groupby中怎么重置索引,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
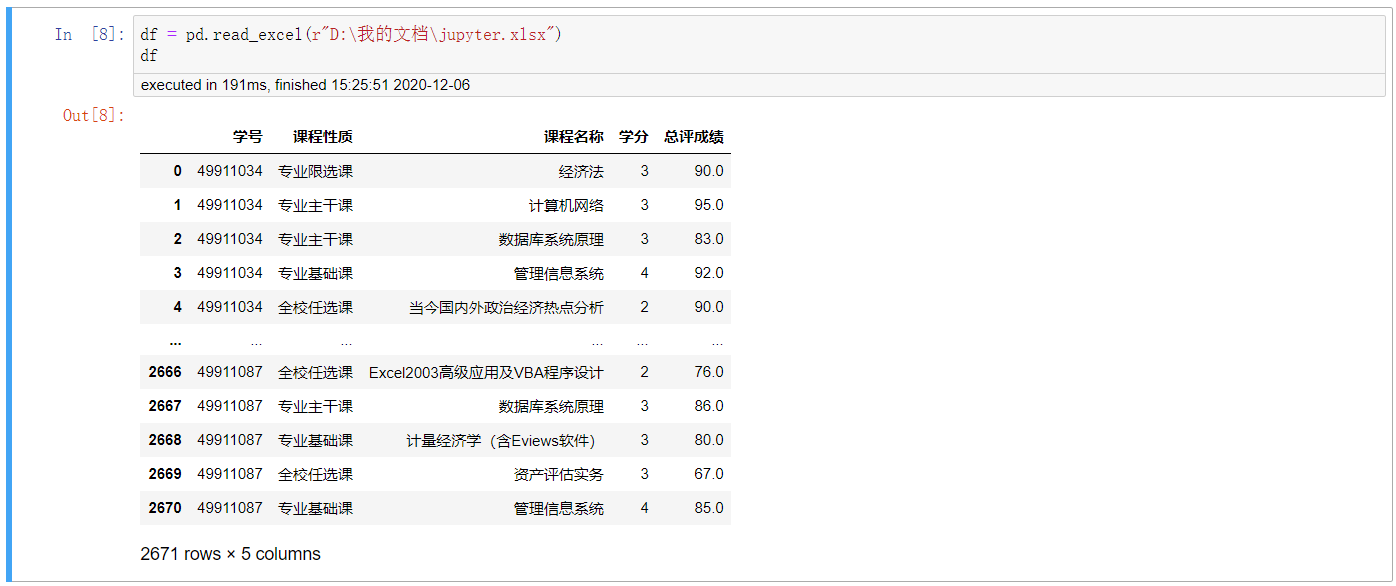
1. 先加载数据
df = pd.read_excel(r"D:\我的文档\jupyter.xlsx") df
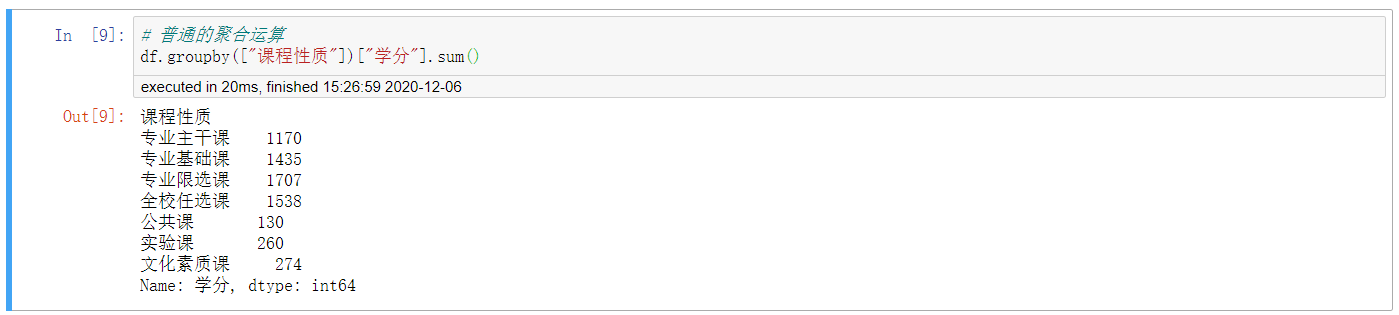
2. 常规的聚合运算
# 普通的聚合运算 df.groupby(["课程性质"])["学分"].sum()
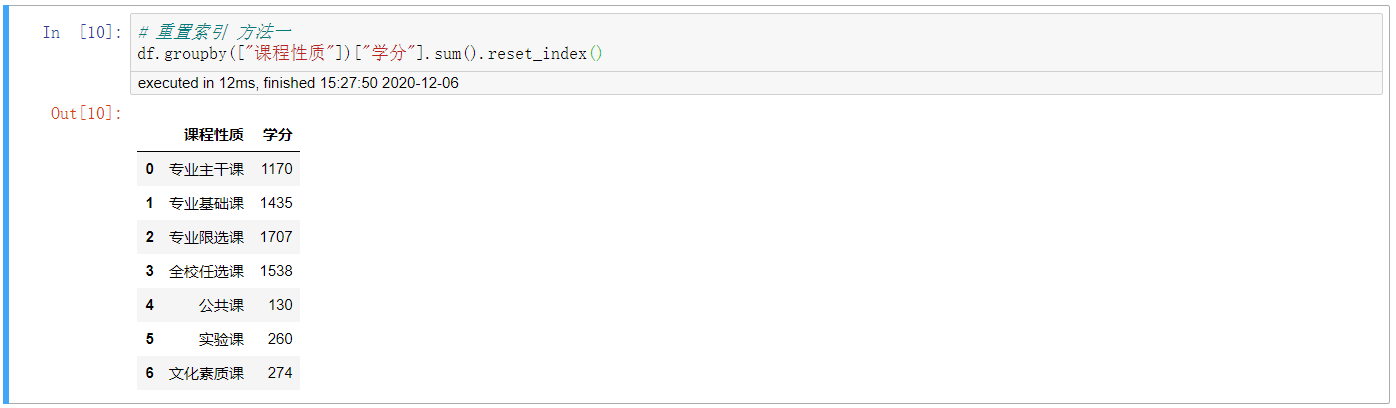
3. 重置索引 方法一
