本篇内容介绍了“怎么深入理解ArrayList源码”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
ArrayList是最常见的集合类,顾名思义,ArrayList就是一个以数组形式实现的集合。它拥有List集合的特点:
存取有序
带索引
允许重复元素
它本身的特点是:
查找元素快
顺序插入快
那ArrayList为什么会有这些特性的?其实从源码中我们就能够了解到它是如何实现的。
Resizable-array implementation of the {@code List} interface. Implements all optional list operations, and permits all elements, including {@code null}. In addition to implementing the {@code List} interface,this class provides methods to manipulate the size of the array that is used internally to store the list.
实现了List接口的,一个可调整大小的数组。可以存储所有的元素,包括null,除了实现了List接口的方法外,还提供了一些方法用于操作内部用于存储元素的数组的大小。
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
RandomAccess标记接口 表示ArrayList支持随机访问。什么是随机访问呢?随机访问是说你可以随意访问该数据结构中的任意一个节点,假设该数据结构有10000个节点,你可以随意访问第1个到第10000个节点。因为ArrayList用数组来存数据,Java中给数组划分内存来存储元素时,划分的是一块连续的内存地址,这些相邻元素是按顺序连续存储的。只要知道起始元素的地址First,直接first+N,便可以得到第N个元素的地址。这就是ArrayList查找快的原因。
Cloneable标记接口 表示ArrayList是可以被克隆的。
java.io.Serializable标记接口 表示ArrayList是可以被序列化的。
主要成员变量:
@java.io.Serial private static final long serialVersionUID = 8683452581122892189L;
用于标明序列化时的版本号。
private static final int DEFAULT_CAPACITY = 10;
默认初始化大小。
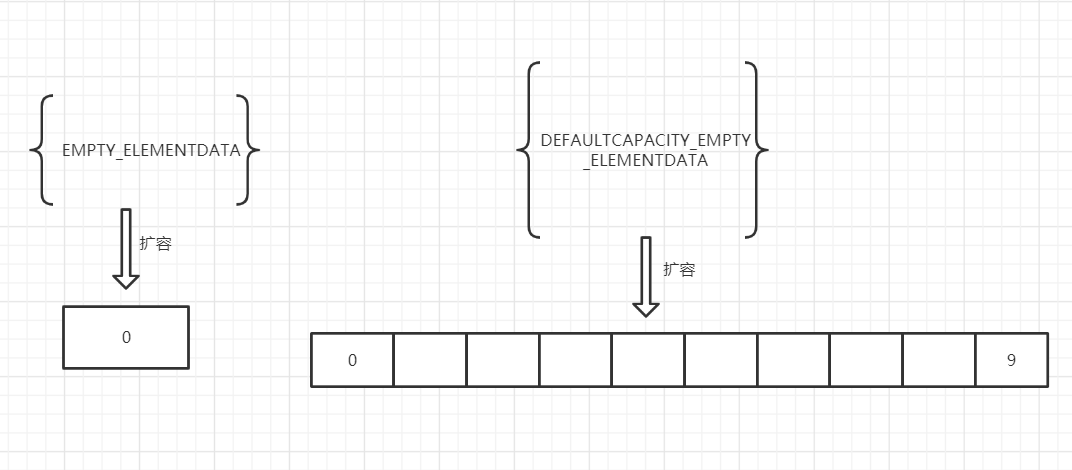
private static final Object[] EMPTY_ELEMENTDATA = {};
默认空数组大小。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
默认初始化空数组大小。
看到这可能有人会有疑问,同样是空数组,为什么要有两个引用变量来表示呢?且看后面的扩容机制说明。
transient Object[] elementData;
这就是ArrayList所维护的用于存储数据的数组了,transient标明这个存储数据的数组不会被序列化,而ArrayList却又打上了标记接口java.io.Serializable说明是可序列化的,这不是自相矛盾了吗?暂且按下不表,看看ArrayList的内部机制再回头说明。
private int size;
ArrayList的大小(其实也就是其中包含的元素个数)。
构造方法:
//传入了初始值的
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
//没有传入初始值的
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//传入一个Collection集合的
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}可以看到,如果传入了初始值initialCapacity,就会按照这个值来初始化数组的大小。如果传入0,则数组等于EMPTY_ELEMENTDATA,如果用了空参构造,则数组等于DEFAULTCAPACITY_EMPTY_ELEMENTDATA。
扩容机制:
我们知道,Java中数组一旦定义则长度是不允许改变的,那么ArrayList如何实现_Resizable-array implementation(可调整大小的数组实现)?_
答案就在扩容机制上:
//传入最小所需要的容量
private Object[] grow(int minCapacity) {
//当前容量大小
int oldCapacity = elementData.length;
//若当前容量大小大于0且数组创建是不是通过空参构造创建的
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//定义新的最小所需容量
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
//右移一位,类似于除以2
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
//传入当前容量,最小需要增加的容量,首选增长的容量
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {
// assert oldLength >= 0
// assert minGrowth > 0
//将最小所需要增加的容量与首选增长的容量比较,取较大的与当前容量相加
int newLength = Math.max(minGrowth, prefGrowth) + oldLength;
if (newLength - MAX_ARRAY_LENGTH <= 0) {
return newLength;
}
return hugeLength(oldLength, minGrowth);
}我们每次添加元素的时候,都会去确认一下当前ArrayList所维护的数组存储的元素是否已经达到上限(元素个数等于数组长度)?如果是的话,就会触发扩容机制grow()去创建一个新的更大的数组来转移数据。
可以看到,若是我们通过传入参数0来构造ArrayList,grow()就会判断出来这个是一个长度为0的自定义空数组,那么就会按照最小的所需要的容量扩容。
如果没有传入参数,就用默认初始容量10,来创建初始的数组。
而且我们可以看到,扩容的时候会判断所需要的最小容量是不是比当前数组的1.5倍还大?不是就按照当前数组长度的1.5倍来扩容,否则就按传进来的最小所需容量来扩容。
为什么是1.5倍呢?
