁгҖӮе…¶еҺҹеӣ жңүеҮ дёӘпјҡ
1.NetmapйңҖиҰҒй©ұеҠЁзҡ„ж”ҜжҢҒпјҢеҚійңҖиҰҒзҪ‘еҚЎеҺӮе•Ҷи®ӨеҸҜиҝҷдёӘж–№жЎҲгҖӮ
2.Netmapд»Қ然дҫқиө–дёӯж–ӯйҖҡзҹҘжңәеҲ¶пјҢжІЎе®Ңе…Ёи§ЈеҶіз“¶йўҲгҖӮ
3.NetmapжӣҙеғҸжҳҜеҮ дёӘзі»з»ҹи°ғз”ЁпјҢе®һзҺ°з”ЁжҲ·жҖҒзӣҙжҺҘ收еҸ‘еҢ…пјҢеҠҹиғҪеӨӘиҝҮеҺҹе§ӢпјҢжІЎеҪўжҲҗдҫқиө–зҡ„зҪ‘з»ңејҖеҸ‘жЎҶжһ¶пјҢзӨҫеҢәдёҚе®Ңе–„гҖӮ
йӮЈд№ҲпјҢжҲ‘们жқҘзңӢзңӢеҸ‘еұ•дәҶеҚҒеҮ е№ҙзҡ„DPDKпјҢд»ҺIntelдё»еҜјејҖеҸ‘пјҢеҲ°еҚҺдёәгҖҒжҖқ科гҖҒAWSзӯүеӨ§еҺӮе•Ҷзҡ„еҠ е…ҘпјҢж ёеҝғзҺ©е®¶йғҪеңЁиҜҘеңҲеӯҗйҮҢпјҢжӢҘжңүе®Ңе–„зҡ„зӨҫеҢәпјҢз”ҹжҖҒеҪўжҲҗй—ӯзҺҜгҖӮж—©жңҹпјҢдё»иҰҒжҳҜдј з»ҹз”өдҝЎйўҶеҹҹ3еұӮд»ҘдёӢзҡ„еә”з”ЁпјҢеҰӮеҚҺдёәгҖҒдёӯеӣҪз”өдҝЎгҖҒдёӯеӣҪ移еҠЁйғҪжҳҜе…¶ж—©жңҹдҪҝз”ЁиҖ…пјҢдәӨжҚўжңәгҖҒи·Ҝз”ұеҷЁгҖҒзҪ‘е…іжҳҜдё»иҰҒеә”з”ЁеңәжҷҜгҖӮдҪҶжҳҜпјҢйҡҸзқҖдёҠеұӮдёҡеҠЎзҡ„йңҖжұӮд»ҘеҸҠDPDKзҡ„е®Ңе–„пјҢеңЁжӣҙй«ҳзҡ„еә”з”Ёд№ҹеңЁйҖҗжӯҘеҮәзҺ°гҖӮ
DPDKж—Ғи·ҜеҺҹзҗҶпјҡ
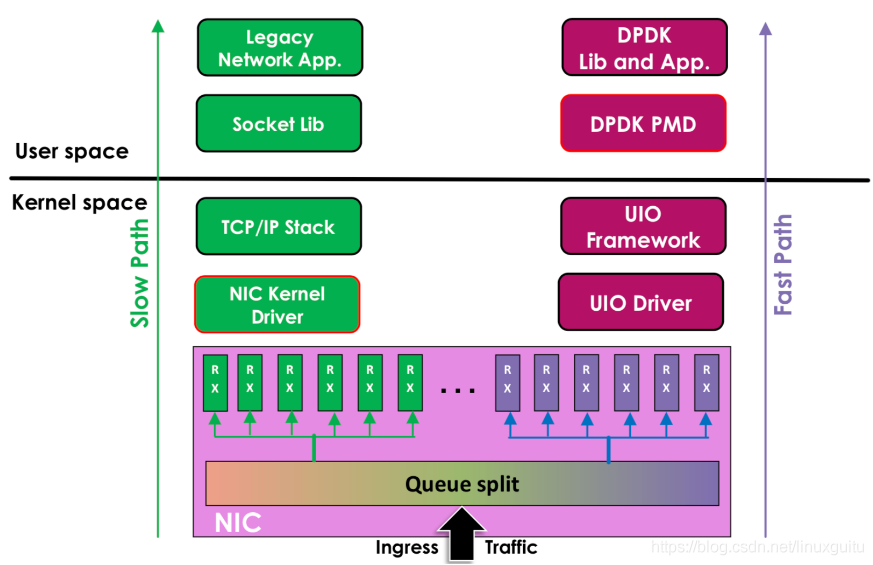
еӣҫзүҮеј•иҮӘJingjing Wuзҡ„ж–ҮжЎЈгҖҠFlow Bifurcation on IntelВ® Ethernet Controller X710/XL710гҖӢ
е·Ұиҫ№жҳҜеҺҹжқҘзҡ„ж–№ејҸж•°жҚ®д»Һ зҪ‘еҚЎ -> й©ұеҠЁ -> еҚҸи®®ж Ҳ -> SocketжҺҘеҸЈ -> дёҡеҠЎ
еҸіиҫ№жҳҜDPDKзҡ„ж–№ејҸпјҢеҹәдәҺUIOпјҲUserspace I/Oпјүж—Ғи·Ҝж•°жҚ®гҖӮж•°жҚ®д»Һ зҪ‘еҚЎ -> DPDKиҪ®иҜўжЁЎејҸ-> DPDKеҹәзЎҖеә“ -> дёҡеҠЎ
з”ЁжҲ·жҖҒзҡ„еҘҪеӨ„жҳҜжҳ“з”ЁејҖеҸ‘е’Ңз»ҙжҠӨпјҢзҒөжҙ»жҖ§еҘҪгҖӮ并且Crashд№ҹдёҚеҪұе“ҚеҶ…ж ёиҝҗиЎҢпјҢйІҒжЈ’жҖ§ејәгҖӮ
