本篇内容主要讲解“JVM的基础知识总结”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“JVM的基础知识总结”吧!
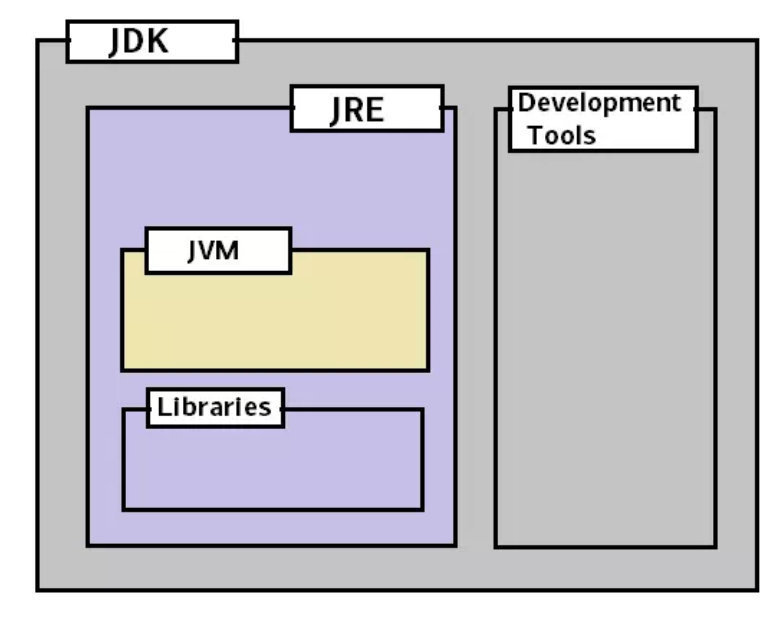
JDK(Java Development Kit) 是用于开发 Java 应用程序的软件开发工具集合,包括 了 Java 运行时的环境(JRE)、解释器(Java)、编译器(javac)、Java 归档 (jar)、文档生成器(Javadoc)等工具。简单的说我们要开发Java程序,就需要安装某个版本的JDK工具包。
JRE(Java Runtime Enviroment )提供 Java 应用程序执行时所需的环境,由 Java 虚拟机(JVM)、核心类、支持文件等组成。简单的说,我们要是想在某个机器上运 行Java程序,可以安装JDK,也可以只安装JRE,后者体积比较小。
Java Virtual Machine(Java 虚拟机)有三层含义,分别是:
JVM规范要求
满足 JVM 规范要求的一种具体实现(一种计算机程序)
一个 JVM 运行实例,在命令提示符下编写 Java 命令以运行 Java 类时,都会创建一 个 JVM 实例,我们下面如果只记到JVM则指的是这个含义;如果我们带上了某种JVM 的名称,比如说是Zing JVM,则表示上面第二种含义
就范围来说,JDK > JRE > JVM:
JDK = JRE + 开发工具
JRE = JVM + 类库
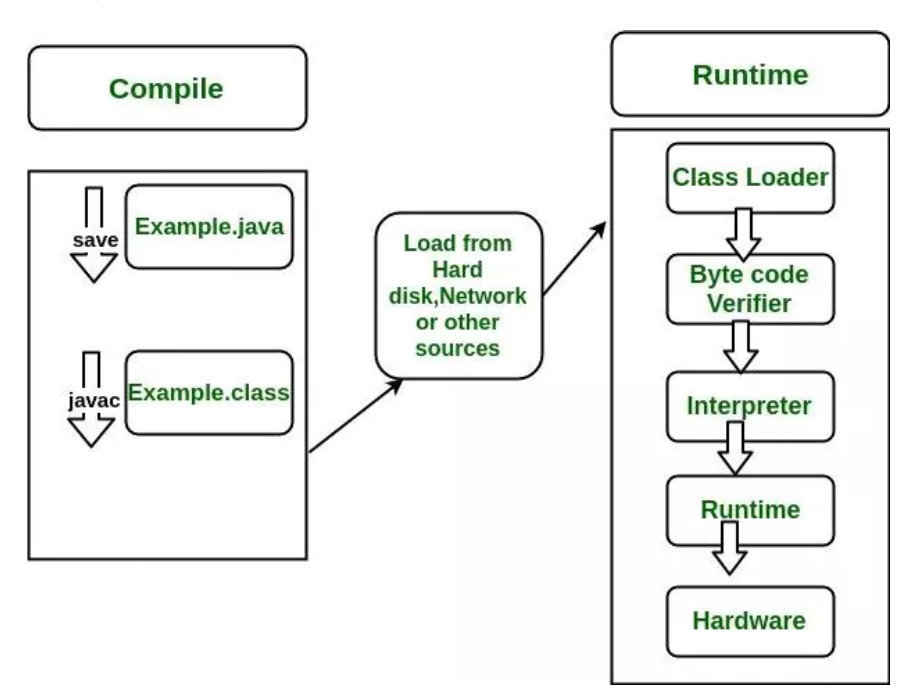
Java程序的开发运行过程为:
我们利用 JDK (调用 Java API)开发Java程序,编译成字节码或者打包程序 然后可以用 JRE 则启动一个JVM实例,加载、验证、执行 Java 字节码以及依赖库, 运行Java程序。
而JVM 将程序和依赖库的Java字节码解析并变成本地代码执行,产生结果 。
最简单/最麻烦的查询方式是询问相关人员。
查找的方式很多,比如,可以使用 which , whereis , ls ‐l 跟踪软连接, 或者 find 命令全局查找(可能需要sudo权限), 例如:
jps ‐v
whereis javac
ls ‐l /usr/bin/javac
find / ‐name javac
> 没有量化就没有改进
分析系统性能问题: 比如是不是达到了我们预期性能指标,判断资源层面有没有问题,JVM层面有没有问题,系统的关键处理流程有没有问题,业务流程是否需要优化
通过工具收集系统的状态,日志,包括打点做内部的指标收集,监控并得出关键性能指标数据,也包括进行压测,得到一些相关的压测数据和性能内部分析数据
根据分析结果和性能指标,进行资源配置调整,并持续进行监控和分析,以优化性能,直到满足系统要求,达到系统的最佳性能状态
CPU:CPU是系统最关键的计算资源,在单位时间内有限,也是比较容易由于业务逻辑处理不合理而出现瓶颈的地方,浪费了CPU资源和过渡消耗CPU资源都不 是理想状态,我们需要监控相关指标;
内存:内存则对应程序运行时直接可使用的数据快速暂存空间,也是有限的,使用过程随着时间的不断的申请内存又释放内存,好在JVM的GC帮我们处理了这些事情,但是如果GC配置的不合理,一样会在一定的时间后,产生包括OOM宕 机之类的各种问题,所以内存指标也需要关注;
IO(存储+网络):CPU在内存中把业务逻辑计算以后,为了长期保存,就必须通过磁盘存储介质持久化,如果多机环境、分布式部署、对外提供网络服务能 力,那么很多功能还需要直接使用网络,这两块的IO都会比CPU和内存速度更慢,所以也是我们关注的重点。
性能优化一般要存在瓶颈问题,而瓶颈问题都遵循80/20原则。既我们把所有的整个处理过程中比较慢的因素都列一个清单,并按照对性能的影响排序,那么前20%的瓶颈问题,至少会对性能的影响占到80%比重。换句话说,我们优先解决了最重要的几个问题,那么性能就能好一大半。
我们一般先排查基础资源是否成为瓶颈。看资源够不够,只要成本允许,加配置可能是最快速的解决方案,还可能是最划算,最有效的解决方案。 与JVM有关的系统资源,主要是 CPU 和 内存 这两部分。 如果发生资源告警/不足, 就需要评估系统容量,分析原因。
