这篇文章主要介绍“什么是RTMP协议”,在日常操作中,相信很多人在什么是RTMP协议问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”什么是RTMP协议”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
实时消息传输协议(Real-Time Messaging Protocol)是目前直播的主要协议,是Adobe公司为Flash播放器和服务器之间提供音视频数据传输服务而设计的应用层私有协议。RTMP协议是目前各大云厂商直线直播业务所公用的基本直播推拉流协议,随着国内直播行业的发展和5G时代的到来,对RTMP协议有基本的了解,也是我们程序员必须要掌握的基本技能。
本文主要阐述RTMP的基本思想和核心概念,并且辅之以livego的源码分析,和大家一起深入学习RTMP协议最核心的知识点。
RTMP协议主要的特点有:多路复用,分包和应用层协议。以下将对这些特点进行详细的描述。
多路复用(multiplex)指的是信号发送端通过一个信道同时传输多路信号,然后信号接收端将一个信道中传递过来的多个信号分别组合起来,分别形成独立完整的信号信息,以此来更加有效地使用通信线路。

简而言之,就是在一个 TCP 连接上,将需要传递的Message分成一个或者多个 Chunk,同一个Message 的多个Chunk 组成 ChunkStream,在接收端,再把 ChunkStream 中一个个 Chunk 组合起来就可以还原成一个完整的 Message,这就是多路复用的基本理念。
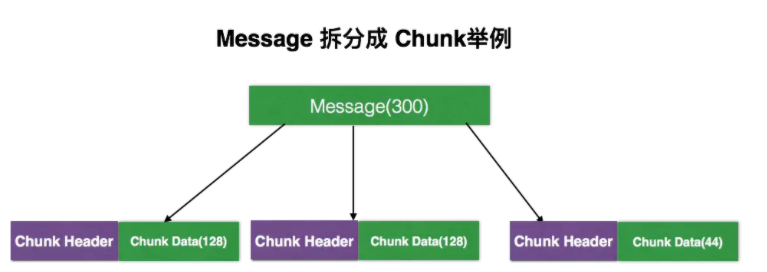
上图是一个简单例子,假设需要传递一个300字节长的Message,我们可以将其拆分成3个Chunk,每一个Chunk可以分成 Chunk Header 和 Chunk Data。在Chunk Header 里我们可以标记这个Chunk中的一些基本信息,如 Chunk Stream Id 和 Message Type;Chunk Data 就是原始信息,上图中将 Message 分成128+128+44 =300,这样就可以完整的传输这个Message了。
关于 Chunk Header 和 Chunk Data 的格式,后文会进行详细介绍。
RTMP协议的第二个大的特性就是分包,与RTSP协议相比,分包是RTMP的一个特点。与普通的业务应用层协议(如:RPC协议)不一样的是,在多媒体网络传输案例中,绝大多数的多媒体传输的音频和视频的数据包都相对比较偏大,在TCP这种可靠的传输协议之上进行大的数据包传递,很有可能阻塞连接,导致优先级更高的信息无法传递,分包传输就是为了解决这个问题而出现的,具体的分包格式,下文会有介绍。
RTMP最后的一个特性,就是应用层协议。RTMP协议默认基于传输层协议TCP而实现,但是在RTMP的官方文档中,只给定了标准的数据传输格式说明和一些具体的协议格式说明,并没有具体官方的完整实现,这就催生出了很多相关的其他业内实现,例如RTMP over UDP等等相关的私有改编的协议出现,给了大家更多的可扩展的空间,方便大家解决原生RTMP存在的直播时延等问题。
作为一种应用层协议,和其他私有传输协议一样(如RPC协议),RTMP也有一些具体代码实现,如 nginx-rtmp、livego 和 srs。本文选用基于go语言实现的开源直播服务器 livego 进行源码级的主流程分析,和大家一起深入学习 RTMP 推拉流的核心流程的实现,帮助大家对RTMP的协议有一个整体的理解。
在进行源码分析之前,我们会通过类比RPC协议的方式,帮助大家对RTMP协议的格式有一个基本的了解,首先我们可以看一个比较简单但实用的RPC协议格式,如下图所示:

我们可以看到这是一个在RPC调用过程中所使用的数据传输格式,之所以使用这样的格式,根本目的还是为了解决"粘包和拆包"的问题。
以下简要描述图中RPC协议的格式:首先用2个字节,MAGIC来表示魔数,标记该协议是对端都能识别的标识,如果接收到的2个字节不是0xbabe的话,则直接丢弃该包;第二个sign占用1个字节,低4位表示消息的类型request/response/heartbeat,高4位表示序列化类型例如json,hessian,protobuf,kyro等等;第三个 status 占用一个字节,表示状态位;随后使用8个字节来表示调用的requestId,一般使用低48位(2的48次方)就足够表示requestId了;接着使用4字节定长的body size来表示Body Content,通过这样的方式就能够很快的解析出RPC消息Message的完整请求对象了。