DPDKж”ҜжҢҒзҡ„CPUдҪ“зі»жһ¶жһ„пјҡx86гҖҒARMгҖҒPowerPCпјҲPPCпјү
DPDKж”ҜжҢҒзҡ„зҪ‘еҚЎеҲ—иЎЁпјҡhttps://core.dpdk.org/supported/пјҢжҲ‘们主жөҒдҪҝз”ЁIntel 82599пјҲе…үеҸЈпјүгҖҒIntel x540пјҲз”өеҸЈпјү
еӣӣгҖҒDPDKзҡ„еҹәзҹіUIO
дёәдәҶи®©й©ұеҠЁиҝҗиЎҢеңЁз”ЁжҲ·жҖҒпјҢLinuxжҸҗдҫӣUIOжңәеҲ¶гҖӮдҪҝз”ЁUIOеҸҜд»ҘйҖҡиҝҮreadж„ҹзҹҘдёӯж–ӯпјҢйҖҡиҝҮmmapе®һзҺ°е’ҢзҪ‘еҚЎзҡ„йҖҡи®ҜгҖӮ
UIOеҺҹзҗҶпјҡ
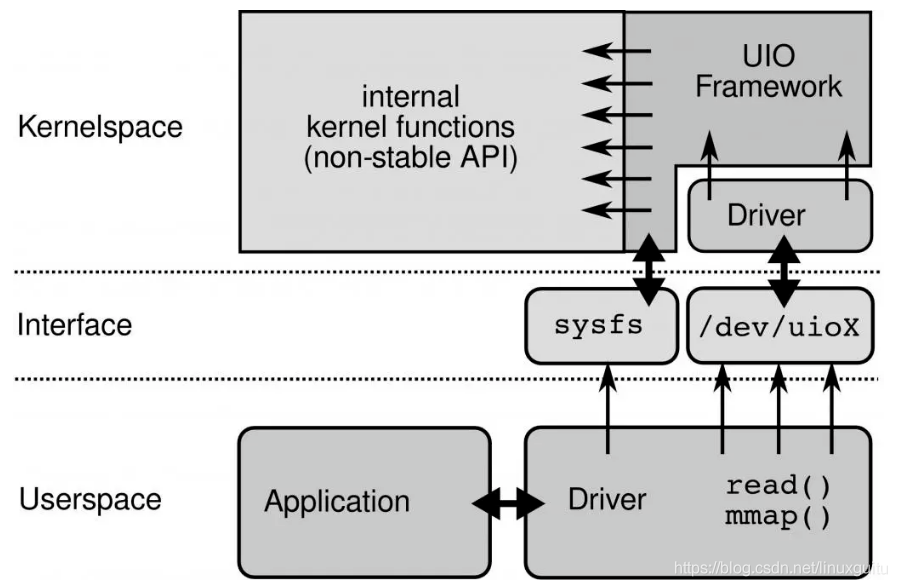
иҰҒејҖеҸ‘з”ЁжҲ·жҖҒй©ұеҠЁжңүеҮ дёӘжӯҘйӘӨпјҡ
1.ејҖеҸ‘иҝҗиЎҢеңЁеҶ…ж ёзҡ„UIOжЁЎеқ—пјҢеӣ дёәзЎ¬дёӯж–ӯеҸӘиғҪеңЁеҶ…ж ёеӨ„зҗҶ
2.йҖҡиҝҮ/dev/uioXиҜ»еҸ–дёӯж–ӯ
3.йҖҡиҝҮmmapе’ҢеӨ–и®ҫе…ұдә«еҶ…еӯҳ
дә”гҖҒDPDKж ёеҝғдјҳеҢ–пјҡPMD
DPDKзҡ„UIOй©ұеҠЁеұҸи”ҪдәҶ硬件еҸ‘еҮәдёӯж–ӯпјҢ然еҗҺеңЁз”ЁжҲ·жҖҒйҮҮз”Ёдё»еҠЁиҪ®иҜўзҡ„ж–№ејҸпјҢиҝҷз§ҚжЁЎејҸиў«з§°дёәPMDпјҲPoll Mode DriverпјүгҖӮ
UIOж—Ғи·ҜдәҶеҶ…ж ёпјҢдё»еҠЁиҪ®иҜўеҺ»жҺүзЎ¬дёӯж–ӯпјҢDPDKд»ҺиҖҢеҸҜд»ҘеңЁз”ЁжҲ·жҖҒеҒҡ收еҸ‘еҢ…еӨ„зҗҶгҖӮеёҰжқҘZero CopyгҖҒж— зі»з»ҹи°ғз”Ёзҡ„еҘҪеӨ„пјҢеҗҢжӯҘеӨ„зҗҶеҮҸе°‘дёҠдёӢж–ҮеҲҮжҚўеёҰжқҘзҡ„Cache MissгҖӮ
иҝҗиЎҢеңЁPMDзҡ„CoreдјҡеӨ„дәҺз”ЁжҲ·жҖҒCPU100%зҡ„зҠ¶жҖҒ
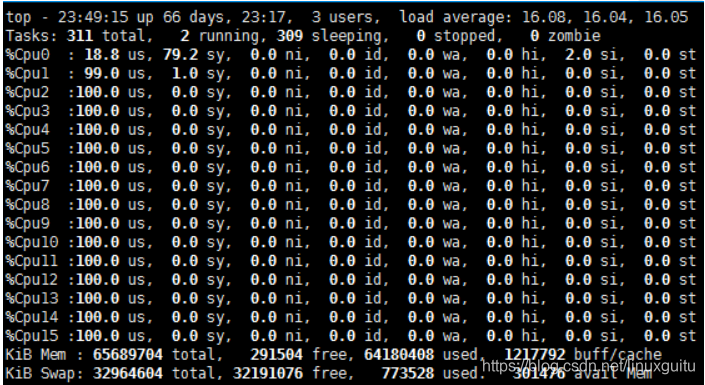
зҪ‘з»ңз©әй—Іж—¶CPUй•ҝжңҹз©әиҪ¬пјҢдјҡеёҰжқҘиғҪиҖ—й—®йўҳгҖӮжүҖд»ҘпјҢDPDKжҺЁеҮәInterrupt DPDKжЁЎејҸгҖӮ
Interrupt DPDKпјҡ
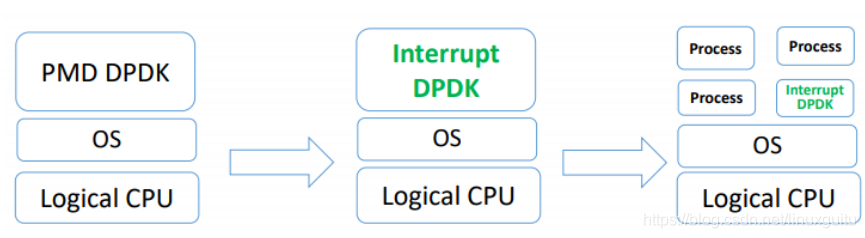
еӣҫзүҮеј•иҮӘDavid Su/Yunhong Jiang/Wei Wangзҡ„ж–ҮжЎЈгҖҠTowards Low Latency Interrupt Mode DPDKгҖӢ