一般衡量系统性能的维度有3个:
延迟(Latency): 一般衡量的是响应时间(Response Time),比如平均响应时间。 但是有时候响应时间抖动的特别厉害,也就是说有部分用户的响应时间特别高, 这时我们一般假设我们要保障95%的用户在可接受的范围内响应,从而提供绝大多数用户具有良好的用户体验,这就是延迟的95线(P95,平均100个用户请求中95个已经响应的时间),同理还有99线,最大响应时间等(95线和99线比较常用;用户访问量大的时候,对网络有任何抖动都可能会导致最大响应时间变得非常大,最大响应时间这个指标不可控,一般不用)。
吞吐量(Throughput): 一般对于交易类的系统我们使用每秒处理的事务数(TPS) 来衡量吞吐能力,对于查询搜索类的系统我们也可以使用每秒处理的请求数 (QPS)。
系统容量(Capacity): 也叫做设计容量,可以理解为硬件配置,成本约束。
性能指标还可分为两类:
业务需求指标:如吞吐量(QPS、TPS)、响应时间(RT)、并发数、业务成功率等。
资源约束指标:如CPU、内存、I/O等资源的消耗情况。
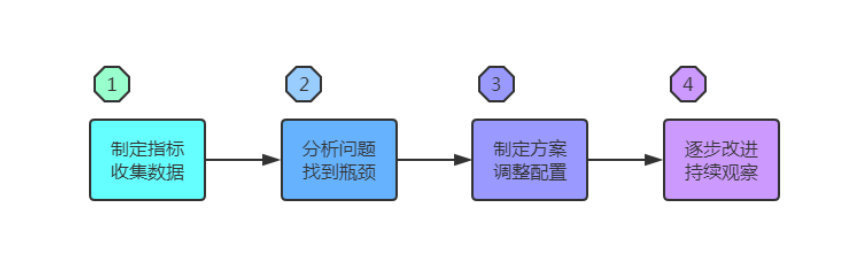
性能调优的第一步是制定指标,收集数据,第二步是找瓶颈,然后分析解决瓶颈问题。通过这些手段,找当前的性能极限值。压测调优到不能再优化了的 TPS和QPS, 就是极限值。知道了极限值,我们就可以按业务发展测算流量和系统压力,以此做容量规划,准备机器资源和预期的扩容计划。最后在系统的日常运行过程中,持续观察,逐步重做和调整以上步骤,长期改善改进系统性能。
我们经常说“ 脱离场景谈性能都是耍流氓 ”,实际的性能分析调优过程中,我们需要根据具体的业务场景,综合考虑成本和性能,使用最合适的办法去处理。系统的性能优化到3000TPS如果已经可以在成本可以承受的范围内满足业务发展的需求,那么再花几个人月优化到3100TPS就没有什么意义,同样地如果花一倍成本去优化到5000TPS 也没有意义。
Donald Knuth曾说过“ 过早的优化是万恶之源 ”,我们需要考虑在恰当的时机去优化系统。在业务发展的早期,量不大,性能没那么重要。我们做一个新系统,先考虑整体设计是不是OK,功能实现是不是OK,然后基本的功能都做得差不多的时候(当然整体的框架是不是满足性能基准,可能需要在做项目的准备阶段就通过POC(概念证明)阶段验证。),最后再考虑性能的优化工作。因为如果一开始就考虑优化,就可 能要想太多导致过度设计了。而且主体框架和功能完成之前,可能会有比较大的改动,一旦提前做了优化,可能这些改动导致原来的优化都失效了,又要重新优化,多做了很多无用功。
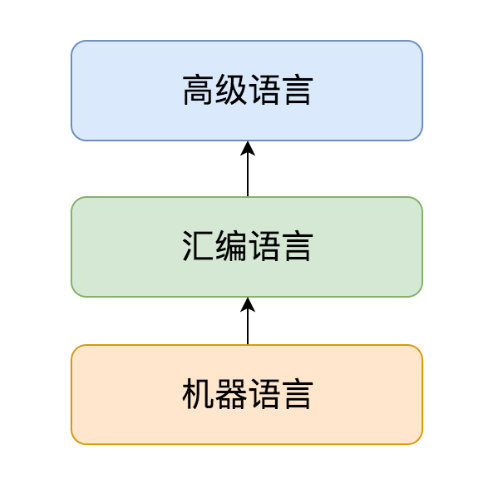
首先,我们可以把形形色色的编程从底向上划分为最基本的三大类:机器语言、汇编 语言、高级语言。
按《计算机编程语言的发展与应用》一文里的定义:计算机编程语言能够实现人与机器之间的交流和沟通,而计算机编程语言主要包括汇编语言、机器语言以及高级语言,具体内容如下:
机器语言:这种语言主要是利用二进制编码进行指令的发送,能够被计算机快速地识别,其灵活性相对较高,且执行速度较为可观,机器语言与汇编语言之间的相似性较高,但由于具有局限性,所以在使用上存在一定的约束性。
汇编语言:该语言主要是以缩写英文作为标符进行编写的,运用汇编语言进行编 写的一般都是较为简练的小程序,其在执行方面较为便利,但汇编语言在程序方面较为冗长,所以具有较高的出错率。
高级语言:所谓的高级语言,其实是由多种编程语言结合之后的总称,其可以对多条指令进行整合,将其变为单条指令完成输送,其在操作细节指令以及中间过 程等方面都得到了适当的简化,所以,整个程序更为简便,具有较强的操作性, 而这种编码方式的简化,使得计算机编程对于相关工作人员的专业水平要求不断放宽。
如果按照有没有虚拟机来划分,高级编程语言可分为两类:
有虚拟机:Java,Lua,Ruby,部分JavaScript的实现等等