通过分析上述的一个简单的RPC协议,其实我们能够发现一个很好的思想,就是最大效率的使用字节,即使用最小的字节数组,来传输最多的数据信息。小小的一个字节能够带来很多的信息量,毕竟一个字节它有64种不同的变化。在网络中,如果只需要利用一个字节就能够传递很多有用的信息的话,那么我们就可以使用极其有限的资源来得到最大的资源利用了。RTMP的官方文档在2012年就出现了,虽然以目前的眼光来看,RTMP协议实现的非常复杂,甚至有些臃肿,但是它在2012年的时候,就能够有比较先进的思想,的确是我们学习的榜样。
在当今WebRTC协议横行的年代里,我们也能够从WebRTC的设计实现中,看到RTMP的影子,上述的RPC协议我们就可以认为是一个与RTMP具有相似设计理念的简化版设计。
在分析RTMP源码之前,我们先对RTMP协议中的几个核心概念做具体说明,方便我们在宏观上对RTMP整个协议栈有一个基本的了解,并且在后文源码分析期间,我们也会通过抓包的方式,更加直观地帮助我们去分析相关的原理。
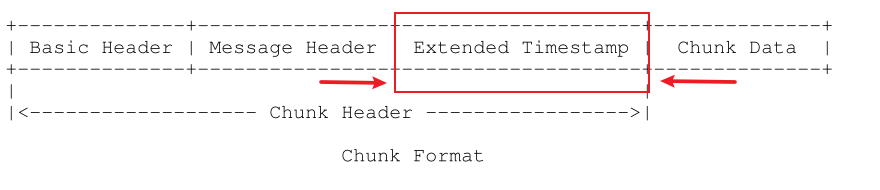
首先,和刚才的RPC协议格式一样,RTMP实际传输的实体对象是Chunk,一个Chunk由Chunk Header和Chunk Body两个部分组成,如下图所示。

Chunk Header这个部分和我们前面说过的RPC协议不太一样,主要是RTMP协议的Chunk Header的长度不是固定的,为什么不是固定的呢?其实还是Adobe公司为了节省数据传输开销。从刚才将一个300字节的Message拆分成3个Chunk的例子中,我们可以看到多路复用其实也是有一个比较明显的缺点,就是我们需要有一个Chunk Header来标记这个Chunk的基本信息,这样其实就是在传输的时候有了额外字节流传输的开销。所以为了保证传输的字节数最少,我们就需要不断地压榨着RTMP的Header的大小,确保Header的大小达到最小,这样才能达到最高的传输效率。
首先我们研究一下Chunk Header中Basic Header的部分,Basic Header的长度就是不固定的,可以是1个字节,2个字节或者3个字节,这取决于Chunk Stream Id(缩写:csid)。
RTMP协议支持的csid的范围是2~65599,0和1是协议保留值,用户不可使用。Basic Header至少含有1个字节(低8位),它的长度就是这1个字节决定的,如下图所示。该字节高2位留给 fmt,fmt的取值决定了 Message Header 的格式,这个在后面会讲到。该字节的低6位就是 csid 的值,当低6位的 csid 取值为0时,表示真实 csid 值大到无法用6个bit表示了,需要借助后续的一个字节才行;当低6位的 csid 取值为1时,表示真实 csid 值大到无法用14个bit表示了,需要再借助后续的一个字节才行。于是,整个Basic Header的长度看起来就不是固定的了,完全取决于首字节的低6位的csid的值。
实际应用中,并没有使用到那么多csid,也就是说一般情况下,Basic Header长度为一个字节,csid取值范围为 2~63。

刚才说了那么多,才仅仅说了Basic Header,而Basci Header只是Chunk Header的组成部分之一,比较喜欢折腾的RTMP协议的作者,把RTMP的Chunk Header模块又设计成了动态大小的,简而言之也是为了节省传输空间,这边能够方便理解的地方就是Chunk Message Header的长度也分四种情况,这就是前面提到的 fmt 这个值决定的。
Message Header 的四种格式如下图所示:
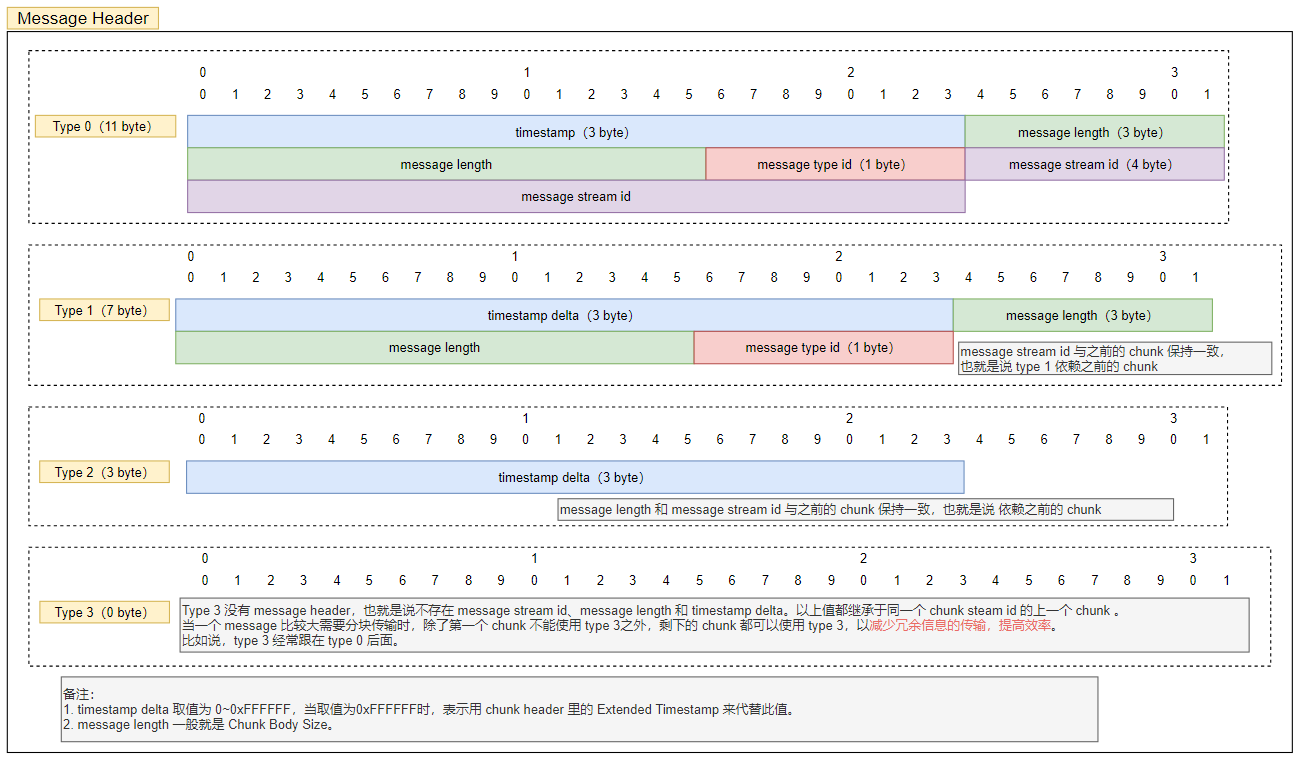
当 fmt 为 0 的时候,Message Header占用11个字节(请注意,这边的11个字节不包括Basic Header的长度),由3个字节长度的timestamp,3个字节长度的message length,1个字节长度的message type Id,4个字节长度的message stream Id所组成的。
