小编给大家分享一下怎么通过postgresql数据仓库实现湖仓一体数据分析,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
// 一.背景
随着云计算的普及和数据分析需求的扩大,数据湖+数据仓库的湖仓一体分析能力成为下一代数据分析系统的核心能力。相对于数据仓库,数据湖在成本、灵活性、多源数据分析等多方面,都有着非常明显的优势。IDC发布的十项2021年中国云计算市场趋势预测中,有三项和数据湖分析有关。可以预见,跨系统集成能力、数据控制能力和更加全面的数据驱动能力,将会是未来数据分析系统重要的竞争领域。
AnalyticDB PostgreSQL版(简称ADB PG)是阿里云数据库团队基于PostgreSQL内核(简称PG)打造的一款云原生数据仓库产品。在PB级数据实时交互式分析、HTAP、ETL、BI报表生成等业务场景,ADB PG都有着独特的技术优势。作为一个数据仓库产品,ADB PG是如何具备湖仓一体分析能力呢?本文将会介绍ADB PG如何基于PG外表、打造数据湖分析能力。
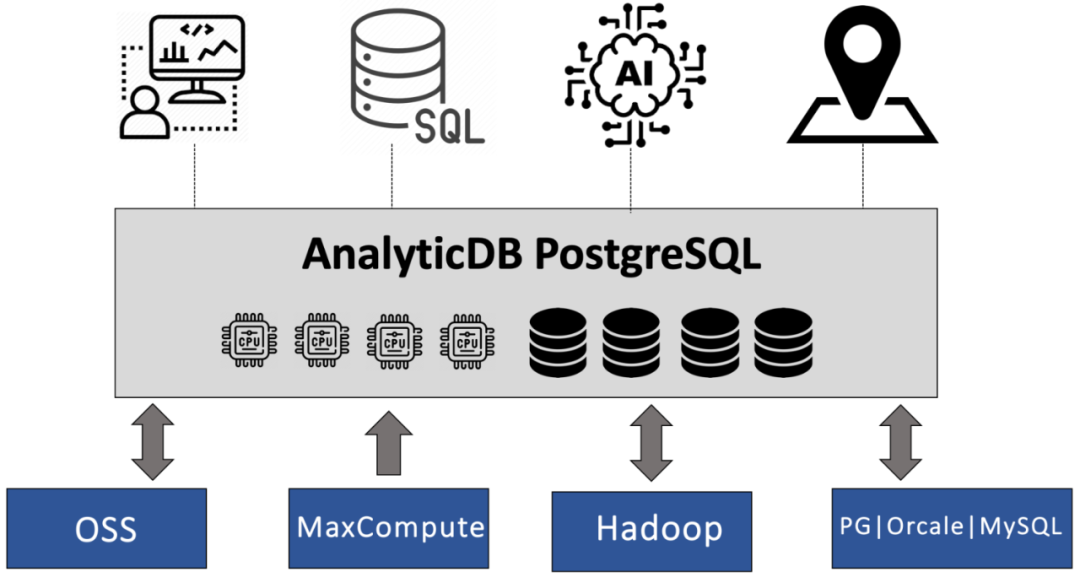
ADB PG继承了PG的外表(Foreign Table)功能,目前ADB PG的湖仓一体能力主要是基于外表打造的。基于PG外表,ADB PG可以对其他数据分析系统的数据进行查询和写入,在兼容多种数据源的同时,复用ADB PG原有的优化器和执行引擎优势。ADB PG的湖仓一体分析能力目前已经支持OSS、MaxCompute、Hadoop、RDS PG、Oracle、RDS MySQL等多种数据源的分析或者写入。用户可以灵活地将ADB PG应用于数据存储、交互式分析、ETL等不同领域,可以在单个实例中实现多种数据分析功能。即可以用ADB PG完成数据分析的核心流程,也可以作为众多环节中的一环去搭建数据链路。
不过,外表数据的分析依赖于外部SDK和网络IO来实现数据读写,由于网络本身的特性与本地磁盘有巨大差异,因此需要在技术层面与本地存储不同、需要不同的性能优化方案。本文以OSS外表数据读写为例,介绍ADB PG在构建湖仓一体分析能力时,所遇到的一些重要问题和解决方案。
// 二.问题分析