无虚拟机:C,C++,C#,Golang,以及大部分常见的编程语言
如果按照变量是不是有确定的类型,还是类型可以随意变化来划分,高级编程语言可 以分为:
静态类型:Java,C,C++等等
动态类型:所有脚本类型的语言
如果按照是编译执行,还是解释执行,可以分为:
编译执行:C,C++,Golang,Rust,C#,Java,Scala,Clojure,Kotlin, Swift...等等
解释执行:JavaScript的部分实现和NodeJS,Python,Perl,Ruby...等等
此外,我们还可以按照语言特点分类:
面向过程:C,Basic,Pascal,Fortran等等
面向对象:C++,Java,Ruby,Smalltalk等等
函数式编程:LISP、Haskell、Erlang、OCaml、Clojure、F#等等
有的甚至可以划分为纯面向对象语言,例如Ruby,所有的东西都是对象(Java不是所有东西都是对象,比如基本类型 int 、 long 等等,就不是对象,但是它们的包装 类 Integer 、 Long 则是对象)。 还有既可以当做编译语言又可以当做脚本语言的,例如Groovy等语言。
现在我们聊聊跨平台,为什么要跨平台,因为我们希望所编写的代码和程序,在源代 码级别或者编译后,可以运行在多种不同的系统平台上,而不需要为了各个平台的不 同点而去实现两套代码。典型地,我们编写一个web程序,自然希望可以把它部署到 Windows平台上,也可以部署到Linux平台上,甚至是MacOS系统上。 这就是跨平台的能力,极大地节省了开发和维护成本,赢得了商业市场上的一致好评。
这样来看,一般来说解释型语言都是跨平台的,同一份脚本代码,可以由不同平台上的解释器解释执行。但是对于编译型语言,存在两种级别的跨平台: 源码跨平台和二进制跨平台。
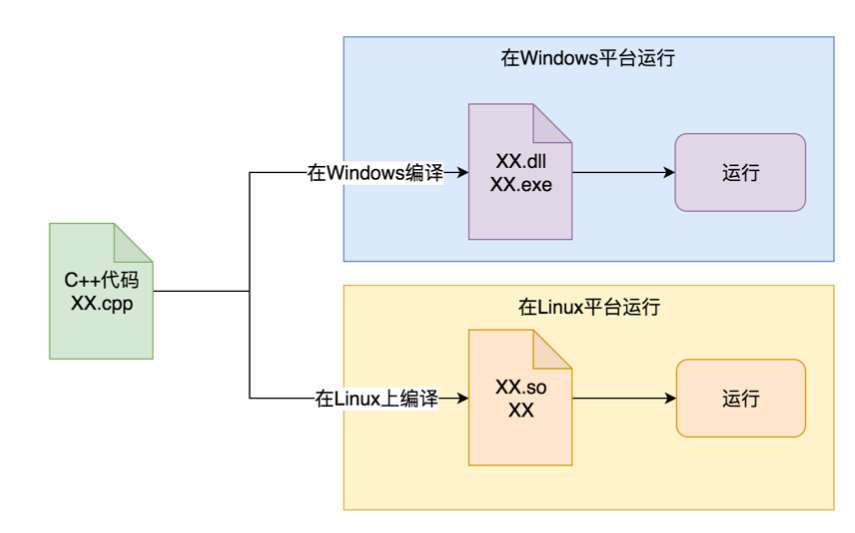
1、典型的源码跨平台(C++):
2、典型的二进制跨平台(Java字节码):
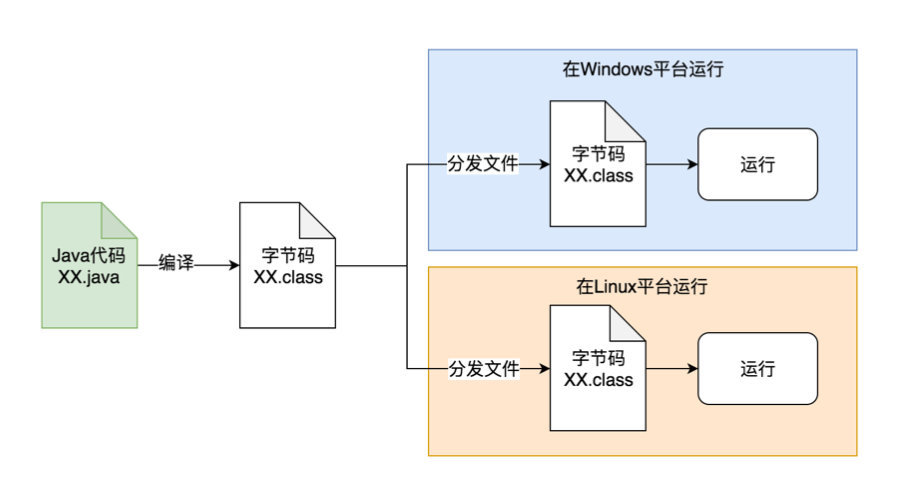
可以看到,C++里我们需要把一份源码,在不同平台上分别编译,生成这个平台相关的二进制可执行文件,然后才能在相应的平台上运行。 这样就需要在各个平台都有开发工具和编译器,而且在各个平台所依赖的开发库都需要是一致或兼容的。 这一点在过去的年代里非常痛苦,被戏称为 “依赖地狱”。 C++的口号是“一次编写,到处(不同平台)编译”,但实际情况上是一编译就报错,变 成了 “一次编写,到处调试,到处找依赖、改配置”。 大家可以想象,你编译一份代 码,发现缺了几十个依赖,到处找还找不到,或者找到了又跟本地已有的版本不兼 容,这是一件怎样令人绝望的事情。
而Java语言通过虚拟机技术率先解决了这个难题。 源码只需要编译一次,然后把编译 后的class文件或jar包,部署到不同平台,就可以直接通过安装在这些系统中的JVM上 面执行。 同时可以把依赖库(jar文件)一起复制到目标机器,慢慢地又有了可以在各个平台都直接使用的Maven中央库(类似于linux里的yum或aptget源,macos里的 homebrew,现代的各种编程语言一般都有了这种包依赖管理机制:python的pip, dotnet的nuget,NodeJS的npm,golang的dep,rust的cargo等等)。这样就实现了 让同一个应用程序在不同的平台上直接运行的能力。
总结一下跨平台:
脚本语言直接使用不同平台的解释器执行,称之为脚本跨平台,平台间的差异由 不同平台上的解释器去解决。这样的话代码很通用,但是需要解释和翻译,效率较低。
编译型语言的代码跨平台,同一份代码,需要被不同平台的编译器编译成相应的二进制文件,然后再去分发和执行,不同平台间的差异由编译器去解决。编译产 生的文件是直接针对平台的可执行指令,运行效率很高。但是在不同平台上编译 复杂软件,依赖配置可能会产生很多环境方面问题,导致开发和维护的成本较 高。
编译型语言的二进制跨平台,同一份代码,先编译成一份通用的二进制文件,然后分发到不同平台,由虚拟机运行时来加载和执行,这样就会综合另外两种跨平台语言的优势,方便快捷地运行于各种平台,虽然运行效率可能比起本地编译类 型语言要稍低一点。 而这些优缺点也是Java虚拟机的优缺点。