其中,timestamp 是绝对时间戳,表示的是这个消息发送的时间;message length 表示的是chunk body的长度;message type id 表示的是消息类型,这个在后文会具体讲到;message stream id 是消息唯一标识。这边需要注意的是,如果这个消息的绝对时间戳大于0xFFFFFF,说明这个时间大到无法用3个字节来表示,需要借助扩展时间戳(Extended Timestamp)来表示,扩展时间戳长度为4个字节,默认放在Chunk Header和Chunk Body之间。
当 fmt 为 1的时候,Message Header占用7个字节,与之前的11个字节的chunk header相比,少了一个message stream id,这个chunk是复用之前的chunk stream id,这个一般用于可变长的消息结构。
当 fmt 为 2的时候,Message Header只占用3个字节,就只包含timestamp的三个字节,与之前相比,既少了stream id也少了message length,这种少了message length的,一般用于固定长度但是需要修正时间的消息(如:音频数据)。
当 fmt 为 3的时候,Chunk Header里就不包含 Message Header 了。一般来说,在拆包的时候,把一个完整的RTMP的Message消息,会拆成第一个是fmt 为 0的Chunk消息,随后的消息也会拆成fmt为3的消息,这样的做的方式就是第一个Chunk附带着最全的Chunk消息信息,后续Chunk信息的Header就会比较小,这样实现比较简单,压缩率也是比较好。当然,如果第一个Message发送成功之后,第二个Message再次发送的时候,就会把第二个Message的第一个Chunk设置成fmt为1类型的Chunk,随后该Message的Chunk的fmt为3,这样就能够进行消息的区分。
刚才花了很多时间去描述Chunk Header,接下来我们再针对Chunk Body进行简单的描述。与Chunk Header相比,Chunk Body就比较简单,没有那么多变长的控制,结构也比较简单,这个里面的数据也就是真正有业务含义的数据,长度默认是128个字节(可以通过 set chunk size 命令协商更改)。里面的数据包组织格式一般是AMF或者FLV格式的音视频数据(不含FLV TAG头)。AMF组织结构的数据组成如下图所示,FLV格式本文不做深入描述,感兴趣的话可以阅读 FLV 官方文档。
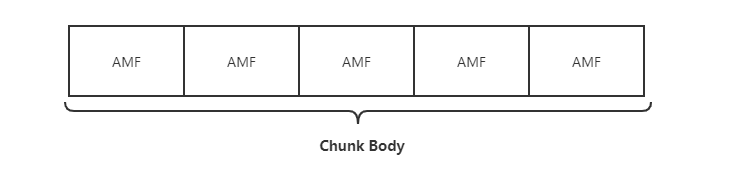
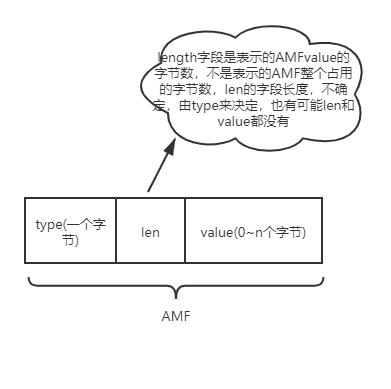
AMF(Action Message Format) 是一种类似JSON,XML的二进制数据序列化格式,Adobe Flash与远程服务端可通过AMF格式的数据进行数据通信。
AMF具体的格式其实与Map的数据结构很相似,就是在KV键值对的基础上,中间多加了一个Value值的length。AMF的结果基本如下图所示,有时候len字段就是空,这个是由type来决定的,我们举例来说,例如我们传输的是number类型的AMF格式的数据,那么len字段我们就可以忽略,因为我们默认number类型的字段占用8个字节,我们这边就可以忽略了。
再举例来说,AMF如果传输的是0x02 string类型的数据的时候,len的长度就默认占据2个字节,因为2个字节足够表示后面value的最大长度了。以此类推,当然有些时候,len和value的值都不存在,就比如传递0x05 传递null的时候,len和value我们就都不需要了。
以下列举一些常用的AMF的type的对应表格,更多信息可以查看官方文档。

我们可以通过WireShark来抓包,实际来体验一下具体的AMF0的格式。
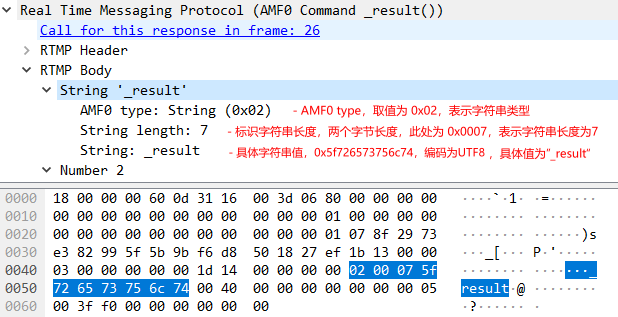
如上图所示,这是一个非常典型的AMF0类型string结构的抓包。AMF目前有2个主要的版本,分别是AFM0和AMF3,在目前的实际使用场景中,AMF0还是占据主流的地位。那么AMF0和AMF3有什么区别呢,当客户端给服务器端发送AMF格式Chunk Data数据的时候,服务端在接收到该信息的时候,如何是知道AMF0或者是AMF3呢?实际上RTMP在Chunk Header中使用message type id来进行区分,当消息使用AMF0编码时,message type id等于20,使用AMF3编码时message type id等于17。