е®ғзҡ„еҺҹзҗҶе’ҢNAPIеҫҲеғҸпјҢе°ұжҳҜжІЎеҢ…еҸҜеӨ„зҗҶж—¶иҝӣе…ҘзқЎзң пјҢж”№дёәдёӯж–ӯйҖҡзҹҘгҖӮ并且еҸҜд»Ҙе’Ңе…¶д»–иҝӣзЁӢе…ұдә«еҗҢдёӘCPU CoreпјҢдҪҶжҳҜDPDKиҝӣзЁӢдјҡжңүжӣҙй«ҳи°ғеәҰдјҳе…Ҳзә§гҖӮ
е…ӯгҖҒDPDKзҡ„й«ҳжҖ§иғҪд»Јз Ғе®һзҺ°
1. йҮҮз”ЁHugePageеҮҸе°‘TLB Miss
й»ҳи®ӨдёӢLinuxйҮҮз”Ё4KBдёәдёҖйЎөпјҢйЎөи¶Ҡе°ҸеҶ…еӯҳи¶ҠеӨ§пјҢйЎөиЎЁзҡ„ејҖй”Җи¶ҠеӨ§пјҢйЎөиЎЁзҡ„еҶ…еӯҳеҚ з”Ёд№ҹи¶ҠеӨ§гҖӮCPUжңүTLBпјҲTranslation Lookaside BufferпјүжҲҗжң¬й«ҳжүҖд»ҘдёҖиҲ¬е°ұеҸӘиғҪеӯҳж”ҫеҮ зҷҫеҲ°дёҠеҚғдёӘйЎөиЎЁйЎ№гҖӮеҰӮжһңиҝӣзЁӢиҰҒдҪҝз”Ё64GеҶ…еӯҳпјҢеҲҷ64G/4KB=16000000пјҲдёҖеҚғе…ӯзҷҫдёҮпјүйЎөпјҢжҜҸйЎөеңЁйЎөиЎЁйЎ№дёӯеҚ з”Ё16000000 * 4B=62MBгҖӮеҰӮжһңз”ЁHugePageйҮҮз”Ё2MBдҪңдёәдёҖйЎөпјҢеҸӘйңҖ64G/2MB=2000пјҢж•°йҮҸдёҚеңЁеҗҢдёӘзә§еҲ«гҖӮ
иҖҢDPDKйҮҮз”ЁHugePageпјҢеңЁx86-64дёӢж”ҜжҢҒ2MBгҖҒ1GBзҡ„йЎөеӨ§е°ҸпјҢеҮ дҪ•зә§зҡ„йҷҚдҪҺдәҶйЎөиЎЁйЎ№зҡ„еӨ§е°ҸпјҢд»ҺиҖҢеҮҸе°‘TLB-MissгҖӮ并жҸҗдҫӣдәҶеҶ…еӯҳжұ пјҲMempoolпјүгҖҒMBufгҖҒж— й”ҒзҺҜпјҲRingпјүгҖҒBitmapзӯүеҹәзЎҖеә“гҖӮж №жҚ®жҲ‘们зҡ„е®һи·өпјҢеңЁж•°жҚ®е№ійқўпјҲData Planeпјүйў‘з№Ғзҡ„еҶ…еӯҳеҲҶй…ҚйҮҠж”ҫпјҢеҝ…йЎ»дҪҝз”ЁеҶ…еӯҳжұ пјҢдёҚиғҪзӣҙжҺҘдҪҝз”Ёrte_mallocпјҢDPDKзҡ„еҶ…еӯҳеҲҶй…Қе®һзҺ°йқһеёёз®ҖйҷӢпјҢдёҚеҰӮptmallocгҖӮ
2. SNAпјҲShared-nothing Architectureпјү
иҪҜ件жһ¶жһ„еҺ»дёӯеҝғеҢ–пјҢе°ҪйҮҸйҒҝе…Қе…ЁеұҖе…ұдә«пјҢеёҰжқҘе…ЁеұҖз«һдәүпјҢеӨұеҺ»жЁӘеҗ‘жү©еұ•зҡ„иғҪеҠӣгҖӮNUMAдҪ“зі»дёӢдёҚи·ЁNodeиҝңзЁӢдҪҝз”ЁеҶ…еӯҳгҖӮ
