这篇文章主要讲解了“python怎么爬明星贴吧”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“python怎么爬明星贴吧”吧!
贴吧的翻页通过url的变化来实现,主要是pn参数:
https://tieba.baidu.com/f?kw=明星&ie=utf-8&pn=页数*50
帖子的内容、发帖者及跟帖数量都可以在网页中找到:

所以,我们只需要用requests模拟请求获得,再用bs4解析就可以获得想要的内容了
1.爬取数据
用了静态网页爬虫的老套路,根据网页源码的特点,用find_all函数提取了帖子、发帖人及跟帖数量等信息,并将3类信息放入列表中,最终生成1个二维列表result,主要为了方便存入数据库,代码如下:
for t in range(250):
print('第{0}页'.format(t+1))
url='https://tieba.baidu.com/f?kw=明星&ie=utf-8&pn={0}'.format(t*50)
header = {
'User-Agent': 'Mozilla/5.0(Windows NT 6.1; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0'
}
response = requests.get(url, header)
soup = BeautifulSoup(response.text, 'html.parser')
items_content = soup.find_all('a', class_='j_th_tit') #内容
items_user = soup.find_all('span', class_='tb_icon_author') #昵称
items_comment = soup.find_all(class_='threadlist_rep_num center_text') #跟帖数量
for i, j, k in zip(items_content, items_user, items_comment):
result.append([i.get('title'), j.get('title')[5:], k.text])
time.sleep(1)2.存入数据库
先创建1个新表,命名为‘STAR’,然后再创建3列,分别命名为“title”、‘author’和‘num’,用于存放1中怕的内容,最后将二维列表result中的内容存入数据库:
conn=pymysql.connect( host='127.0.0.1', port=3306, user='root', password='数据库密码', db='test1', charset='utf8mb4' ) cur = conn.cursor() #如果存在TIEBA表,则删除 cur.execute("DROP STAR IF EXISTS STAR") #创建TIEBA表 sql = """ create table STAR( title char(255), author char(100), num char(20)) """ cur.execute(sql) for i in result: cur.execute("INSERT INTO STAR(title,author,num) VALUES ('{0}','{1}','{2}')". format(i[0].replace('\'','').replace('\"','').replace('\\',''), i[1], i[2])) conn.commit()
由于帖子内容中存在表情等符号,所以选择用'utf8mb4'这样就可以把表情也存入数据库了,但是还有一些标点符号在写入过程会出错,所以用replace给替换掉了。
总共爬了1万3千多条数据,基本把最近两年的帖子都爬完了。
用create_engine模块读取数据库表中的内容,代码如下:
import pandas as pd
from sqlalchemy importcreate_engine
# 初始化数据库连接,使用create_engine模块
engine =create_engine('mysql+pymysql://root:密码@127.0.0.1:3306/test1')
# 查询语句,选出STAR表中的所有数据
sql = ''' select *from STAR; '''
# read_sql_query的两个参数: sql语句, 数据库连接
df =pd.read_sql_query(sql, engine)
# 输出STAR表的查询结果
df['num']=[int(i) for i in list(df['num'])]
df=df.drop_duplicates(subset=['title','author','num'], keep='first')因为跟帖数量是以字符格式存入的,所以先将其转为整数,再用drop_duplicates模块对数据进行去重,这样就把数据整理完毕了。
上万条数据放在你面前,用肉眼是看不出什么名堂的,所以我这里选择了几个角度,用python统计分析这个贴吧里到底隐藏着什么秘密
1.找出发帖数量最多的20个人
说简单点就是创建1个空字典,然后把df['author']转成列表,统计列表中元素个数,将元素及个数存入字典中,再对字典进行排序,将前十个画成柱状图,代码如下:
#发帖数量排名
rank_num={}
for i in list(set(list(df['author']))):
rank_num[i.replace(' ', '')] = list(df['author']).count(i)
rank_num = sorted(rank_num.items(), key=lambda x: x[1], reverse=True)
bar = Bar("柱状图", "发帖数量-昵称")
bar.add("发帖数量-昵称", [i[0] for i in rank_num[:10]], [i[1] for i in rank_num[:10]],
xaxis_rotate=45, mark_line=["average"], mark_point=["max", "min"])
bar.render('发帖数量-昵称.html')结果如下:
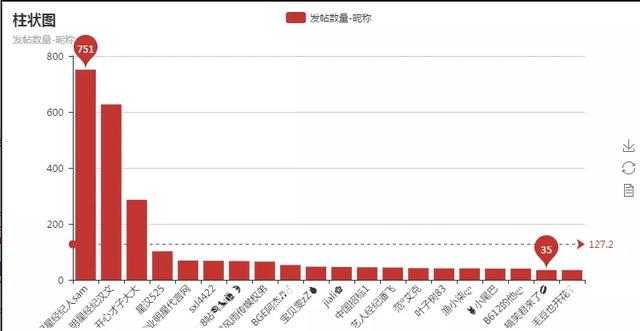
这个猎头发帖有点猛啊,单人最高发了751个,真厉害。
2.找出跟帖数最多的20个帖子
dff=df.sort_values(by='num', ascending=False).head(10)
bar = Bar('跟帖数量排名',width=1000,height=400)
bar.use_theme('dark')
bar.add('' ,dff['title'][::-1], dff['num'][::-1], is_convert=True, is_yaxis_inverse=False, xaxis_rotate=45,is_label_show=True,label_pos='right')
bar.render("跟帖数量排名.html")
跟帖最多的竟然是个水贴,数量高达73459次
3.制作所有帖子的词云图
先把所有帖子连接成字符,用jieba进行分词,插入背景图片,代码如下:
import matplotlib.pyplot as plt import jieba from wordcloud importwordcloud text='' for i in list(df['title']): text+=i print(text) cut_text = jieba.cut(text) result=[] for i in cut_text: result.append(i) result = ">
效果如下:

感谢各位的阅读,以上就是“python怎么爬明星贴吧”的内容了,经过本文的学习后,相信大家对python怎么爬明星贴吧这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