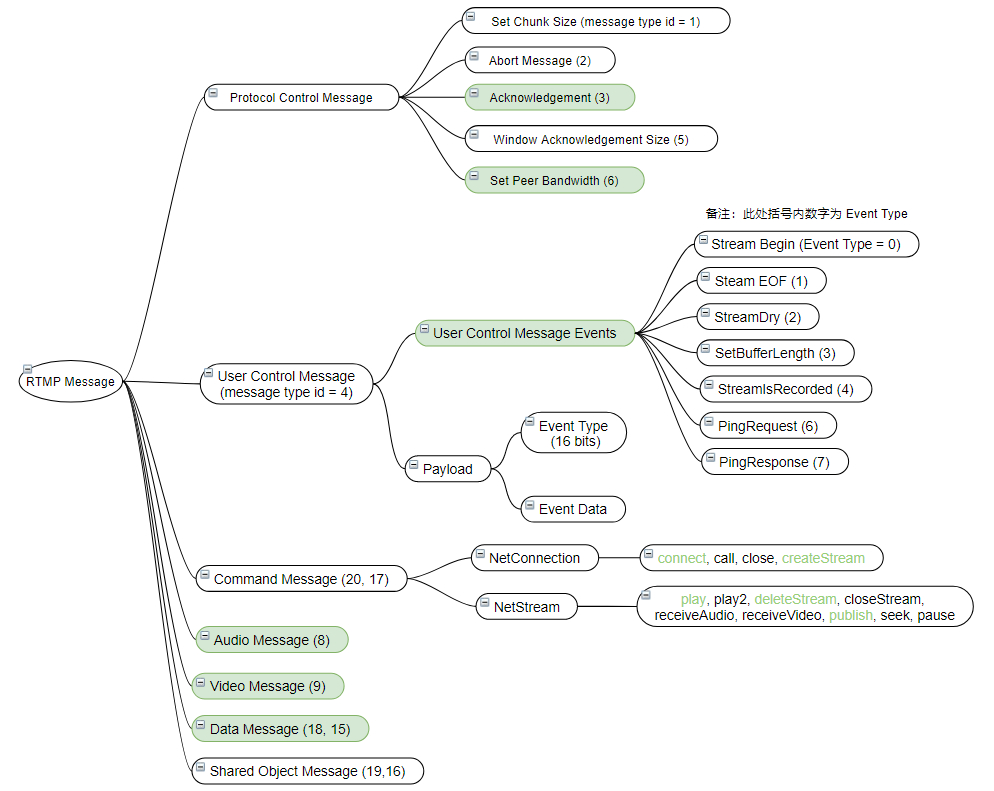
首先,用一句话来总结一下Chunk和Message的关系,一个Message是由多个Chunk组成,多个Chunk Stream id一样的Chunk称之为Chunk Stream,接收端可以重新合并解析为完整的Message。RTMP相比于RPC消息来说,消息类型多了很多,前文讲的RPC消息类型归根结底就request,response和heartbeat这三种类型,但是RTMP协议的消息类型就比较丰富。RTMP消息主要分为以下三大类型:协议控制消息,数据消息和命令消息。
**协议控制消息:**Message Type ID = 1~6,主要用于协议内的控制。
**数据消息:**Message Type ID = 8 9
188: Audio 音频数据
9: Video 视频数据1
8: Metadata 包括音视频编码、视频宽高等音视频元数据。
命令消息 Command Message (20, 17):此类型消息主要有 NetConnection 和 NetStream 两类,两类分别有多个函数,该消息的调用,可理解为远程函数调用。
总览图如下,后续在源码解析章节,会进行具体介绍,其中着色部分为常用消息。
网络协议的学习是一个枯燥的过程,我们尝试结合 RTMP协议原文和WireShark抓包的方式,尽量形象地给大家描述 RTMP 协议中的核心流程,包括握手,连接,createStream,推流和拉流。本节所有的抓包数据的基本环境是:livego作为RTMP服务器(服务端口为1935),OBS作为推流应用,VLC作为拉流应用。
作为一个应用层协议解析来说,首先,我们要注意的就是主体流程的把握,对于每一个 RTMP 服务器来说,每一个推流和拉流从代码层面来说,都是一个网络链接,针对每一个连接,我们要进行对应的工序进行处理,我们可以看到livego中源码中所展示的一样,有一个handleConn方法,顾名思义,就是用来处理每一个连接,按照主流程来说,分为第一部分的握手,第二个核心模块的依据RTMP包协议,进行Chunk header和Chunk body的解析,后续再根据解析出来的Chunk header和Chunk body再做具体的处理。
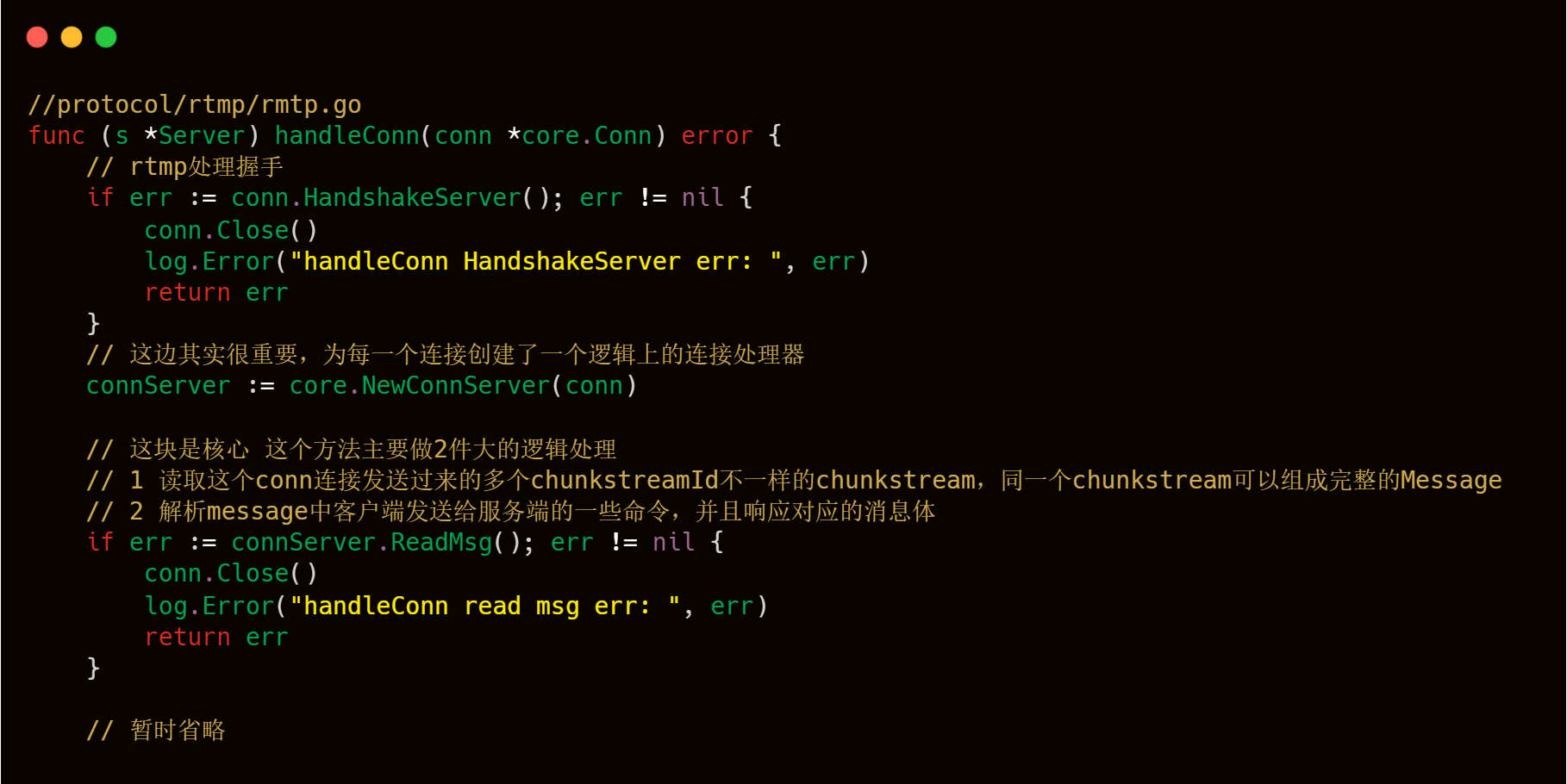
可以看到上述代码块,主要有2个核心方法:一个是HandshakeServer,主要处理握手逻辑;另一个是ReadMsg方法,主要处理Chunk header和Chunk body信息的读取。
协议原文的5.2.5节详细介绍了 RTMP 握手的过程,图示如下:
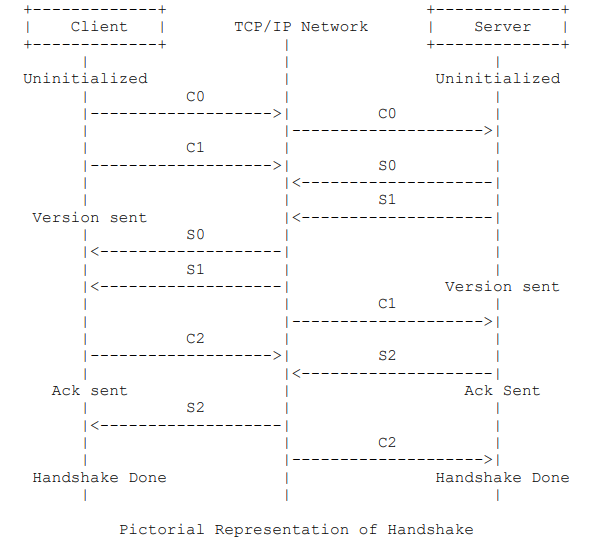
乍一看,可能会觉得此过程有些复杂。所以,我们还是先用 WireShark 抓包来整体看看过程吧。
WireShark 抓包的 Info 能够为我们解读 RTMP 包的含义,从下图可以看出,握手主要涉及到3个包。其中第16号包是客户端向服务端发送 C0 和 C1 消息,18号包是服务端向客户端发送 S0,S1 和 S2 消息,20号包是客户端向服务端发送 C2 消息。如此,客户端和服务端就完成了握手过程。
通过 WireShark 抓包可以看出,握手过程还是非常简洁的,有点类似 TCP 三次握手的过程,所以从实际抓包来说,与RTMP协议原文的5.2.5节介绍的还是有些出入的,整体流程变得很简洁。

现在可以回头看看上面那个比较复杂的握手流程图了。图中将客户端和服务端分为四种状态,分别是:未初始化,已发送版本号,已发送 ACK,握手完成。
未初始化:客户端和服务端无任何交流阶段;
已发送版本号:发送了 C0 或者 S0;
已发送 ACK:发送了 C2 或者 S2;
握手完成:接收到了 S2 或者 C2。
RTMP 协议规范并没有限定死 C0,C1,C2 和 S0,S1,S2 的顺序,但是制定了以下规则:
客户端必须收到服务端发来的 S1 后才能发送 C2;
客户端必须收到服务端发来的 S2 后才能发送其他数据;
服务端必须收到客户端发来的 C0 后才能发送 S0 和 S1;
服务端必须收到客户端发来的 C1 后才能发送 S2;