3. SIMDпјҲSingle Instruction Multiple Dataпјү
д»ҺжңҖж—©зҡ„mmx/sseеҲ°жңҖж–°зҡ„avx2пјҢSIMDзҡ„иғҪеҠӣдёҖзӣҙеңЁеўһејәгҖӮDPDKйҮҮз”Ёжү№йҮҸеҗҢж—¶еӨ„зҗҶеӨҡдёӘеҢ…пјҢеҶҚз”Ёеҗ‘йҮҸзј–зЁӢпјҢдёҖдёӘе‘ЁжңҹеҶ…еҜ№жүҖжңүеҢ…иҝӣиЎҢеӨ„зҗҶгҖӮжҜ”еҰӮпјҢmemcpyе°ұдҪҝз”ЁSIMDжқҘжҸҗй«ҳйҖҹеәҰгҖӮ
SIMDеңЁжёёжҲҸеҗҺеҸ°жҜ”иҫғеёёи§ҒпјҢдҪҶжҳҜе…¶д»–дёҡеҠЎеҰӮжһңжңүзұ»дјјжү№йҮҸеӨ„зҗҶзҡ„еңәжҷҜпјҢиҰҒжҸҗй«ҳжҖ§иғҪпјҢд№ҹеҸҜзңӢзңӢиғҪеҗҰж»Ўи¶ігҖӮ
4. дёҚдҪҝз”Ёж…ўйҖҹAPI
иҝҷйҮҢйңҖиҰҒйҮҚж–°е®ҡд№үдёҖдёӢж…ўйҖҹAPIпјҢжҜ”еҰӮиҜҙgettimeofdayпјҢиҷҪ然еңЁ64дҪҚдёӢйҖҡиҝҮvDSOе·Із»ҸдёҚйңҖиҰҒйҷ·е…ҘеҶ…ж ёжҖҒпјҢеҸӘжҳҜдёҖдёӘзәҜеҶ…еӯҳи®ҝй—®пјҢжҜҸз§’д№ҹиғҪиҫҫеҲ°еҮ еҚғдёҮзҡ„зә§еҲ«гҖӮдҪҶжҳҜпјҢдёҚиҰҒеҝҳи®°дәҶжҲ‘们еңЁ10GEдёӢпјҢжҜҸз§’зҡ„еӨ„зҗҶиғҪеҠӣе°ұиҰҒиҫҫеҲ°еҮ еҚғдёҮгҖӮжүҖд»ҘеҚідҪҝжҳҜgettimeofdayд№ҹеұһдәҺж…ўйҖҹAPIгҖӮDPDKжҸҗдҫӣCyclesжҺҘеҸЈпјҢдҫӢеҰӮrte_get_tsc_cyclesжҺҘеҸЈпјҢеҹәдәҺHPETжҲ–TSCе®һзҺ°гҖӮ
еңЁx86-64дёӢдҪҝз”ЁRDTSCжҢҮд»ӨпјҢзӣҙжҺҘд»ҺеҜ„еӯҳеҷЁиҜ»еҸ–пјҢйңҖиҰҒиҫ“е…Ҙ2дёӘеҸӮж•°пјҢжҜ”иҫғеёёи§Ғзҡ„е®һзҺ°пјҡ
static inline uint64_t
rte_rdtsc(void)
{
uint32_t lo, hi;
__asm__ __volatile__ (
"rdtsc" : "=a"(lo), "=d"(hi)
);
return ((unsigned long long)lo) | (((unsigned long long)hi) << 32);
}иҝҷд№ҲеҶҷйҖ»иҫ‘жІЎй”ҷпјҢдҪҶжҳҜиҝҳдёҚеӨҹжһҒиҮҙпјҢиҝҳж¶үеҸҠеҲ°2ж¬ЎдҪҚиҝҗз®—жүҚиғҪеҫ—еҲ°з»“жһңпјҢжҲ‘们зңӢзңӢDPDKжҳҜжҖҺд№Ҳе®һзҺ°пјҡ