我们前面提到了很多次 Java运行时 和 JVM虚拟机 ,简单的说JRE就是Java的运行 时,包括虚拟机和相关的库等资源。 可以说运行时提供了程序运行的基本环境,JVM在启动时需要加载所有运行时的核心库等资源,然后再加载我们的应用程序字节码,才能让应用程序字节码运行在JVM这 个容器里。
但也有一些语言是没有虚拟机的,编译打包时就把依赖的核心库和其他特性支持,一 起静态打包或动态链接到程序中,比如Golang和Rust,C#等。 这样运行时就和程序指令组合在一起,成为了一个完整的应用程序,好处就是不需要虚拟机环境,坏处是编译后的二进制文件没法直接跨平台了。
内存管理就是内存的生命周期管理,包括内存的申请、压缩、回收等操作。 Java的内存管理就是GC,JVM的GC模块不仅管理内存的回收,也负责内存的分配和压缩整理。
Java中的字节码,英文名为 bytecode , 是Java代码编译后的中间代码格式。JVM需要读取并解析字节码才能执行相应的任务。 由单字节( byte )的指令组成, 理论上最多支持 256 个操作码(opcode)。实际上Java只使用了200左右的操作码, 还有一些操作码则保留给调试操作。
操作码, 下面称为指令 , 主要由类型前缀和操作名称两部分组成。
> 例如,' i ' 前缀代表 ‘ integer ’,所以,' iadd ' 很容易理解, 表示对整数执行加法运算。
栈操作指令,包括与局部变量交互的指令
程序流程控制指令
对象操作指令,包括方法调用指令
算数运算以及类型转换指令
此外还有一些执行专门任务的指令,比如同步(synchronization)指令,以及抛出异常相关的指令等等
我们都知道 new 是Java编程语言中的一个关键字, 但其实在字节码中,也有一个指令叫做 new 。 当我们创建类的实例时, 编译器会生成类似下面这样的操作码:
```
0: new #2 // class demo/jvm0104/HelloByteCode
3: dup
4: invokespecial #3 // Method "<init>":()V
```当你同时看到 new, dup 和 invokespecial 指令在一起时,那么一定是在创建类的实例对象! 为什么是三条指令而不是一条呢?这是因为:
new 指令只是创建对象,但没有调用构造函数。
invokespecial 指令用来调用某些特殊方法的, 当然这里调用的是构造函数。
dup 指令用于复制栈顶的值。
由于构造函数调用不会返回值,所以如果没有dup指令, 在对象上调用方法并初始化之后,操作数栈就会是空的,在初始化之后就会出问题, 接下来的代码就无法对其进行处理。
在调用构造函数的时候,其实还会执行另一个类似的方法 <init> ,甚至在执行构造函数之前就执行了。还有一个可能执行的方法是该类的静态初始化方法 <clinit> ,但 <clinit> 并不能被直接调用,而是由这些指令触发的: new , getstatic , putstatic or invokestatic。
有很多指令可以操作方法栈。 前面也提到过一些基本的栈操作指令: 他们将值压入栈,或者从栈中获取值。 除了这些基础操作之外也还有一些指令可以操作栈内存; 比如 swap 指令用来交换栈顶两个元素的值。下面是一些示例:
最基础的是 dup 和 pop 指令。
dup 指令复制栈顶元素的值。
pop 指令则从栈中删除最顶部的值。
还有复杂一点的指令:比如, swap , dup_x1 和 dup2_x1 。
顾名思义, swap 指令可交换栈顶两个元素的值,例如A和B交换位置(图中示例 4);
dup_x1 将复制栈顶元素的值,并在插入在最上面两个值后(图中示例5);
dup2_x1 则复制栈顶两个元素的值,并插入最上面三个值后(图中示例6)。
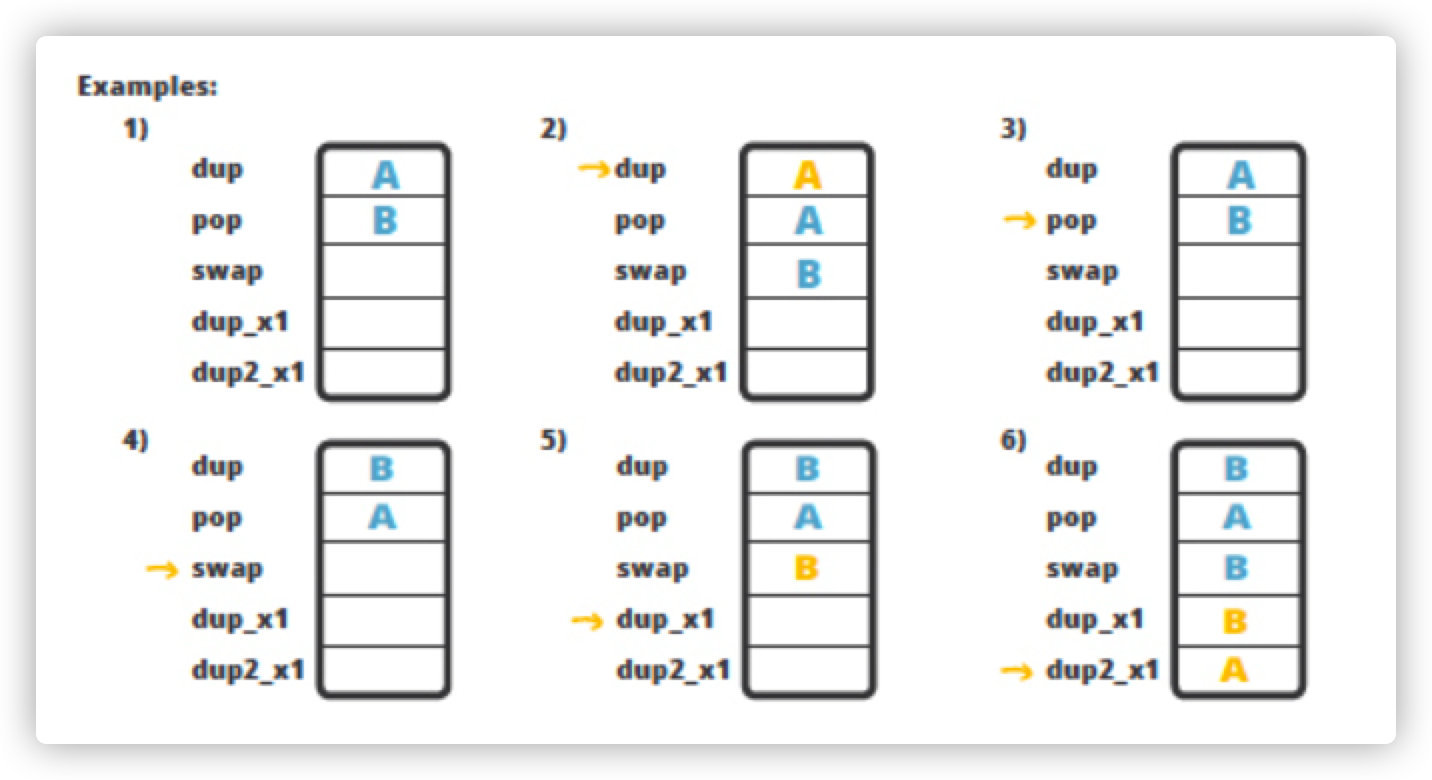
dup , dup_x1 , dup2_x1 指令补充说明 :
dup 指令:官方说明是,复制栈顶的值, 并将复制的值压入栈.