ADB PG内核可以分为优化器、执行引擎和存储引擎。外表数据分析可以复用ADB PG原有的优化器和执行引擎的核心部分,仅需少量修改。主要扩展是存储引擎层的改造,也就是通过外表接口对外表数据进行读写。外表数据是存储在另一个分布式系统当中,需要通过网络与ADB PG进行连接,这是和读取本地文件的最核心的区别。一方面,不同的外表数据会提供不同的远程访问接口,需要在工程上进行兼容,比如OSS、MaxCompute的数据读取接口都不相同。另一方面,通过网络访问远程机器上的数据有一定的共性,比如网络的延迟、网络放大、带宽限制、网络稳定性问题等。
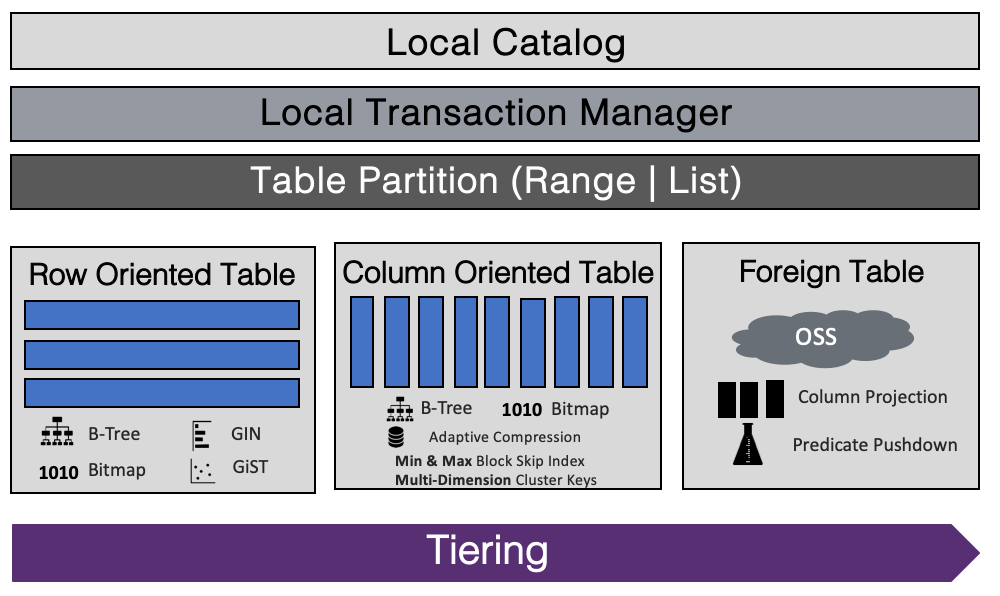
本文将会围绕上述核心挑战,介绍ADB PG外表分析项目在支持OSS数据分析过程中的一些重要技术点。OSS是一种阿里云推出的一种低成本分布式存储系统,存储了大量的冷热数据,有较大的数据分析需求。为了方便开发者进行扩展,OSS提供了基于Java、Go、C/C++、Python等主流开发语言的SDK。ADB PG采用了OSS C SDK进行开发。目前ADB PG已经完美支持OSS外表分析的各项功能,除建表语句不同外,用户可以像访问本地表一样访问OSS外表。支持并发读取和写入,支持CSV、ORC、Parquet等常见数据格式。
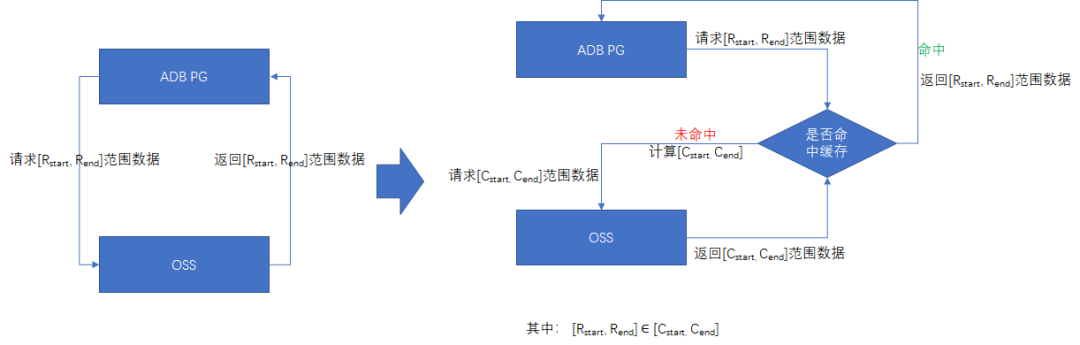
3.2 列过滤与谓词下推
由于网络本身的IO性能往往是低于本地存储的IO性能的,因此在扫描外表数据时,要尽量减少IO的带宽资源消耗。ADB PG在处理ORC、Parquet格式的文件时,采用了列过滤和谓词下推技术,来达到这一目的。
列过滤,即外表只请求SQL查询所需的数据列、忽略不需要的数据列。因为ORC、Parquet都是列式存储格式,所以外表在发起网络请求时,只需请求所需列所在的数据范围即可,从而大幅减小网络I/O。同时,ORC、Parquet会对列数据进行压缩处理,进一步减小I/O。
谓词下推,是将执行计划里的上层的过滤条件(如WHERE子句中的条件),移动到下层的外表扫描节点,使外表扫描进行网络请求时,过滤掉不符合查询条件的数据块,从而减少网络I/O。在ORC/Parquet格式文件中,会在每一个block头部保存该block中每一列数据的min/max/sum等统计信息,当外表扫描时,会先读取该block的头部统计信息,与下推的查询条件进行比较,如果该列的统计信息不符合查询条件,则可以直接跳过该列数据。