static inline uint64_t
rte_rdtsc(void)
{
union {
uint64_t tsc_64;
struct {
uint32_t lo_32;
uint32_t hi_32;
};
} tsc;
asm volatile("rdtsc" :
"=a" (tsc.lo_32),
"=d" (tsc.hi_32));
return tsc.tsc_64;
}е·§еҰҷзҡ„еҲ©з”ЁCзҡ„unionе…ұдә«еҶ…еӯҳпјҢзӣҙжҺҘиөӢеҖјпјҢеҮҸе°‘дәҶдёҚеҝ…иҰҒзҡ„иҝҗз®—гҖӮдҪҶжҳҜдҪҝз”Ёtscжңүдәӣй—®йўҳйңҖиҰҒйқўеҜ№е’Ңи§ЈеҶі
CPUдәІе’ҢжҖ§пјҢи§ЈеҶіеӨҡж ёи·іеҠЁдёҚзІҫзЎ®зҡ„й—®йўҳ
еҶ…еӯҳеұҸйҡңпјҢи§ЈеҶід№ұеәҸжү§иЎҢдёҚзІҫзЎ®зҡ„й—®йўҳ
зҰҒжӯўйҷҚйў‘е’ҢзҰҒжӯўIntel Turbo BoostпјҢеӣәе®ҡCPUйў‘зҺҮпјҢи§ЈеҶійў‘зҺҮеҸҳеҢ–еёҰжқҘзҡ„еӨұеҮҶй—®йўҳ
5. зј–иҜ‘жү§иЎҢдјҳеҢ–
еҲҶж”Ҝйў„жөӢ
зҺ°д»ЈCPUйҖҡиҝҮpipelineгҖҒsuperscalarжҸҗй«ҳ并иЎҢеӨ„зҗҶиғҪеҠӣпјҢдёәдәҶиҝӣдёҖжӯҘеҸ‘жҢҘ并иЎҢиғҪеҠӣдјҡеҒҡеҲҶж”Ҝйў„жөӢпјҢжҸҗеҚҮCPUзҡ„并иЎҢиғҪеҠӣгҖӮйҒҮеҲ°еҲҶж”Ҝж—¶еҲӨж–ӯеҸҜиғҪиҝӣе…Ҙе“ӘдёӘеҲҶж”ҜпјҢжҸҗеүҚеӨ„зҗҶиҜҘеҲҶж”Ҝзҡ„д»Јз ҒпјҢйў„е…ҲеҒҡжҢҮд»ӨиҜ»еҸ–зј–з ҒиҜ»еҸ–еҜ„еӯҳеҷЁзӯүпјҢйў„жөӢеӨұиҙҘеҲҷйў„еӨ„зҗҶе…ЁйғЁдёўејғгҖӮжҲ‘们ејҖеҸ‘дёҡеҠЎжңүж—¶еҖҷдјҡйқһеёёжё…жҘҡиҝҷдёӘеҲҶж”ҜжҳҜtrueиҝҳжҳҜfalseпјҢйӮЈе°ұеҸҜд»ҘйҖҡиҝҮдәәе·Ҙе№Ійў„з”ҹжҲҗжӣҙзҙ§еҮ‘зҡ„д»Јз ҒжҸҗзӨәCPUеҲҶж”Ҝйў„жөӢжҲҗеҠҹзҺҮгҖӮ
#pragma once
#if !__GLIBC_PREREQ(2, 3)
# if !define __builtin_expect
# define __builtin_expect(x, expected_value) (x)
# endif
#endif
#if !defined(likely)
