这篇文章给大家介绍K-means算法如何实现二维数据聚类,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
所谓聚类分析,就是给定一个元素集合D,其中每个元素具有n个观测属性,对这些属性使用某种算法将D划分成K个子集,要求每个子集内部的元素之间相似度尽可能高,而不同子集的元素相似度尽可能低。聚类分析是一种无监督的观察式学习方法,在聚类前可以不知道类别甚至不用给定类别数量。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等领域。
聚类算法有很多种,如K-means(K均值聚类)、K中心聚类、密度聚类、谱系聚类、最大期望聚类等。这里我们重点介绍K-means聚类算法,该算法的基本思想是以空间中K个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。K-means算法实现简单、计算速度快、原理易于理解、具有理想的聚类效果,因此该算法是公认的经典数据挖掘方法之一。
例如对于常见的二维数据集,设计K-means聚类方法,对80个二维数据点进行聚类分析。K-means算法的Python语言实现及处理过程如下:
如下图所示的80个二维样本数据集,存储为testSet文本文档。经过数据预处理和简单分析,得知该数据集共有4个类别,因而能确定聚类数K为4。
首先导入必要的模块:
import kmeans
import numpy as np
import matplotlib.pyplot as plt
from math import sqrt
(1) 从文件加载数据集
构建数据矩阵,从文本中逐行读取数据,形成供后继使用的数据矩阵。
dataSet=[]
fileIn=open('testSet.txt')
for line in fileIn.readlines():
lineArr=line.strip().split('\t')
dataSet.append([float(lineArr[0]),float(lineArr[1])])
(2) 调用kmeans算法进行数据聚类
通过以下命令调用设计的kmeans模块,进行数据聚类。
dataSet=np.mat(dataSet)
k=4
centroids,clusterAssment=kmeans.kmeanss(dataSet,k)
kmeans模块主要包含如下几个函数。
距离度量函数。这里使用的是欧氏距离,计算过程如下:
def eucDistance(vec1,vec2):
return sqrt(sum(pow(vec2-vec1,2)))
初始聚类中心选择。从数据集中随机选择K个数据点,用作初始聚类中心。
def initCentroids(dataSet,k):
numSamples,dim=dataSet.shape
centroids=np.zeros((k,dim))
for i in range(k):
index=int(np.random.uniform(0,numSamples))
centroids[i,:]=dataSet[index,:]
return centroids
K-Means 聚类算法。该算法会创建k个质心,然后将每个点分配到最近的质心,再重新计算质心。这个过程重复数次,直到数据点的簇分配结果不再改变位置。
def kmeanss(dataSet,k):
numSamples=dataSet.shape[0]
clusterAssement=np.mat(np.zeros((numSamples,2)))
clusterChanged=True
##step1:init centroids
centroids=initCentroids(dataSet,k)
while clusterChanged:
clusterChanged=False
for i in range(numSamples):
minDist = 100000.0
minIndex=0
##step2 find the centroid who is closest
for j in range(k):
distance=eucDistance(centroids[j,:],dataSet[i,:])
if distance < minDist:
minDist=distance
minIndex=j
##step3: update its cluster
clusterAssement[i,:]=minIndex,minDist**2
if clusterAssement[i,0]!=minIndex:
clusterChanged=True
##step4: update centroids
for j in range(k):
pointsInCluster=dataSet[np.nonzero(clusterAssement[:,0].A==j)[0]]
centroids[j,:]=np.mean(pointsInCluster,axis=0)
print ('Congratulations,cluster complete!')
return centroids,clusterAssement
聚类结果显示。将聚类划分在的不同簇的数据,用不同的颜色和符号进行显示,同时画出最终的聚类中心。
def showCluster(dataSet,k,centroids,clusterAssement):
numSamples,dim=dataSet.shape
mark=['or','ob','og','ok','^r','+r','<r','pr']
if k > len(mark):
print("Sorry!")
return 1
for i in np.xrange(numSamples):
markIndex=int(clusterAssement[i,0])
plt.plot(centroids[i,0],centroids[i,1],mark[i],markersize=12)
plt.show()
(3) 聚类结果显示
对80个二维数据,使用K-means方法进行聚类,聚类结果如图13-5所示,迭代后的聚类中心用方形表示,其他数据用不同颜色的原点表示。
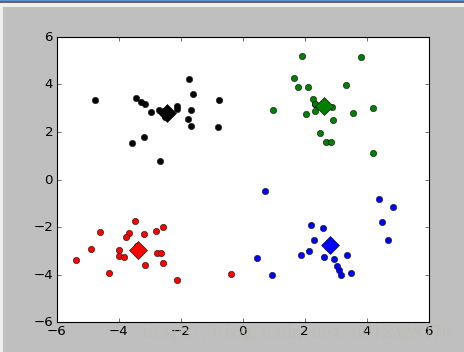
图 二维数据的聚类结果
关于K-means算法如何实现二维数据聚类就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