dup_x1 指令 : 官方说明是,复制栈顶的值, 并将复制的值插入到最上面2个值的下方。
dup2_x1 指令: 官方说明是,复制栈顶 1个64位/或2个32位的值, 并将复制的值按照原始顺序,插入原始值下面一个32位值的下方。
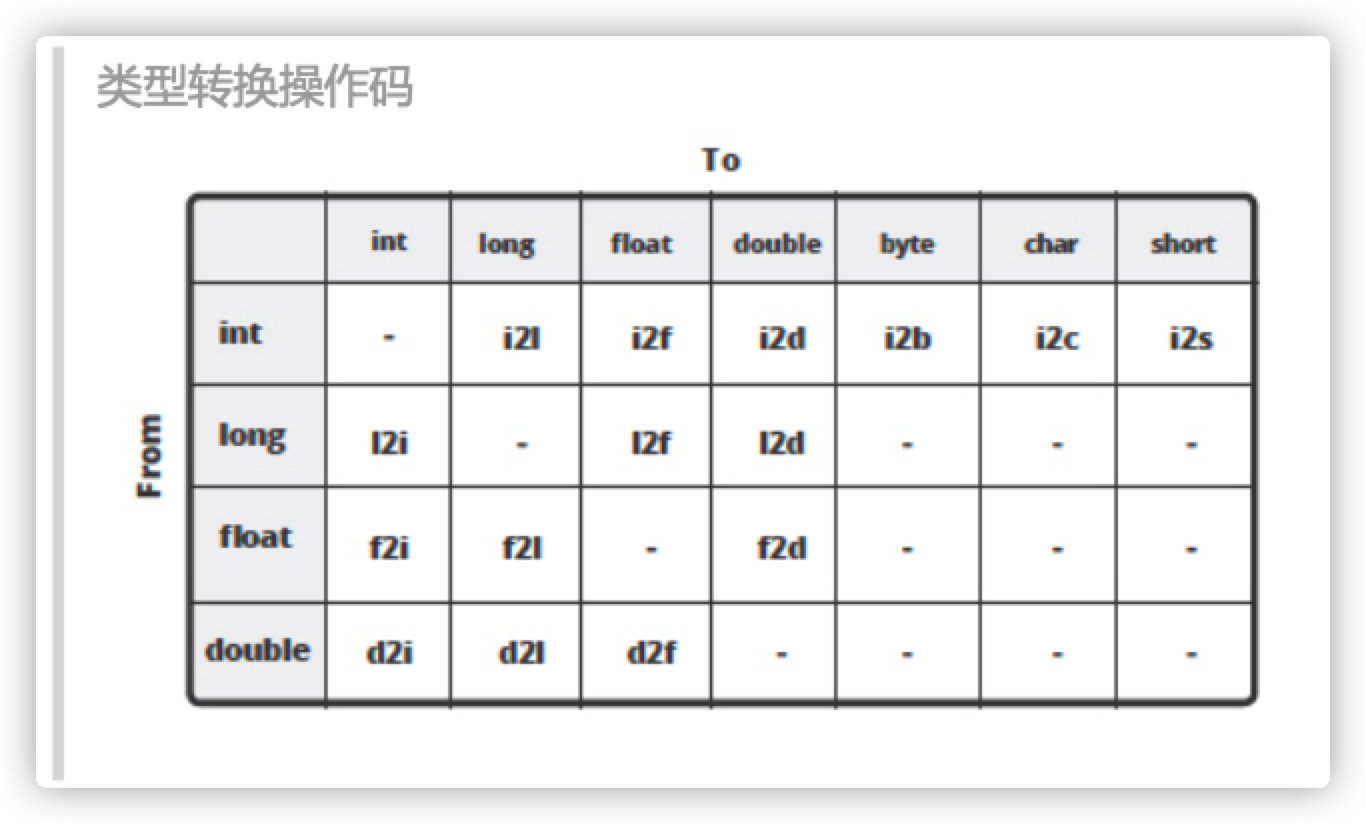
Java字节码中有许多指令可以执行算术运算。实际上,指令集中有很大一部分表示都是关于数学运算的。对于所有数值类型( int , long , double , float ),都有加, 减,乘,除,取反的指令。 那么 byte 和 char , boolean 呢? JVM 是当做 int 来处理的。另外还有部分指令用于数据类型之间的转换。
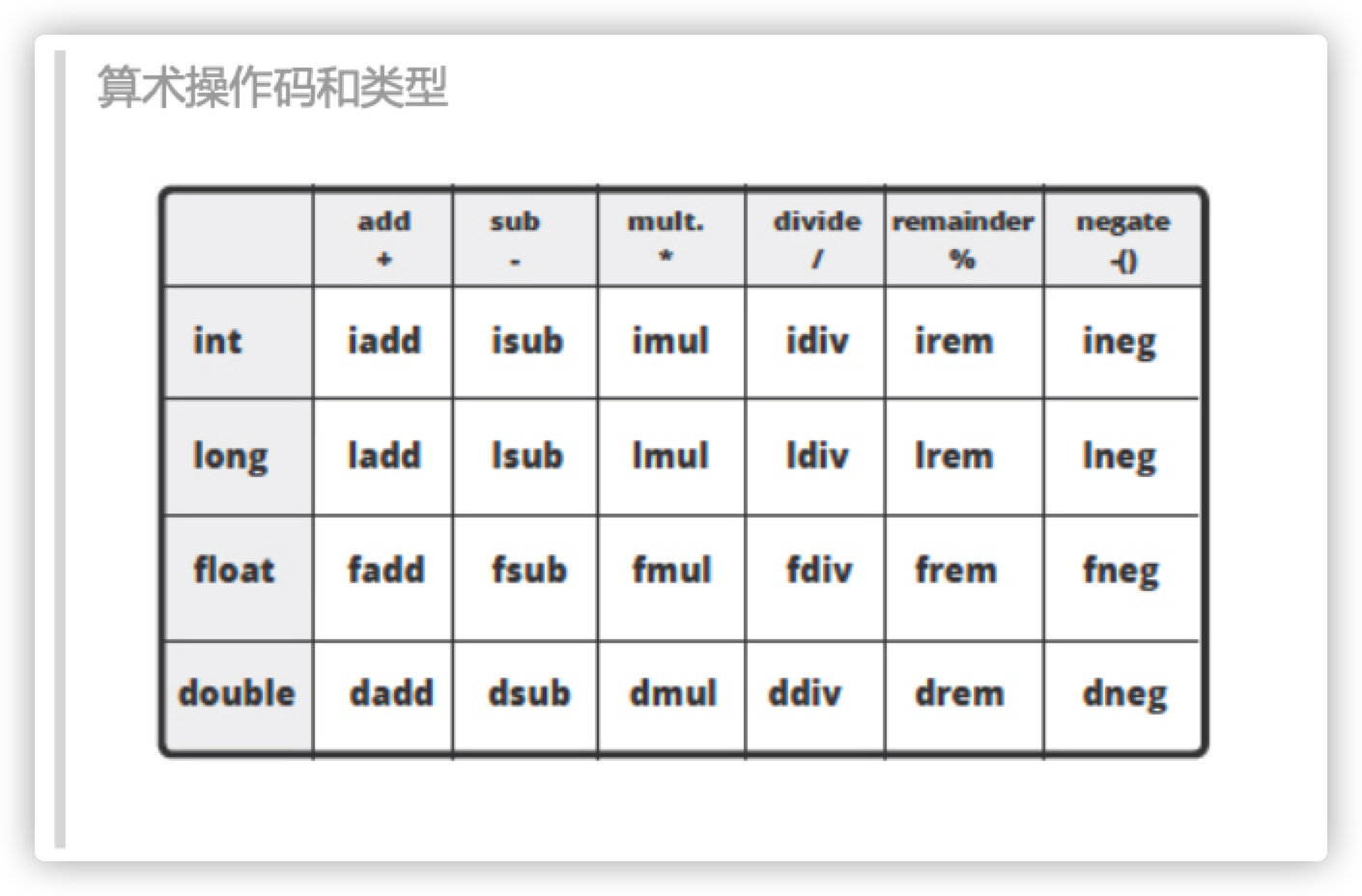
当我们想将 int 类型的值赋值给 long 类型的变量时,就会发生类型转换。
invokestatic ,顾名思义,这个指令用于调用某个类的静态方法,这也是方法调用指令中最快的一个。
invokespecial , 我们已经学过了, invokespecial 指令用来调用构造函数, 但也可以用于调用同一个类中的 private 方法, 以及可见的超类方法。
invokevirtual ,如果是具体类型的目标对象, invokevirtual 用于调用公共,受保护和打包私有方法。
invokeinterface ,当要调用的方法属于某个接口时,将使用invokeinterface 指令。
> 那么 invokevirtual 和 invokeinterface 有什么区别呢?这确实是个好问 题。 为什么需要 invokevirtual 和 invokeinterface 这两种指令呢? 毕竟 所有的接口方法都是公共方法, 直接使用 invokevirtual 不就可以了吗? 这么做是源于对方法调用的优化。JVM必须先解析该方法,然后才能调用它
使用 invokestatic 指令,JVM就确切地知道要调用的是哪个方法:因为调用的是静态方法,只能属于一个类。
使用 invokespecial 时, 查找的数量也很少, 解析也更加容易,那么运行时就能更快地找到所需的方法。
ava虚拟机的字节码指令集在JDK7之前一直就只有前面提到的4种指令 (invokestatic,invokespecial,invokevirtual,invokeinterface)。随着JDK 7的发 布,字节码指令集新增了 invokedynamic 指令。这条新增加的指令是实现“动态类型 语言”(Dynamically Typed Language)支持而进行的改进之一,同时也是JDK 8以后 支持的lambda表达式的实现基础。
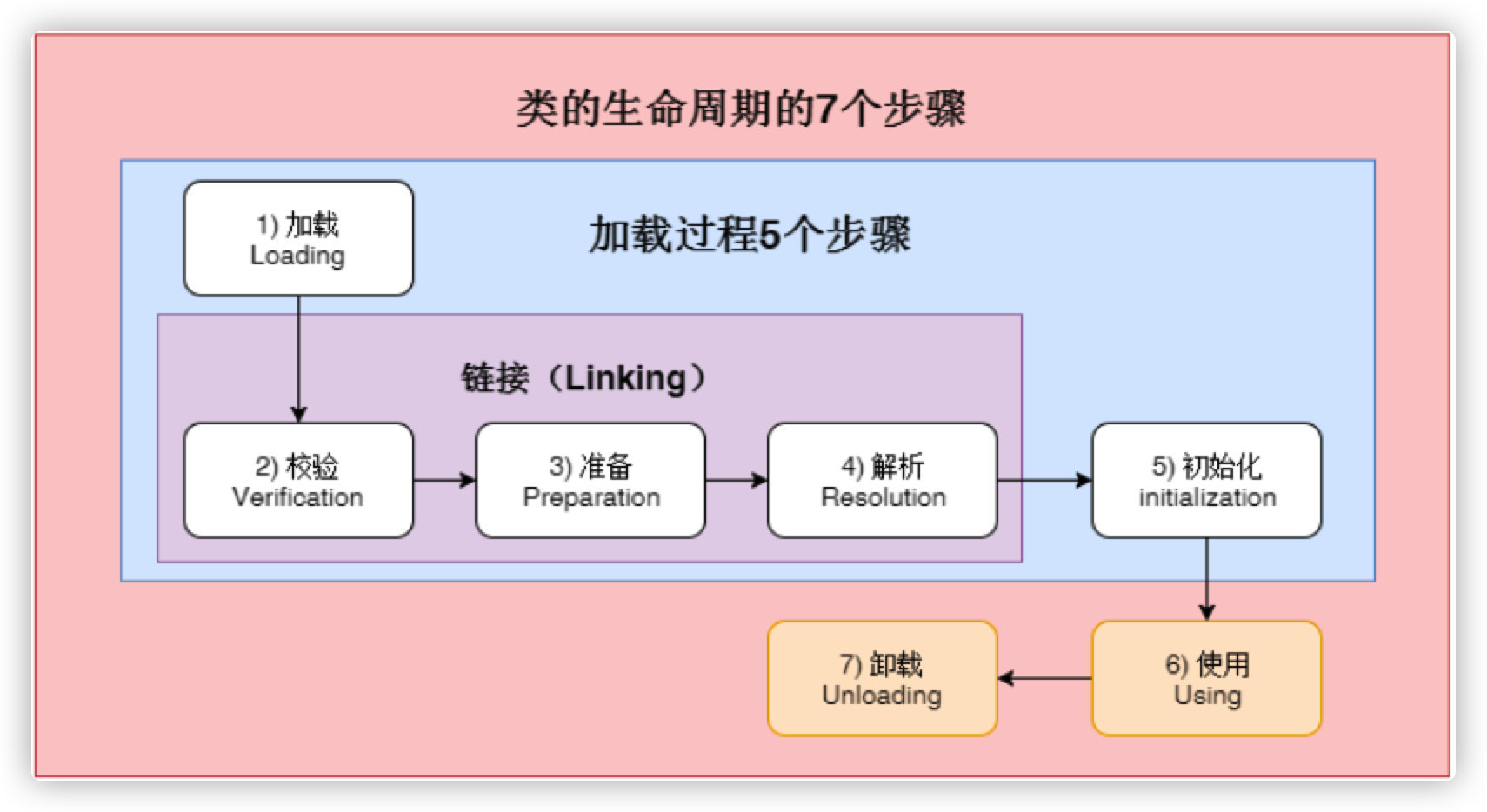