这里简单介绍ORC格式的外表的谓词下推的实现方案。一个ORC文件按数据行分成若干个Stripe组成,Stripe中数据按列式存储。每个Stripe又分为若干个Row Group, 所有列的每 10000行 组成一个Row Group。如下图所示。
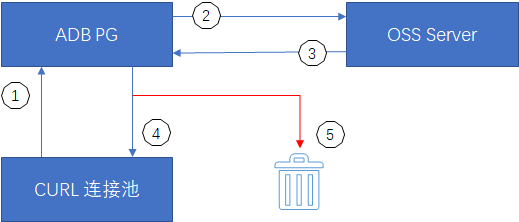
① ADB PG访问OSS外表时,先从CURL连接池中获取连接,若不存在则新建。
② ADB PG使用CURL连接句柄与OSS Server请求通信。
③ OSS Server通过CURL连接句柄返回通信结果。
④ 正常返回的CURL连接句柄使用完毕后加回连接池待下次使用。
⑤ 异常状态的CURL连接句柄销毁。
3.4 内存管理方案的兼容问题
ADB PG基于PostgreSQL内核打造,也继承了PostgreSQL的内存管理机制。PostgreSQL的内存管理采用了进程安全的内存上下文MemoryContext,而OSS C SDK是线程安全的内存上下文APR Pool。在MemoryContext内存环境下,每个已经分配的内存,都可以显式地调用free释放,由MemoryContext进行内存碎片的整理,但在APR Pool中,我们只看到内存池的创建、内存的申请和内存池的销毁等操作,却没有内存的显式释放接口。
这种情况意味着,我们需要对于OSS C SDK接口所持有的内存的生命周期有明确的了解,否则极易出现内存泄漏和访问已经释放的内存等问题。通常我们会按照如下两种方式申请APR Pool的内存。
方式一适用于重入低频的操作接口,如获取OSS文件清单列表。
方式二适用于多次重入的操作接口,如周期性向OSS请求指定文件指定范围的数据。
通过这种方法,可以很好地解决ADB PG与OSS C SDK在内存管理方面的不兼容问题。

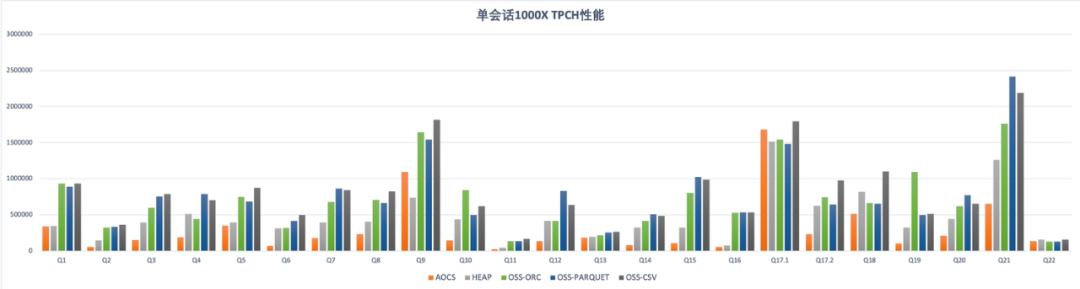
下图是TPCH 22条查询的详细时间。本地表与外表的性能差距在不同的查询上差距有所不同。考虑到外表在存储成本、灵活性、扩展能力方面的优势,ADB PG外表分析在应用场景的潜力是巨大的。
看完了这篇文章,相信你对“怎么通过postgresql数据仓库实现湖仓一体数据分析”有了一定的了解,如果想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