服务端必须收到客户端发来的 C2 后才能发送其他数据。
从 WireShark 抓包分析可以看出,整个握手过程的确是遵循了以上规定。现在问题来了,C0,C1,C2,S0,S1 和 S2 这些消息到底是些什么玩意?其实,RTMP 协议规范里面明确定义了它们的数据格式。
C0 和 S0:1个字节长度,该消息指定了 RTMP 版本号。取值范围 0~255,我们只需要知道 3 才是我们需要的就行。其他取值含义感兴趣的话可以阅读协议原文。
C1 和 S1:1536个字节长度,由 时间戳+零值+随机数据 组成,握手过程的中间包。
C2 和 S2:1536个字节长度,由 时间戳+时间戳2+随机数据回传 组成,基本上是 C1 和 S1 的 echo 数据。一般在实现上,会令 S2 = C1,C2 = S1。
下面我们结合 livego 源码来加强对握手过程的理解。
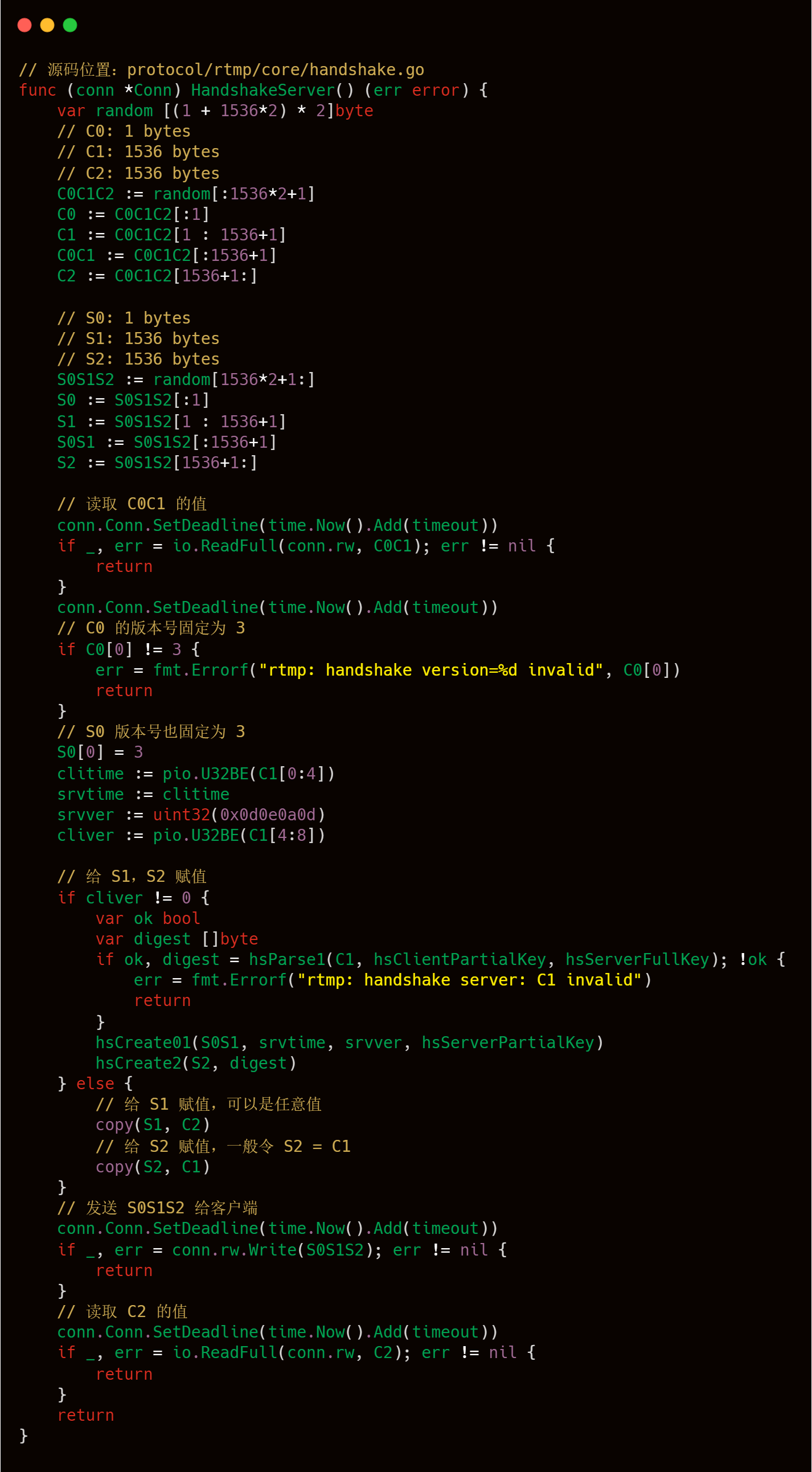
到此为止,最简单的握手流程就到此结束了,可以看出整个握手流程还是比较清晰的,处理逻辑也是比较简单,也比较便于理解。
3.2.2.1 解析RTMP协议的Chunk信息
握手之后,就要做开始做连接等相关的事情处理了,再做此信息处理之前,工欲善其事必先利其器。
我们先要按照RTMP协议的规范来解析Chunk Header和Chunk body了,将网络传输的字节包数据转换成我们可识别的信息处理,再根据这些可识别的信息数据,再做对应流程的处理,这块是源码解析的关键核心,涉及的知识点非常多,大家可以结合上文一起看,可以方便大家理解ReadMsg这块核心逻辑的理解。

上述的代码块逻辑很清晰,主要是读取每一个conn连接中,进行对应的编解码,获取到一个个Chunk,并且将相同ChunkStreamId的Chunk再次进行合并,合并成对应的Chunk Stream,最后一个个完整的Chunk Stream就是Message了。
这块代码就是和我们之前理论部分知识介绍的chunkstreamId那块知识比较接近的地方了,大家可以结合起来一起看,大家在脑海中,要注意就是一个conn连接,会传递多个Message,例如连接Message,createStreamMessage等等,每一个Message就是Chunk Stream,也就是多个csid相同的Chunk,所以livego的作者使用map这样的数据结构进行存储,key就是csid,value就是chunkstream,这样就可以将向rtmp服务器发送过来的信息能够全部保存下来。
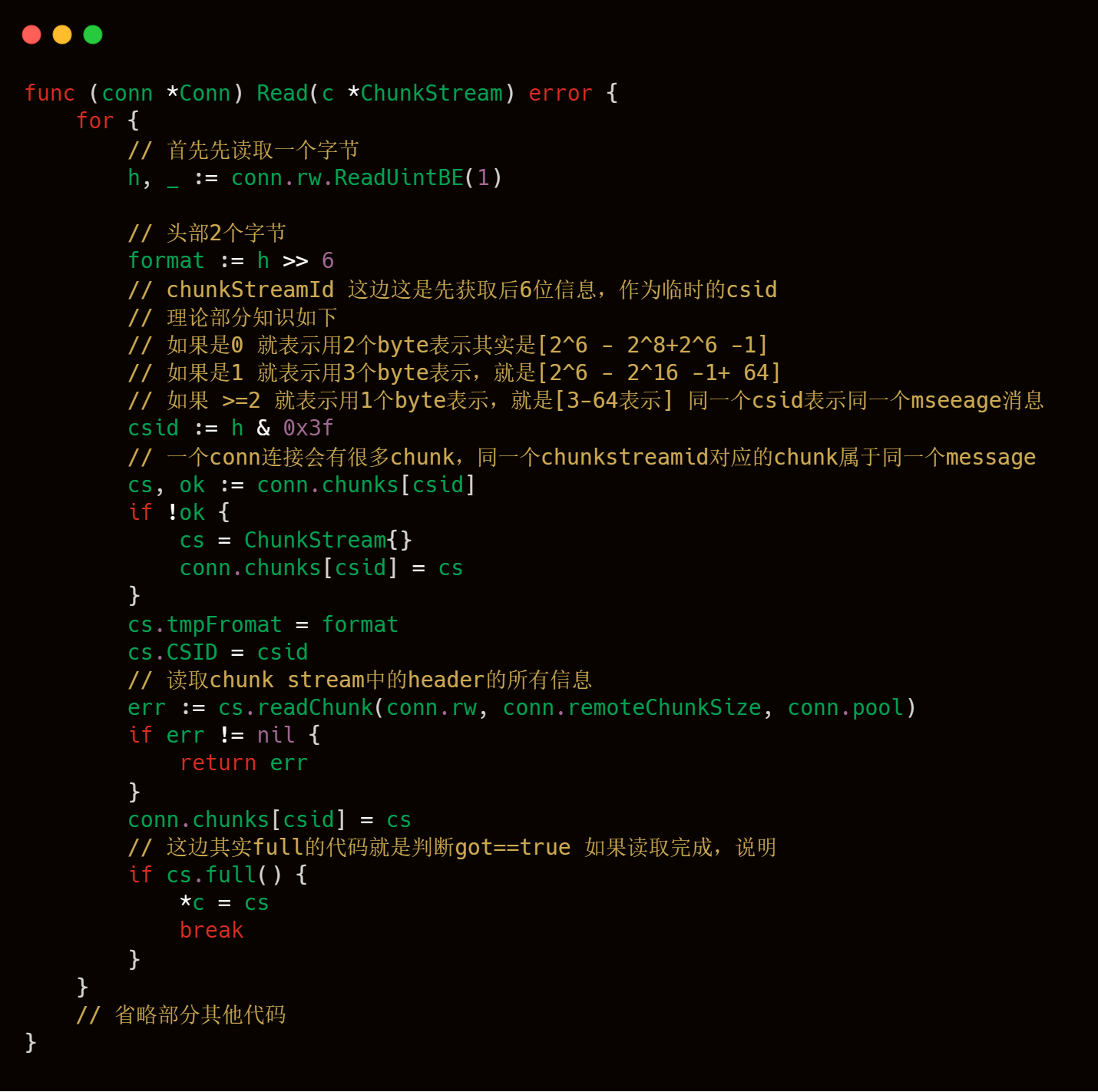
readChunk代码的具体逻辑实现分成如下几个部分:
1)csid的修正,至于理论部分参照上述逻辑,这块其实是basic header的处理。
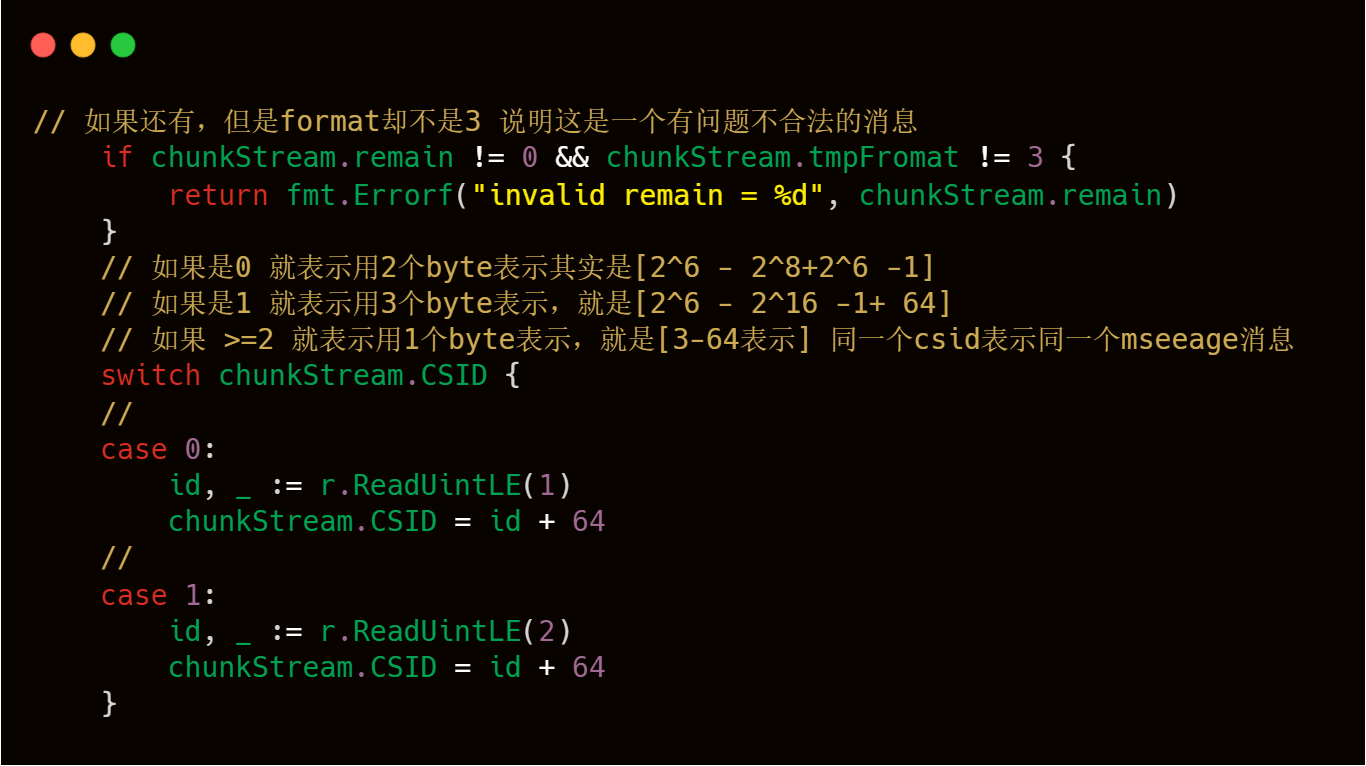
2)Chunk Header按照format的数值进行对应的解析处理,上文理论部分也已经介绍过了,下文也有具体的注释解释,有两个技术点需要注意第一就是timestramp时间戳的处理,第二个注意点是chunk.new(pool)这行代码,也是需要大家注意,代码注释中也写的比较清楚。
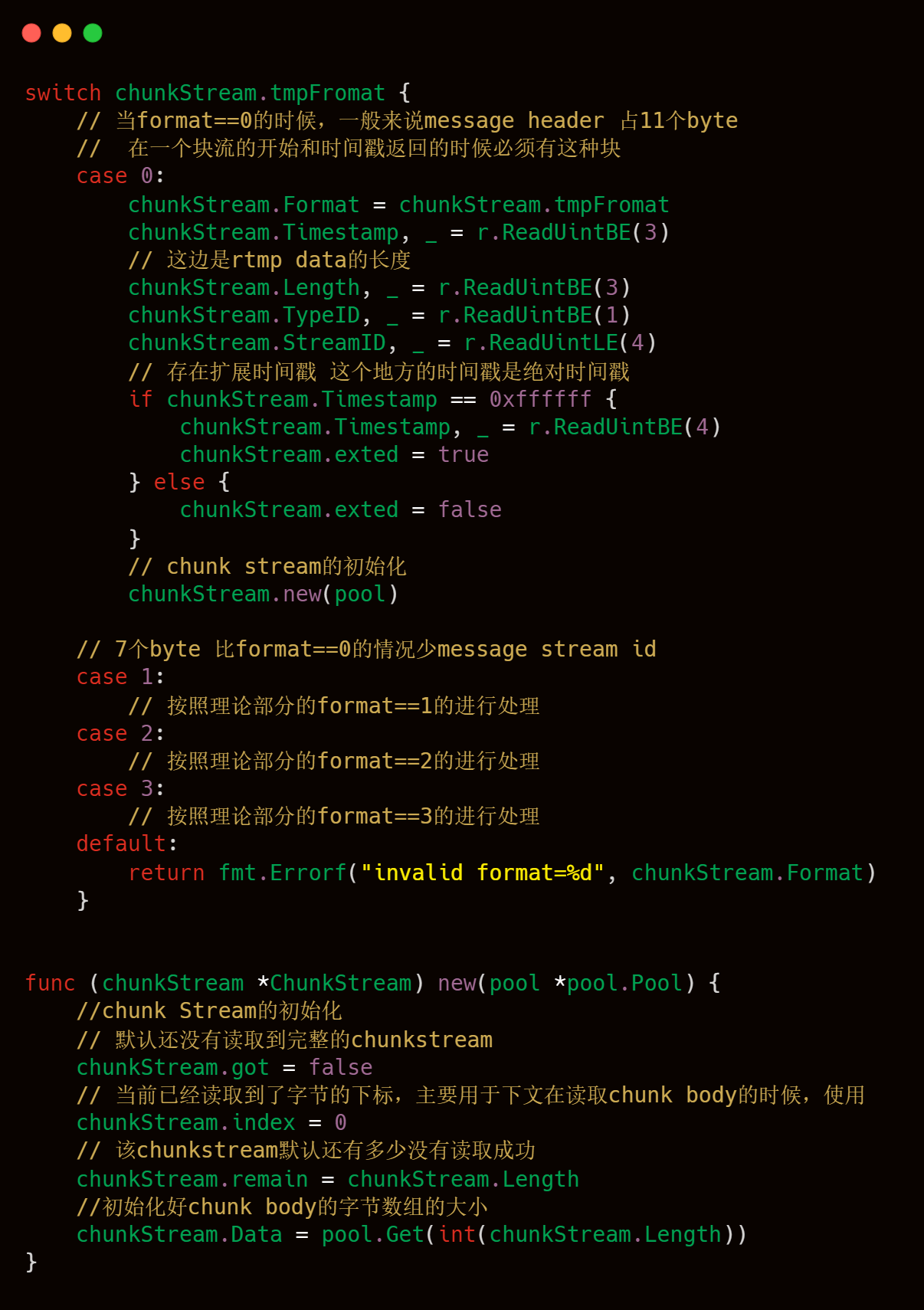
3)Chunk Body的读取处理,上文理论部分说过,Chunk header中当fmt 为 0 的时候,会有一个message length字段,这个字段会控制Chunk Body的大小,依据这个字段,我们可以很轻松地读取到Chunk body信息的读取,整体逻辑如下。
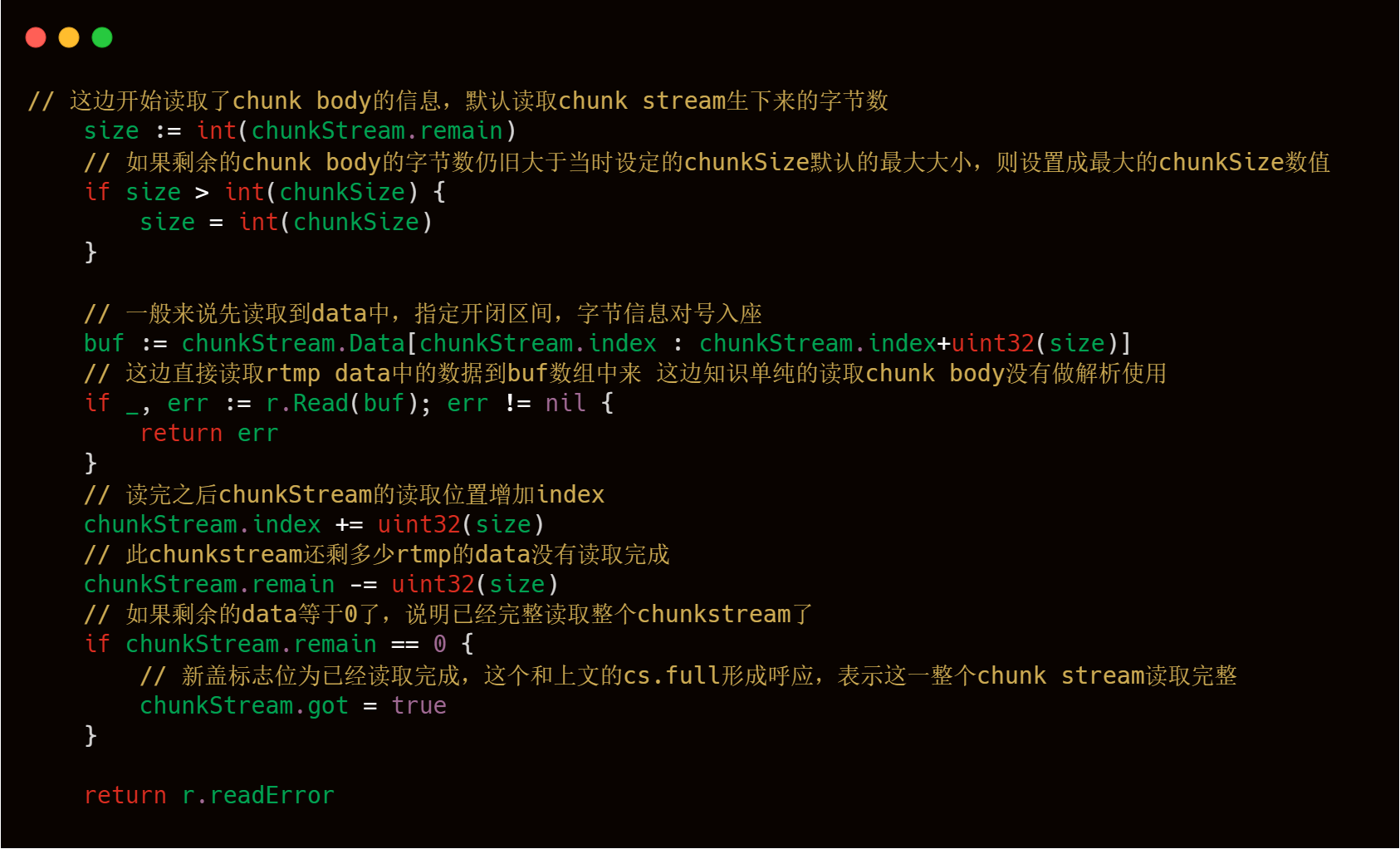
到此为止,我们已经成功解析了Chunk Header,读取了Chunk Body,注意我们只是读取了Chunk Body还没有按照AMF格式对Chunk Body进行解析,针对Chunk Body部分的逻辑处理,在下文会进行详细的源码介绍,不过现在我们已经解析到了一个连接发送过来的ChunkStream了,接下来我们就可以回到主流程的分析了。
刚才说了握手完成后,并且我们也解析到了ChunkStream信息了,接下来我们就要依据ChunkStream的typeId和Chunk Body中的AMF数据进行对应的工序流程处理了,具体思路大家可以这样理解,客户端A发送xxxCmd命令,RTMP服务端根据typeId和AMF信息解析出xxxCmd命令,并给以对应命令的响应。