一个类在JVM里的生命周期有7个阶段,分别是加载(Loading)、验证 (Verification)、准备(Preparation)、解析(Resolution)、初始化 (Initialization)、使用(Using)、卸载(Unloading)。 其中前五个部分(加载,验证,准备,解析,初始化)统称为类加载,下面我们就分 别来说一下这五个过程。
加载阶段也可以称为“装载”阶段。 这个阶段主要的操作是: 根据明确知道的class完全限定名, 来获取二进制classfile格式的字节流,简单点说就是 找到文件系统中/jar包中/或存在于任何地方的“ class文件 ”。 如果找不到二进制表示形式,则会抛出NoClassDefFound 错误。装载阶段并不会检查 classfile 的语法和格式。类加载的整个过程主要由JVM和Java 的类加载系统共同完成, 当然具体到loading 阶 段则是由JVM与具体的某一个类加载器(java.lang.classLoader)协作完成的。
链接过程的第一个阶段是校验 ,确保class文件里的字节流信息符合当前虚拟机的要求,不会危害虚拟机的安全。校验过程检classfile 的语义,判断常量池中的符号,并执行类型检查, 主要目的是判断字节码的合法性,比如 magic number, 对版本号进行验证。 这些检查 过程中可能会抛出 VerifyError , ClassFormatError 或 UnsupportedClassVersionError 。 因为classfile的验证属是链接阶段的一部分,所以这个过程中可能需要加载其他类, 在某个类的加载过程中,JVM必须加载其所有的超类和接口。 如果类层次结构有问题(例如,该类是自己的超类或接口,死循环了),则JVM将抛出 ClassCircularityError 。 而如果实现的接口并不是一个 interface,或者声明的超类是一个 interface,也会抛出 IncompatibleClassChangeError 。
然后进入准备阶段,这个阶段将会创建静态字段, 并将其初始化为标准默认值(比如 null 或者 0值 ),并分配方法表,即在方法区中分配这些变量所使用的内存空间。 请注意,准备阶段并未执行任何Java代码。
例如:
public static int i = 1;在准备阶段 i 的值会被初始化为0,后面在类初始化阶段才会执行赋值为1; 但是下面如果使用final作为静态常量,某些JVM的行为就不一样了:
public static final int i = 1;对应常量i,在准备阶段就会被赋值1,其实这样还是比较puzzle,例如其他语言 (C#)有直接的常量关键字const,让告诉编译器在编译阶段就替换成常量,类似 于宏指令,更简单。
然后进入可选的解析符号引用阶段。 也就是解析常量池,主要有以下四种:类或接口的解析、字段解析、类方法解析、接 口方法解析。