1.如果一次性扩容扩得太大,必然造成内存空间的浪费。
2.如果一次性扩容扩得不够,那么下一次扩容的操作必然比较快地会到来,这会降低程序运行效率,要知道扩容还是比较耗费性能的一个操作,因为会新建数组移动数据。
所以扩容扩多少,是JDK开发人员在时间、空间上做的一个权衡,提供出来的一个比较合理的数值。
添加元素:
//添加单个元素,默认添加到集合尾
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
//实际调用的方法
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
//添加另一个集合,默认添加到集合尾
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
Object[] elementData;
final int s;
if (numNew > (elementData = this.elementData).length - (s = size))
elementData = grow(s + numNew);
//5个参数的意思分别是:源数组,源数组开始复制的位置,目标数组,目标数组开始接收的位置,接收的长度
System.arraycopy(a, 0, elementData, s, numNew);
size = s + numNew;
return true;
}基本上很浅显易懂,只要容量够就能直接添加,否则得扩容。
其中modCount是用于快速失败的一种机制,因为基本集合在多线程环境下是不安全的,这个以后再讨论。
删除元素:
//按元素删除
public boolean remove(Object o) {
final Object[] es = elementData;
final int size = this.size;
int i = 0;
//标签旧方法,用于跳出多个循环
found: {
if (o == null) {
for (; i < size; i++)
if (es[i] == null)
break found;
} else {
for (; i < size; i++)
if (o.equals(es[i]))
break found;
}
return false;
}
fastRemove(es, i);
return true;
}
//按索引删除
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}
//实际执行方法
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
es[size = newSize] = null;
}分两种情况,一种是按照传入的元素去删除,这样得从数组开头遍历过去并且逐一调用equals方法比较,只要找到第一个符合的就将其删除。
第二种是按照传入的索引去删除,这个可以直接定位。另外需要注意的一点是当ArrayList里存储的是Integer包装类的时候,依然是选择索引删除。
删除的意思是将数组此位置的元素的引用设置为null,如果没有另外的引用指向此元素,那么此元素就会被标记为垃圾被回收。
如果删除的元素在最后就不用移动元素了,如果不在就需要移动元素。

插入元素:
public void add(int index, E element) {
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if ((s = size) == (elementData = this.elementData).length)
elementData = grow();
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
elementData[index] = element;
size = s + 1;
}先判断容量是否足够,再去将此位置以及后面的元素全部向后移动一位,最后将传入的元素插入此位置。
最后说明:
了解了ArrayList的各种机制,我们就能知道为什么存储元素的elementData用transient修饰了
//序列化
@java.io.Serial
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioral compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
//反序列化
@java.io.Serial
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// like clone(), allocate array based upon size not capacity
SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Object[].class, size);
Object[] elements = new Object[size];
// Read in all elements in the proper order.
for (int i = 0; i < size; i++) {
elements[i] = s.readObject();
}
elementData = elements;
} else if (size == 0) {
elementData = EMPTY_ELEMENTDATA;
} else {
throw new java.io.InvalidObjectException("Invalid size: " + size);
}
}其实主要是看里边的两个循环的方法,涉及到的是size。我们已经了解了存放元素的数组会动态的改变,因此里边未必就存满了元素。真正有多少个元素是size负责的。所以我们序列化的时候仅仅去遍历size个对象就能完成序列化了。这样就能避免序列化太多不需要的东西,加快序列化速度以及减小文件大小。
“怎么深入理解ArrayList源码”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4829153/blog/4728633



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