# 重置索引 方法一 df.groupby(["课程性质"])["学分"].sum().reset_index()
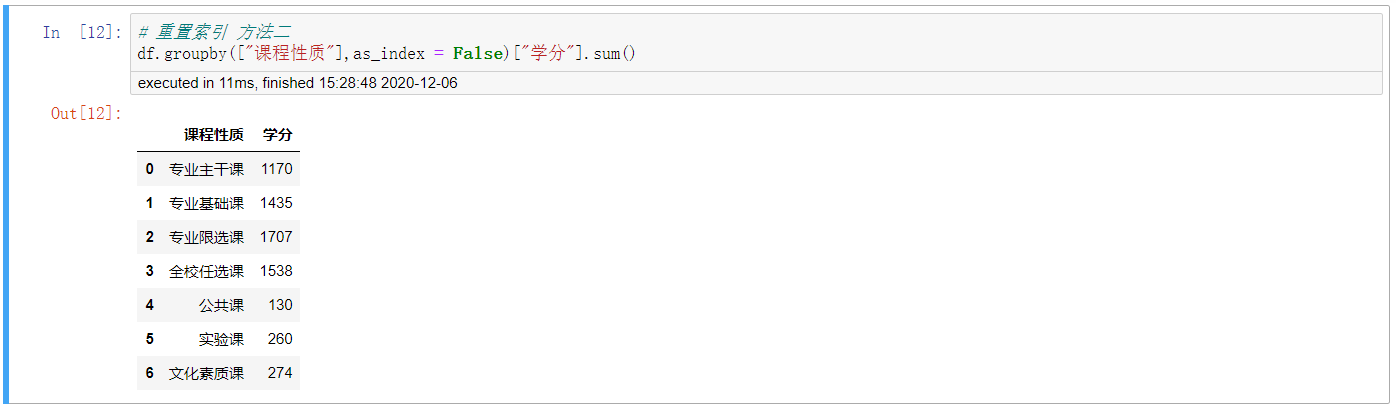
4. 重置索引 方法二
# 重置索引 方法二 df.groupby(["课程性质"],as_index = False)["学分"].sum()
如果看不清楚,请在看下面:
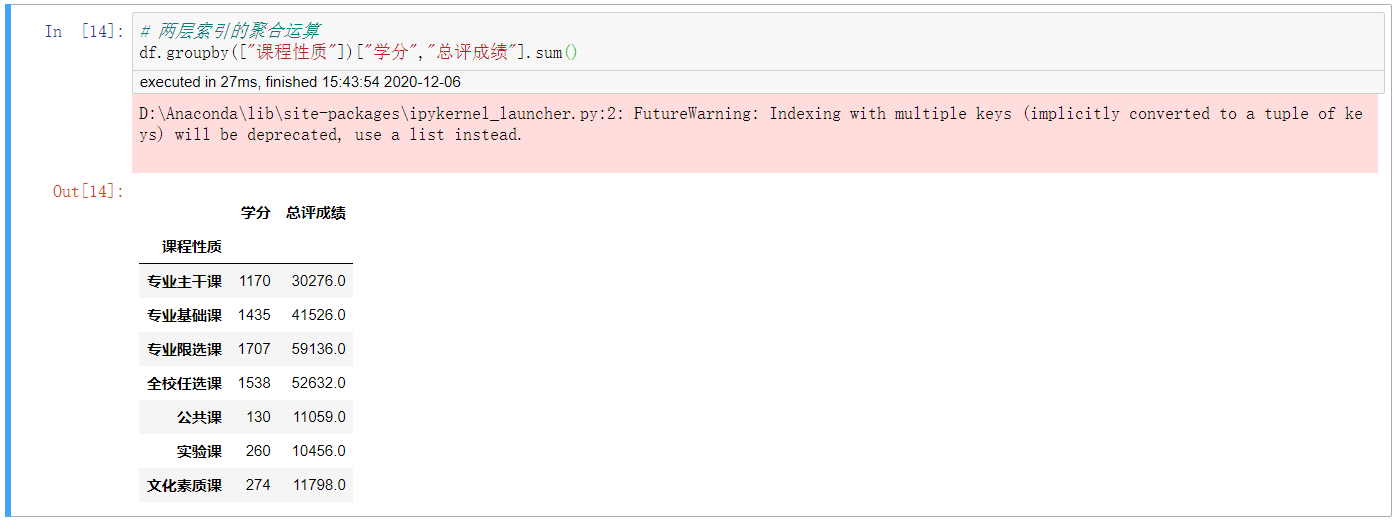
5. 带两组变元(下面的两层索引纯属笔误,但懒得改了)的聚合运算
# 两层索引的聚合运算 df.groupby(["课程性质"])["学分","总评成绩"].sum()
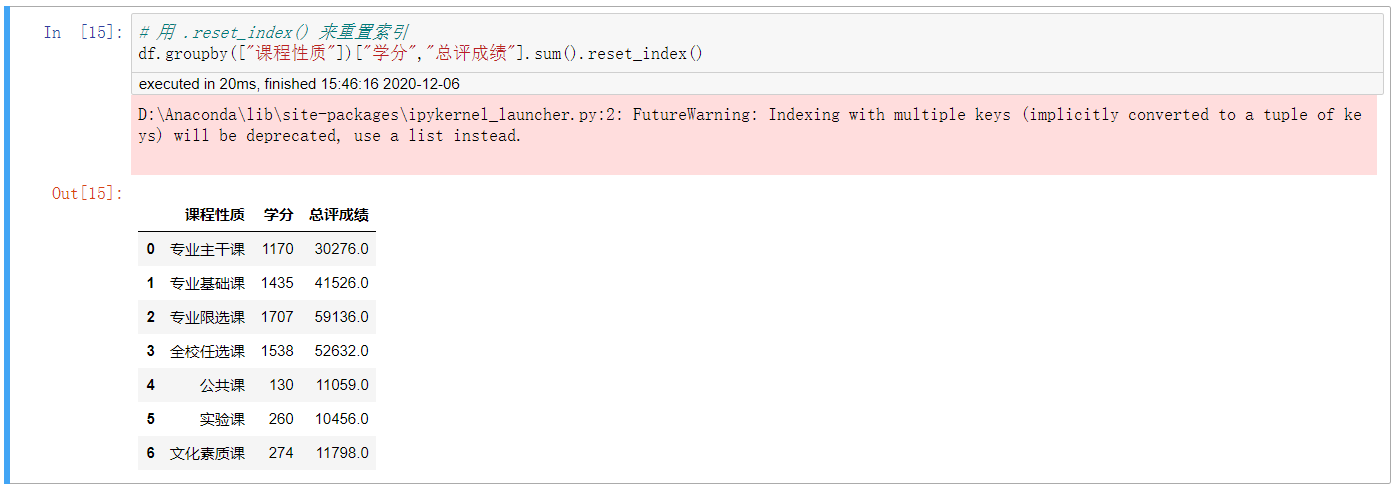
6. 用 .reset_index() 来重置索引
# 用 .reset_index() 来重置索引 df.groupby(["课程性质"])["学分","总评成绩"].sum().reset_index()
7. 用 .groupby(as_index = False) 来重置索引
# 用 .groupby(as_index = False) 来重置索引 df.groupby(["课程性质"],as_index = False)["学分","总评成绩"].sum()

看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