#define likely(x) (__builtin_expect(!!(x), 1))
#endif
#if !defined(unlikely)
#define unlikely(x) (__builtin_expect(!!(x), 0))
#endif
CPU Cacheйў„еҸ–
Cache Missзҡ„д»Јд»·йқһеёёй«ҳпјҢеӣһеҶ…еӯҳиҜ»йңҖиҰҒ65зәіз§’пјҢеҸҜд»Ҙе°ҶеҚіе°Ҷи®ҝй—®зҡ„ж•°жҚ®дё»еҠЁжҺЁйҖҒзҡ„CPU CacheиҝӣиЎҢдјҳеҢ–гҖӮжҜ”иҫғе…ёеһӢзҡ„еңәжҷҜжҳҜй“ҫиЎЁзҡ„йҒҚеҺҶпјҢй“ҫиЎЁзҡ„дёӢдёҖиҠӮзӮ№йғҪжҳҜйҡҸжңәеҶ…еӯҳең°еқҖпјҢжүҖд»ҘCPUиӮҜе®ҡжҳҜж— жі•иҮӘеҠЁйў„еҠ иҪҪзҡ„гҖӮдҪҶжҳҜжҲ‘们еңЁеӨ„зҗҶжң¬иҠӮзӮ№ж—¶пјҢеҸҜд»ҘйҖҡиҝҮCPUжҢҮд»Өе°ҶдёӢдёҖдёӘиҠӮзӮ№жҺЁйҖҒеҲ°CacheйҮҢгҖӮ
APIж–ҮжЎЈпјҡhttps://doc.dpdk.org/api/rte__prefetch_8h.html
static inline void rte_prefetch0(const volatile void *p)
{
asm volatile ("prefetcht0 %[p]" : : [p] "m" (*(const volatile char *)p));
}#if !defined(prefetch)
#define prefetch(x) __builtin_prefetch(x)
#endif
вҖҰзӯүзӯү
еҶ…еӯҳеҜ№йҪҗ
еҶ…еӯҳеҜ№йҪҗжңү2дёӘеҘҪеӨ„пјҡ
l йҒҝе…Қз»“жһ„дҪ“жҲҗе‘ҳи·ЁCache LineпјҢйңҖ2ж¬ЎиҜ»еҸ–жүҚиғҪеҗҲ并еҲ°еҜ„еӯҳеҷЁдёӯпјҢйҷҚдҪҺжҖ§иғҪгҖӮз»“жһ„дҪ“жҲҗе‘ҳйңҖд»ҺеӨ§еҲ°е°ҸжҺ’еәҸе’Ңд»ҘеҸҠејәеҲ¶еҜ№йҪҗгҖӮеҸӮиҖғгҖҠData alignment: Straighten up and fly rightгҖӢ
#define __rte_packed __attribute__((__packed__))
l еӨҡзәҝзЁӢеңәжҷҜдёӢеҶҷдә§з”ҹFalse sharingпјҢйҖ жҲҗCache MissпјҢз»“жһ„дҪ“жҢүCache LineеҜ№йҪҗ
#ifndef CACHE_LINE_SIZE
#define CACHE_LINE_SIZE 64
#endif
#ifndef aligined
#define aligined(a) __attribute__((__aligned__(a)))