上述代码块中的handleCmdMsg中也是这个RTMP服务端处理客户端命令的代码精髓了,可以看出livego是支持AMF3和AMF0的,AMF3和AMF0的区别,上文也已经介绍过了,下文的代码注释写的也比较清楚,然后就是解析AMF格式的Chunk Body的数据,解析出来的结果也是按照Slice格式进行存储。
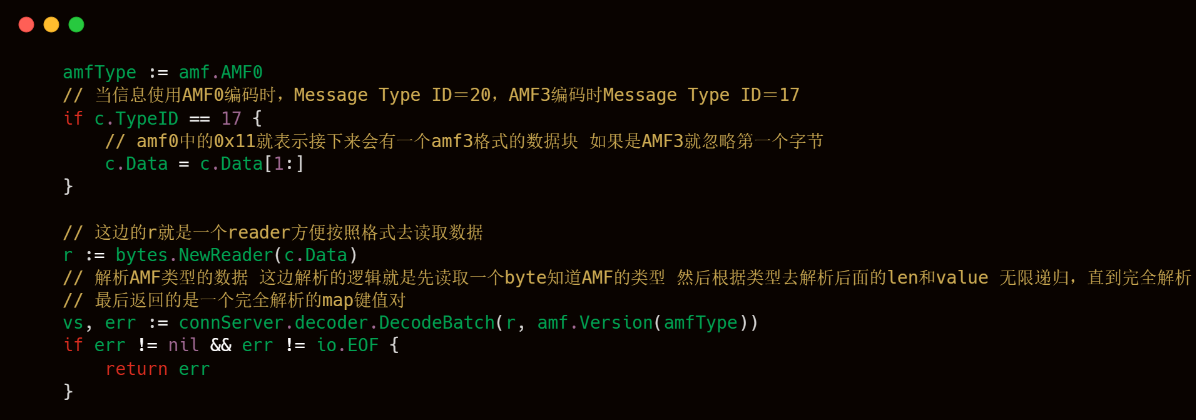
解析好typeId和AMF,接下来就是水到渠成的对各个命令进行处理了。
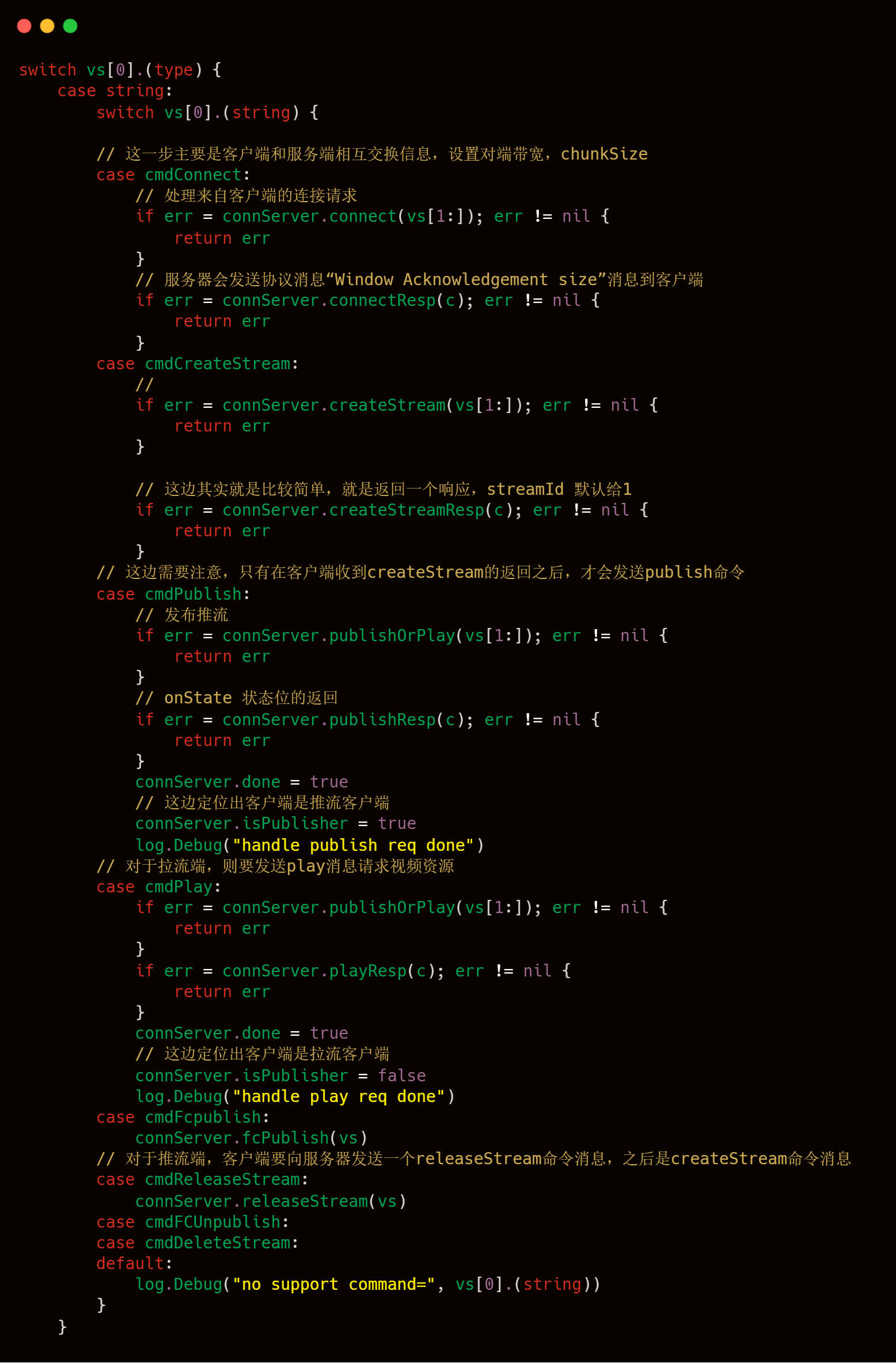
接下来是针对每一个客户端命令的处理了。
3.2.2.2 连接
连接(Connect)命令处理过程:连接过程客户端和服务端会完成窗口大小,传输块大小和带宽大小的确认,RTMP 协议原文详细介绍了连接过程,如下图所示:

同样,我们这里用 WireShark 抓包分析:
从抓包可以看出,连接过程只用了3个包就完成了:
22 号包:客户端告诉服务端,我想要设置 chunk size 为 4096;
24 号包:客户端告诉服务端,我想要连接叫 “live” 的应用;
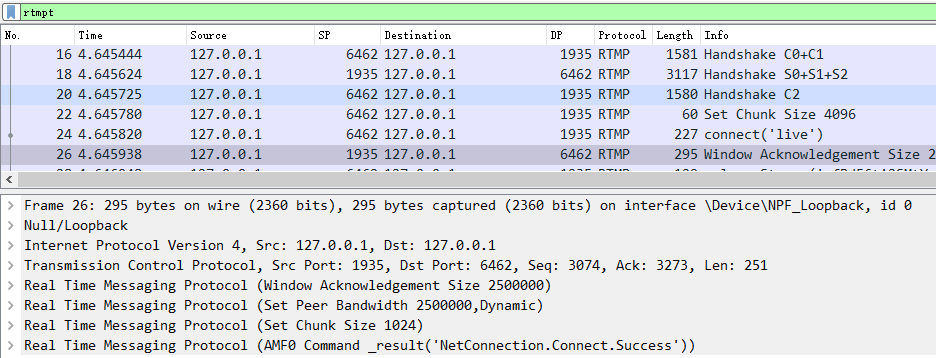
26 号包:服务端响应客户端的连接请求,确定窗口大小,带宽大小和 chunk size,以及返回 “_result” 表示响应成功。这些都是通过一个 TCP 包来完成的。
那么客户端和服务端是如何知道这些包的含义的呢?这就是 RTMP 协议规范所制定的规则了,我们可以通过阅读规范来了解,当然也可以通过 wrieshark 来帮助我们快速解析。以下是 22 号包的详细解析,我们重点关注 RTMP 协议解析信息就行。
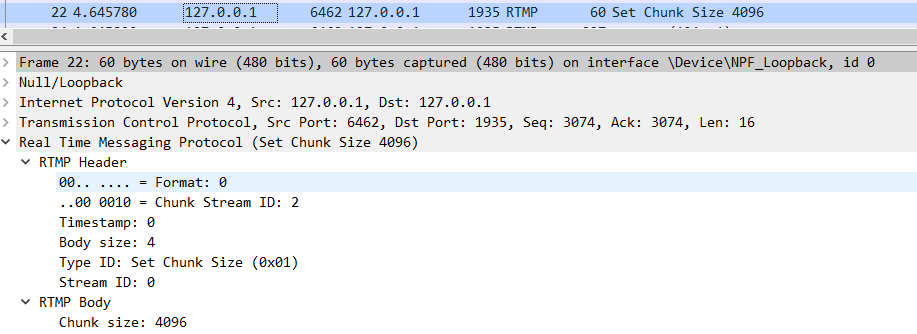
从图中可以看出, RTMP Header 包含有 Format 信息,Chunk Stream ID 信息,Timestamp 信息,Body size 信息,Message Type ID 信息和 Messgae Stream ID 信息。Type ID 的十六进制值为 0x01,含义为 Set Chunk Size,属于协议控制消息(Protocol Control Messages)。
RTMP 协议规范5.4节规定了,对于协议控制消息,Chunk Stream ID 必须设为 2,Message Stream ID 必须设为 0,时间戳直接忽略。从 WireShark 抓包解析出的信息可知,22号包的确是符合 RTMP 规范的。
现在我们来看看 24 号包的详细解析。
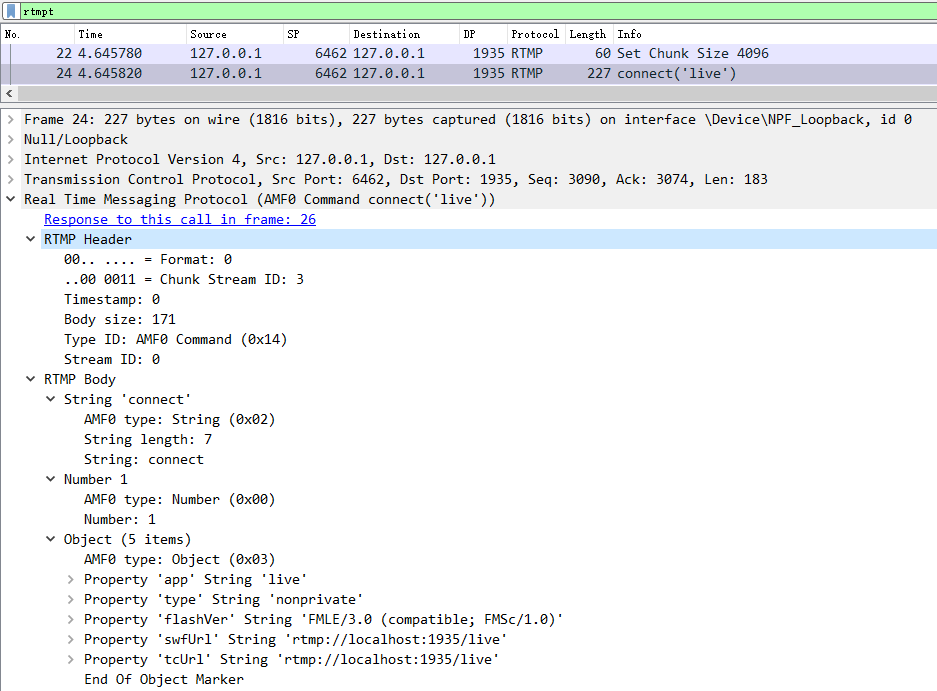
24 号包也是客户端发出的,可以看到它设置Message Stream ID 为 0,Message Type ID 为 0x14(即十进制的20),含义为 AMF0 命令。AMF0 属于 RTMP 命令消息(RTMP Command Messages),RTMP 协议规范并没有规定连接过程必须要使用的 Chunk Stream ID,因为真正起作用的是 Message Type ID,服务端根据 Message Type ID 来做相应的响应。连接过程发送的 AMF0 命令携带的是 Object 类型的数据,会告诉服务端要连接的应用名和播放地址等信息。
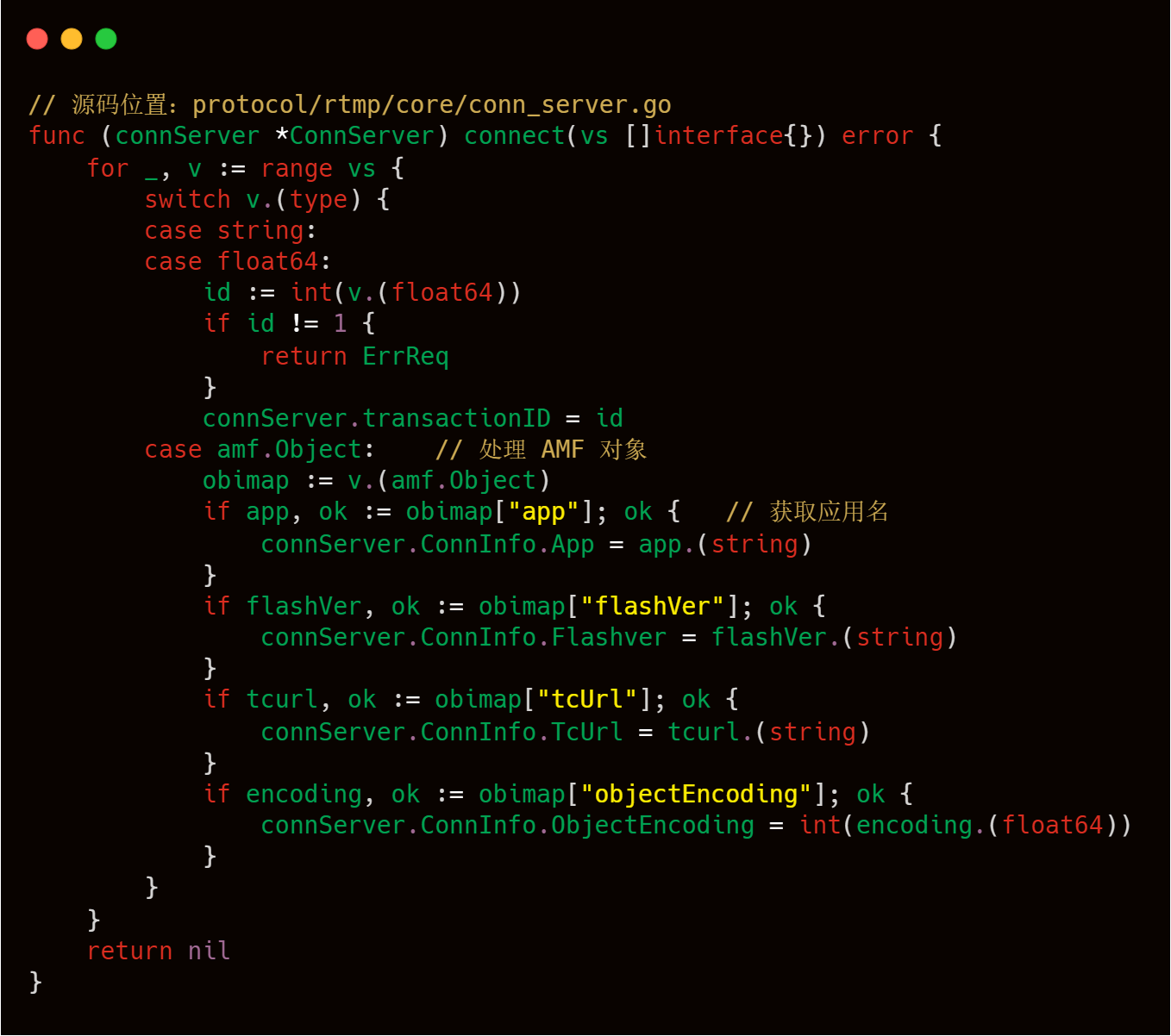
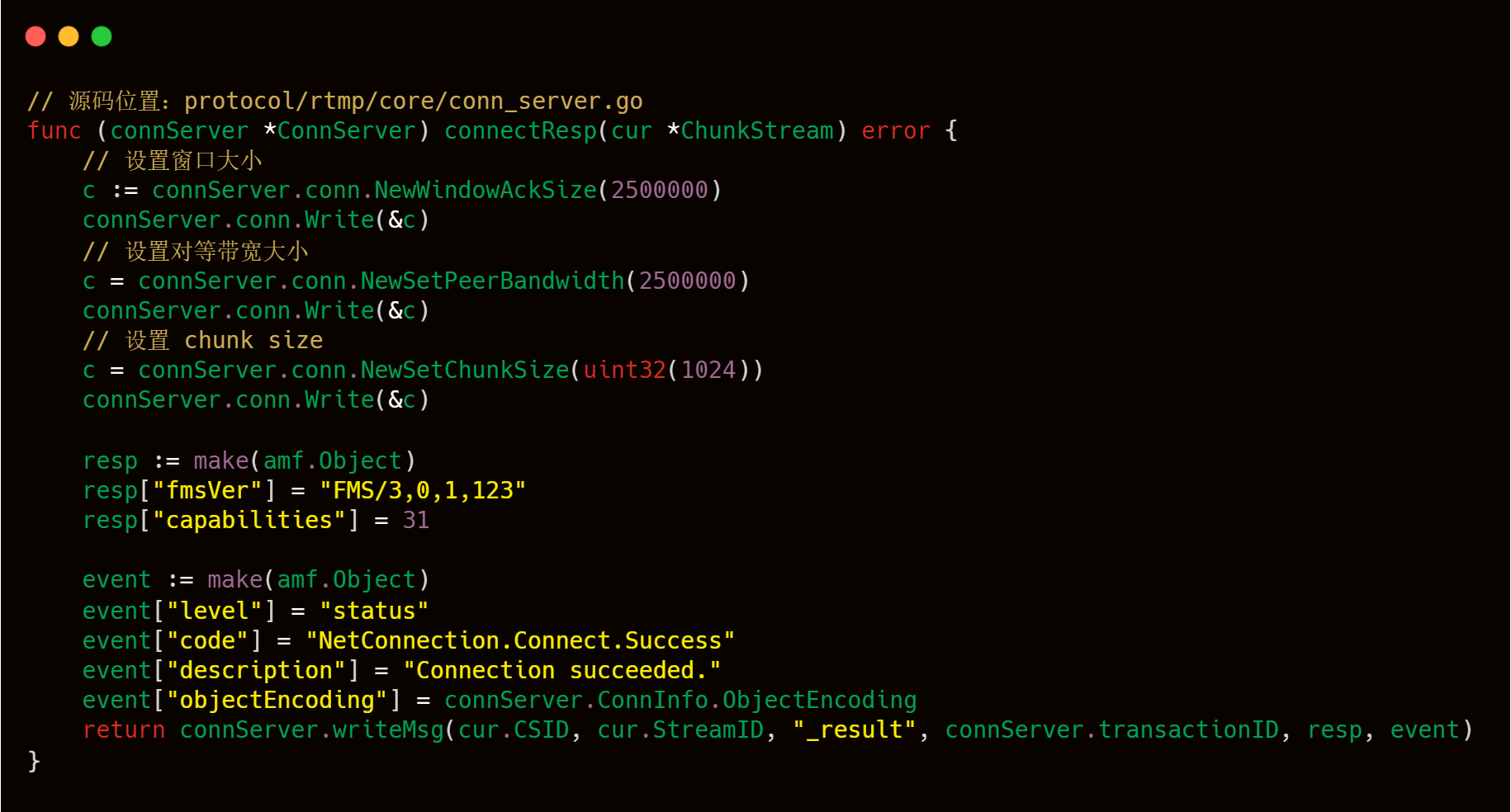
以下代码是 livego 处理客户端请求连接的过程。
收到客户端连接应用的请求后,服务端需要作出相应响应给客户端,也就是 WireShark 抓取的 26 号包的内容,详细内容如下图所示,可以看到服务端在一个包里面做了好几件事情。
我们可以结合 livego 源码来深入学习该过程。
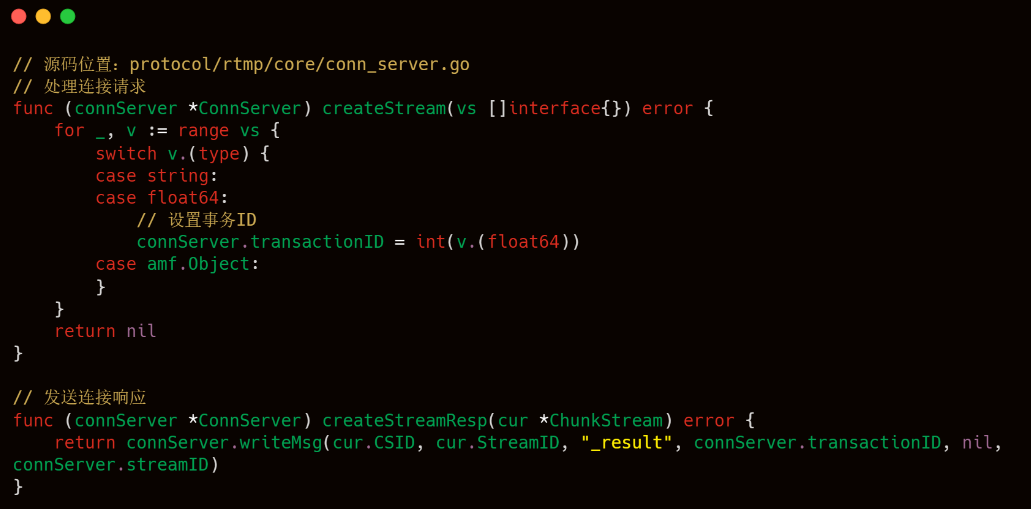
3.2.2.3 createStream
连接完成后,就可以创建流了。创建流的过程相对来说比较简单,只需要两个包就能够实现,如下所示:

其中 32 号包是客户端发起 createStream 请求,34 号包是服务端响应,以下是 livego 处理客户端连接请求的源码。