简单的来说就是我们编写的代码中,当一个变量引用某个对象的时候,这个引用在 .class 文件中是以符号引用来存储的(相当于做了一个索引记录)。 在解析阶段就需要将其解析并链接为直接引用(相当于指向实际对象)。如果有了直 接引用,那引用的目标必定在堆中存在。加载一个class时, 需要加载所有的super类和super接口。
JVM规范明确规定, 必须在类的首次“主动使用”时才能执行类初始化。 初始化的过程包括执行:
类构造器方法
static静态变量赋值语句
static静态代码块
如果是一个子类进行初始化会先对其父类进行初始化,保证其父类在子类之前进行初 始化。所以其实在java中初始化一个类,那么必然先初始化过 java.lang.Object 类,因为所有的java类都继承自java.lang.Object。
了解了类的加载过程,我们再看看类的初始化何时会被触发呢?JVM 规范枚举了下述多种触发情况:
当虚拟机启动时,初始化用户指定的主类,就是启动执行的 main方法所在的类;
当遇到用以新建目标类实例的 new 指令时,初始化 new 指令的目标类,就是 new一个类的时候要初始化
当遇到调用静态方法的指令时,初始化该静态方法所在的类;
当遇到访问静态字段的指令时,初始化该静态字段所在的类;
子类的初始化会触发父类的初始化;
如果一个接口定义了 default 方法,那么直接实现或者间接实现该接口的类的初始化,会触发该接口的初始化;
使用反射 API 对某个类进行反射调用时,初始化这个类,其实跟前面一样,反射调用要么是已经有实例了,要么是静态方法,都需要初始化;
当初次调用 MethodHandle 实例时,初始化该 MethodHandle 指向的方法所在的类。
同时以下几种情况不会执行类初始化:
通过子类引用父类的静态字段,只会触发父类的初始化,而不会触发子类的初始化。
定义对象数组,不会触发该类的初始化。
常量在编译期间会存入调用类的常量池中,本质上并没有直接引用定义常量的类,不会触发定义常量所在的类。
通过类名获取Class对象,不会触发类的初始化,Hello.class不会让Hello类初始化。
通过Class.forName加载指定类时,如果指定参数initialize为false时,也不会触发类初始化,其实这个参数是告诉虚拟机,是否要对类进行初始化。 Class.forName(“jvm.Hello”)默认会加载Hello类。
通过ClassLoader默认的loadClass方法,也不会触发初始化动作(加载了,但是不初始化)。
类加载过程可以描述为“通过一个类的全限定名a.b.c.XXClass来获取描述此类的Class 对象”,这个过程由“类加载器(ClassLoader)”来完成。这样的好处在于,子类加载器可以复用父加载器加载的类。系统自带的类加载器分为三种 :