#endif
еёёйҮҸдјҳеҢ–
еёёйҮҸзӣёе…ізҡ„иҝҗз®—зҡ„зј–иҜ‘йҳ¶ж®өе®ҢжҲҗгҖӮжҜ”еҰӮC++11еј•е…ҘдәҶconstexpпјҢжҜ”еҰӮеҸҜд»ҘдҪҝз”ЁGCCзҡ„__builtin_constant_pжқҘеҲӨж–ӯеҖјжҳҜеҗҰеёёйҮҸпјҢ然еҗҺеҜ№еёёйҮҸиҝӣиЎҢзј–иҜ‘ж—¶еҫ—еҮәз»“жһңгҖӮдёҫдҫӢзҪ‘з»ңеәҸдё»жңәеәҸиҪ¬жҚў
#define rte_bswap32(x) ((uint32_t)(__builtin_constant_p(x) ? \
rte_constant_bswap32(x) : \
rte_arch_bswap32(x)))
е…¶дёӯrte_constant_bswap32зҡ„е®һзҺ°
#define RTE_STATIC_BSWAP32(v) \
((((uint32_t)(v) & UINT32_C(0x000000ff)) << 24) | \
(((uint32_t)(v) & UINT32_C(0x0000ff00)) << 8) | \
(((uint32_t)(v) & UINT32_C(0x00ff0000)) >> 8) | \
(((uint32_t)(v) & UINT32_C(0xff000000)) >> 24))
5пјүдҪҝз”ЁCPUжҢҮд»Ө
зҺ°д»ЈCPUжҸҗдҫӣеҫҲеӨҡжҢҮд»ӨеҸҜзӣҙжҺҘе®ҢжҲҗеёёи§ҒеҠҹиғҪпјҢжҜ”еҰӮеӨ§е°Ҹз«ҜиҪ¬жҚўпјҢx86жңүbswapжҢҮд»ӨзӣҙжҺҘж”ҜжҢҒдәҶгҖӮ
static inline uint64_t rte_arch_bswap64(uint64_t _x)
{
register uint64_t x = _x;
asm volatile ("bswap %[x]"
: [x] "+r" (x)
);
return x;
}иҝҷдёӘе®һзҺ°пјҢд№ҹжҳҜGLIBCзҡ„е®һзҺ°пјҢе…ҲеёёйҮҸдјҳеҢ–гҖҒCPUжҢҮд»ӨдјҳеҢ–гҖҒжңҖеҗҺжүҚз”ЁиЈёд»Јз Ғе®һзҺ°гҖӮжҜ•з«ҹйғҪжҳҜйЎ¶з«ҜзЁӢеәҸе‘ҳпјҢеҜ№иҜӯиЁҖгҖҒзј–иҜ‘еҷЁпјҢеҜ№е®һзҺ°зҡ„иҝҪжұӮдёҚдёҖж ·пјҢжүҖд»ҘйҖ иҪ®еӯҗеүҚдёҖе®ҡиҰҒе…ҲдәҶи§ЈеҘҪиҪ®еӯҗгҖӮ
GoogleејҖжәҗзҡ„cpu_featuresеҸҜд»ҘиҺ·еҸ–еҪ“еүҚCPUж”ҜжҢҒд»Җд№Ҳзү№жҖ§пјҢд»ҺиҖҢеҜ№зү№е®ҡCPUиҝӣиЎҢжү§иЎҢдјҳеҢ–гҖӮй«ҳжҖ§иғҪзј–зЁӢж°ёж— жӯўеўғпјҢеҜ№зЎ¬д»¶гҖҒеҶ…ж ёгҖҒзј–иҜ‘еҷЁгҖҒејҖеҸ‘иҜӯиЁҖзҡ„зҗҶи§ЈиҰҒж·ұе…Ҙдё”дёҺж—¶дҝұиҝӣгҖӮ