3.2.2.4 推流
创建流完成后,就可以开始推流或者拉流了,RTMP 协议规范的7.3.1节也有给出推流示意图,如下图所示。其中连接和创建流的过程上文已经详细介绍过了,我们重点看发布内容(Publishing Content)的过程就行。

使用 livego 推流前,需要先获取推流的 channelkey。我们可以通过如下命令获取频道为 “movie” 的 channelKey。响应内容中的 Content 的 data 字段值就是推流需要的 channelKey。
$ curl http://localhost:8090/control/get?room=movie
StatusCode : 200
StatusDescription : OK
Content : {"status":200,"data":"rfBd56ti2SMtYvSgD5xAV0YU99zampta7Z7S575K
LkIZ9PYk"}
RawContent : HTTP/1.1 200 OK
Content-Length: 72
Content-Type: application/json
Date: Tue, 09 Feb 2021 09:19:34 GMT
{"status":200,"data":"rfBd56ti2SMtYvSgD5xAV0YU99zampta7Z7S575K
LkIZ9PYk"}
Forms : {}
Headers : {[Content-Length, 72], [Content-Type, application/json], [Date
, Tue, 09 Feb 2021 09:19:34 GMT]}
Images : {}
InputFields : {}
Links : {}
ParsedHtml : mshtml.HTMLDocumentClass
RawContentLength : 72使用OBS推流到 livego 服务器中应用名为 live 的 movie 频道,推流地址为:rtmp://localhost:1935/live/rfBd56ti2SMtYvSgD5xAV0YU99zampta7Z7S575KLkIZ9PYk。同样,我们还是先看一下WireShark 的抓包内容吧。
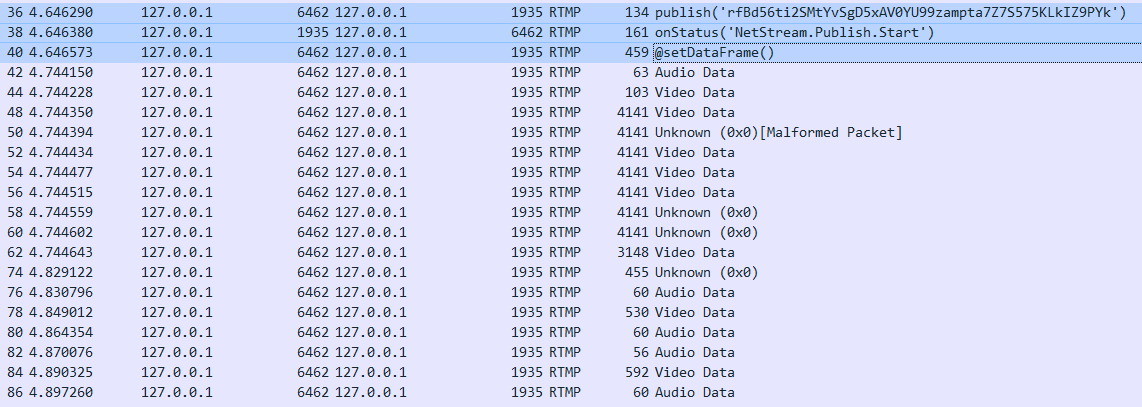
推流初期,客户端发起 publish 请求,也就是36号包的内容,该请求中需要带上频道名,在这个包里面就是"rfBd56ti2SMtYvSgD5xAV0YU99zampta7Z7S575KLkIZ9PYk"。
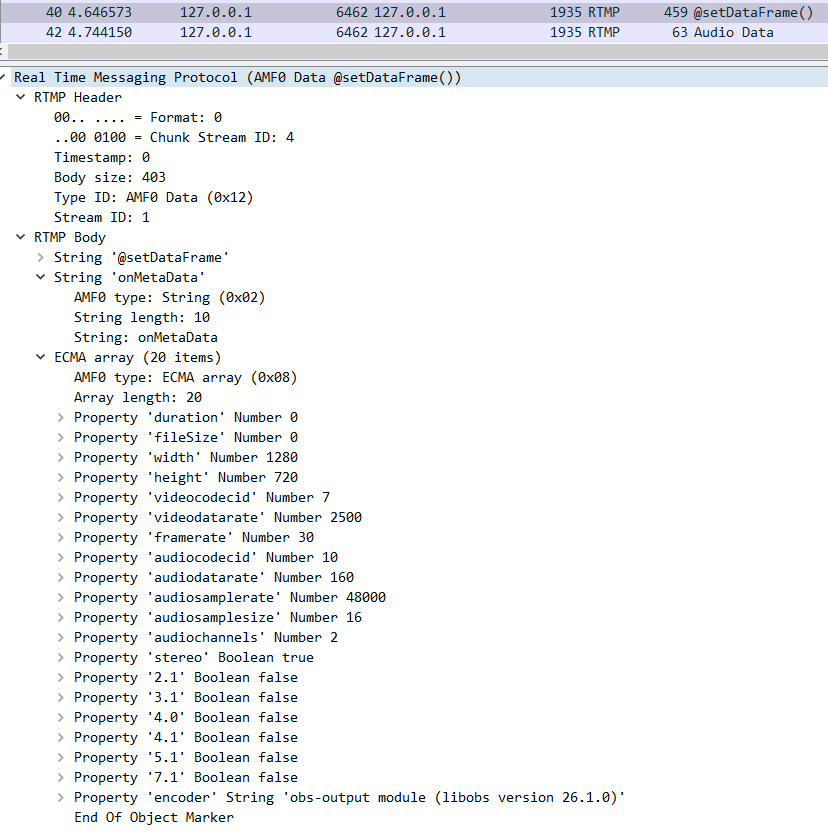
服务端会首先会检测这个频道名是否存在以及检查这个推流名是否被使用中,如果不存在或者在使用的话就会拒绝客户端的推流请求。由于我们在推流前已经生成了该频道名,客户端可以合法使用,于是服务端在38号包中回应的是 "NetStream.Publish.Start",也就是告诉客户端可以开始推流了。客户端在推流音视频数据前需要先把音视频的的元数据发给服务端,也就是40号包所做的事情,我们可以看一下该包的详细内容。从下图可以看出,发送元数据信息比较多,包含有视频分辨率,帧率,音频采样率和音频声道等关键信息。
告诉服务端音视频元数据后,客户端就可以开始发送有效的音视频数据了,服务端会一直接收这些数据,直到客户端发出 FCUnpublish 和 deleteStream 命令为止。stream.go 的 TransStart() 方法主要逻辑为接收推流客户端的音视频数据,然后在本地缓存最新的一个数据包,最后将音视频数据发给各个拉流端。其中读取推流客户单音视频数据主要是使用到 rtmp.go 中的 VirReader.Read() 方法,相关代码和注释如下所示。
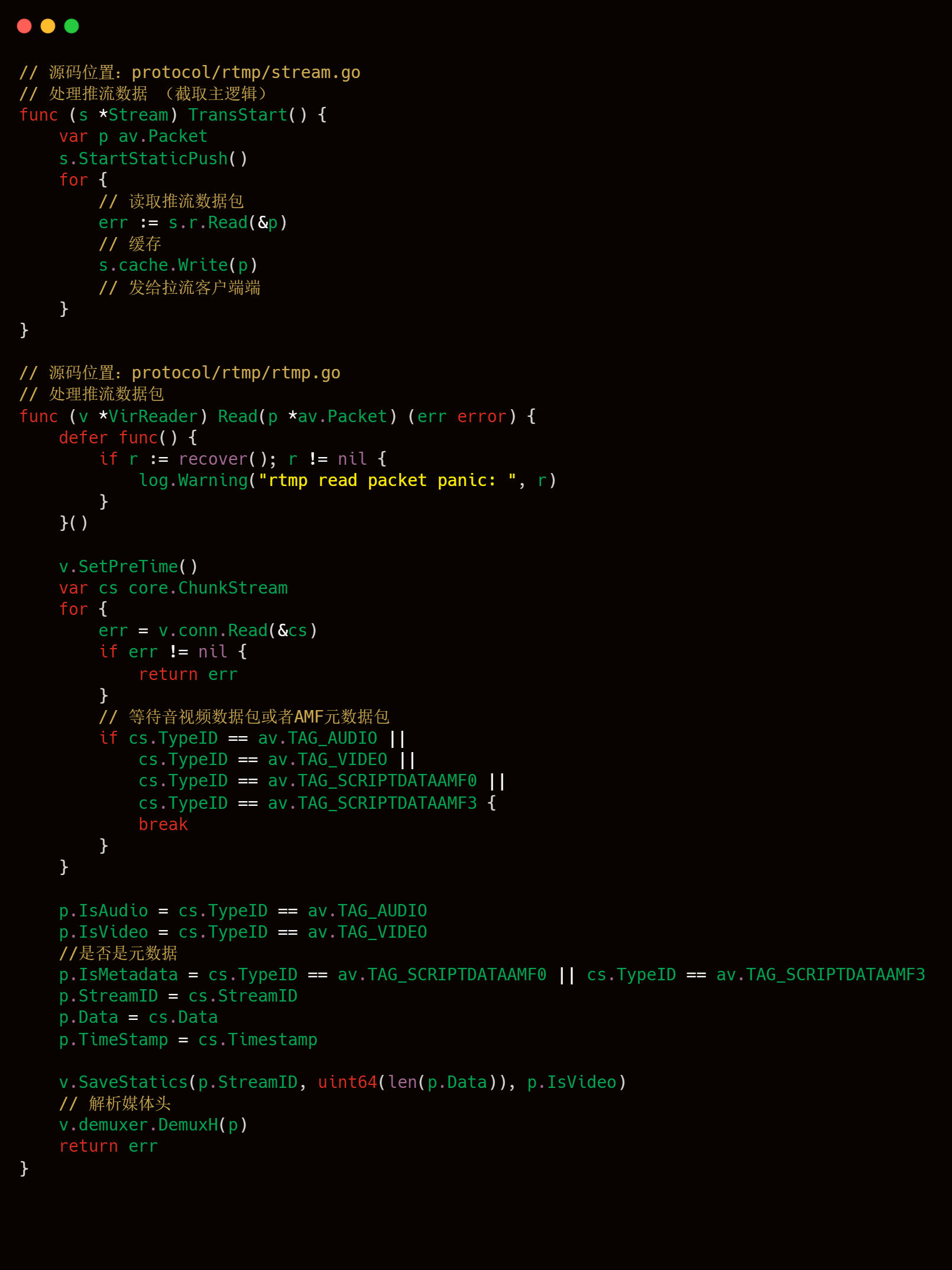
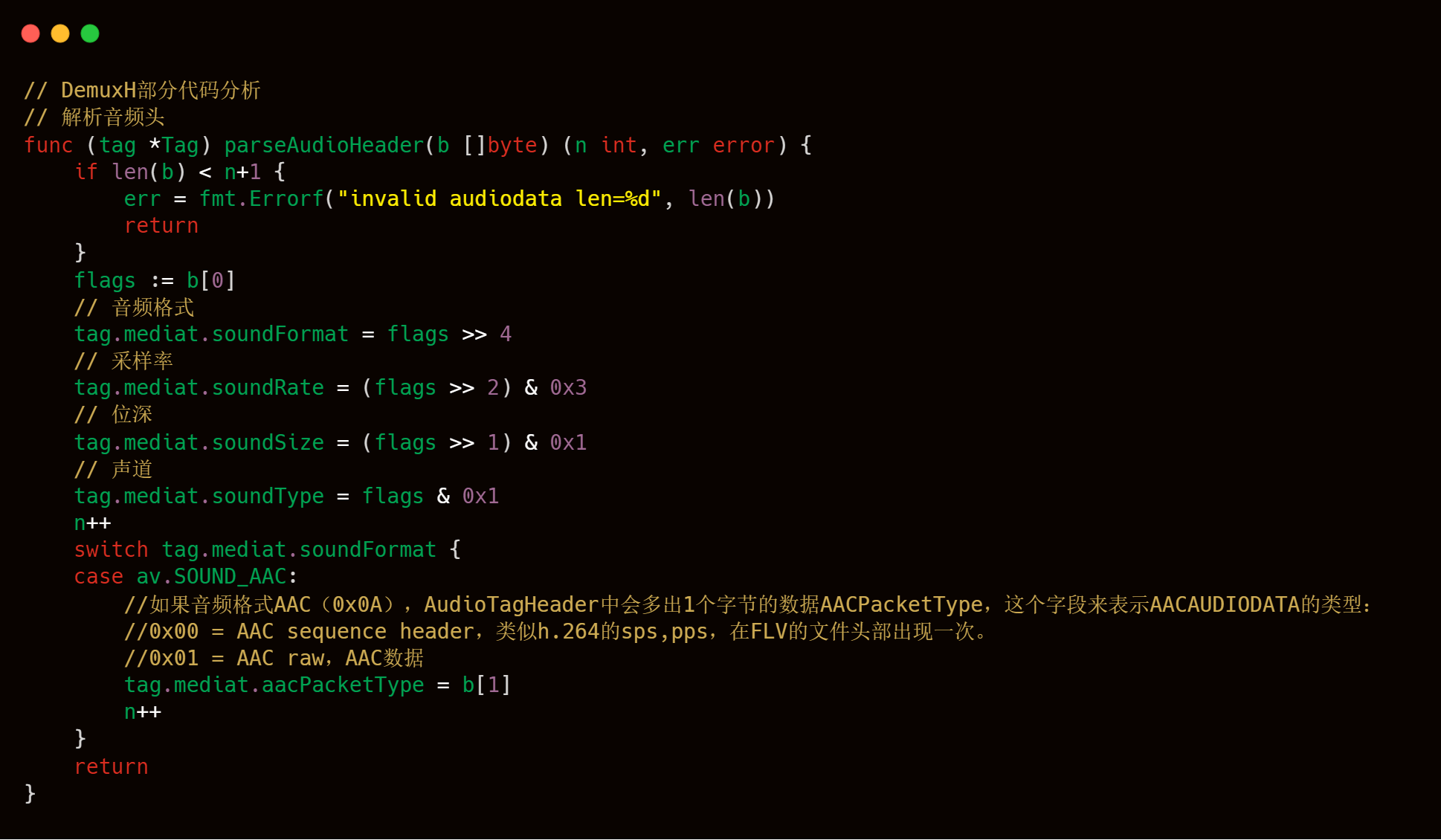
附媒体头信息解析的部分源码分析。
解析音频头
解析视频头
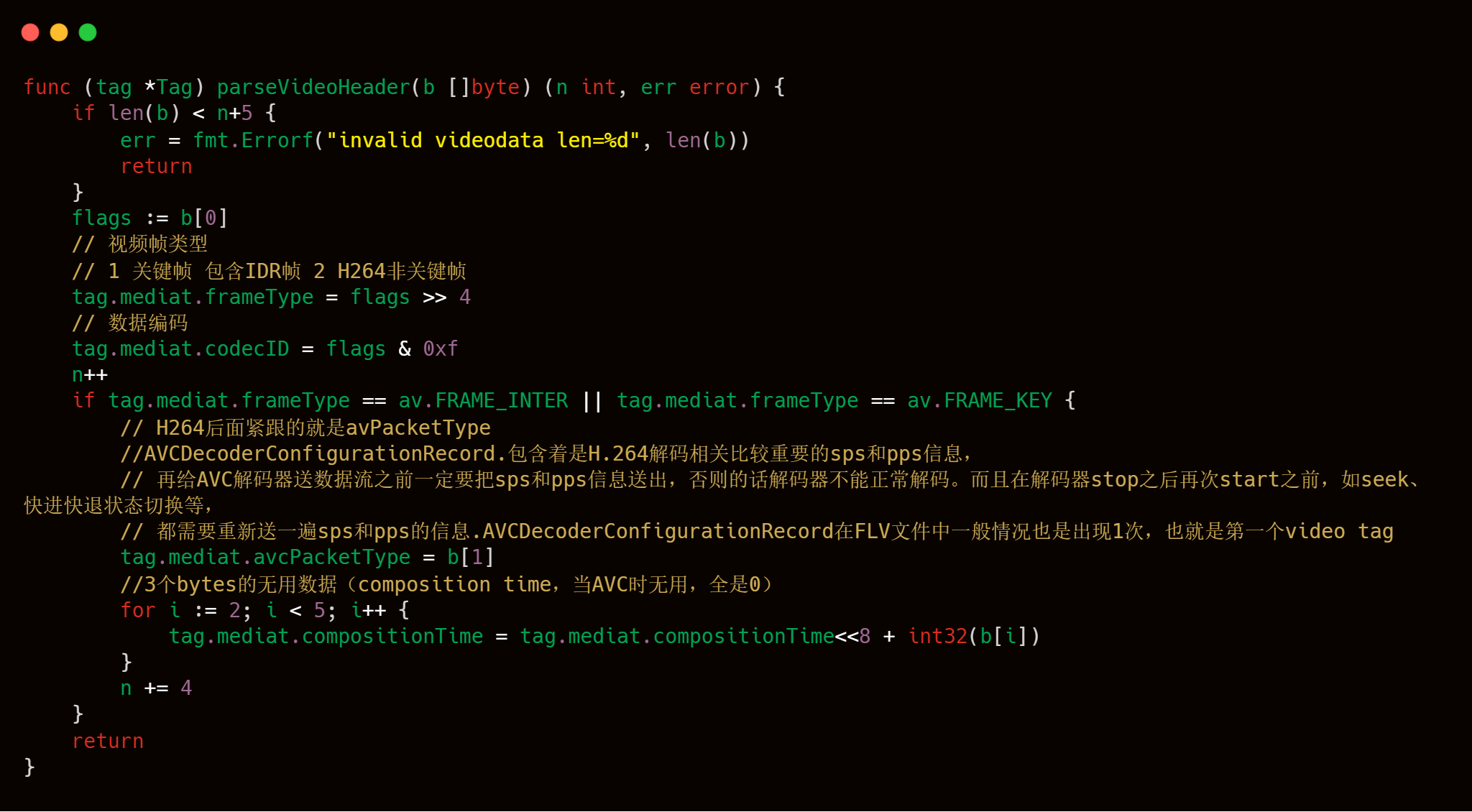
3.2.2.5 拉流
有了推流客户端的持续推流,拉流客户端就可以通过服务器持续拉取到音视频数据了。RTMP 协议规范的7.2.2.1节对拉流过程进行了详细描述。其中,握手、连接和创建流的过程前文已经讲述过了,我们重点关注下 play 命令的过程就行。