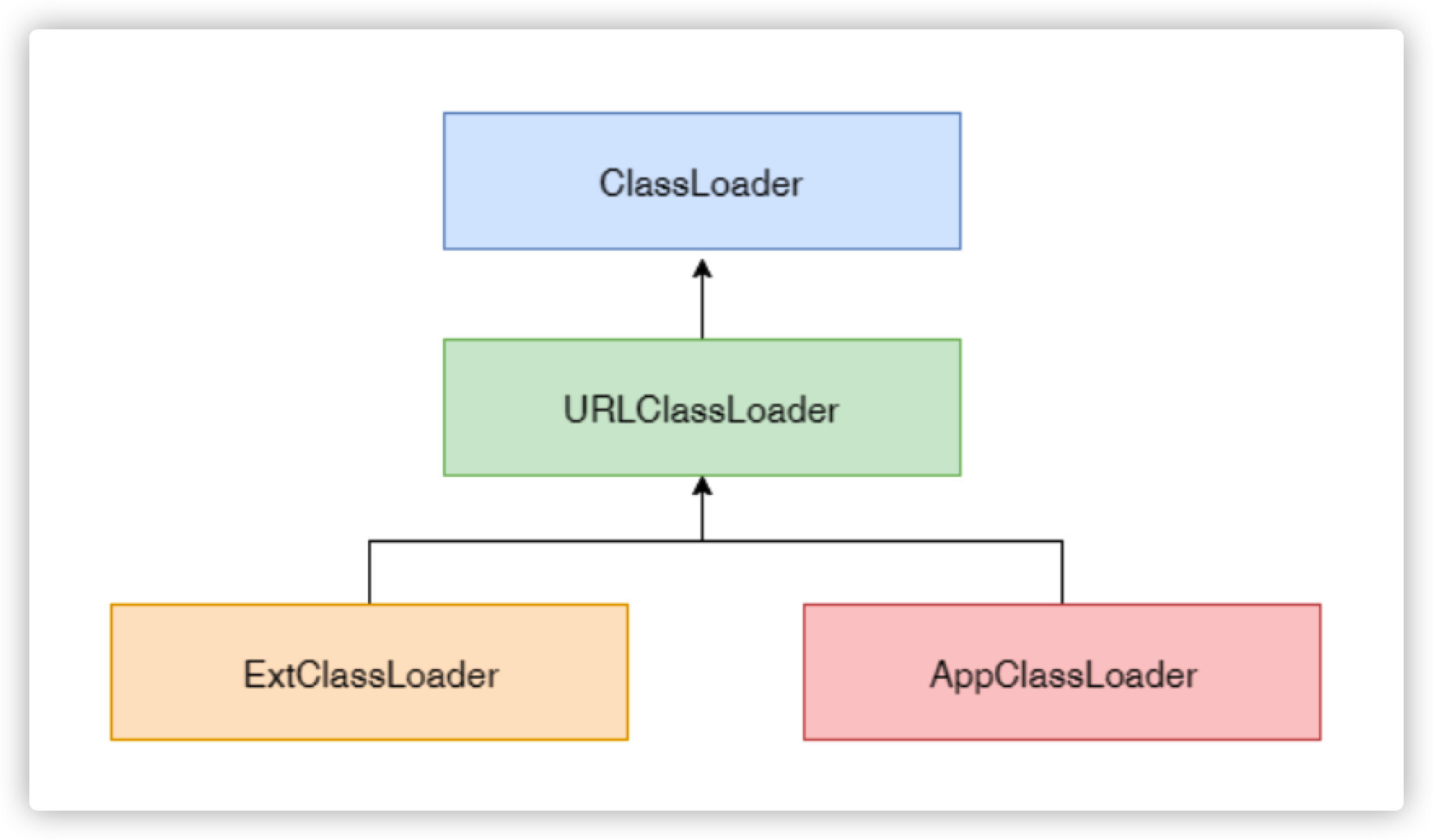
启动类加载器(BootstrapClassLoader)
启动类加载器(bootstrap class loader): 它用来加载 Java 的核心类,是用原生 C++代码来实现的,并不继承自
java.lang.ClassLoader(负责加载JDK中 jre/lib/rt.jar里所有的class)。它可以看做是JVM自带的,我们再代码层面无法直接获取到
启动类加载器的引用,所以不允许直接操作它, 如果打印出来就是个 null 。举例来说,java.lang.String是由启动类加载器加载
的,所以 String.class.getClassLoader()就会返回null。但是后面可以看到可以通过命令行 参数影响它加载什么。
扩展类加载器(ExtClassLoader)
扩展类加载器(extensions class loader):它负责加载JRE的扩展目录,lib/ext 或者由java.ext.dirs系统属性指定的目录中的JAR包的类,代码里直接获取它的父 类加载器为null(因为无法拿到启动类加载器)。
应用类加载器(AppClassLoader)
应用类加载器(app class loader):它负责在JVM启动时加载来自Java命令的classpath或者cp选项、java.class.path系统属性指定的jar包和类路径。在应用程序代码里可以通过ClassLoader的静态方法getSystemClassLoader()来获取应用类加载器。如果没有特别指定,则在没有使用自定义类加载器情况下,用户自定义的类都由此加载器加载。
类加载机制有三个特点:
双亲委托:当一个自定义类加载器需要加载一个类,比如java.lang.String,它很懒,不会一上来就直接试图加载它,而是先委托自己的父加载器去加载,父加载 器如果发现自己还有父加载器,会一直往前找,这样只要上级加载器,比如启动类加载器已经加载了某个类比如java.lang.String,所有的子加载器都不需要自己加载了。如果几个类加载器都没有加载到指定名称的类,那么会抛出 ClassNotFountException异常。
负责依赖:如果一个加载器在加载某个类的时候,发现这个类依赖于另外几个类或接口,也会去尝试加载这些依赖项。
缓存加载:为了提升加载效率,消除重复加载,一旦某个类被一个类加载器加载,那么它会缓存这个加载结果,不会重复加载。
到此,相信大家对“JVM的基础知识总结”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3769077/blog/4694417



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