дёғгҖҒDPDKз”ҹжҖҒ
еҜ№жҲ‘们дә’иҒ”зҪ‘еҗҺеҸ°ејҖеҸ‘жқҘиҜҙDPDKжЎҶжһ¶жң¬иә«жҸҗдҫӣзҡ„иғҪеҠӣиҝҳжҳҜжҜ”иҫғиЈёзҡ„пјҢжҜ”еҰӮиҰҒдҪҝз”ЁDPDKе°ұеҝ…йЎ»е®һзҺ°ARPгҖҒIPеұӮиҝҷдәӣеҹәзЎҖеҠҹиғҪпјҢжңүдёҖе®ҡдёҠжүӢйҡҫеәҰгҖӮеҰӮжһңиҰҒжӣҙй«ҳеұӮзҡ„дёҡеҠЎдҪҝз”ЁпјҢиҝҳйңҖиҰҒз”ЁжҲ·жҖҒзҡ„дј иҫ“еҚҸи®®ж”ҜжҢҒгҖӮдёҚе»әи®®зӣҙжҺҘдҪҝз”ЁDPDKгҖӮ
зӣ®еүҚз”ҹжҖҒе®Ңе–„пјҢзӨҫеҢәејәеӨ§пјҲдёҖзәҝеӨ§еҺӮж”ҜжҢҒпјүзҡ„еә”з”ЁеұӮејҖеҸ‘йЎ№зӣ®жҳҜFD.ioпјҲThe Fast Data ProjectпјүпјҢжңүжҖқ科ејҖжәҗж”ҜжҢҒзҡ„VPPпјҢжҜ”иҫғе®Ңе–„зҡ„еҚҸи®®ж”ҜжҢҒпјҢARPгҖҒVLANгҖҒMultipathгҖҒIPv4/v6гҖҒMPLSзӯүгҖӮз”ЁжҲ·жҖҒдј иҫ“еҚҸи®®UDP/TCPжңүTLDKгҖӮд»ҺйЎ№зӣ®е®ҡдҪҚеҲ°зӨҫеҢәж”ҜжҢҒеҠӣеәҰз®—жҜ”иҫғйқ и°ұзҡ„жЎҶжһ¶гҖӮ
и…ҫи®Ҝдә‘ејҖжәҗзҡ„F-Stackд№ҹеҖјеҫ—е…іжіЁдёҖдёӢпјҢејҖеҸ‘жӣҙз®ҖеҚ•пјҢзӣҙжҺҘжҸҗдҫӣдәҶPOSIXжҺҘеҸЈгҖӮ
Seastarд№ҹеҫҲејәеӨ§е’ҢзҒөжҙ»пјҢеҶ…ж ёжҖҒе’ҢDPDKйғҪйҡҸж„ҸеҲҮжҚўпјҢд№ҹжңүиҮӘе·ұзҡ„дј иҫ“еҚҸи®®Seastar Native TCP/IP Stackж”ҜжҢҒпјҢдҪҶжҳҜзӣ®еүҚиҝҳжңӘзңӢеҲ°жңүеӨ§еһӢйЎ№зӣ®еңЁдҪҝз”ЁSeastarпјҢеҸҜиғҪйңҖиҰҒеЎ«зҡ„еқ‘жҜ”иҫғеӨҡгҖӮ
жҲ‘们GBN GatewayйЎ№зӣ®йңҖиҰҒж”ҜжҢҒL3/IPеұӮжҺҘе…ҘеҒҡWanзҪ‘е…іпјҢеҚ•жңә20GEпјҢеҹәдәҺDPDKејҖеҸ‘гҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңд»Җд№ҲжҳҜDPDKвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