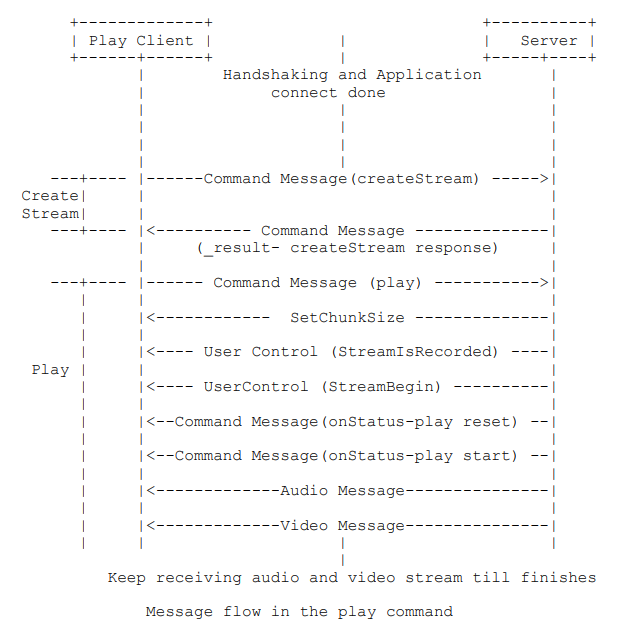
同样,我们先用 WireShark 抓包来分析下。客户端通过 640 号包告诉服务器,我想要播放叫 “movie” 的频道。

此处为什么是叫 “movie” 而不是推流时候用的“rfBd56ti2SMtYvSgD5xAV0YU99zampta7Z7S575KLkIZ9PYk”,其实这两个指向的是同一个频道,只不过一个用于推流一个用于拉流,我们可以从 livego 的源码来印证这一点。
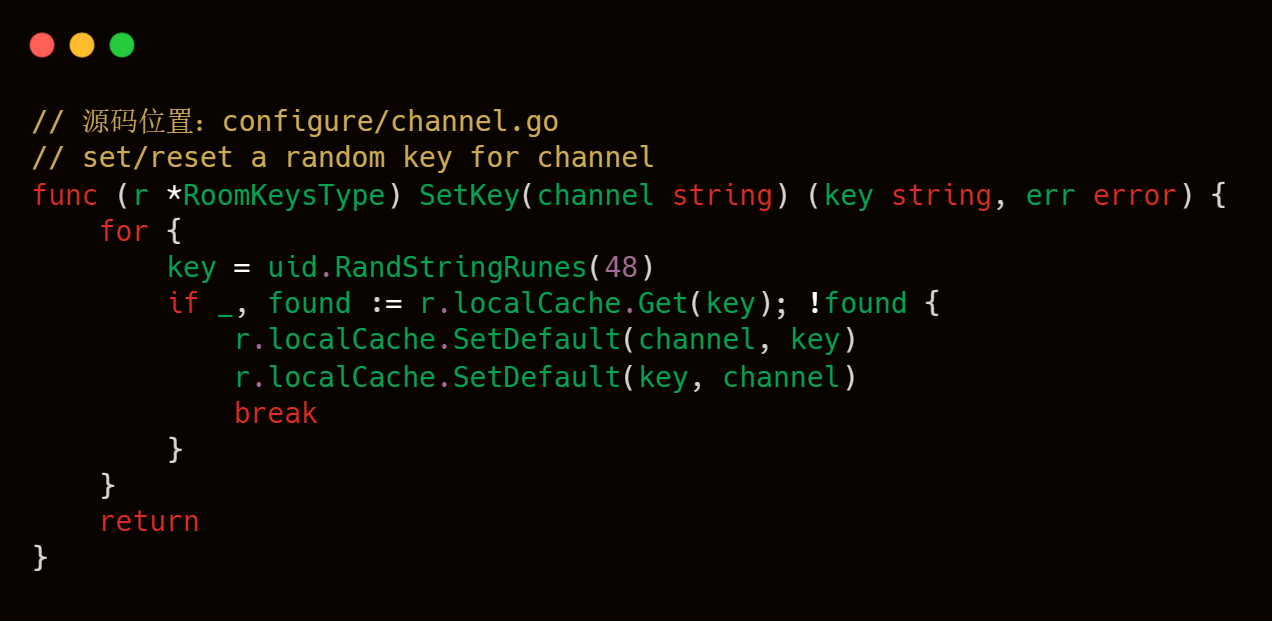
服务端收到拉流客户端的 play 请求后,会做出响应 "NetStream.Play.Reset","NetStream.Play.Start" ,"NetStream.Play.PublishNotify" 和音视频元数据。这些工作做完后,就可以持续发送音视频数据给拉流客户端了。我们可以通过 livego 源码来加深一下对此过程的理解。
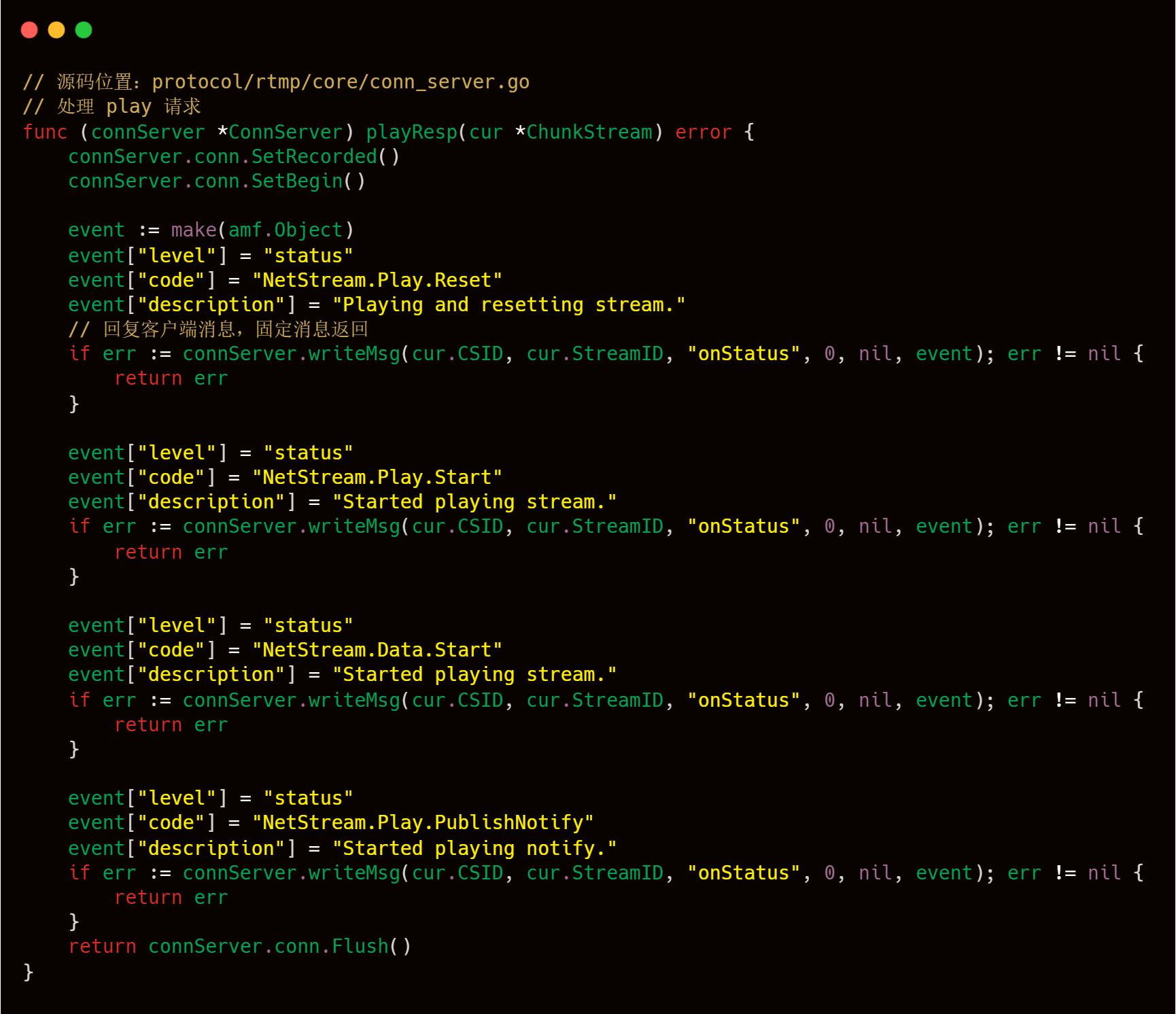
通过 chan 读取推流数据,然后发给拉流客户端。
到此为止整个RTMP的主体流程就是这样了,这边不涉及FLV,HLS等具体传输协议或者格式转换的源码说明,也就是说RTMP服务器怎么收到推流客户端的音视频包也会原封不动地分发给拉流客户端,并没有做额外的处理,不过现在各大云厂商拉流端都支持http-flv,hls等传输协议的支持,并且也支持音视频的录制回放点播功能,这块livego其实也是支持的。
因为篇幅限制,这边就不再展开介绍,后续有机会,再单独一起学习分享介绍livego关于这块逻辑的处理。
目前基于RTMP协议的直播是国内直播的基准协议,也是各大云厂商都兼容的直播协议,它的多路复用,分包等优秀特性也是各大厂商选择它的一个重要原因。在这个基础之上,也是因为它是应用层协议,腾讯,阿里,声网等大型云厂商,也会对其协议的细节,进行源码的改造,例如实现多路音视频流的混流,单路的录制等功能。
但是RTMP也有它自己本身的缺点,时延较高就是RTMP一个最大的问题,在实际的生产过程中,即使在比较健康的网络环境中,RTMP的时延也会有3~8s,这与各大云厂商给出的1~3s理论时延值还是有较大出入的。那么时延会带来哪些问题呢?我们可以想象如下的一些场景:
在线教育,学生提问,老师都讲到下一个知识点了,才看到学生上一个提问。
电商直播,询问宝贝信息,主播“视而不理”。
打赏后迟迟听不到主播的口播感谢。
在别人的呐喊声知道球进了,你看的还是直播吗?
特别是现在直播已经形成产业链的大环境下,很多主播都是将其作为一个职业,很多主播使用在公司同一个网络下进行直播,在公司网络的出口带宽有限的情况下,RTMP和FLV格式的延迟会更加严重,高时延的直播影响了用户和主播的实时互动,也阻碍了一些特殊直播场景的落地,例如带货直播,教育直播等。
以下是使用RTMP协议常规的解决方案:
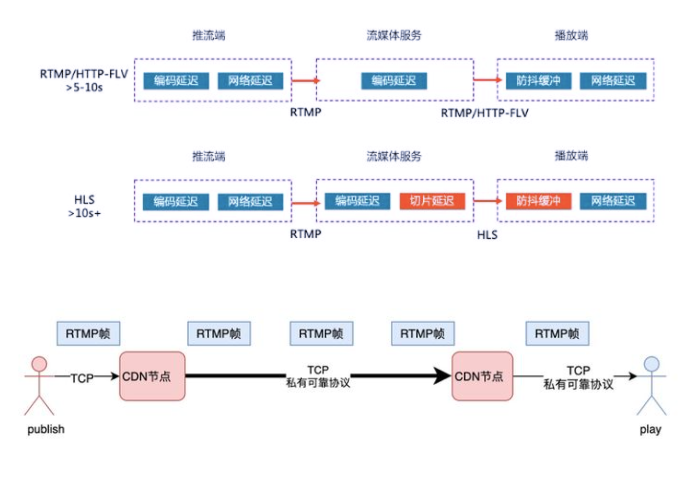
根据实际的网络情况和推流的一些设置,例如关键帧间隔,推流码率等等,时延一般会在8秒左右,时延主要来自于2个大的方面:
CDN链路延迟, 这分为两部分,一部分是网络传输延迟。CDN内部有四段网络传输,假设每段网络传输带来的延迟是20ms,那这四段延迟便是100ms;此外,使用RTMP帧为传输单位,意味着每个节点都要收满一帧之后才能启动向下游转发的流程;CDN为了提升并发性能,会有一定的优化发包策略,会增加部分延迟。在网络抖动的场景下,延迟就更加无法控制了,可靠传输协议下,一旦有网络抖动,后续的发送流程都将阻塞,需要等待前序包的重传。
播放端buffer,这个是延迟的主要来源。公网环境千差万别,推流、CDN传输、播放接收这几个环节任何一个环节发生网络抖动,都会影响到播放端。为了对抗前边链路的抖动,播放器的常规策略是保留6s 左右的媒体buffer。
到此,关于“什么是RTMP协议”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/vivotech/blog/5051106



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



